








论文下载链接:https://arxiv.org/pdf/2202.08791.pdf
代码链接:https://github.com/OpenNLPLab/cosFormer
1. 动机
Transformer 在自然语言处理、计算机视觉和音频处理方面取得了巨大的成功。作为其核心组件之一,softmax 注意力有助于捕获长程依赖关系,但由于序列长度的二次空间和时间复杂度,从而禁止其扩展。为了降低计算复杂度,通常采用核(Kernel)方法通过逼近 softmax 算子来降低复杂度。然而,由于近似误差的存在,它们在不同任务/语料库中的性能存在差异,与普通的softmax注意力相比,其性能出现了下降。
作者认为softmax算子似乎是主要的障碍,而高效而准确地逼近softmax是很难实现的,一个问题自然出现了:我们能否用一个线性函数代替softmax算子,同时保持其关键属性?
2. 方法

本文提出cosFormer的线性变压器,其核心是将不可分解的非线性softmax操作替换为带有可分解的非线性重加权机制的线性操作。该模型既适用于随机注意力,也适用于交叉注意力,且输入序列长度具有线性时间和空间复杂度,因此对长期依赖关系的建模能力较强。
- Transformer的一般形式
给定一个长度为N的输入序列 x x x,我们首先将其表示在特征维度为d的嵌入空间 x ∈ R N × d x\in R^{N\times d} x∈RN×d中。因此,可以将输入为 x x x的一个Transformer block T : R N × d → R N × d \mathcal{T} :R^{N\times d}\rightarrow R^{N\times d} T:RN×d→RN×d定义为:

其中 F \mathcal{F} F为包含残差连接的前馈网络; A \mathcal{A} A是计算注意矩阵A的自注意函数,注意矩阵A对N具有二次空间和时间复杂度,因此成为 T \mathcal{T} T在长输入时的计算瓶颈。
而 A \mathcal{A} A有三个重要组件,分别为 q u e r y Q query\ {Q} query Q, k e y K key\ K key K和 v a l u e V value\ V value V,他们是经过三个可学习的线性矩阵 W Q W_Q WQ, W K W_K WK, W V W_V WV计算获得,即
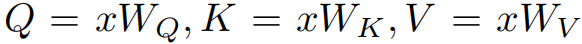
则 A ( x ) \mathcal{A(x)} A(x)的输出 O ∈ R N × d \mathcal{O}\in R^{N \times d} O∈RN×d可计算为:
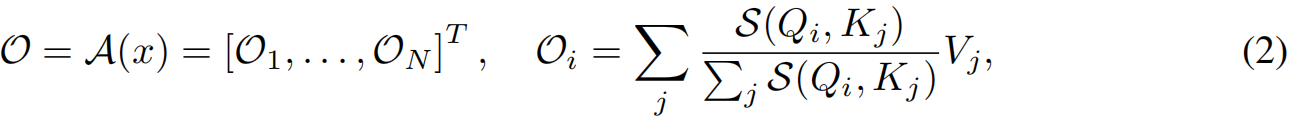
其中 S ( ⋅ ) \mathcal{S(\cdot)} S(⋅)度量query之间的相似性。如果 S ( Q , K ) = e x p ( Q K T ) \mathcal{S}(Q,K)=exp(QK^T) S(Q,K)=exp(QKT),则公式(2)通过softmax归一化成为点积attention。在这种情况下,计算每一行的输出 Q i {Q_i} Qi的空间和时间复杂度为 O ( N ) O(N) O(N)。因此,计算 O O O的总空间和时间复杂度随输入长度呈二次增长。 - self-attention的线性化
根据公式(2),我们可以选择任何相似函数来计算注意力矩阵。为了保持线性计算预算,一种解决方法是采用一个可分解的相似函数,即:

其中 ϕ \phi ϕ是一个内核函数,它将query和key映射到它们的隐藏表示。然后可以将公式(2)写成核函数的形式:

然后,通过矩阵积的性质,实现线性复杂度下的注意运算:
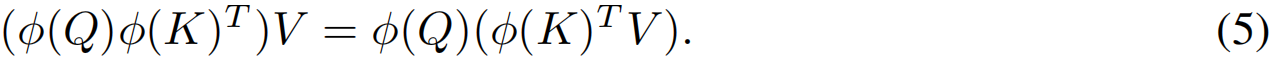
在这种形式(公式(5))中,替代了显式地计算注意矩阵 A = Q K T ∈ R N × N A=QK^T\in R^{N \times N} A=QKT∈RN×N,作者先计算 ϕ ( K ) T V ∈ R d × d \phi(K)^TV\in R^{d \times d} ϕ(K)TV∈Rd×d,然后乘以 ϕ ( Q ) ∈ R N × d \phi(Q)\in R^{N \times d} ϕ(Q)∈RN×d。通过使用这种方法,我们只引入了 O ( N d 2 ) O(Nd^2) O(Nd2)的计算复杂度。

