







雪花算法
概念
雪花算法是一个分布式id生成算法,它生成的id一般情况下具有唯一性。由64位01数字组成,第一位是符号位,始终为0。接下来的41位是时间戳字段,根据当前时间生成。然后中间的10位表示机房id+机器id,也可以是单独的机器id。最后12位是序列号。

优点和不足
优点:
全局唯一: 雪花算法生成的 ID 是全局唯一的,即使在分布式系统中也能保证 ID 的唯一性。
有序: 雪花算法生成的 ID 是有序的,可以根据时间戳进行排序。
高效: 雪花算法的生成速度非常快,可以满足高并发场景的需求。
缺点:
依赖时间: 雪花算法依赖时间戳,如果系统时间出现问题,可能会导致 ID 重复。
解决方案
百度的UidGenerator:Java实现, 基于Snowflake算法的唯一ID生成器。
- UidGenerator 会在生成 ID 之前对时间戳进行校验,确保时间戳是递增的。
- 如果发现时间戳出现回拨,则会抛出异常,拒绝生成 ID。
代码示例
public class SnowFlake {
// 数据中心(机房) id
private long datacenterId;
// 机器ID
private long workerId;
// 同一时间的序列
private long sequence;
public SnowFlake(long workerId, long datacenterId) {
this(workerId, datacenterId, 0);
}
public SnowFlake(long workerId, long datacenterId, long sequence) {
// 合法判断
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));
}
System.out.printf("worker starting. timestamp left shift %d, datacenter id bits %d, worker id bits %d, sequence bits %d, workerid %d",
timestampLeftShift, datacenterIdBits, workerIdBits, sequenceBits, workerId);
this.workerId = workerId;
this.datacenterId = datacenterId;
this.sequence = sequence;
}
// 开始时间戳(2021-10-16 22:03:32)
private long twepoch = 1634393012000L;
// 机房号,的ID所占的位数 5个bit 最大:11111(2进制)--> 31(10进制)
private long datacenterIdBits = 5L;
// 机器ID所占的位数 5个bit 最大:11111(2进制)--> 31(10进制)
private long workerIdBits = 5L;
// 5 bit最多只能有31个数字,就是说机器id最多只能是32以内
private long maxWorkerId = -1L ^ (-1L << workerIdBits);
// 5 bit最多只能有31个数字,机房id最多只能是32以内
private long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
// 同一时间的序列所占的位数 12个bit 111111111111 = 4095 最多就是同一毫秒生成4096个
private long sequenceBits = 12L;
// workerId的偏移量
private long workerIdShift = sequenceBits;
// datacenterId的偏移量
private long datacenterIdShift = sequenceBits + workerIdBits;
// timestampLeft的偏移量
private long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
// 序列号掩码 4095 (0b111111111111=0xfff=4095)
// 用于序号的与运算,保证序号最大值在0-4095之间
private long sequenceMask = -1L ^ (-1L << sequenceBits);
// 最近一次时间戳
private long lastTimestamp = -1L;
// 获取机器ID
public long getWorkerId() {
return workerId;
}
// 获取机房ID
public long getDatacenterId() {
return datacenterId;
}
