






一、概述
在当今数据驱动的时代,海量信息的产生与应用正以前所未有的速度增长,深刻影响着社会经济的各个方面。从金融、医疗、教育到娱乐,数据已成为推动行业创新与变革的关键要素。然而,随着数据量级的爆炸性增长,传统的数据处理与分析方法逐渐显得力不从心,难以满足日益复杂的数据需求。特别是在跨领域协同工作时,如何有效地整合与利用分散在不同系统中的异构数据,成为了亟待解决的挑战。
在之前一系列的实践过程中,我们已经借助LLM 构建的Data Multi-Agents 体系覆盖了“数据采集-数据集成-知识检索-数据清洗治理-数据分析-数据展示”全链条的数据智能体体系,通过协作平台及协作机制将各个智能体串联起来,解决数据领域的问题,是进一步提升“数据-信息-模型-知识-价值”等数据要素流转的重要抓手。
在此背景下,提出构建“数据多智能体协作平台”。该平台旨在应对大数据时代下的复杂问题,通过构建一个由众多AI Agents构成的智能体网络,实现对海量数据的高效处理与智能分析。每个Agent都具备独立思考与行动的能力,能够针对特定的数据类型与应用场景,灵活运用相应的算法与工具,实现数据的深度挖掘与价值提取。
更重要的是,这些Agent并非孤立存在,而是通过一套精心设计的协作机制紧密相连,形成了一个高度协调的智能体集群。它们能够根据任务的需要,自动组织起来,共同解决复杂问题,无论是实时数据分析、预测建模还是个性化推荐,都能游刃有余。这种基于多智能体的协作模式,不仅极大地提升了数据处理的灵活性与效率,也为数据行业的未来发展开辟了新的可能性。
同时借助大模型的代码生成能力,我们将通过“原型设计-大模型提取原型描述信息-代码大模型生成平台代码-执行”的原则从0到1,自主构建一个数据多智能体协作平台的前端系统。运用的技术有:原型设计、任务描述及优化、多模态大模型、代码模型、streamlit前端框架、数据展示框架(pyecharts、streamlit等)等。
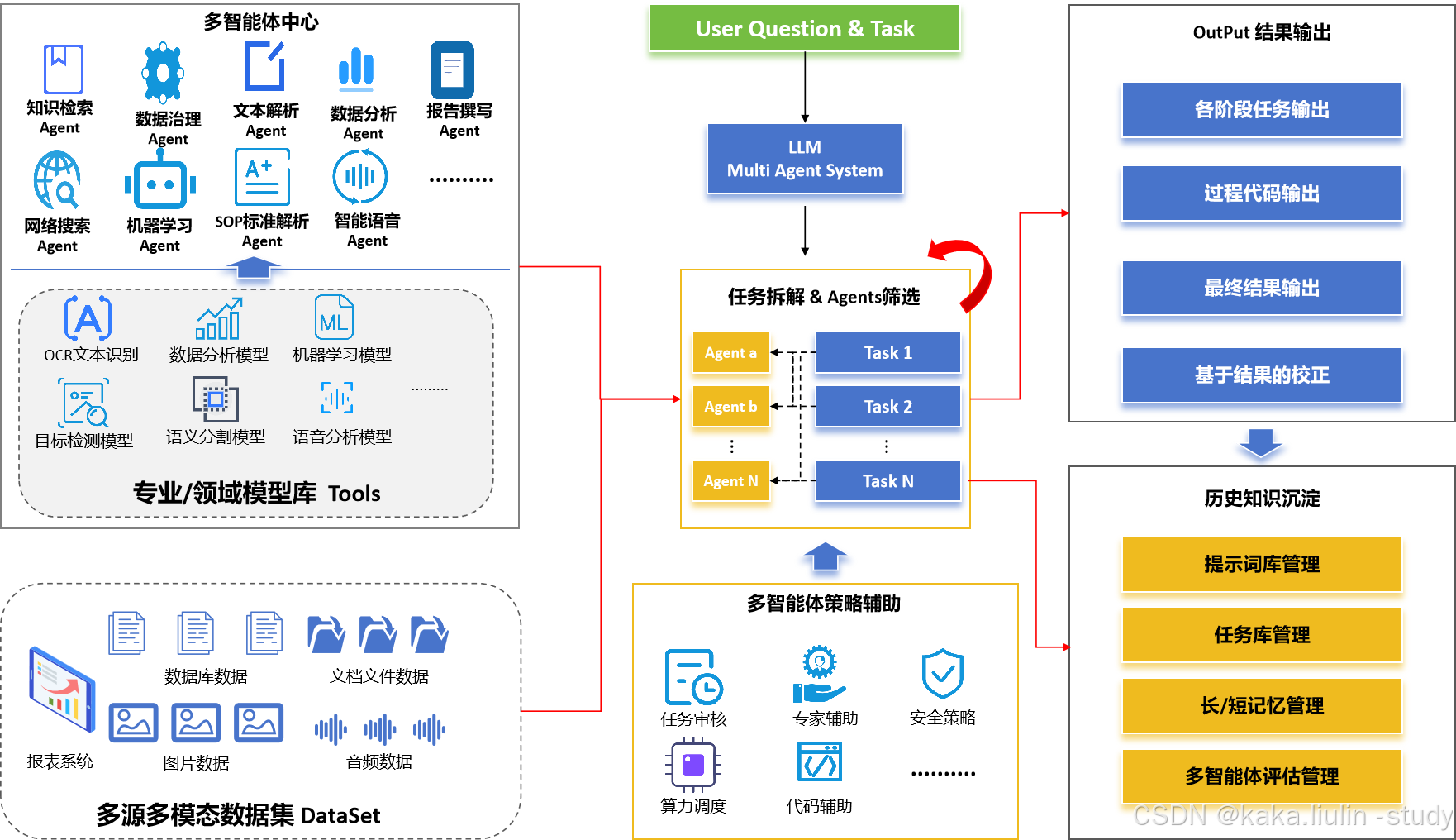
二、技术框架
数据多智能体协作平台围绕着利用大型语言模型(LLM)来编排一个多智能体系统(MAS)的原则构建,这使得我们能够采用全面的方法来回应用户的查询。这种创新设计融合了先进的数据分析与AI技术,以交付精确且富有上下文内涵的响应。
当接收到一个查询时,系统会启动任务分解流程,随后选择专门的AI智能体,这些智能体针对解决特定的子任务而定制。该多智能体系统由多样化的智能体组成,每个智能体都装备有领域特定的技能,如知识检索、数据治理和文本分析。
支撑这些智能体的是强大的领域模型,涵盖了诸如OCR文本识别和对象检测的能力,使它们能够有效地应对复杂的任务。平台的数据生态系统包含了丰富的多源多模态数据集,包括结构化数据库和非结构化文档文件,为智能处理提供了坚实的基础。
一个核心组件,即结果输出模块,负责整合来自不同阶段的输出,综合程序代码,并基于反馈循环精炼最终结果。与此相辅相成的是,历史知识积累模块管理提示词库、任务存储库以及长短期记忆系统,通过经验不断优化系统性能,确保持续改进。
多智能体策略支持模块在任务验证、专家咨询以及实施安全策略方面发挥着关键作用,保护所处理信息的完整性和安全性。通过协同智能,平台优化了解决问题的效率,展示了AI在数据管理和分析方面变革性的力量。
这一架构体现了尖端AI能力与复杂数据处理的融合,使平台处于技术创新的前沿,能够应对多面挑战,展现人工智能在数据处理领域的强大潜力。
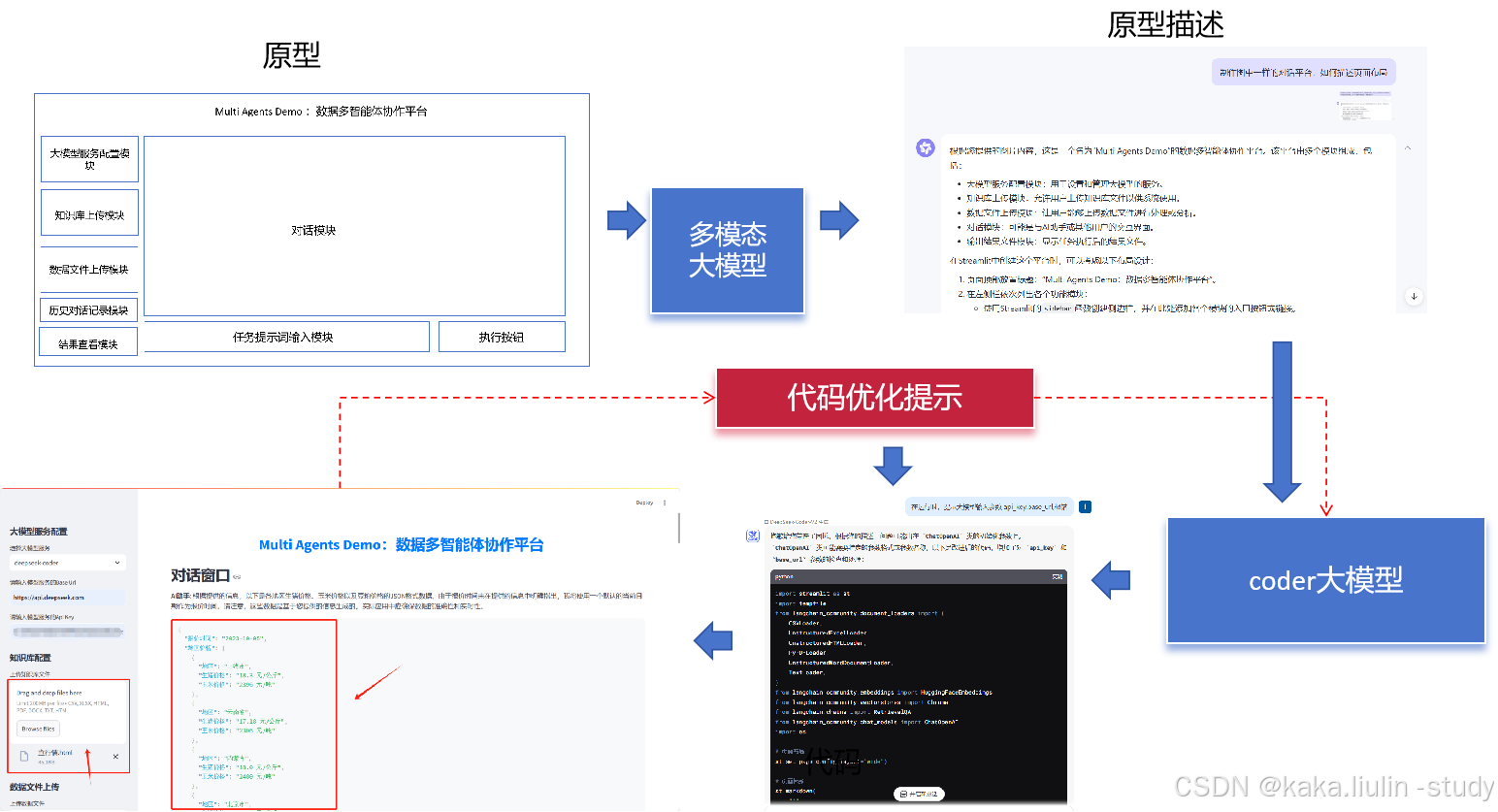
三、设计框架
随着人工智能技术的发展,越来越多的企业开始尝试将其应用于实际生产环境中。然而由于缺乏有效的工具支持,很多项目都无法顺利完成。为了解决这个问题,我们提出了这样一个解决方案——基于多模态大模型的自动化编程生成代码及构建“数据多智能体协作平台”。
流程:
1、原型设计阶段:首先明确项目的目标和需求,然后根据这些内容绘制出初步的原型图。接下来就是利用多模态大模型对其进行解析,提取其中的关键信息。
2、描述信息收集阶段:在得到原型图的基础上,我们需要进一步完善它的细节部分。比如添加注释说明每个模块的具体作用,或者给出一些示例数据供参考。
3、系统任务描述阶段:有了完整的原型图和详细的文字描述后,我们就可以开始着手准备系统任务描述文件了。这里主要涉及到两个方面的工作:一是定义好输入输出格式;二是列出所有可能遇到的情况及其对应的解决办法。
4、代码生成阶段:最后一步就是利用代码大模型将上述的所有准备工作转化为实际可用的程序代码。这个过程中可能会涉及到各种各样的语言和技术栈,但只要遵循一定的规范和标准,就能够保证最终产品的质量。
5、迭代生成阶段:根据执行的效果、报错信息、优化点等等信息,形成代码优化提示词,迭代持续优化“数据多智能体协作平台”代码,不断完善平台。
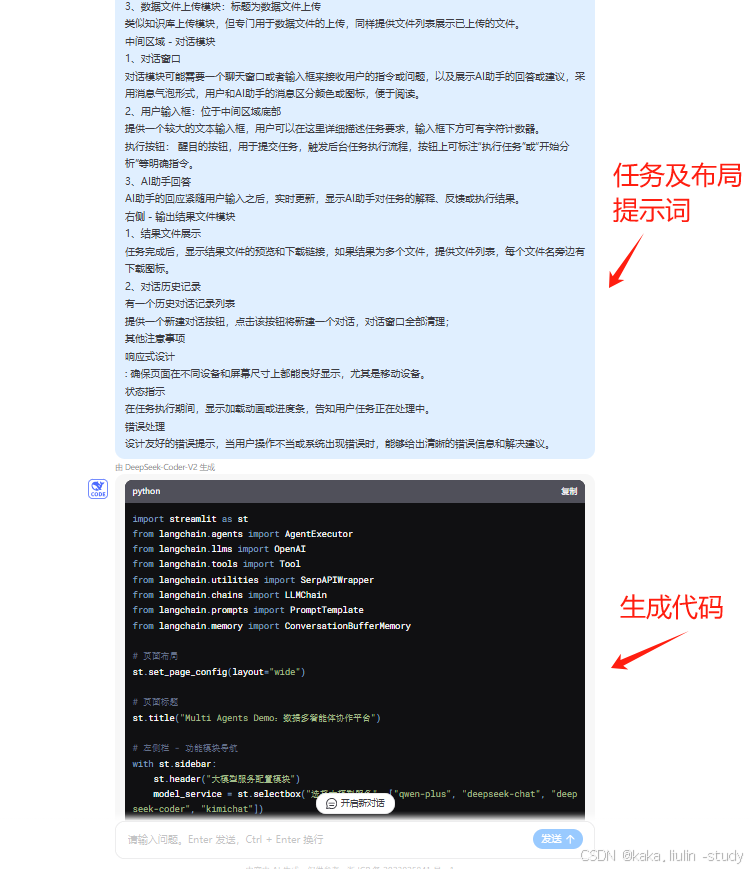
四、平台搭建
借助通义千问、deepseek等开放平台的图片描述、代码生成等能力,逐步搭建“数据多智能体协作平台”;
