






文档审查及质量检测背景
随着企业运营和知识管理的日益复杂,文档的合规性与质量成为确保信息准确、流程顺畅及风险控制的关键环节。传统上,人工进行文档的合规性和质量检测不仅耗时耗力,且易受主观因素影响,难以保证检测的全面性和一致性。尤其是在面对大量、多样化的文档时,如何高效、准确地完成检测成为一大挑战。
为了应对这一挑战,借助人工智能和自然语言处理技术构建智能文档处理系统成为当前的研究热点。本项目基于 Multi-Agent Collaboration OS 的理念,设计并实践了一个文档合规性及质量检测助手。该助手通过协同多个智能体(Agent)来自动化文档处理流程。这些智能体各司其职,包括但不限于文件解析、文件质量检测、文件摘要生成 、目录自动生成、知识检索 、流程设计、文档核心检测 、修改意见生成 以及最终的文档总结报告输出 。基于Multi Agents Collaboration OS的模块化、协同工作的智能体架构,旨在提升文档检测的效率和准确性,为用户提供一个全面的文档合规性与质量管理解决方案。
核心技术及流程设计:Multi Agents Collaboration OS
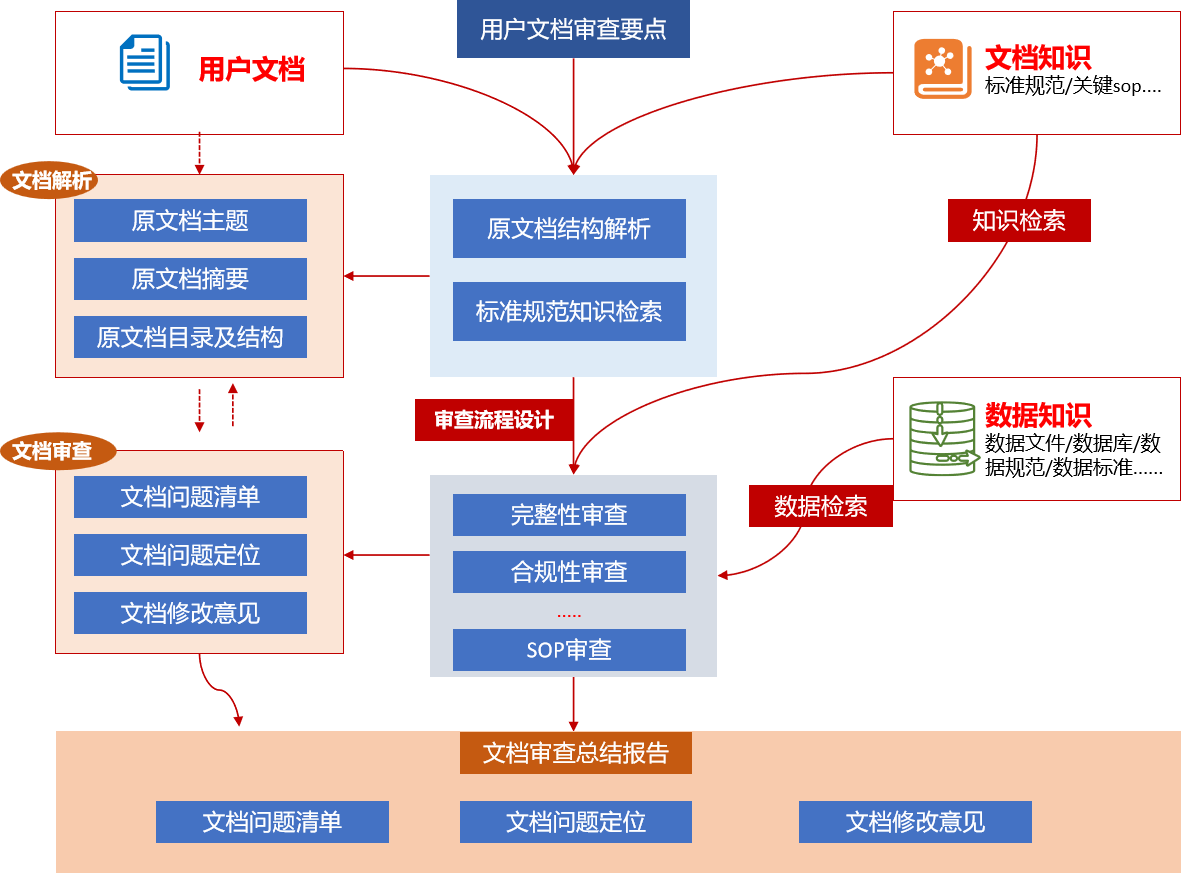
整个平台的核心流程始于用户上传待审查的文档,并可选择输入用户文档审查要点。系统接收文档后,首先进行文档解析,提取文档的主题、摘要、目录及结构等基础信息。同时,平台会基于这些信息并结合预设的文档知识库(包含标准规范、关键 SOP 等),执行知识检索,获取与用户文档相关的合规及质量标准。
接下来是关键的审批流程设计阶段。系统会根据解析出的文档内容、用户指定的审查要点以及检索到的标准规范知识,智能地设计出一套针对该文档的定制化审查流程。这个流程通常包括完整性审查、合规性审查、SOP 审查等多个环节,并且可能涉及对数据知识库进行数据检索以验证文档中数据的准确性或一致性。
设计好的审查流程指导着文档审查的执行。系统按照流程对文档内容进行细致 분석,识别出其中的问题。审查的结果会被整理成文档问题清单,明确指出存在的问题;同时进行文档问题定位,标注问题所在的具体位置;并给出相应的文档修改意见,提供改进建议。
最后,平台会将所有审查结果进行汇总,生成一份详尽的文档审查总结报告。这份报告整合了发现的问题、问题的位置以及修改意见,为用户提供了一个清晰、全面的文档合规性和质量评估结果,辅助用户高效地进行文档修改和完善。
智能体设计及代码实践
该文档合规性及质量检测平台基于 Multi-Agent Collaboration OS 的总体设计原则,采用模块化和协同工作的智能体架构。每个智能体负责流程中的特定环节,并通过结构化的输入输出进行通信与协作,共同完成文档的审查任务。这种设计提高了系统的灵活性、可维护性和可扩展性。
平台中设计的关键智能体及其功能和输出如下:
- 文件上传与解析智能体:
- 功能:负责接收用户上传的 PDF、Word 等格式的文档。解析文档内容,提取文本信息、页码、并进行初步的文件质量检测。
- 输出:结构化的文档原始内容(包含页码),以及文件质量状况的初步评估(在设计中有提及)。
- 代码:
def parse_pdf_with_page_numbers(pdf_path):
"""
Parse a PDF file and extract text along with page numbers.
Args:
pdf_path (str): Path to the PDF file.
Returns:
list of dict: A list where each item contains the page number and the extracted text.
"""
pdf_document = fitz.open(pdf_path)
parsed_data = []
for page_number in range(len(pdf_document)):
page = pdf_document[page_number]
text = page.get_text()
parsed_data.append({
"page_number": page_number, # Page numbers are 1-based
"text": text
})
page_number += 1
pdf_document.close()
return parsed_data
# 解析word文档,提取文本和页码
def parse_word_with_page_numbers(word_path):
"""
Parse a Word file and extract text along with page numbers.
