







- 前言
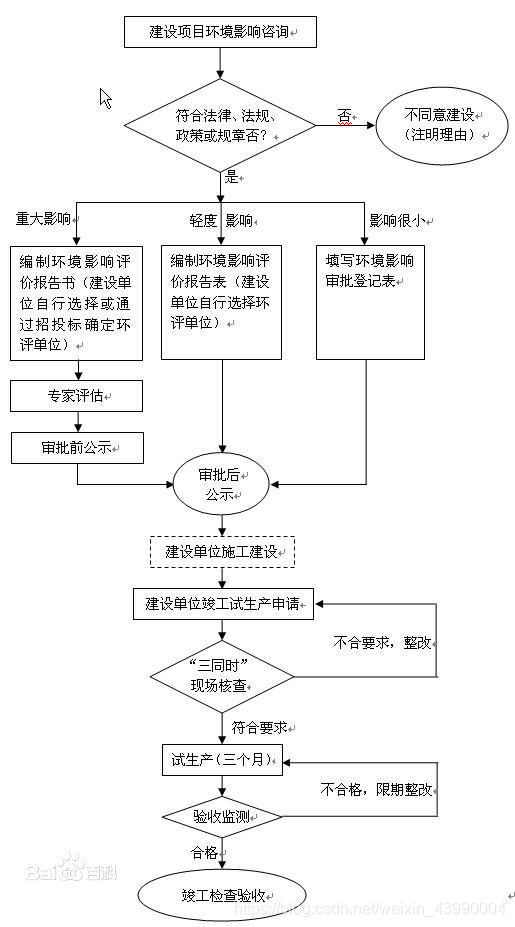
在生猪养殖行业内,众所周知,我国的生猪养殖以小养殖户为主。相应的要获取生猪市场准确的数据相对较难,每年新建多少猪场,可提供多少的出栏和存栏等等数据对于稳定我国或地区生猪供应具有很大的参考意义。为此,我们想到是否可以通过猪场建设过程中留下的一些痕迹老获取新建猪场情况?从网上的资源来看,猪场建设过程需要进行环境影响评价公示,进而将新建猪场的基本信息进行环评备案,通过审核的猪场新建项目建成之后还需进行排污监测,合格的国家生态环保部发放排污许可证。如下图所示。
因此,我们从国家生态环保部入手,收集了两个官方网站,各省市建设项目环境影响登记表备案系统及公示入口(以下简称备案系统):[http://www.hj369.com.cn/djb/];全国排污许可证管理信息平台(以下简称许可系统):http://permit.mee.gov.cn/permitExt/syssb/xxgk/xxgk!sqqlist.action需要说明的是这两个环评管理系统应该是唯二国家官方的公示系统。在各省市的环保部门网站也是有相应的入口可以连接进来。 - 数据源及获取
通过进入备案系统,可以看到可以比较方便的获取到新建项目的基本信息,进入登记表详细信息,亦可查看到建设项目的规模。
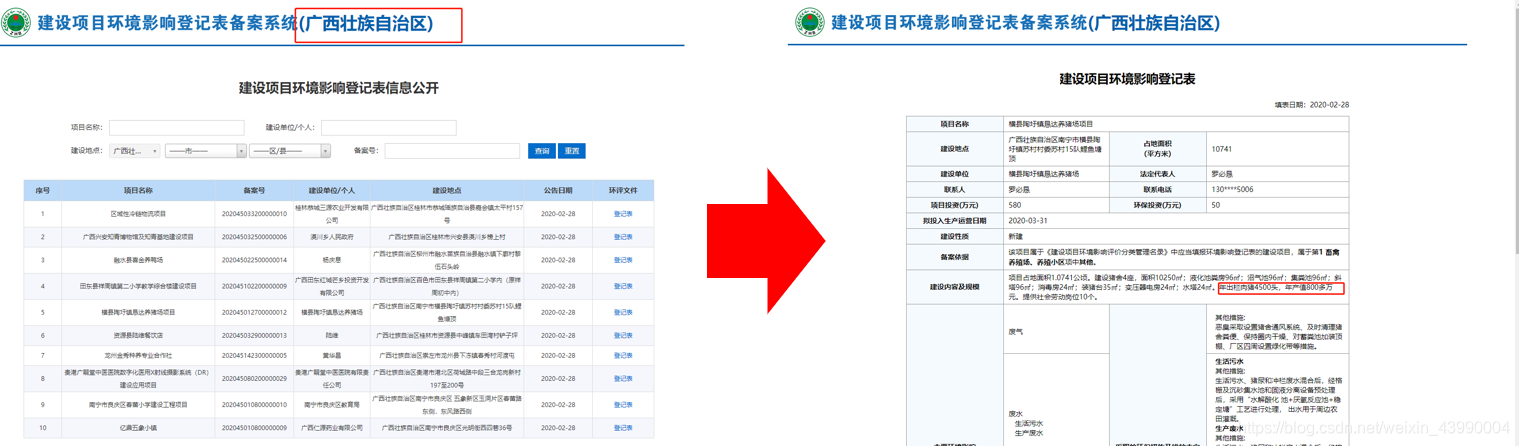
数据获取,通过一定的手段我们获取了广西壮族自治区的生猪养殖项目所有需要环评公示的项目。从2017年01月到2020年02月一共2291条数据.