(一)、原型设计及原型布局描述信息获取:

(二)、任务描述信息及原型布局信息输入代码大模型生成平台的代码,本次使用streamlit框架构建平台。
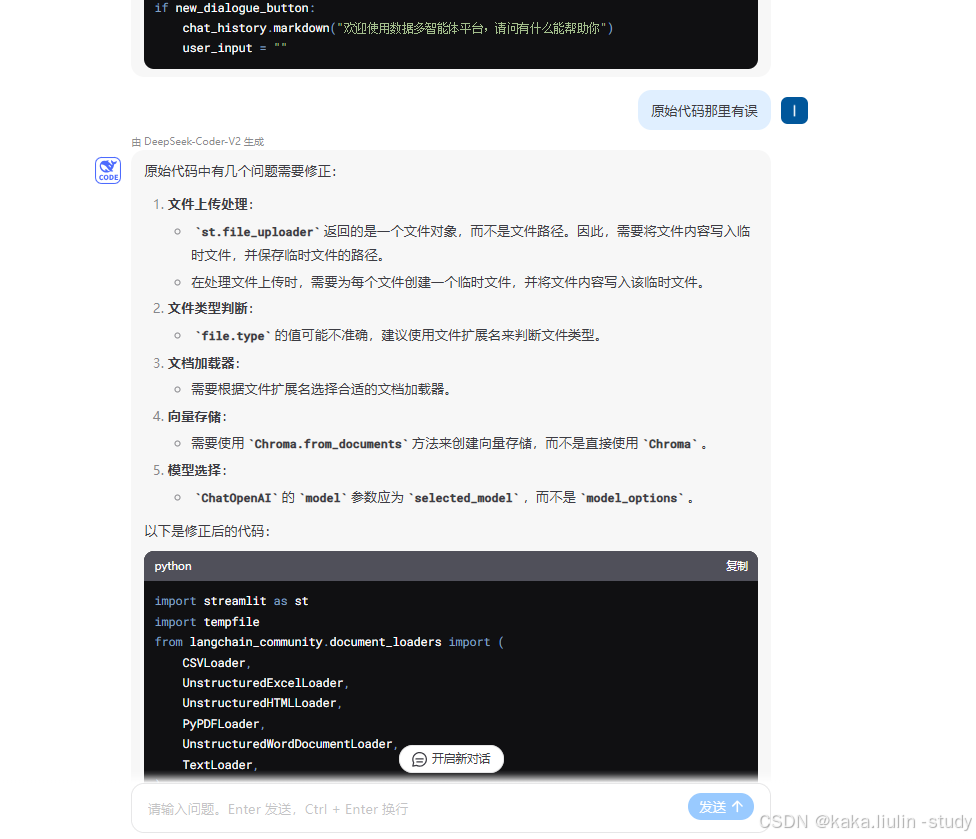
(三)、优化及迭代代码
(四)、最终的平台呈现:
streamlit run desktop/数据多智能体协作平台/rag_project.py --server.enableXsrfProtection false
五、技术实现
1、数据多智能体协作体系的构建
RAG Agent Tool:知识检索增强生成工具
构建一个检索本地知识和生成与用户问题或任务相关答案的智能体工具
# 定义文件加载器
def load_document(file_path):
_, file_extension = os.path.splitext(file_path)
if file_extension == '.docx':
loader = UnstructuredWordDocumentLoader(file_path)
elif file_extension == '.xlsx' or file_extension == '.xls':
loader = UnstructuredExcelLoader(file_path)
elif file_extension == '.csv':
loader = CSVLoader(file_path)
elif file_extension == '.html':
loader = UnstructuredHTMLLoader(file_path)
elif file_extension == '.xml':
loader = UnstructuredXMLLoader(file_path)
elif file_extension == '.pdf':
loader = PyPDFLoader(file_path)
else:
raise ValueError(f"Unsupported file type: {file_extension}")
return loader.load()
# 加载多个文档
def load_multiple_documents(file_paths):
documents = []
for file_path in file_paths:
documents.extend(load_document(file_path))
return documents
# 文本分割
text_splitter = RecursiveCharacterTextSplitter(chunk_size=10000, chunk_overlap=500)
# 加载和分割文档
file_paths = ['/content/多智能体知识库.docx','/content/成都市青白江区生物(物种)多样性.pdf']
documents = load_multiple_documents(file_paths)
split_docs = text_splitter.split_documents(documents)
# 使用Hugging Face的嵌入模型
embeddings = HuggingFaceEmbeddings(model_name="avsolatorio/GIST-small-Embedding-v0")
# 创建向量存储
vectordb = Chroma.from_documents(documents=split_docs,embedding=embeddings)
class RAGTool(BaseTool):
name = "Retrieval-Augmented-Generation"
description ='A RAG too, By retrieving relevant text, obtain knowledge\industry standards\data analysis strategies,which related to user questions, and summarize and generate answers.'
def _run(self, prompt_for_data:str)->str:
# 2. Incorporate the retriever into a question-answering chain.
system_prompt = (
"You are an assistant for question-answering tasks. "
"Use the following pieces of retrieved context to answer "
"the question. If you don't know the answer, say that you "
"don't know. Use three sentences maximum and keep the "