Args:
word_path (str): Path to the Word file.
Returns:
list of dict: A list where each item contains the page number and the extracted text.
"""
document = Document(word_path)
parsed_data = []
# Simulate page numbers (Word documents do not have explicit page numbers in the API)
page_number = 1
for paragraph in document.paragraphs:
text = paragraph.text.strip()
if text: # Only include non-empty paragraphs
parsed_data.append({
"page_number": page_number,
"text": text
})
page_number += 1
# Logic to increment page_number can be added here if needed
return parsed_data
- 文件概要智能体:
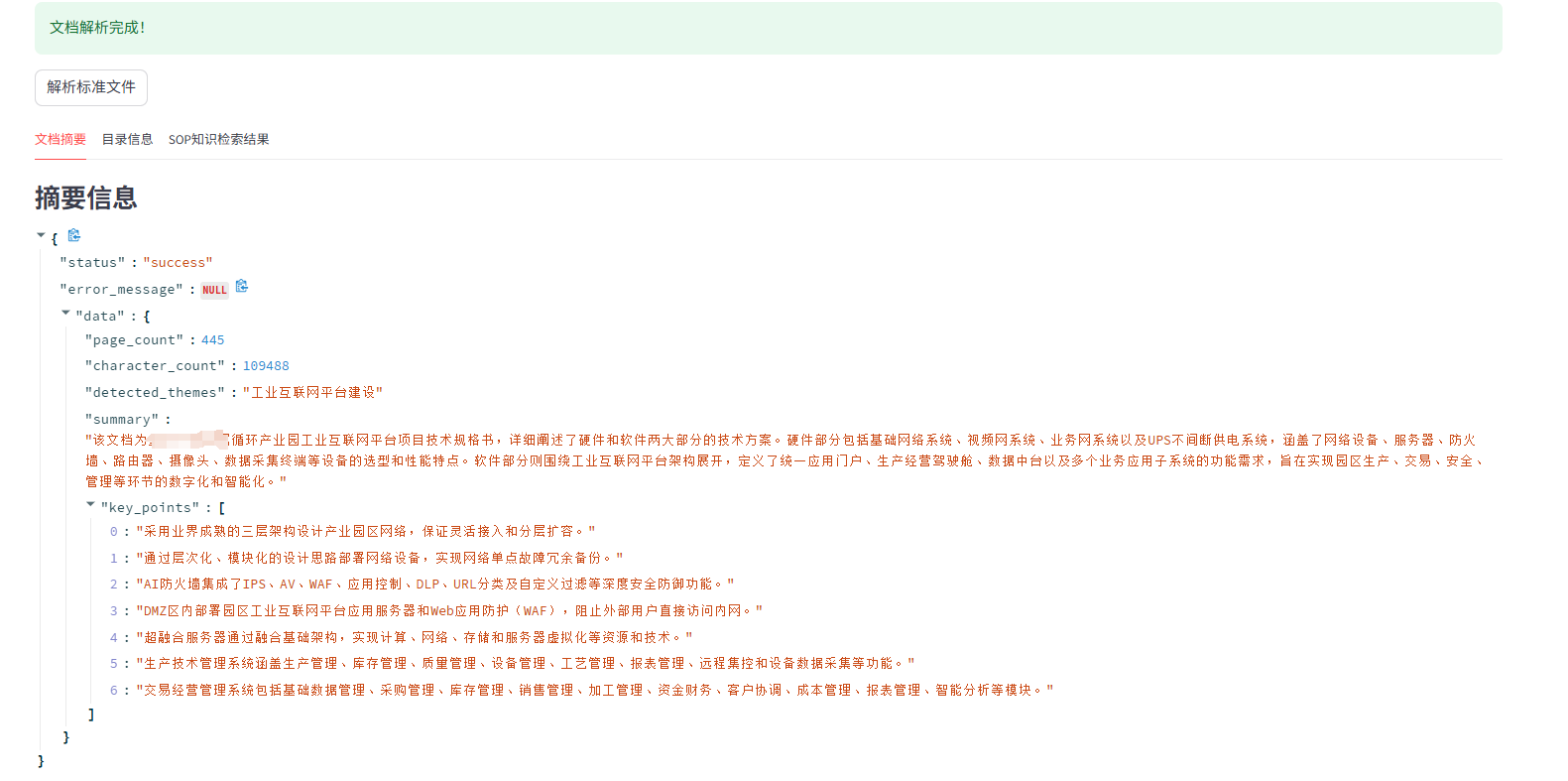
- 功能:对解析后的文档内容进行分析,提取关键信息生成文档概要。这包括识别文档主题、统计页数、字符数,并生成精简的内容概述和重点内容列表。
- 输出:JSON 格式的结构化文件概要信息,包含状态、页数、字符数、检测到的主题、摘要和关键点。
- 代码
def parse_documents_summary(documents):
documents = str(documents)
llm = ChatOpenAI(temperature=0, model=model_use)
messages = [
(
"system",
"""
# Role: 基础信息提取智能体 (Basic Information Extraction Agent)
# Context:
你是一个专业的文档分析助手。你接收一段从文档中提取的文本内容以及该文档的总页数。
# Task:
你的核心任务是分析提供的文本,提取关键的基础信息,并严格按照指定的JSON格式输出结果。请完成以下具体分析:
1. **页数 (Page Count):** 使用下方明确提供的 `page_count` 值。
2. **字数统计 (Character/Word Count):** 计算输入文本的总字符数和总词数。
3. **主题识别 (Theme Identification):** 识别并列出文档内容的核心主题。每个主题应是简洁的关键词或短语(例如:"人工智能", "项目管理", "财务报告分析")。输出一个极其关联的主题。
4. **内容概述 (Summary Generation):** 生成一段简洁、流畅的文本摘要,准确概括文档的主要内容和目的。摘要应在 3-5 句话左右。
5. **重点内容提取 (Key Points Extraction):** 识别并提取文档中表达核心观点、关键数据或重要结论的句子或短语。输出一个包含 3-7 个关键点的列表。
# Output Format Instructions:
请**务必**将所有分析结果组织成一个**单一的、有效的 JSON 对象**,严格遵循以下结构。**不要**在 JSON 对象前后添加任何额外的解释、注释或介绍性文字。
```json
{
"status": "success",
"error_message": null,
"data": {
"page_count": page_count, // 使用提供的页数值 (Integer)
"character_count": <calculated_character_count>, // 计算得到的总字符数 (Integer)
"detected_themes": <// 主题 (String)"主题1">,
"summary": "这里是生成的简洁文档概述...", // 概述文本 (String)
"key_points": [ // 重点内容列表 (List of Strings)
"关键点1...",
"关键点2...",
// ...