// 获取最新一次获取的时间戳
public long getLastTimestamp() {
return lastTimestamp;
}
// 获取下一个随机的ID
public synchronized long nextId() {
// 获取当前时间戳,单位毫秒
long timestamp = timeGen();
if (timestamp < lastTimestamp) {
System.err.printf("clock is moving backwards. Rejecting requests until %d.", lastTimestamp);
throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds",
lastTimestamp - timestamp));
}
// 去重
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
// sequence序列大于4095
if (sequence == 0) {
// 调用到下一个时间戳的方法
timestamp = tilNextMillis(lastTimestamp);
}
} else {
// 如果是当前时间的第一次获取,那么就置为0
sequence = 0;
}
// 记录上一次的时间戳
lastTimestamp = timestamp;
// 偏移计算
return ((timestamp - twepoch) << timestampLeftShift) |
(datacenterId << datacenterIdShift) |
(workerId << workerIdShift) |
sequence;
}
private long tilNextMillis(long lastTimestamp) {
// 获取最新时间戳
long timestamp = timeGen();
// 如果发现最新的时间戳小于或者等于序列号已经超4095的那个时间戳
while (timestamp <= lastTimestamp) {
// 不符合则继续
timestamp = timeGen();
}
return timestamp;
}
private long timeGen() {
return System.currentTimeMillis();
}
public static void main(String[] args) {
SnowFlake worker = new SnowFlake(1, 1);
long timer = System.currentTimeMillis();
for (int i = 0; i < 10000; i++) {
worker.nextId();
}
System.out.println(System.currentTimeMillis());
System.out.println(System.currentTimeMillis() - timer);
}
}
UUID
UUID是一个128位(16字节)长度的标识符,通常以 36 个字符的字符串形式表示。能够在分布式系统中生成全局唯一标识。它可以实现基于随机数生成,不依赖于时间戳或其他信息。
优点与不足
优点
- 全局唯一
- 随机无序
不足
- 1、占用更多的存储空间uuid 是一个 128 位的二进制数,通常以 36 个字符的字符串形式表示,占用了很多的存储空间,比一般的整数型主键要大得多。这会增加数据库的磁盘占用,降低查询效率,影响性能。
- 2、主键是包含索引的,然后mysql的索引是通过b+树来实现的,每一次新的UUID数据的插入,为了查询的优化,都会对索引底层的b+树进行修改,因为UUID数据是无序的。所以每一次UUID数据的插入都会对主键地的b+树进行很大的修改,这一点很不好。 插入完全无序,不但会导致一些中间节点产生分裂。
举例:
假设一个 B+ 树的叶子节点可以存储 10 个数据。
如果使用自增 ID 作为主键,插入数据的顺序是 1、2、3、4、5…,那么叶子节点的填充率会比较均匀,页分裂的次数会比较少。
如果使用 UUID 作为主键,插入数据的顺序可能是 10、5、1、7、3…,那么叶子节点的填充率会比较不均匀,一些叶子节点可能很快被填满,而另一些叶子节点可能仍然很空,页分裂的次数会比较多。
两种算法的比较
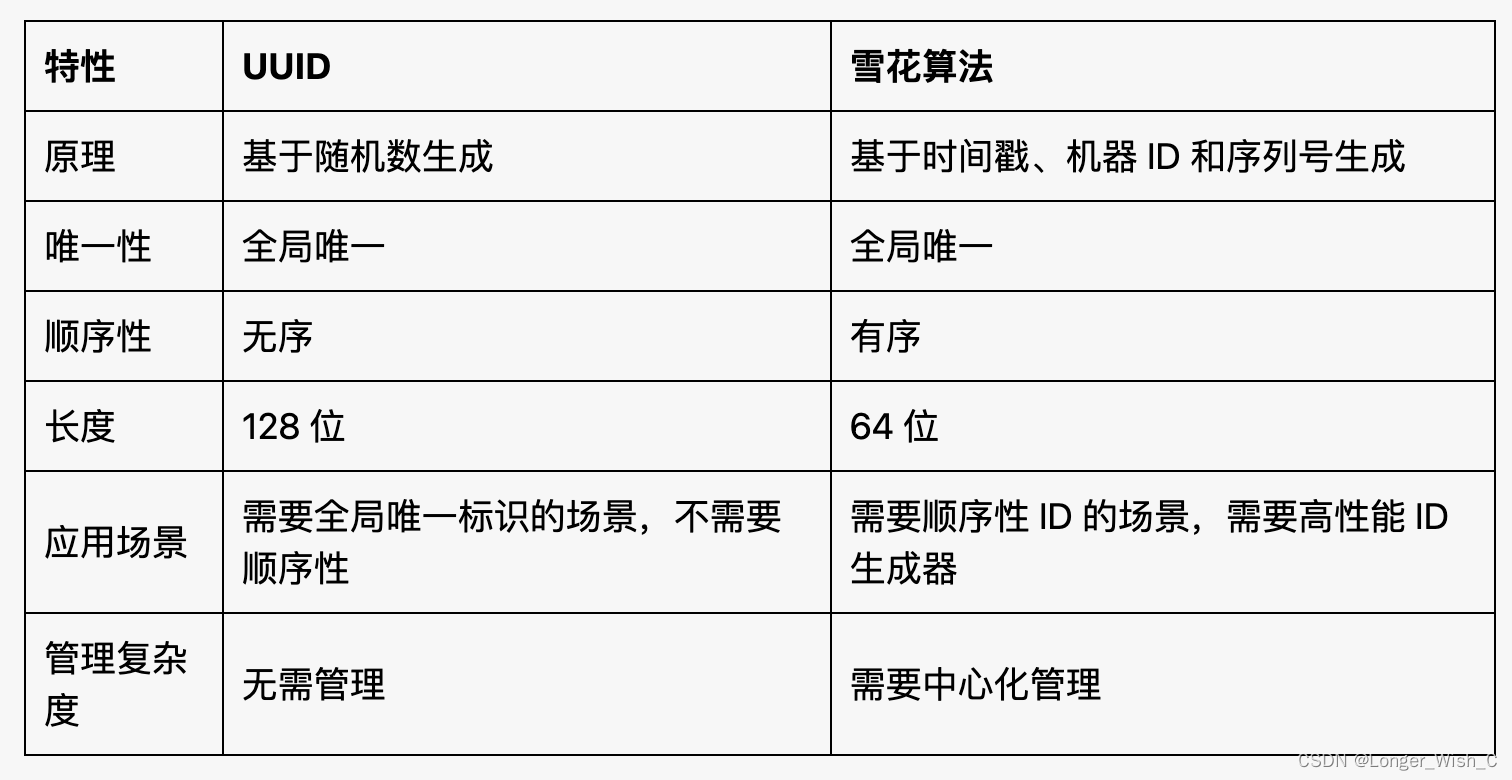
应用场景区别
UUID 更适合需要全局唯一标识,但不需要顺序性的场景,例如数据库记录、文件、用户等。
雪花算法 更适合需要顺序性 ID,并且需要高性能 ID 生成器的场景,例如消息队列、订单号、流水号等。
















 815
815

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