"answer concise."
"\n\n"
"{context}"
)
prompt = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
("human", "{input}"),
]
)
question_answer_chain = create_stuff_documents_chain(llm, prompt)
rag_chain = create_retrieval_chain(vectordb.as_retriever(), question_answer_chain)
result = rag_chain.invoke({'input':prompt_for_data})
return result['output']
Python Code Agent Tool:python代码生成及执行用于数据分析的工具
利用AutoGen构建一个生成和执行python 代码,用该工具来做数据分析
class PythonCodeTool(BaseTool):
name = "python code writer and excute for CSV,xlsx,etc"
description ="You are a tool used for data analysis of tables such as CSV, XLSX, and other spreadsheet formats."
def _run(self, prompt_for_data:str)->str:
# 创建一个本地命令行代码执行器
executor = LocalCommandLineCodeExecutor(
timeout=10, # 每次代码执行的超时时间,单位为秒
work_dir='/content/data', # 使用临时目录来存储代码文件
)
config_deepseek = {"config_list": [{"model": "deepseek-coder","base_url":"xxx","api_key":"xxx"}],"cache_seed": None}
# 创建一个配置了代码执行器的代理
code_executor_agent = ConversableAgent(
"code_executor_agent",
llm_config=False, # 关闭此代理的LLM功能
code_execution_config={"executor": executor}, # 使用本地命令行代码执行器
human_input_mode="NEVER", # 此代理始终需要人类输入,以确保安全
is_termination_msg=lambda msg: "TERMINATE" in msg["content"].lower()
)
# 代码编写代理的系统消息是指导LLM如何使用代码执行代理中的代码执行器
code_writer_system_message = """You are a helpful AI assistant.
Solve tasks using your coding and language skills.
In the following cases, suggest python code (in a python coding block) or shell script (in a sh coding block) for the user to execute.
1. When you need to collect info, use the code to output the info you need, for example, browse or search the web, download/read a file, print the content of a webpage or a file, get the current date/time, check the operating system. After sufficient info is printed and the task is ready to be solved based on your language skill, you can solve the task by yourself.
2. When you need to perform some task with code, use the code to perform the task and output the result. Finish the task smartly.
Solve the task step by step if you need to. If a plan is not provided, explain your plan first. Be clear which step uses code, and which step uses your language skill.