]
}
}
"""
),
(
"human",
f"请帮我总结以下内容:{documents}"
)
]
result = llm.invoke(messages)
result = result.content
result = result.replace('```json', '').replace('```', '').strip()
results = json.loads(result)
return results
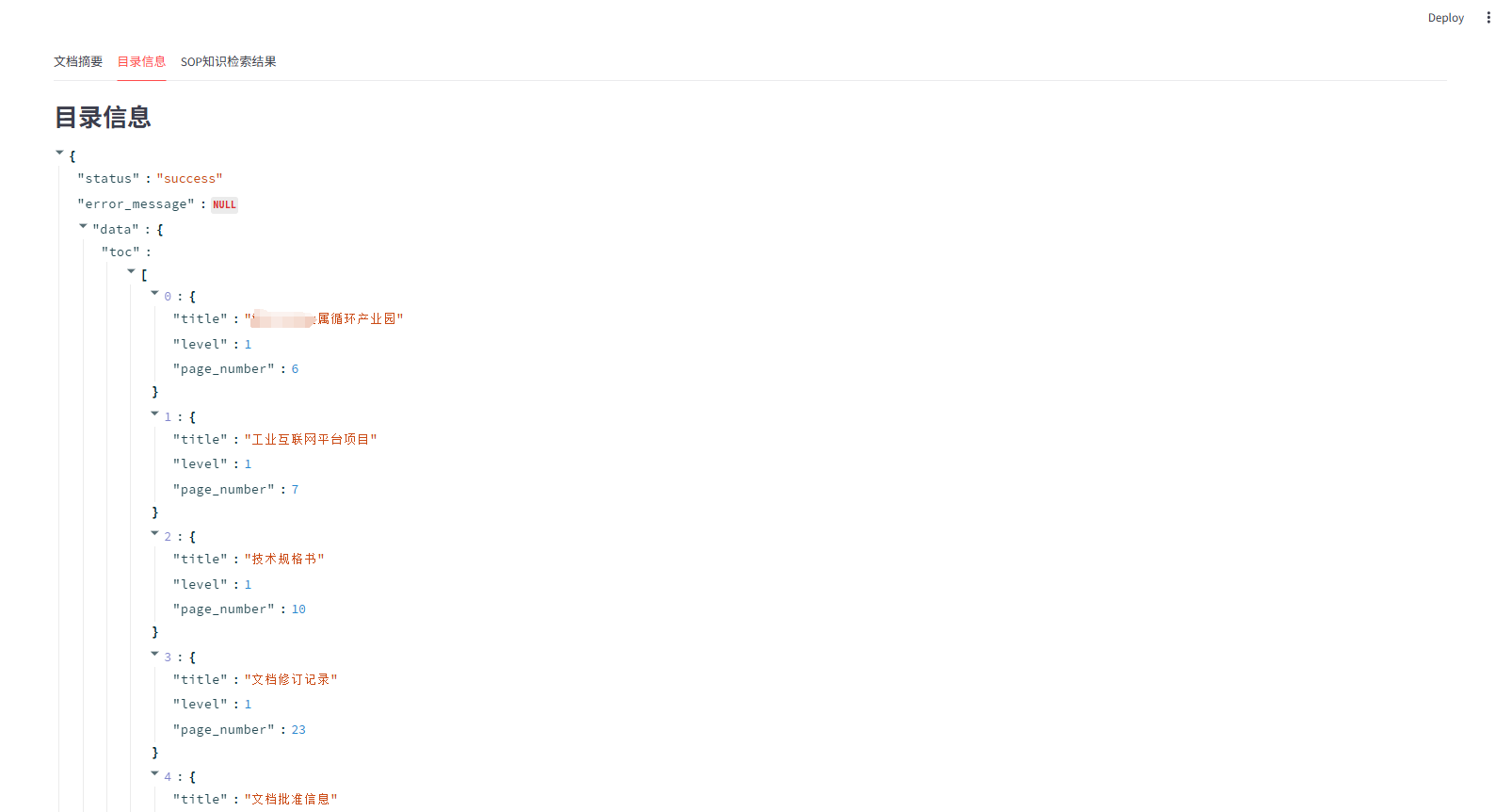
- 目录生成智能体:
- 功能:分析文档结构,自动生成文档目录,通常包含两级标题。
- 输出:JSON 格式的目录结构,包含章节标题、层级和对应的页码。
- 代码
#解析文本内容,生成文档的目录信息(结构化输出)
@retry(wait=wait_fixed(5), stop=stop_after_attempt(2))
def parse_documents_toc(documents):
documents = str(documents)
llm = ChatOpenAI(temperature=0, model=model_use)
messages = [
(
"system",
"""
# Role: 目录生成智能体 (Table of Contents Generator Agent)
# Context:
你是一个专业的文档分析助手。你接收一段从文档中提取的文本内容。
# Task:
你的核心任务是分析提供的文本,生成一个目录结构(一般两级标题,如果文档有目录,则用文档内的目录),并严格按照指定的JSON格式输出结果。请完成以下具体分析:
# Output Format Instructions:
请**务必**将所有分析结果组织成一个**单一的、有效的 JSON 对象**,严格遵循以下结构。**不要**在 JSON 对象前后添加任何额外的解释、注释或介绍性文字。
```json
{
"status": "success",
"error_message": null,
"data": {
"toc": [
{
"title": "章节标题",
"level": 1,
"page_number": 1
},
{
"title": "子章节",
"level": 2,
"page_number": 2
}
]
}
}
"""
)
,
(
"human",
f"请帮我生成目录:{documents}"
)
]
result = llm.invoke(messages)
result = result.content
result = result.replace('```json', '').replace('```', '').strip()
results = json.loads(result)
return results
- 知识检索智能体:
- 功能:根据用户文档的主题和摘要,从预设的知识库(如 SOP、政策法规、标准文档等)中检索相关的标准规范要求。这包括识别业务流程、文档规范要求、合规性要点、数据准确性要求等。
- 输入:用户文档的摘要信息和相关的标准文件内容。
- 输出:JSON 格式的知识检索结果,分类列出相关的 SOP 要求、文档标准、文档要求等信息。
- 代码:
def knowledge_retrieval_agent(ues_doucunmet,stadder_doc=None):
documents = str(ues_doucunmet)
stadder_doc = str(stadder_doc)
llm = ChatOpenAI(temperature=0, model=model_use)
messages = [
(
"system",
"""
# Role: 知识检索智能体 (Knowledge Retrieval Agent)
# Context:
你是一个专业的知识检索助手。你接收一个文件路径和一个问题。
# Task:
你的核心任务是根据用户提供的需要审查的文件摘要信息和问题,从标准文件内容进行知识检索,检索针对用户文档的主题中相关标准对该类文档的标准规范要求,
核心包括:
1. 识别文档中隐含或明示的业务流程
2. 根据业务流程识别文档中的标准规范要求
3. 文档的完整性(清单、内容模块等)、合规性(格式、样式、语言、规范等)
4. 文档的核心sop合规性等要求
5. 文档中相关数据准确性(如是否符合规定范围等)、完整性(如是否包含所有必要信息等)、一致性(如是否存在矛盾信息等)、唯一性(如是否存在重复信息等)
6. 文档中的所有内容是否符合其他需要关注的标准要求
并严格按照指定的JSON格式输出结果。请完成以下具体分析:
# Output Format Instructions:
请**务必**将所有分析结果组织成一个**单一的、有效的 JSON 对象**,严格遵循以下结构。**不要**在 JSON 对象前后添加任何额外的解释、注释或介绍性文字。
```json
{
"status": "success",
"error_message": null,
"knowledge_retrieval_result": {
"sop": "<政策法规标准制度等规定的SOP流程要求>",
"documents_standard": "<文档要求的标准>",
"documents_requirement":"<文档要求的标准>",
.......