注意:在典型的自然语言任务中,一个head d d d的特征维度总是比输入序列长度N小得多( d ≪ N d\ll N d≪N)。因此,可以省略 d d d,实现 O ( N ) O(N) O(N)的计算复杂度。如上图2所示。 - softmax注意力分析
通过实验确定了softmax操作的两个关键属性,它们可能对其性能起重要作用:
1)确保attention矩阵A中的所有值都是非负的;
2)提供了一种非线性重加权机制来集中注意力连接的分布,稳定训练

为了验证假设,对于公式(3)中 ϕ \phi ϕ函数进行三种实例化:
1) identify映射 ϕ I = I \phi_I=I ϕI=I,它不能保留非负性;
2) ϕ R e L U = R e L U ( ⋅ ) \phi_{ReLU}=ReLU(\cdot) ϕReLU=ReLU(⋅),它只保留输入正值而将负值替换为零;
3) ϕ L e a k y R e L U = L e a k y R e L U ( ⋅ ) \phi_{LeakyReLU}=LeakyReLU(\cdot) ϕLeakyReLU=LeakyReLU(⋅),它也没有非负性,但具有与ReLU相同的非线性;
由表1可得,对比 ϕ I \phi_I ϕI, ϕ L e a k y R e L U \phi_{LeakyReLU} ϕLeakyReLU和 ϕ R e L U \phi_{ReLU} ϕReLU结果证明了在相似度矩阵中只保留正的值,模型忽略了负相关的特征,能有效地避免了聚集不相关的上下文信息。通过比较 ϕ R e L U \phi_{ReLU} ϕReLU和softmax的结果,我们发现采用softmax重新加权的模型收敛更快,对下游任务有更好的泛化能力。这可以解释为softmax标准化放大了相关对,这对于识别有用的模式可能很有用。 - cosFormer
该模型完全抛弃了softmax归一化,但仍然具有非负性和重加权机制。cosFormer由两个主要部分组成:线性映射核 ϕ l i n e a r \phi_{linear} ϕlinear和基于cos的重加权机制。
1)线性映射核 ϕ l i n e a r \phi_{linear} ϕlinear
回想一下公式(2)注意力的一般形式,让我们将线性相似度定义为:
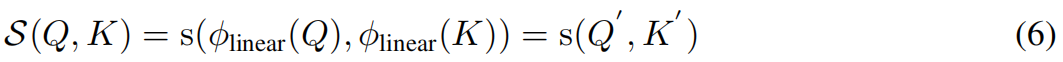
其中, ϕ l i n e a r \phi_{linear} ϕlinear是将查询 Q Q Q和键 K K K映射到我们期望的表示形式 Q ′ Q' Q′和 K ′ K' K′的变换函数, s s s是可线性分解的函数,用于度量 Q ′ Q' Q′和 K ′ K' K′之间的相似性。
具体来说,为了保证矩阵A全正值和避免聚合负相关信息,我们采用ReLU(·)作为转换函数,从而有效地消除了负值:

由于 Q ′ Q' Q′和 K ′ K' K′只包含非负值,我们直接取它们的点积 s ( x , y ) = x y T , x , y ∈ R 1 × d s(x, y) = xy^T, x, y \in R^{1 \times d} s(x,y)=xyT,x,y∈R1×d,然后按行归一化来计算注意力矩阵 这 里 有 点 疑 惑 , 怎 么 公 式 中 又 突 然 出 现 了 f ( , ) ? 不 应 该 是 s ( , ) 末 ! ! ! \textcolor{blue}{这里有点疑惑,怎么公式中又突然出现了f(,)?不应该是s(,)末!!!} 这里有点疑惑,怎么公式中又突然出现了f(,)?不应该是s(,)末!!!😵😵):
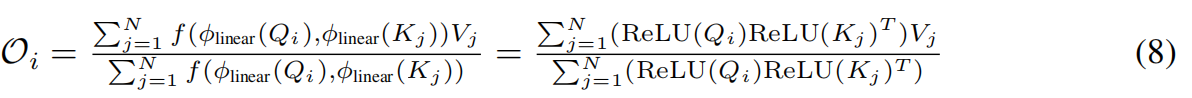
基于公式(4),重新排列点积的顺序,得到线性复杂度下的被提出的注意表达式:
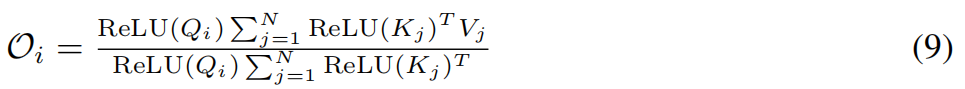
2)基于cos的重加权机制