When using code, you must indicate the script type in the code block. The user cannot provide any other feedback or perform any other action beyond executing the code you suggest. The user can't modify your code. So do not suggest incomplete code which requires users to modify. Don't use a code block if it's not intended to be executed by the user.
If you want the user to save the code in a file before executing it, put # filename: <filename> inside the code block as the first line. Don't include multiple code blocks in one response. Do not ask users to copy and paste the result. Instead, use 'print' function for the output when relevant. Check the execution result returned by the user.
If the result indicates there is an error, fix the error and output the code again. Suggest the full code instead of partial code or code changes. If the error can't be fixed or if the task is not solved even after the code is executed successfully, analyze the problem, revisit your assumption, collect additional info you need, and think of a different approach to try.
When you find an answer, verify the answer carefully. Include verifiable evidence in your response if possible.
Reply 'TERMINATE' in the end when everything is done.
"""
# 创建一个名为code_writer_agent的代码编写代理,配置系统消息并关闭代码执行功能
code_writer_agent = ConversableAgent(
"code_writer_agent",
system_message=code_writer_system_message,
llm_config=config_deepseek, # 使用GPT-4模型
code_execution_config=False, # 关闭此代理的代码执行功能
is_termination_msg=lambda msg: "TERMINATE" in msg["content"].lower()
)
#创建数据分析的prompt模板
prompt_hub = """
When addressing a user's data analysis requirements, we can optimize the entire data analysis process into several critical steps to ensure that every phase from data preprocessing to the final result presentation is conducted efficiently and accurately:
1. Understanding and Defining the Problem (Requirements Analysis)
Please plan and execute the data analysis tasks based on the user's question {prompt_for_data}. The following data analysis tasks are optional and for reference, but more importantly, they should be tailored according to the user's specific question.
2. Data Preprocessing
1. Structuring
Data Integration: Gather all relevant data sources and convert unstructured or semi-structured data into structured format.
Data Cleaning: Check data quality, including but not limited to removing duplicates, correcting erroneous data, and handling missing values.
2. Handling Outliers and Missing Values
Outlier Detection: Use statistical methods or machine learning models to identify and manage outliers.
Missing Value Treatment: Choose a filling strategy based on business logic, such as using averages, medians, modes, or predictive filling.
3. Data Analysis
Design and execute the data analysis workflow based on the user's question. This may include:
Descriptive Analysis: Understand the basic characteristics and distribution of the data.
Exploratory Analysis: Discover potential patterns and associations through charts and statistical tests.
Predictive Analysis: Utilize historical data to forecast future trends.
Prescriptive Analysis: Provide decision recommendations based on analysis results.
4. Data Visualization
Creating Data Dashboards
Decide whether to create a data dashboard based on the user's needs and its specific style. Dashboards can be created using tools like PyEcharts or Streamlit, ensuring that the interface is intuitive, the information is clear, and the analysis results are effectively communicated.
Interactivity: Consider adding interactive features to allow users to customize views across different dimensions of data.
Visual Effects: Choose appropriate chart types, such as line graphs, bar charts, heat maps, etc., to present data in the most visually intuitive way.
Layout Design: Arrange various charts' positions and sizes rationally to ensure the overall aesthetics and readability of the dashboard.
5. Reporting and Feedback
Report Writing: Summarize analysis results, explain findings in concise language, and provide suggestions.
User Feedback: Present the analytical outcomes to the user, collect feedback, and adjust the analysis focus or methods as needed.
"""
#执行
chat_result = code_executor_agent.initiate_chat(
code_writer_agent,
message=prompt_hub+prompt_for_data,
is_termination_msg=lambda msg: "TERMINATE" in msg["content"].lower(),
summary_method="reflection_with_llm",
max_turns=6,
)
def _arun(self, prompt_for_data: str):
raise NotImplementedError("Async operation not supported yet")
@property
def is_single_input(self):
return True # Indicate that this tool accepts a single input
SQL Agent:数据库查询工具
借助langchain sql模块构建数据库查询多智能体工具
from langchain_community.utilities.sql_database import SQLDatabase
from langchain_community.agent_toolkits.sql.prompt import SQL_FUNCTIONS_SUFFIX
from langchain_core.messages import AIMessage, SystemMessage
from langchain_core.prompts.chat import (
ChatPromptTemplate,
HumanMessagePromptTemplate,
MessagesPlaceholder,
)
from langchain_community.agent_toolkits import SQLDatabaseToolkit
from langchain.agents import create_openai_tools_agent
db = SQLDatabase.from_uri("sqlite:///Chinook.db")
class SQLDatabaseTool(BaseTool):
name = "Tool_for_DataBase_analysis"
description ="""As a Data designed to facilitate the process of accessing, analyzing, and presenting data stored in one or more databases."""
def _run(self, prompt_for_sql:str)->str:
toolkit = SQLDatabaseToolkit(db=db, llm=llm)
context = toolkit.get_context()
tools = toolkit.get_tools()
messages = [
HumanMessagePromptTemplate.from_template("{input}"),
AIMessage(content=SQL_FUNCTIONS_SUFFIX),
MessagesPlaceholder(variable_name="agent_scratchpad"),
]
prompt = ChatPromptTemplate.from_messages(messages)
prompt = prompt.partial(**context)
agent = create_openai_tools_agent(llm, tools, prompt)
agent_executor = AgentExecutor(
agent=agent,
tools=toolkit.get_tools(),
verbose=True,
return_intermediate_steps=True,
)
agent = create_openai_tools_agent(llm, tools, prompt)
sql_agent_executor = AgentExecutor(
agent=agent,
tools=toolkit.get_tools(),
verbose=True,
return_intermediate_steps=True,
)
chat = agent_executor.invoke({'input':prompt_for_sql})
return chat['output']
Report Writer Agent Tool:报告撰写工具
构建一个撰写数据分析、业务流程等的报告撰写工具
class ReportTool(BaseTool):
name = "Tool_for_Data_analysis_report"
description ="""As a Data Analyst, please compose a comprehensive data report addressing the user's inquiry."""
def _run(self, prompt_for_report:str)->str:
report_summary_chain = LLMChain(
llm=llm,
prompt=PromptTemplate(
input_variables=["analysis"],
template="根据分析结果 {analysis},请提供一个简短的报告摘要。"
)
)
result = report_summary_chain.invoke({'input':prompt_for_report})
return result
2、数据多智能体协作体系构建
提示词设计
template_= """
Answer the following questions as best you can. You have access to the following tools:
{tools}
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin!
Question: {input}
Thought:{agent_scratchpad}
"""
PROMPT = PromptTemplate(
input_variables=["input", "tool_names", "tools"], template=template_
)
协作封装及工具组装
tools = [
Tool(
name = "Retrieval-Augmented-Generation",
func=RAGTool(),
description="A RAG too, By retrieving relevant text, obtain industry standards, data analysis strategies related to user questions, and summarize and generate answers."
),
Tool(
name = "Python_code_writer_and_excute_for_csv",
func=PythonCodeTool(),
description="A python code writer and excute tool used to excute code analyze the situation in the data named pig_market_data, where the data is the slaughter weight and price data of the pig market."
),
Tool(
name = "Tool_for_Data_analysis_report",
func=ReportTool(),
description="As a Data Analyst, please compose a comprehensive data report addressing the user's inquiry."