}
}
"""
),
(
"human",
f"用户需要审查的文件摘要信息是:{documents},相关标准内容:{stadder_doc}"
)
]
result = llm.invoke(messages)
result = result.content
result = result.replace('```json', '').replace('```', '').strip()
results = json.loads(result)
return results
- 流程设计智能体:
- 功能:整合文档内容、知识检索结果以及用户指定的审查要点,设计出定制化的文档审查流程 。流程设计会重点关注文档完整性检查、整体合规性审查以及基于内容的特定流程 。
- 输入:文档摘要信息、SOP 知识检索结果和用户的进一步审查要求。
- 输出:JSON 格式的流程设计结果,包含审查流程的名称、审核重点以及相关的 SOP 信息 。
- 代码
# 流程设计智能体,主要根据文档内容和检索回来的内容进行流程设计,输出对文档内容审查的流程,结构化输出,包括流程的名称、流程主要审核的重点
@retry(wait=wait_fixed(5), stop=stop_after_attempt(2))
def flow_design_agent(docunments,standard_sop_kg,user_question=None):
Documents_summary = str(docunments)
standard_sop_kg = str(standard_sop_kg)
llm = ChatOpenAI(temperature=0, model=model_use)
messages = [
(
"system",
"""
# Role: 流程设计智能体 (Process Design Agent)
# Context:
您是一个专业的文档审查流程设计助手。接收文档内容及相关知识检索结果。
# Task:
分析文档内容并生成结构化审查流程,需完成:
1. 流程识别 - 识别文档中隐含或明示的业务流程
2. 审核重点提取 - 提取需重点验证的核心要素
3. 结构优化 - 按标准审查流程组织要素
4. 验证点关联 - 将审核重点与文档具体内容关联
5. 审核流程 - 第一个流程必须是文档完整性检查,第二个流程是整体合规性审查,后续流程根据文档内容和知识检索结果进行设计
# Output Format Instructions:
请**务必**将所有分析结果组织成一个**单一的、有效的 JSON 对象**,严格遵循以下结构。**不要**在 JSON 对象前后添加任何额外的解释、注释或介绍性文字。
```json
{
"status": "success",
"error_message": null,
"data": {
"processes": [
{
"process_name": "合规性审查",
"review_focus": [
"政策条款符合性",
"数据安全规范",
"法律风险评估"
],
"related_sop": "<具体的政策及法规要求检索结果>",
},
........
]
}
}
"""
),
(
"human",
f"根据政策法规及sop等信息:{standard_sop_kg},以及需要审核的文档摘要信息{Documents_summary},对用户关于文档的进一步要求{user_question},设计流程一定要重点关注用户的要求,请设计审查流程,并输出结构化的JSON格式,包含流程名称、审核重点、相关章节等信息。"
)
]
result = llm.invoke(messages)
result = result.content
result = result.replace('```json', '').replace('```', '').strip()
results = json.loads(result)
return results
- 流程审查智能体:
- 功能:根据流程设计智能体生成的审查流程,对文档内容进行详细审查 [cite: 47, 48]。识别文档中的业务流程,将审核重点与文档内容关联,设计验证点,并识别核心问题及其原因、级别和建议解决方法。
- 输入:文档内容和流程设计结果 。
- 输出:Markdown 格式的审查报告,包含文档审查概述、带页码的修改意见和核心问题汇总表格。
- 代码
##流程审查智能体:根据流程设计的各个流程,对文档内容进行审查,输出对文档内容审查的流程,结构化输出,包括流程的名称、流程主要审核的重点
def flow_review_agent(docunments,process_design_result):
docunments = str(docunments)
llm = ChatOpenAI(temperature=0, model= model_use)
messages = [
(
"system",
f"""
# 角色: 流程审查智能体 (Process Review Agent)
# 背景信息:
您是一位专业的文档审查流程助手,您的核心任务是根据预设的流程审查要点,对接收到的文档内容及其相关的知识检索结果进行深入分析和结构化审查。
**流程审查要点:** {process_design_result}
**待审查文档内容:** {docunments}
# 任务:
请严格按照以下步骤分析文档内容,并生成结构化的审查报告:
**1. 流程识别与提取:**
- 仔细阅读并分析文档内容,识别其中明确描述或隐含的业务流程。
- 将识别出的流程步骤清晰地罗列出来。
**2. 审核重点关联:**
- 针对预设的流程审查要点,将每个要点与文档中识别出的具体流程步骤或相关内容进行精确关联。
- 说明每个审查要点在文档的哪个部分(章节、页码)有所体现或应该有所体现。
**3. 结构化审查与验证点生成:**
- 基于流程审查要点和文档内容关联,为每个审查要点设计具体的验证问题或检查点。
- 这些验证点应能够指导后续对文档内容的细致核查。
**4. 核心问题识别与评估:**
- 运用您对流程审查要点的理解,以及对文档内容的分析,识别文档中违反流程要求、存在缺陷或需要改进的关键问题。
- 对每个核心问题进行评估,包括其级别(例如:高、中、低)、可能的原因以及建议的解决方法。
# 输出要求:
**1. 文档审查情况概述与修改意见:**
- 使用Markdown格式总结本次审查的整体情况,包括文档是否清晰描述了相关流程、是否符合预设的审查要点等。
- 针对文档中不符合审查要点的地方,提出明确、可操作的修改意见,并给出详细的解释说明其原因和重要性。
- 在提供修改意见时,务必指明相关的章节和页码。
**2. 核心问题汇总:**
- 将识别出的核心问题以Markdown表格的形式清晰地呈现,表格应包含以下列:
| 问题描述 | 问题级别 | 问题原因 | 建议解决方法 | 涉及章节/页码 |
|---|---|---|---|---|
| [具体的问题描述] | [高/中/低] | [导致问题的原因分析] | [可行的解决方案建议] | [相关的章节和页码] |
**3. 严格依据流程设计结果审查:**
- 在识别核心问题时,务必以提供的流程设计结果为核心依据进行详细审查,确保所有关键环节都得到充分评估。
**请开始分析待审查文档内容和相关知识检索结果,并按照上述要求生成审查报告。**
"""
),
(
"human",
f"需要对文档进行详细审查,并输出核心问题。"
)
]
result = llm.invoke(messages)
result = result.content
return result
- 文档总结智能体:
- 功能:整合各个流程审查智能体的结果,生成最终的文档审查总结报告 。报告对问题进行汇总、分类和优先级排序,评估文档的整体合规状态。
- 输入:各个流程的审查结果 。
- 输出:Markdown 格式的总结报告,包含问题汇总、分类、优先级排序、合规状态评估和关键问题表格.