softmax注意力引入的非线性重权机制可以集中注意力权重的分布,从而稳定训练过程。作者还发现,在某些情况下,它可以惩罚远端连接,并加强局部性。事实上,这种局部性偏差,即很大一部分上下文依赖来自邻近的标记,通常在下游的NLP任务中观察到,如上图3(1)所示。
基于上述假设,需要一种可分解的重加权机制来满足softmax的第二个性质,该机制可以引入最近偏差到注意力矩阵。在这里,作者提出了一种基于余弦的重加权机制,因为它完全符合我们的目的:
1)托勒密定理确保了余弦权重可以分解为两个求和;
2)如图3(4)所示,cos会给相邻的token赋予更多的权重,从而加强局域性。此外,通过比较图3(2)和(3)中的注意力矩阵,cosFormer比没有重新加权机制的cosFormer执行了更多的局部性。
具体来说,结合公式(6),将余弦重加权的模型定义为:
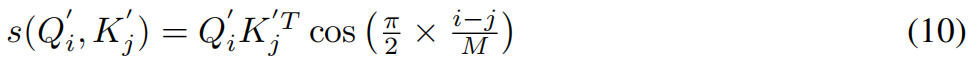
通过利用托勒密定理,将这个公式分解为:
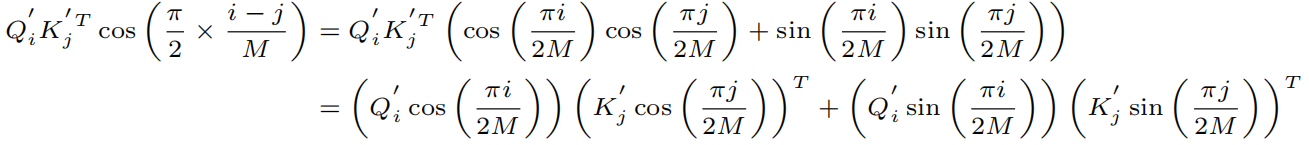
其中 i , j = 1 , … N , M ≥ N i, j = 1,…N, M≥N i,j=1,…N,M≥N,且 Q ′ = R e L U ( Q ) Q'=ReLU(Q) Q′=ReLU(Q), K ′ = R e L U ( K ) K'=ReLU(K) K′=ReLU(K)。令
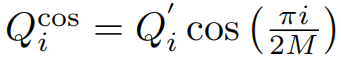
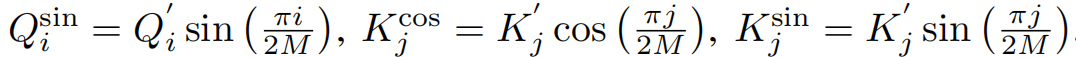
提出的注意力模块的输出可以表示为:
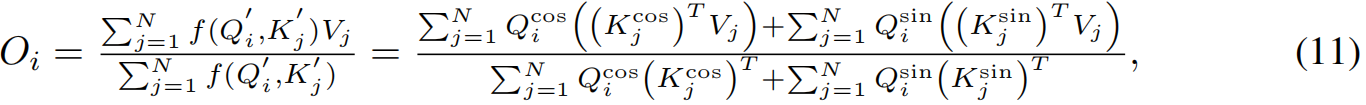
其中 O i O_i Oi是注意力模块在序列第i个位置的输出。在不失一般性的前提下,我们的方法得到的线性复杂度为:
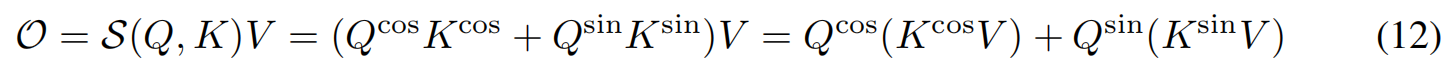
3. 部分实验结果
-
复杂度结果

-
下游微调任务

-
Long-range-arena基线的结果

-
有效性对比

-
消融实验

4. 结论
本文介绍了一种具有线性时间和空间复杂度的新型高效Transformer——cosFormer。cosFormer基于原始softmax注意的两个关键属性:
(1) 注意矩阵中的每个元素都是非负的,因此在上下文信息聚合时不包含负相关信息;
(2)非线性加权方案集中了注意矩阵的分布,以便更好地利用序列建模中的局部性归纳偏差。
为了在cosFormer中实现这些特性,本文利用ReLU函数作为线性运算,以保证cosFormer的非负性;提出了一种新的基于cos的加权机制,增强了原有softmax注意中的局部偏差。由于本文的cosFormer是自然可分解的,它不会遭受累积的近似误差,通常发生在以前的线性Transformer。
- 在因果预训练、双向预训练和多个下游文本理解任务上,cosFormer比普通transformer取得了相当甚至更好的性能;
- 在长序列基准测试中,cosFormer在5个不同的任务中实现了最先进的性能;
- cosFormer在时间和存储效率方面比现有的所有高效变压器都具有显著的整体优势,便于变压器易于扩展到更长的输入序列。
















 999
999











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