),
Tool(
name = "Tool_for_sqldata",
func=SQLDatabaseTool(),
description="Database Query and Visualization Tool"
),
]
agent = ZeroShotAgent.from_llm_and_tools(
llm=llm,
tools=tools,
prompt=PROMPT,
)
Multi_agent = AgentExecutor(agent=agent, tools=tools, max_iterations=150, handle_parsing_errors=True,early_stopping_method="generate",verbose=True,return_intermediate_steps=True)
3\数据多智能体协作平台的构建
如前述,借助多模态大模型能力和代码生成大模型能力,生成协作平台的核心代码
# -*- coding: utf-8 -*-
import streamlit as st
from langchain_community.document_loaders import (
CSVLoader,
UnstructuredExcelLoader,
UnstructuredHTMLLoader,
PyPDFLoader,
Docx2txtLoader,
UnstructuredWordDocumentLoader,
TextLoader,
PyMuPDFLoader
)
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_chroma import Chroma
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain.chains import RetrievalQA
from langchain_community.chat_models import ChatOpenAI
import os
import time
import autogen
from autogen import ConversableAgent, UserProxyAgent
import tempfile
from autogen.coding import LocalCommandLineCodeExecutor
from pyecharts.charts import Bar
from pyecharts import options as opts
import base64
from data_analysis import code_for_data_analysis
from data_analysis import auto_rag
import pandas as pd
import bs4
from langchain import hub
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
import importlib
from langchain_project import rag_chain_qa
from multi_agents import Multi_agent_invoke
# 页面布局设置
st.set_page_config(layout="wide")
# 页面标题
st.title("Multi Agents Demo:数据多智能体协作平台")
# 创建文件夹
UPLOAD_FOLDER = 'uploads'
KNOWLEDGE_FOLDER = os.path.join(UPLOAD_FOLDER, 'knowledge')
DATA_FOLDER = os.path.join(UPLOAD_FOLDER, 'data')
if not os.path.exists(KNOWLEDGE_FOLDER):
os.makedirs(KNOWLEDGE_FOLDER)
if not os.path.exists(DATA_FOLDER):
os.makedirs(DATA_FOLDER)
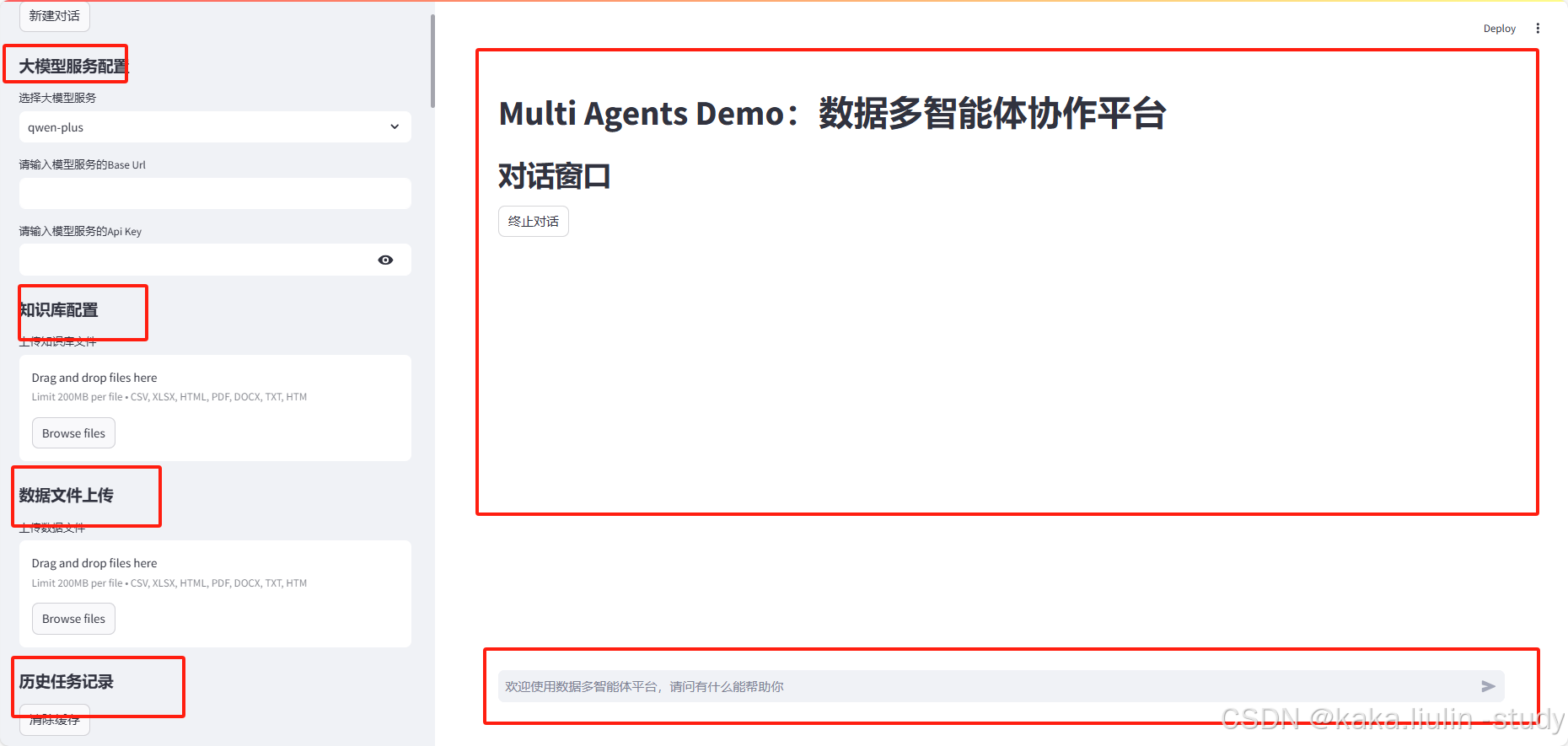
# 左侧栏 - 功能模块导航
with st.sidebar:
st.header("功能模块导航")
if st.button("新建对话"):
st.session_state.chat_history = []
st.session_state.messages = []
st.header("大模型服务配置")
model_options = ["qwen-plus", "deepseek-chat", "deepseek-coder", "kimichat"]
selected_model = st.selectbox("选择大模型服务", model_options)
base_url = st.text_input("请输入模型服务的Base Url")
api_key = st.text_input("请输入模型服务的Api Key", type="password")
st.header("知识库配置")
knowledge_files = st.file_uploader("上传知识库文件", accept_multiple_files=True, type=["csv", "xlsx", "html", "pdf", "docx", "txt"])
st.header("数据文件上传")
data_files = st.file_uploader("上传数据文件", accept_multiple_files=True, type=["csv", "xlsx", "html", "pdf", "docx", "txt"])
st.header("历史任务记录")
if "history" not in st.session_state:
st.session_state.history = []
for task in st.session_state.history:
task_display = task[:10] + "..." if len(task) > 10 else task
col1, col2 = st.columns([5, 1])