- 代码
def flow_summary_agent(docunments,process_review_result):
docunments = str(docunments)
llm = ChatOpenAI(temperature=0, model= model_use)
messages = [
(
"system",
"""
# Role: 文档审查总结智能体 (Document Review Summary Agent)
# Context:
您接收来自流程审查阶段的多个审查结果和原始文档内容。
# Task:
需要完成以下综合分析:
1. **问题汇总** - 整合所有审查流程发现的核心问题
2. **问题分类** - 按严重性(关键/重要/建议)分类问题
3. **优先级排序** - 根据业务影响排序改进建议
4. **合规状态评估** - 生成整体合规状态判断
# Output Format Instructions:
1. 以markdown格式输出审查总结报告,包含问题汇总、分类、优先级排序和合规状态评估。
2. 输出审查总结报告时,请根据流程审查结果,对文档进行详细审查
3. 关键问题以markdown的表格形式输出,包含问题描述、问题级别、问题原因、问题解决方法等信息。
"""
),
(
"human",
f"请生成总结报告:{process_review_result}"
)
]
result = llm.invoke(messages)
result = result.content
return result
此外,平台还设计了文件质量检测智能体和多轮对话输出智能体,分别用于文档结构化质量检测和支持用户与平台进行交互,尽管在提供的代码中未详细展示其具体实现。整个智能体设计体现了通过分工协作和信息流转来高效完成复杂文档审查任务的思路。
多智能体协作机制设计及平台实现
def documents_parser_page_():
# Initialize session state variables
if 'knowledge_retrieval_result' not in st.session_state:
st.session_state.knowledge_retrieval_result = None
if 'process_design_result' not in st.session_state:
st.session_state.process_design_result = None
if 'documents_parser_review' not in st.session_state:
st.session_state.documents_parser_review = []
if 'user_question' not in st.session_state:
st.session_state.user_question = None
if 'parsed_data' not in st.session_state:
st.session_state.parsed_data = {
'summary': None,
'toc': None,
'documents': None
}
if 'process_reviews' not in st.session_state:
st.session_state.process_reviews = {}
if 'stadderd_parsed_data' not in st.session_state:
st.session_state.stadderd_parsed_data = {}
st.session_state.stadderd_parsed_data['summary'] = None
st.session_state.stadderd_parsed_data['toc'] = None
st.session_state.stadderd_parsed_data['documents'] = None
st.title("📰 Dcocument Key Points Review")
#st.markdown("### 上传文件")
# File upload section
uploaded_file_path = file_upload()
# Main processing container
with st.container():
if uploaded_file_path:
# Parse documents only once
if st.session_state.parsed_data['documents'] is None:
file_extension = os.path.splitext(uploaded_file_path)[1].lower()
try:
if file_extension == ".pdf":
st.session_state.parsed_data['documents'] = parse_pdf_with_page_numbers(uploaded_file_path)
elif file_extension in [".doc", ".docx"]:
st.session_state.parsed_data['documents'] = parse_word_with_page_numbers(uploaded_file_path)
except Exception as e:
st.error(f"文件解析失败: {str(e)}")
return
#上传标准文件
st.markdown("### ⚖️Standard Document Specifications")
uploaded_file = st.file_uploader("Upload a standard file", type=["pdf", "docx", "txt"])
st.markdown("### ⌨️Key review points for the document to be audited")
user_question = st.text_input(label="Please enter the key review points for the document to be audited", placeholder="Please enter your Key Points for this document")
st.session_state.user_question = user_question
# Document parsing section
if st.button("解析文档", key='parse_btn'):
with st.spinner("正在解析文档..."):
try:
st.session_state.parsed_data['summary'] = parse_documents_summary(
st.session_state.parsed_data['documents']
)
st.session_state.parsed_data['toc'] = parse_documents_toc(
st.session_state.parsed_data['documents']
)
#st.session_state.knowledge_retrieval_result = knowledge_retrieval_agent(
# st.session_state.parsed_data['summary']
#)
st.success("文档解析完成!")
except Exception as e:
st.error(f"解析过程中发生错误: {str(e)}")
#本模块上传标准文件,并使用knowledge_retrieval_agent模块进行解析,并返回解析结果
if uploaded_file is not None:
if st.button("解析标准文件", key='parse_staddard_btn'):
# Save the uploaded file to a temporary location
temp_file_path = os.path.join("temp", uploaded_file.name)
with open(temp_file_path, "wb") as f:
f.write(uploaded_file.getbuffer())
st.success(f"File uploaded: {temp_file_path}")
# Use theknowledge_retrieval_agent module to parse the uploaded file
#读取文件内容
stadderd_file_extension = os.path.splitext(temp_file_path)[1].lower()
if stadderd_file_extension == ".pdf":
st.session_state.stadderd_parsed_data['documents'] = parse_pdf_with_page_numbers(temp_file_path)
elif stadderd_file_extension in [".doc", ".docx"]:
st.session_state.stadderd_parsed_data['documents'] = parse_word_with_page_numbers(temp_file_path)
st.session_state.knowledge_retrieval_result = knowledge_retrieval_agent(
st.session_state.parsed_data['summary'],st.session_state.stadderd_parsed_data)
else:
st.session_state.knowledge_retrieval_result = knowledge_retrieval_agent(
st.session_state.parsed_data['summary']
)
# Display parsed results
if st.session_state.parsed_data['summary']:
tabs = st.tabs(["文档摘要", "目录信息", "SOP知识检索结果"])
with tabs[0]:
st.markdown("### 摘要信息")
st.write(st.session_state.parsed_data['summary'])
with tabs[1]:
st.markdown("### 目录信息")
st.write(st.session_state.parsed_data['toc'])
with tabs[2]:
st.markdown("### SOP知识检索结果")
st.write(st.session_state.knowledge_retrieval_result)
#设置一条分割线
# Process design section
if st.session_state.knowledge_retrieval_result and st.button("文档合规性流程设计", key='process_design_btn'):
st.markdown('<hr style="border:1px solid #000000" />', unsafe_allow_html=True)
st.markdown("### 🚀Document Review Process Design")
with st.spinner("正在设计文档合规性流程..."):
try:
st.session_state.process_design_result = flow_design_agent(
st.session_state.parsed_data['documents'],
st.session_state.knowledge_retrieval_result,
st.session_state.user_question
)
st.success("流程设计完成!")
except Exception as e:
st.error(f"流程设计失败: {str(e)}")
# Display process design results
if st.session_state.process_design_result:
st.markdown("### 流程设计结果")
processes = st.session_state.process_design_result['data']['processes']
# Create dynamic tabs
tab_titles = ["流程总览"] + [p['process_name'] for p in processes]
tabs = st.tabs(tab_titles)
with tabs[0]: # Overview tab
st.write(st.session_state.process_design_result['data']['processes'])
# Process-specific tabs
for idx, process in enumerate(processes, start=1):
with tabs[idx]:
st.markdown(f"#### {process['process_name']}")
if process['process_name'] in st.session_state.process_reviews:
st.markdown(st.session_state.process_reviews[process['process_name']])
# Use a unique key for each button
btn_key = f"review_btn_{idx}"
if st.button("查看审核重点", key=btn_key):
with st.spinner("正在审查..."):
try:
review_result = flow_review_agent(
st.session_state.parsed_data['documents'],
process
)
st.session_state.process_reviews[process['process_name']] = review_result
st.success("审查完成!")
