







 本文详细介绍了神经网络的训练过程,包括激活函数的选择、数据预处理的重要性、权重初始化策略以及Batch Normalization的作用。强调了ReLU家族在解决梯度消失问题上的优势,同时讨论了Sigmoid和tanh的不足。在数据预处理方面,讨论了如何通过减去均值和标准化来改善模型训练。此外,还提到了学习率的选取和超参数优化对模型性能的影响。
本文详细介绍了神经网络的训练过程,包括激活函数的选择、数据预处理的重要性、权重初始化策略以及Batch Normalization的作用。强调了ReLU家族在解决梯度消失问题上的优势,同时讨论了Sigmoid和tanh的不足。在数据预处理方面,讨论了如何通过减去均值和标准化来改善模型训练。此外,还提到了学习率的选取和超参数优化对模型性能的影响。
overview
1.一次设置
激活函数,预处理,权重初始化,正则化,梯度检查
2.训练时动态调整
迁移学习,参数更新,超参数优化
3.评估
model ensembles, test-time augmentation
文章目录
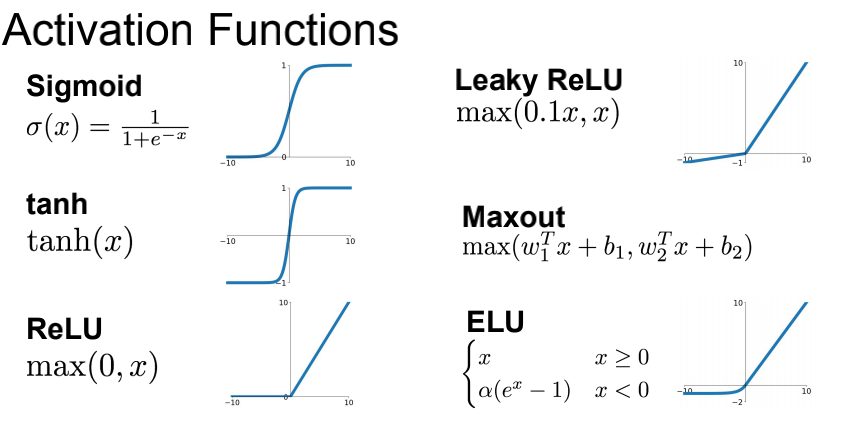
激活函数
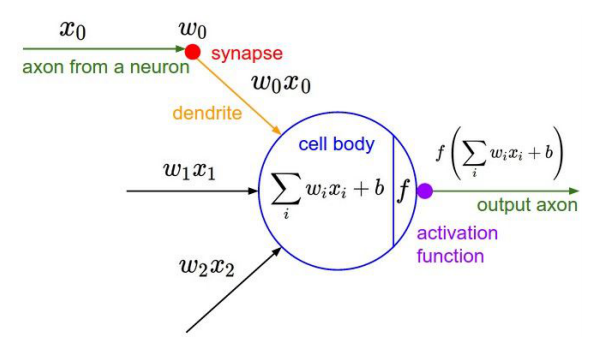
与神经细胞类比:
从神经元轴突传来数据(x0)到达突触(w0) 经过树突(w0x0) 到达细胞体,通过激活函数向轴突输出数据
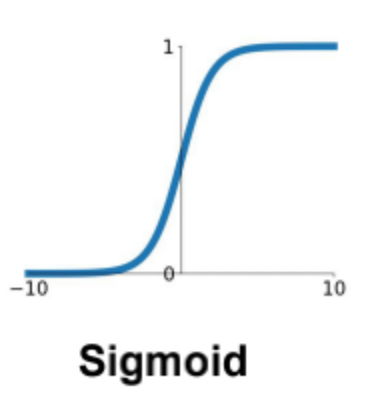
Sigmoid 函数
∂ σ ( x ) ∂ x = σ ( x ) ( 1 − σ ( x ) ) \frac{\partial \sigma(x)}{\partial x}=\sigma(x)(1-\sigma(x)) ∂x∂σ(x)=σ(x)(1−σ(x))
存在的问题:
- 饱和的神经元会把梯度杀死,会是0
- Sigmoid输出不是以0为中心的,因为是[0, 1],会导致后续的输入是以0.5为中心的分布,进而会导致出现下图的Z字收敛的情况出现。
- 由于损失函数对w求偏导的结果
因此,当所有的输入x都是正数的时候,上游梯度的导数要么全都是正的,要么全都是负的。因此,会导致W会以一个不好的方向收敛,会浪费时间。
∂ L ∂ w = σ ( ∑ i w i x i + b ) ( 1 − σ ( ∑ i w i
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 519
519

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