with col1:
st.markdown(f"**{task_display}**")
with col2:
if st.button("❌", key=f"delete_{task}"):
st.session_state.history.remove(task)
st.experimental_rerun()
if st.button("清除缓存"):
st.session_state.chat_history = []
st.session_state.messages = []
st.session_state.history = []
st.experimental_rerun()
# 加载文件并处理
def load_and_process_files(files, folder):
documents = []
for file in files:
try:
file_path = os.path.join(folder, file.name)
with open(file_path, "wb") as f:
f.write(file.read())
loader = get_loader(file, file_path)
if loader:
documents.extend(loader.load())
else:
st.warning(f"不支持的文件类型: {file.type}")
except Exception as e:
st.error(f"加载文件时出错: {e}")
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100000, chunk_overlap=1000)
docs = text_splitter.split_documents(documents)
# 调试输出
if not docs:
st.warning("没有文档被加载或分割。")
embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-mpnet-base-v2")
try:
db = Chroma.from_documents(docs, embeddings, persist_directory="./chroma_db")
except Exception as e:
st.error(f"创建 Chroma 数据库时出错: {e}")
db = None
return db
def get_loader(file, file_path):
if file.type == "text/csv":
return CSVLoader(file_path)
elif file.type == "application/vnd.ms-excel":
return UnstructuredExcelLoader(file_path)
elif file.type == "application/vnd.openxmlformats-officedocument.spreadsheetml.sheet":
return UnstructuredExcelLoader(file_path) # 添加对 .xlsx 文件的支持
elif file.type == "text/html":
return UnstructuredHTMLLoader(file_path)
elif file.type == "application/pdf":
return PyPDFLoader(file_path)
elif file.type == "application/vnd.openxmlformats-officedocument.wordprocessingml.document":
return Docx2txtLoader(file_path)
elif file.type == "text/plain":
return TextLoader(file_path)
else:
return None
# 初始化 knowledge_db 和 data_db
knowledge_db = None
data_db = None
# 处理知识库文件
if knowledge_files:
knowledge_db = load_and_process_files(knowledge_files, KNOWLEDGE_FOLDER)
# 处理数据文件
if data_files:
data_db = load_and_process_files(data_files, DATA_FOLDER)
# 中间区域 - 对话模块
st.header("对话窗口")
if "messages" not in st.session_state:
st.session_state.messages = []
for message in st.session_state.messages:
with st.chat_message(message["role"], avatar=message["avatar"]):
st.markdown(message["content"])
# 数据分析工作配置
config_deepseek = {"config_list": [{"model": selected_model,"base_url":base_url,"api_key":api_key}],"cache_seed": None}
work_dir = DATA_FOLDER
file_path = []
# 用户输入框
qa = None
qa_for_data = None
if prompt := st.chat_input("欢迎使用数据多智能体平台,请问有什么能帮助你"):
st.session_state.messages.append({"role": "user", "content": prompt, "avatar": "🐱"})
with st.chat_message("user", avatar="🐱"):
st.markdown(prompt)
with st.chat_message("assistant", avatar="🤖"):
message_placeholder = st.empty()
with st.spinner("AI助手正在生成回答..."):