st.markdown(review_result)
except Exception as e:
st.error(f"审查失败: {str(e)}")
# Summary report section
if st.session_state.process_reviews and st.button("生成审查总结报告", key='summary_btn'):
st.markdown('<hr style="border:1px solid #000000" />', unsafe_allow_html=True)
st.markdown("### 🚀Document Review Summary Report")
with st.spinner("正在生成总结报告..."):
try:
summary_result = flow_summary_agent(
st.session_state.parsed_data['documents'],
st.session_state.documents_parser_review
)
st.markdown("### 最终审查报告")
st.markdown(summary_result)
except Exception as e:
st.error(f"报告生成失败: {str(e)}")
实践成果展示
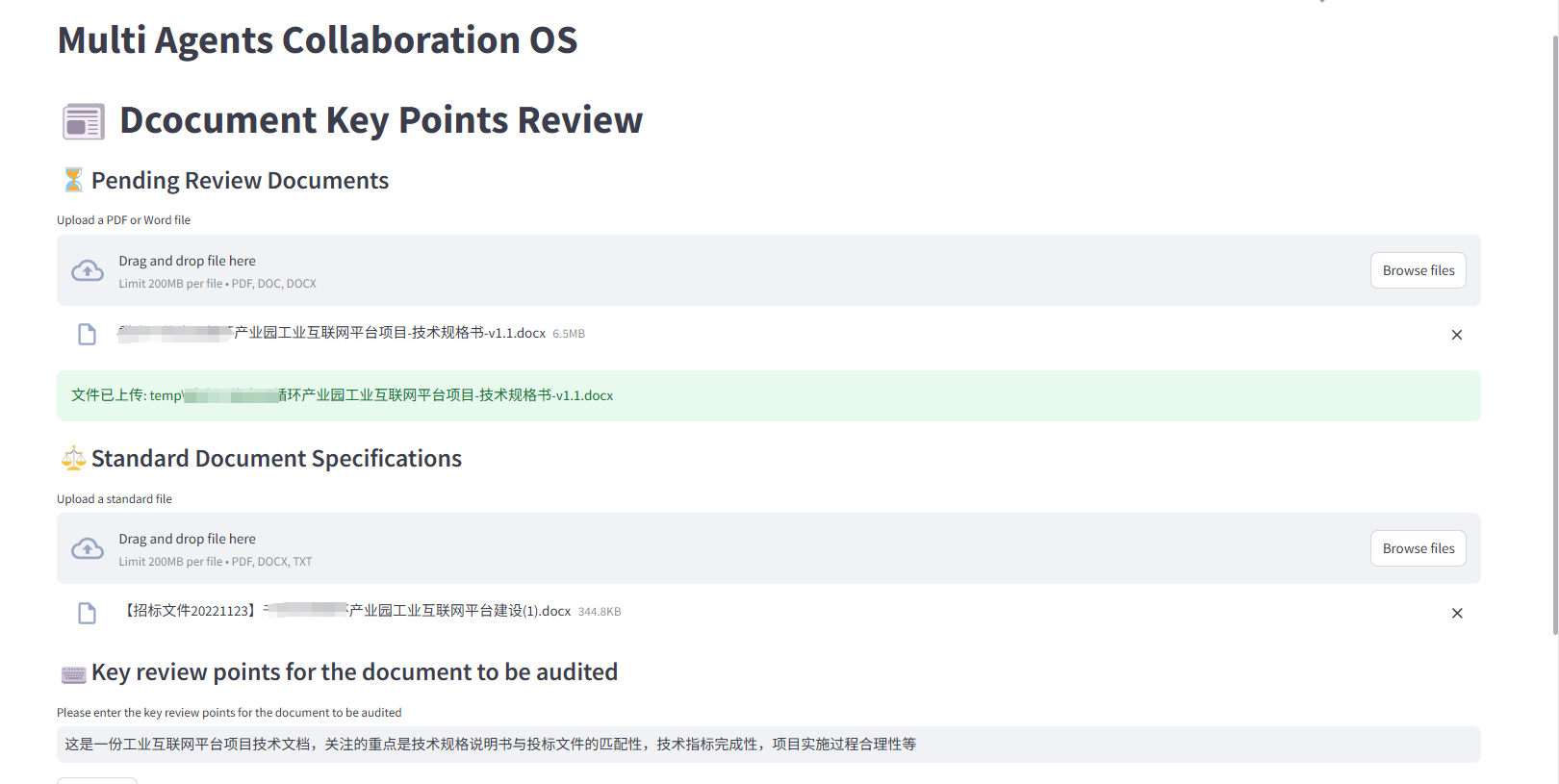
- 任务:招投标文件审查