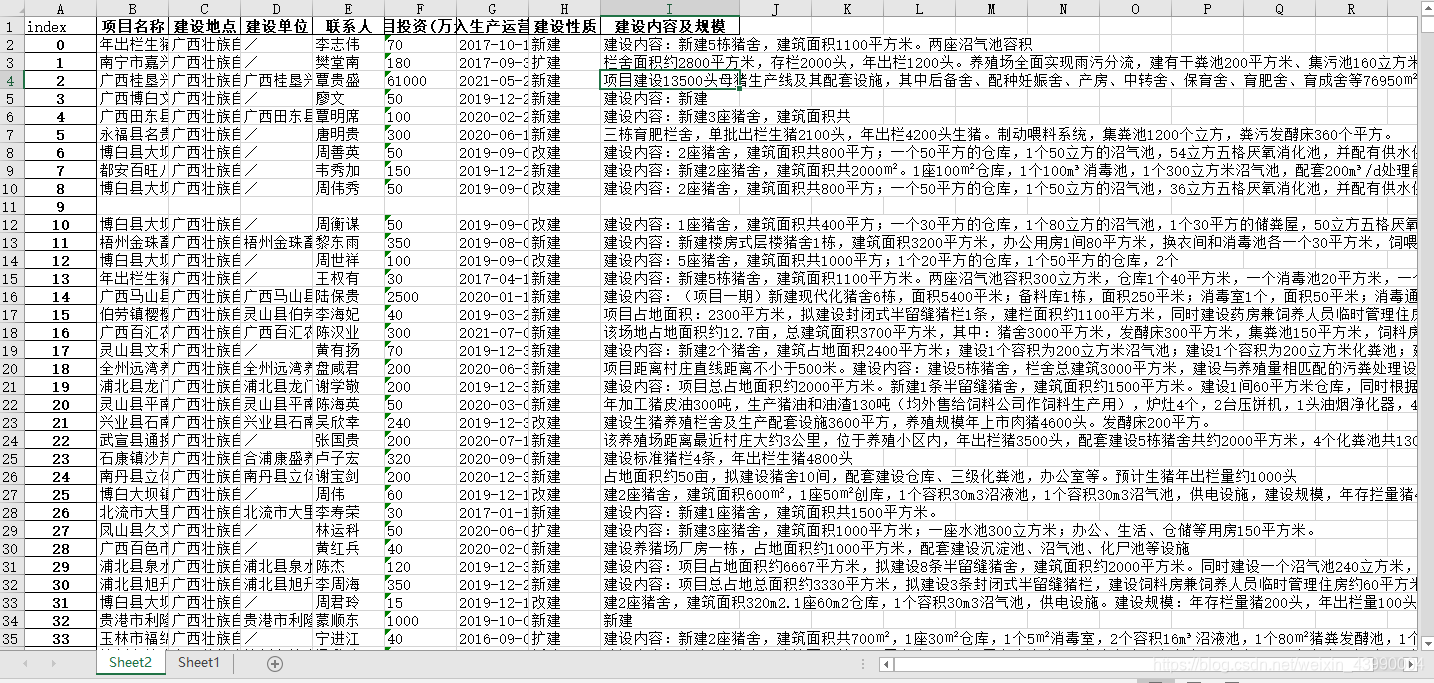
- 数据清洗
1 生猪存栏出栏数据获取
我们可以看到猪场存栏和出栏数据在建设规模中,采用正则式提取关键数据:
content_txt['inventory'] = content_txt['scale'].str.extract(r'(存栏.*?\d+)',expand=False)
content_txt['inventory']=content_txt['inventory'].str.extract(r'(\d+)',expand=False)
content_txt['out'] = content_txt['scale'].str.extract(r'(出栏.*?\d+)',expand=False)
content_txt['out']=content_txt['out'].str.extract(r'(\d+)',expand=False)
查看数据缺失情况,有较多建设单位或个人未填写出栏和存栏数据。
2 缺失值处理
基本思路,利用投资与出栏存栏存在一定的关系来建模估算存栏和出栏。
(1)将投资额划分成区间
1)首先看已有存栏出栏的项目投资情况
data_out = data[data['out'].notnull()]
data_inventory = data[data['inventory'].notnull()]
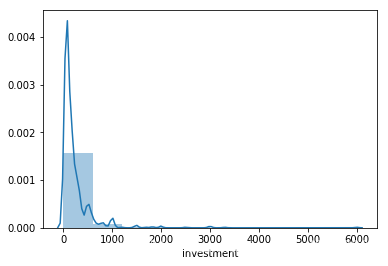
第一个投资频数图:
可引导投资基本集中在1000万以下,其中500万占绝大多数,符合我国养殖规模偏小散户的事实;
sns.distplot(data_out.investment,bins=10)
第二个投资区间频数图:查看投资0~500万的分布情况
data_out_500 = data_out[data_out['investment']<500]
sns.distplot(data_out_500.investment,bins=10)
plt.title('投资在0-500万的分布情况')
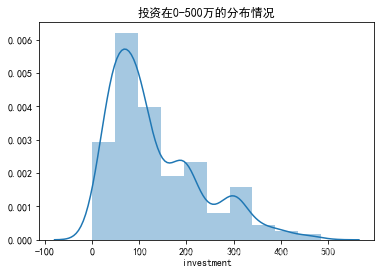
利用投资区间频数图,将投资区间划分为:[0,50,100,150,200,250,300,350,500,1000,2000,3000,4000,5000,6000,10000,800000];
data_out['investment_bins']=pd.cut(data_out['investment'], [0,50,100,150,200,250,300,350,500,1000,2000,3000,4000,5000,6000,10000,800000], labels=[u"0-50",u"50-100",u"100-150",u"150-200",u"200-250",u"250-300",u"300-350",u"350-500",u"500-1000",u"1000-2000",u"2000-3000",u"3000-4000",u"4000-5000",u"5000-6000",u"6000-10000",u"10000-800000"])