llm = ChatOpenAI(model=selected_model, openai_api_key=api_key, openai_api_base=base_url)
if knowledge_db and data_db :
response_run = Multi_agent_invoke(llm,knowledge_db,work_dir,prompt)
response = response_run['output']
else:
response = "请先上传文件。"
message_placeholder.markdown(response)
st.session_state.messages.append({"role": "assistant", "content": response, "avatar": "🤖"})
st.session_state.history.append(prompt)
message_placeholder.markdown(response)
st.session_state.messages.append({"role": "assistant", "content": response, "avatar": "🤖"})
st.session_state.history.append(prompt)
# 终止对话按钮
if st.button("终止对话"):
st.session_state.messages = []
# 左侧栏 - 结果浏览
with st.sidebar:
st.header("结果浏览")
file_types = ["所有类型", "csv", "xlsx", "html", "pdf", "docx", "txt", "png", "jpg", "jpeg", "py"]
selected_file_type = st.selectbox("筛选文件类型", file_types)
sort_order = st.selectbox("排序方式", ["升序", "降序"])
generated_files = os.listdir(DATA_FOLDER)
file_info_list = []
for file in generated_files:
file_path = os.path.join(DATA_FOLDER, file)
file_info = (file, time.strftime('%Y-%m-%d %H:%M', time.localtime(os.path.getmtime(file_path))), file_path)
file_info_list.append(file_info)
# 根据文件类型和排序方式筛选和排序文件
if sort_order == "升序":
file_info_list.sort(key=lambda x: x[1])
else:
file_info_list.sort(key=lambda x: x[1], reverse=True)
for file, _, file_path in file_info_list:
if selected_file_type == "所有类型" or file.endswith(selected_file_type):
file_info = f"{file} (生成时间: {time.strftime('%Y-%m-%d %H:%M', time.localtime(os.path.getmtime(file_path)))}"
if st.button(file_info):
st.session_state.current_page = file
st.session_state.previous_page = "sidebar"
st.experimental_rerun()
if "current_page" in st.session_state and st.session_state.current_page == file:
st.markdown(f'<p style="color:white; background-color:blue; padding:0.5em; border-radius:0.5em;">{file_info}</p>', unsafe_allow_html=True)
else:
st.markdown(f'<p style="padding:0.5em;">{file_info}</p>', unsafe_allow_html=True)
# 检查是否有需要显示的页面
if "current_page" in st.session_state and st.session_state.current_page is not None:
file_path = os.path.join(DATA_FOLDER, st.session_state.current_page)
with open(file_path, "r", encoding="utf-8") as f:
file_content = f.read()
if file_path.endswith('.html'):
if "pyecharts" in file_content:
st.components.v1.html(file_content, width=800, height=600)
else:
st.write(file_content)
elif file_path.endswith('.py'):
if "streamlit" in file_content:
spec = importlib.util.spec_from_file_location("module.name", file_path)
module = importlib.util.module_from_spec(spec)
spec.loader.exec_module(module)
if hasattr(module, 'run'):
module.run()
else:
st.error(f"文件 {st.session_state.current_page} 中没有找到 'run' 函数。")
else:
st.code(file_content, language="python")