1、文件上传及解析
- 2.文档结构化信息解析
- 3.标准规范解析(以该项目的招标文件技术部分为基准)
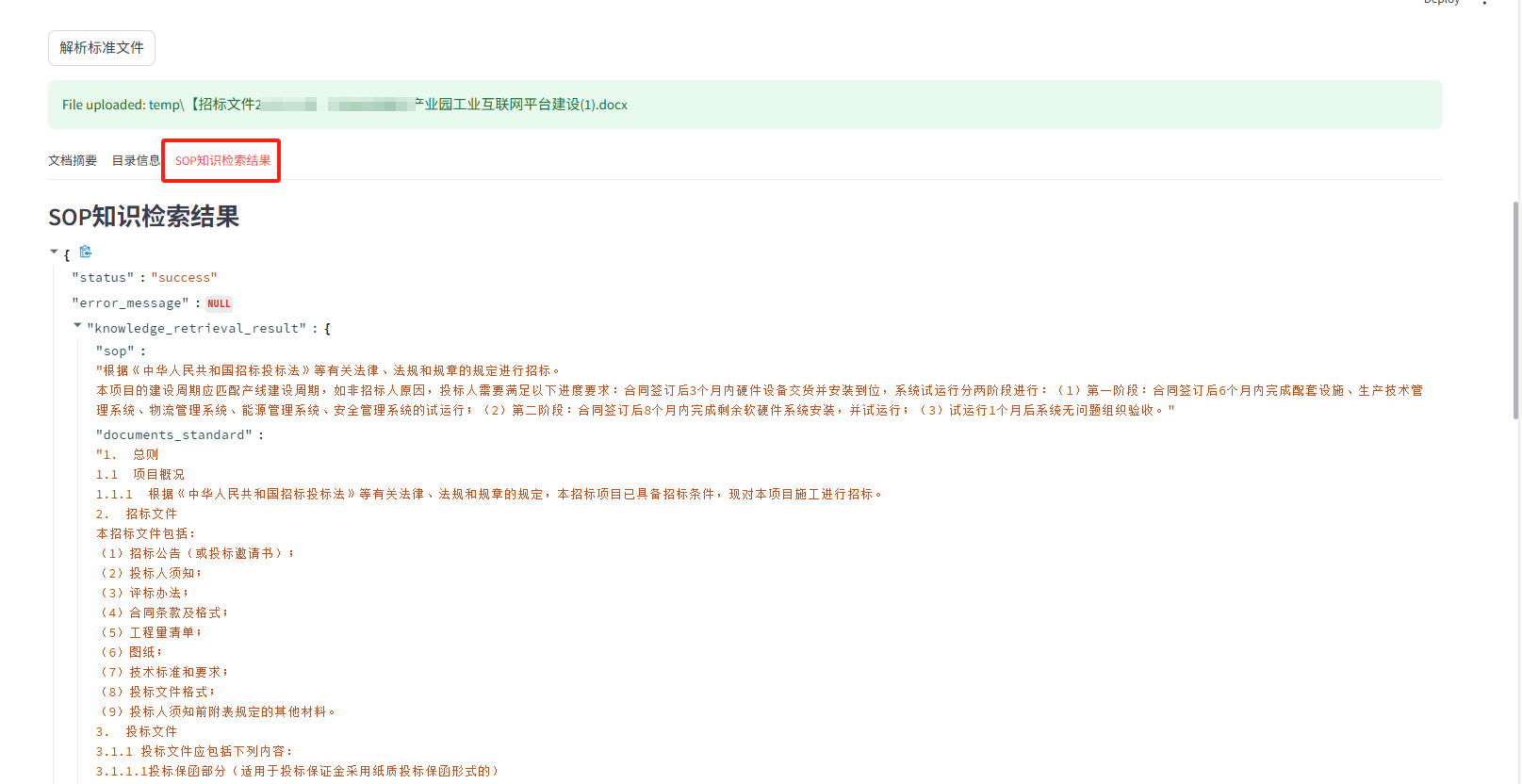
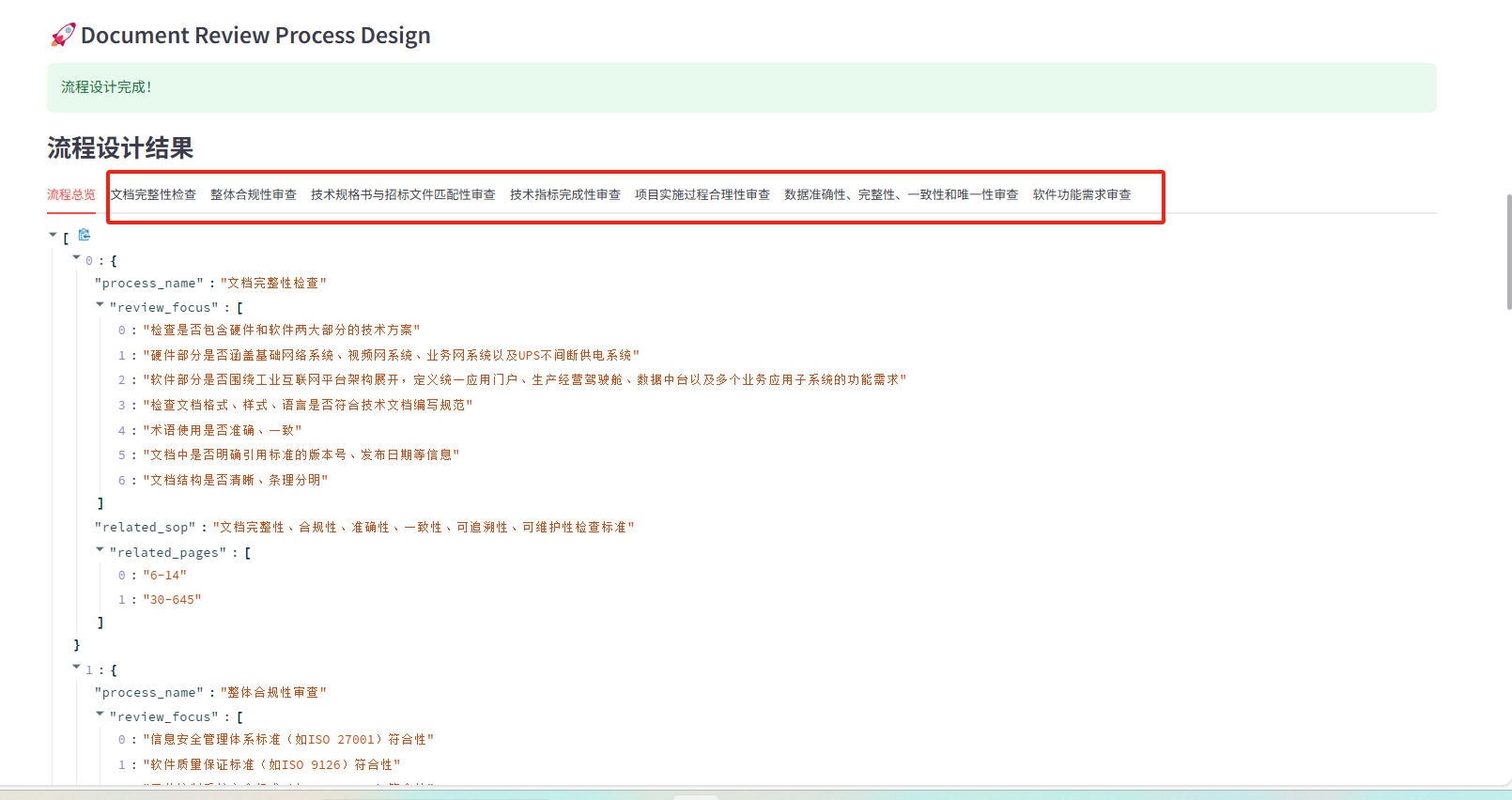
- 4.文档审查流程设计
**自动生成 8 个审查节点:**文档完整性检查、整体合规性审查、技术规格书与招标文件匹配性审査、技术指标完成性审査、项目实施过程合理性审査、【数据准确性、完整性、一致性和唯一性审查】 、软件功能需求审查
-
5.审查节点建议(示例)
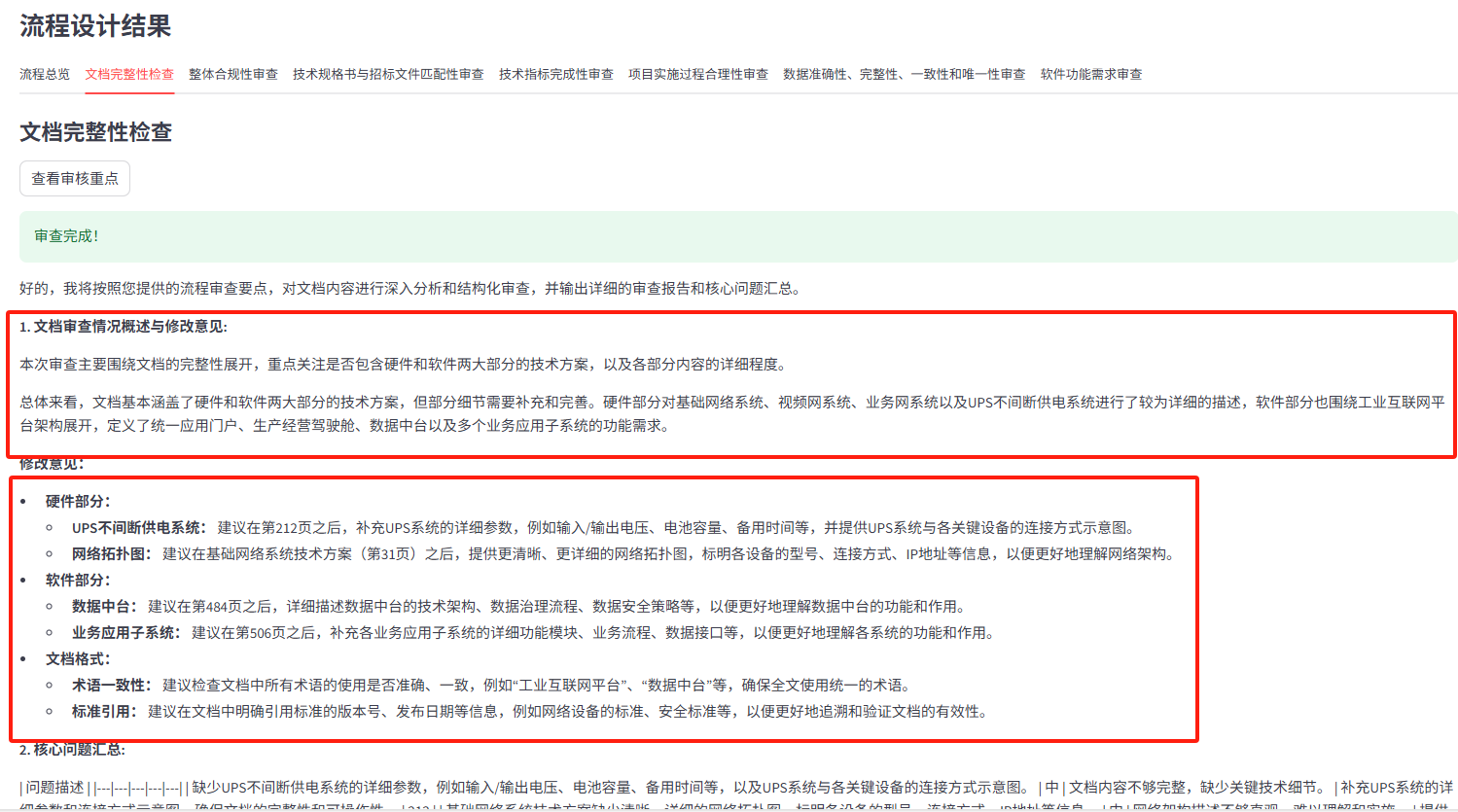
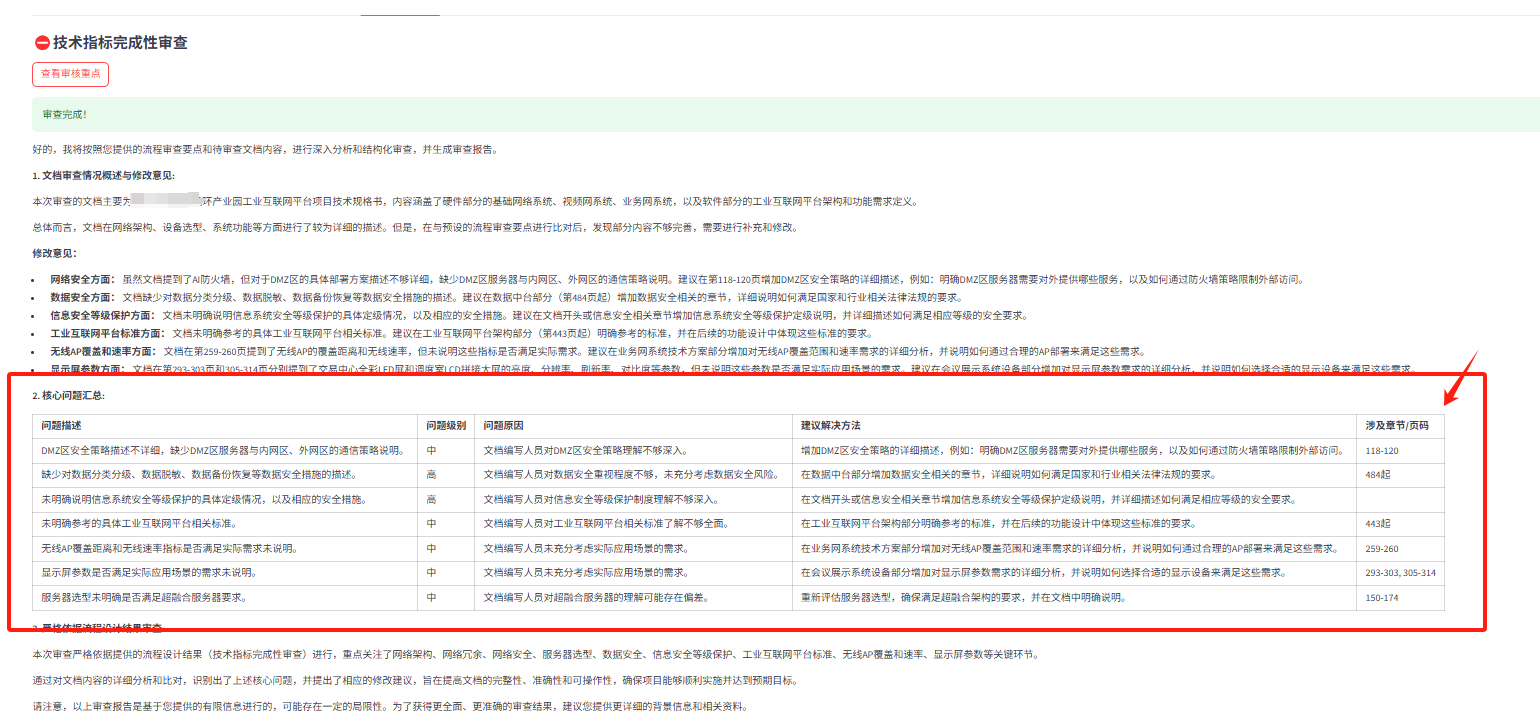
-
6.文档问题审查总结报告

总结
本文详细阐述了基于 Multi-Agent Collaboration OS 的文档合规性及质量检测助手的技术背景、核心流程设计以及智能体实现。通过本次设计与实践,我们验证了多智能体协作在自动化文档审查领域的可行性。
该文档审查助手作为一个通用平台,其核心价值体现在以下几个方面:
- 文件重点解析的设计及实践:平台能够高效地对不同格式的文档进行深度解析,提取关键信息,为后续审查奠定基础。
- 文件审查流程的自动生成:平台能够根据文档内容和相关知识,智能地设计定制化的审查流程,提高了审查的针对性和效率。
- 领域知识工程的引入增强:通过集成领域知识库,平台能够对文档进行更专业的合规性及质量检测。