(2)根据已有的数据获取缺失值
将区间内的出栏和存栏量的平均值映射到缺失值,也即根据投资划分的存栏/出栏平均值进行填空。
data_bins = data_out.groupby(by='investment_bins').mean()
data_bins.out.fillna(value=0,inplace=True)
data_bins.out = data_bins.out.apply(lambda x: int(x/100)*100)
data_bins.inventory.fillna(value=0,inplace=True)
data_bins.inventory = data_bins.inventory.apply(lambda x: int(x/100)*100)
data_bins.out = data_bins['out'].astype(int)
data_bins.inventory = data_bins['inventory'].astype(int)
bins_dict_out = data_bins['out'].T.to_dict()
bins_dict_inv = data_bins['inventory'].T.to_dict()
(3)数据校验
- 第一个图为源数据中已有存栏和出栏量的频数图
sns.distplot(data_out.out,bins=10)
plt.title('出栏量分布情况')
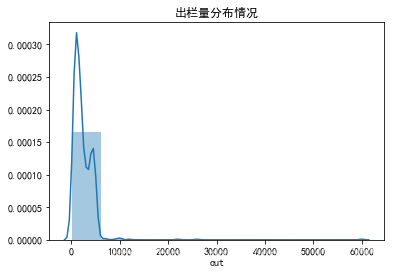
- 出栏量在6000以下的占绝大多数。查看0~6000头出栏分布情况:
data_out_500 = data_out[data_out['out']<6000]
sns.distplot(data_out_500.out,bins=10)
plt.title('出栏在0-6000的分布情况')
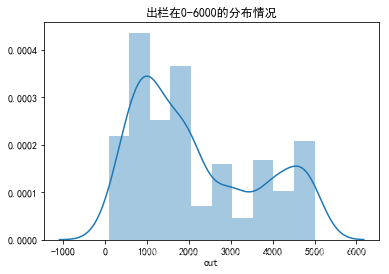
- 查看经过投资划分进行缺失值填空的0~6000头出栏分布情况
sns.distplot(data[data.out<6000].out,bins=10)
plt.title('出栏0~6000头分布情况')
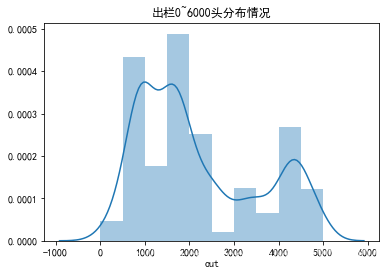
从数据分布情况来看,数据缺失值的处理还算是比较成功的。
下一章将根据处理好的数据进行分析。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