# 添加返回按钮
if st.button("返回"):
st.session_state.current_page = None
st.session_state.previous_page = None
st.experimental_rerun()
def display_chart(data):
bar = (
Bar()
.add_xaxis(data["x"])
.add_yaxis("数据", data["y"])
.set_global_opts(title_opts=opts.TitleOpts(title="数据分析结果"))
)
return bar.render_embed()
# 在对话窗口输出最终结果时显示生成的图表
if "chart_data" in st.session_state:
st.components.v1.html(display_chart(st.session_state.chart_data), height=500)
六、平台实践
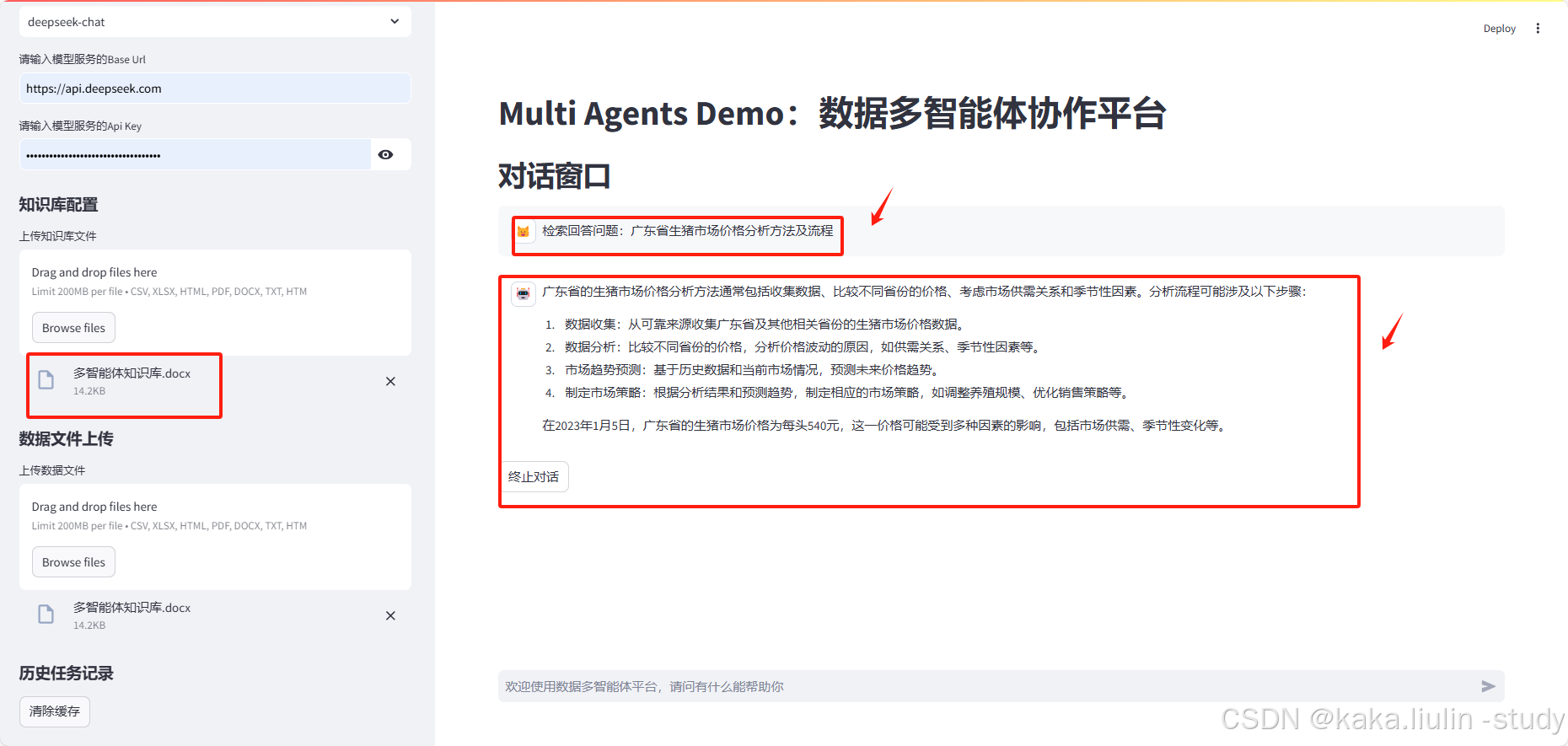
任务一:单任务,知识检索生成
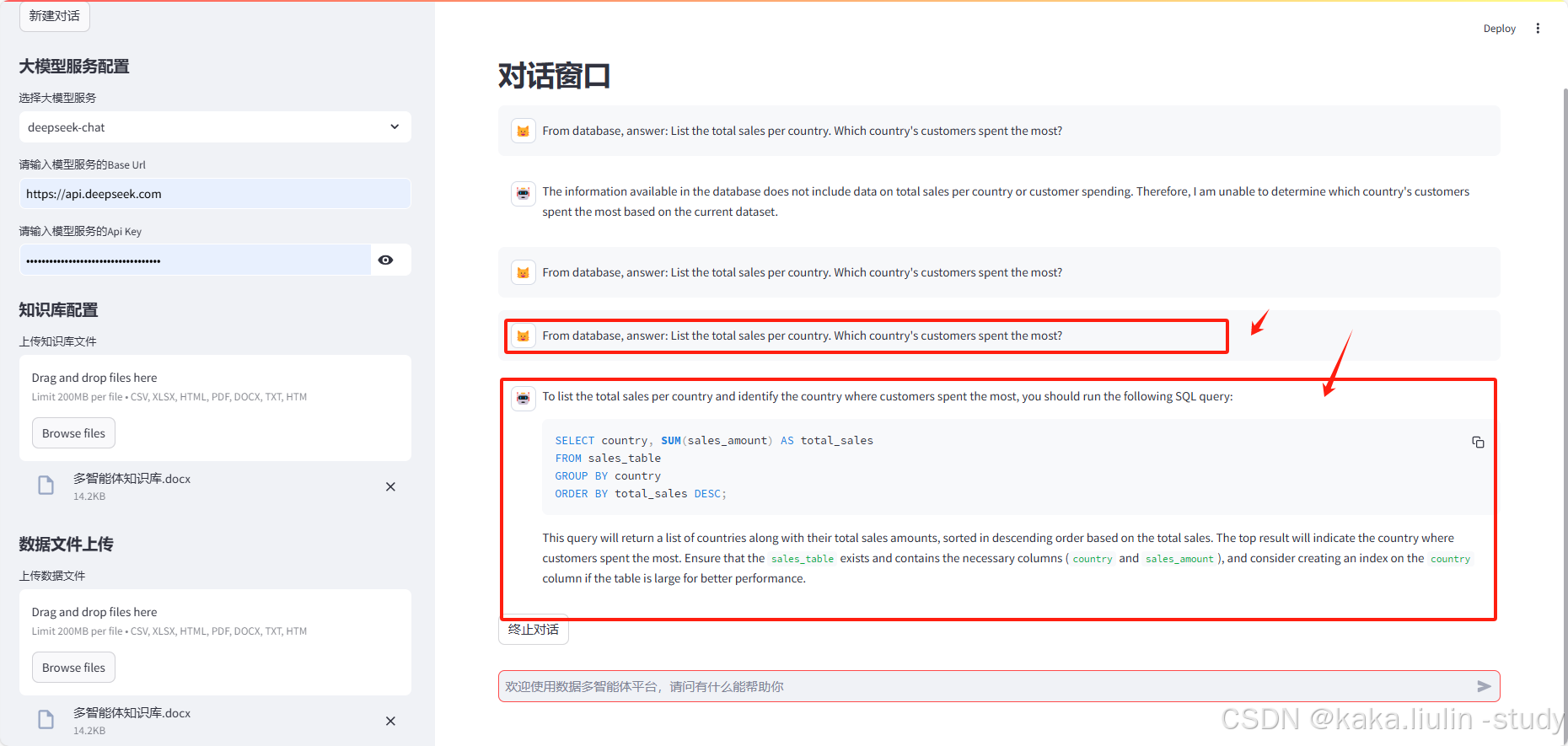
任务二:单任务,数据库查询
公共数据库:sqlite:///Chinook.db
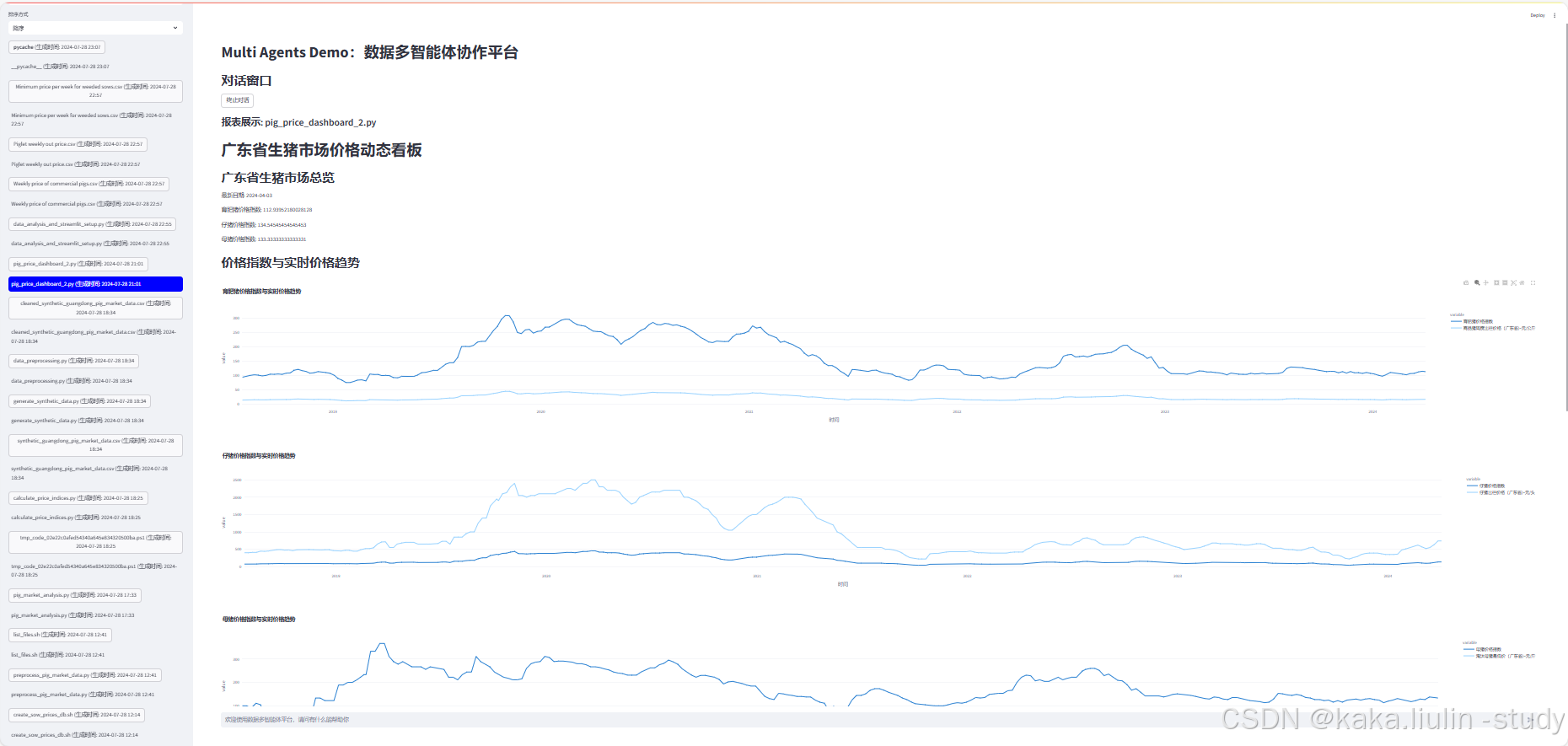
任务三:多任务协作,数据分析
<我们想要使用Streamlit 库创建一个数据看板,用于展示和分析广东省生猪市场的价格动态,保存数据看板为py文件。 一、数据获取与清洗: 1、从数据文件上传文件夹中获取广东省生猪市场的实时数据,包括育肥猪、仔猪和母猪的价格信息。 -具体而言,我们需要关注以下几类数据,其中包含了广东省生猪市场价格数据: 全国母猪市场价格数据:Minimum price per week for weeded sows.csv ; 全国仔猪市场价格数据:Piglet weekly out price.csv; 全国育肥猪价格数据:Weekly price of commercial pigs.csv; 2、清洗数据,确保其准确无误且格式一致。 -计算价格指数: 1、基于获取的实时价格,计算育肥猪、仔猪和母猪 的价格指数。价格指数可以通过标准化当前价格与基期价格的比例来计算 2、计算过程中,请确保考虑到数据的时间序列性质,选择最早日期作为基期。 二、数据保存: 1、将 计算出的价格指数以及对应的实时价格数据保存到一个CSV文件中。CSV文件应包含日期、育肥猪价格指数、育肥猪实时价格、仔猪价格指数、仔猪实时价格、母猪价格指数、母猪实时价格等字段。 三、数据可视化: 1、使用Streamlit 库、Plotly 库:创建一个综合看板,利用Streamlit 库、Plotly 库的图表功能,展示各类猪只的价格指数与实时价格 变化。保存数据看板为py文件。确保每个包含Streamlit代码的Python文件都有一个名为run的函数来运行Streamlit应用。 2、看板布局: 顶部:广东省生猪市场总览,显示最新日期的平均价格指数。 中部: 第二个模块:两个独立的折线图,母猪价格指数折线图,母猪实时价格趋势图 第三个模块:两个独立的柱状图,仔猪价格指数折线图, 仔猪实时价格趋势图 第四个模块:两个独立的折线图,育肥猪价格指数折线图,育肥猪实时价格趋势图 第五个模块:两个独立的双折线图,母猪与仔猪价格指数对比折线图,母猪与育肥猪价格指数对比折线图 底部:数据表格,列出具体日期的价格指数与实时价格,便于查阅。 3、图表样式: 折线图:清晰标注日期轴,区分价格指数与实时价格的两条折线,使用不同的颜色和标记点。 颜色方案:采用温和而对比明显的颜色组合,如深蓝与亮橙,便于区分不同类别。 图例与标题:确保每个图表都有清晰的标题和图例,标注价格指数与实时价格的含义。 4、交互性与美观性 交互设计:允许用户通过下拉菜单或滑块选择不同的日期范围,动态更新图表与表格中的数据。 响应式设计:确保看板在不同设备上(桌面、平板、手机)都能良好显示,适应屏幕尺寸自动调整布局。 视觉美观:整体设计简洁明快,避免过多装饰,确保数据呈现为主。>
—生成的代码:
[外链图片转存中…(img-z2eotXI1-1722180669567)]
——生成的数据看板
七、总结
1、大模型选型问题:经过本系列【数据多智能体协作平台】的构建和测试实践,当前国内的大模型在面对复杂任务、多文件处理以及多流程协作方面与GPT存在一定的差距;自我构建的开源大模型服务受制于硬件在多轮对话、任务迭代等表现上依然不如人意;在智能体构建及测试上、智能体协作构建及测试上,大模型的选型应该遵循“GPT系列测试验证想法——>大厂大模型在线服务测试调整——>开源大模型测试及应用效果微调”的路径。
2、多智能体协作问题:多智能体的协作机制和体系的构建重点有两方面,①智能体的构建,在智能体的构建过程中需要对智能体的功能和工作流程做比较详细的描述,使得在协作过程中能够精准的调用到适用的智能体解决问题;②协作体系的构建一个是依赖提示词的精准性,需要描述智能体的任务、多智能体迭代优化的流程等,另一个是面对复杂的任务可能需要借助langgraph等可做流程定制和节点控制的框架进行优化。
3、平台构建及扩展问题:平台的构建完全可以借助代码大模型的代码生成能力,对于报错信息、页面布局优化、细节优化等可以将源代码分块交给大模型进行优化处理;平台的扩展还需要再知识库构建、数据文件库管理、数据库管理上进行完善。
4、信息系统的未来设想:【LLM 构建Data Multi-Agents 赋能数据分析平台的实践】这个系列,我们从多种大模型嵌入、数据采集、数据治理、数据分析、数据展示及平台构建等流程的构建进行了设想、概念设计、系统设计及实践;为大模型在数据分析平台中的应用做了大量的探索。可以想见的未来,数据分析平台在大模型的加持下,将发生模式的变革,数据价值的挖掘可能朝着所见即所得迈进,数据分析师的工作将重新回归到数据模型的建立上,数据模型可以作为工具智能体嵌入到整个协作体系内,数据的采集、清洗、数据智能体的调用、数据展示变得更加简单而自动化。


















 542
542

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