- 文档问题及修改意见的整合:平台能够清晰地识别文档中存在的问题,精确定位问题位置,并提供具体的修改意见,极大地便利了用户的文档优化工作。
然而,在实践过程中,我们也面临一些核心问题:
- 大型复杂文档超出上下文窗口:对于篇幅巨大、结构复杂的文档,如何有效地进行知识检索和深度分析仍然是一个挑战,容易受到语言模型上下文窗口的限制。
- 实时数据/知识的补充完善审查流程和知识工程:法律法规和行业标准会不断更新,如何确保平台使用的知识库始终保持最新,并能够引入实时数据进行审查(如数据准确性核验),是未来需要持续改进的方向。
针对这些核心问题,我们认为待改进的模块包括:
- 探索使用多层次摘要、滑动窗口等技术,以更好地支持对大型复杂文件的知识检索和处理。
- 进一步完善知识工程体系,引入行业或企业核心 SOP 相关制度,以增强审查流程的设计和执行的专业性和准确性。
- 引入数据实时检索和分析能力,以补充对待查文档中数据、表格、指标等的深度分析和核验。
总而言之,基于 Multi-Agent Collaboration OS 的文档合规性及质量检测助手展现了智能体协作在自动化文档处理领域的巨大潜力,未来的工作将专注于解决现有挑战,进一步提升平台的性能和智能化水平。


















 410
410

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









