







目录
需求:将性别这一列数据 “男”全部改为先生,“女”全部改为女士
需求:网站导出数据时,数据过大分表导出,想将导出的表合并成一张表,表字段相同
知识点:Pandas如何遍历一列数据? data.at[0, 'a']
创建新的工作簿
import pandas as pd
file_path = r"C:\Users\YGJ ing7\Desktop\pandas.xlsx"
data = pd.DataFrame()
data.to_excel(file_path)
print("make a new file!")新建工作簿同时写入数据
data = pd.DataFrame({'id':[1, 2, 3], "name": ['关羽', '刘备', '张飞']})
print(data)
--------结果--------
id name
0 1 关羽
1 2 刘备
2 3 张飞设置索引
data.set_index('id')读取数据
import pandas as pd
file_path = r"C:\Users\admin\Desktop\1.xlsx"
data = pd.read_excel(file_path)
# 取一行数据
print(data.head(1))
# 查看数据的形状,返回(行数、列数)
print(data.shape)
# 查看列名列表
print(data.columns)
# 查看索引列
print(data.index)
# 查看每一列数据类型
print(data.dtypes)知识点1: 几个重要的参数skiprow, 跳过开头的几行,,usecols只读取c,e二列 【C:F是c-f列】
df = pd.read_excel(file_path, skiprows=4, usecols="C, E")- skiprow, 跳过开头的几行
- usecols只读取c,e二列 【C:F是c-f列】
- dtype={"身份证号":"str",“手机号”: “str”}放在读出来的数据科学计数法表示
知识点2:只想要一些数据:head(num) 想要几行写几行;
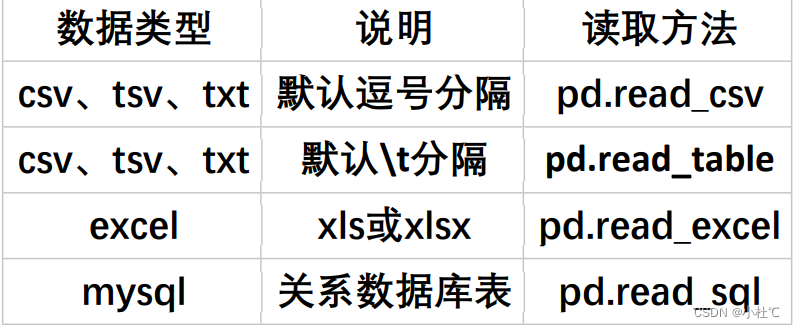
知识点3:reas_csv() 默认逗号分隔,read_table() 添加参数sep='\s+' 匹配\t \n \r等 导入re库;
知识点4:读取文件表头设置 headers=None, names=[] 配合使用
data = pd.read_csv(file_path, header=None, names=['性别', '姓名', '年龄', '手机号', '住址', '入职日期'], nrows=3)txt和CSV文件转化
读取TXT文件,在写入csv文件
import pandas as pd
file_path = r"C:\Users\admin\Desktop\1.txt"
data = pd.read_csv(file_path, header=None, names=['性别', '姓名', '年龄', '手机号', '住址', '入职日期'])
data.to_csv(r"C:\Users\admin\Desktop\1.csv", encoding='gbk')读取数据库内容
import pandas as pd
import pymysql
db = pymysql.connect(host="127.0.0.1", user="root", password="12**56", database="task01", charset="utf8", port=3306)
data = pd.read_sql('select * from table_a', con=db, )
print(data)pandas数据结构
Series序列,一维数组表示一行或一列数据
import pandas as pd
data = pd.Series(['loa', 'jia', 'iqo', 'kms', 'neh', 'ncjx', 'mkd'])
print(data)
print(data.index)
print(data.values)DataFrame用法
1,传入二维列表格式,columns表示列字段, 执行如下代码:
import pandas as pd
data=pd.DataFrame([[1,2,3],[4,5,6],[7,8,9]],columns=['a','b','c'])
--------结果--------
a b c
0 1 2 3
1 4 5 6
2 7 8 9
2, 传入的字典格式数据,
data = pd.DataFrame({'id':[1, 2, 3], "name": ['关羽', '刘备', '张飞']})
print(data)
--------结果--------
id name
0 1 关羽
1 2 刘备
2 3 张飞3, DataFrame结构,如何取数据??
print(data['a'][0] ) # 先列后行
print(data.loc[1]['a'] ) # 先行后列
print(data.iloc[1][0] ) # 数字形式 行-列
print(data[['a','b']]) # 取2列数据
--------结果-------
1
4
4
a b
0 1 2
1 4 5
2 7 8实现VLOOKUP功能
第一个表字段通过学号进行匹配,添加一列总分字段
# -*- coding: utf-8 -*-
import pandas as pd
df_sinfo = pd.read_excel(r"C:\Users\admin\Desktop\Vlookup.xlsx", sheet_name="花名册")
print(df_sinfo.head())
df_grade = pd.read_excel(r"C:\Users\admin\Desktop\Vlookup.xlsx", sheet_name="成绩单")
print(df_grade.head())
res = pd.merge(df_sinfo, df_grade.loc[:, ["学号", "总分"]], how="left", on="学号")
print(res)
---------------------------结果----------------------------
学号 姓名 班级
0 1 张三 1班
1 2 李四 1班
2 3 王五 2班
3 4 赵六 2班
4 5 邓七 3班
学号 语文 数学 英语 总分
0 1 67 77 63 207
1 2 81 58 65 204
2 3 89 60 58 207
3 4 67 61 52 180
4 5 78 55 51 184
学号 姓名 班级 总分
0 1 张三 1班 207
1 2 李四 1班 204
2 3 王五 2班 207
3 4 赵六 2班 180
4 5 邓七 3班 184需求:将总分调整顺序,放在第一列??
实现思路:
- 复制结果表中的总分列
- 将结果表中的总分列删除 res.drop("总分", axis=1)
- 插入复制的总分列
total = res["总分"]
res = res.drop("总分", axis=1)
res.insert(0, "总分", total)
print(res)
---------------------------结果----------------------------
总分 学号 姓名 班级
0 207 1 张三 1班
1 204 2 李四 1班
2 207 3 王五 2班
3 180 4 赵六 2班
4 184 5 邓七 3班
需求:将性别这一列数据 “男”全部改为先生,“女”全部改为女士
解决思路:利用pandas中的map映射方法
第一种方式:字典映射
import pandas as pd
file_path = r"C:\Users\admin\Desktop\数据.xlsx"
df = pd.read_excel(file_path)
dict_map = {"男": "先生", "女": "女士"}
# df["称呼"] = df["性别"].map(dict_map)
df["性别"] = df["性别"].map(dict_map)
print(df)首先创建一个映射:字典格式
性别字段.map(映射)在赋值给该列,如果想创建一个新的列“称呼”就赋值给新的列
第二种方式:函数映射
map()中也可以传入一个函数
def replace_map(x):
if "男" == x:
res = "先生"
else:
res = "女士"
return res
df["称呼"] = df["性别"].map(replace_map)
print(df)需求:姓名字段在表1是列,在表2是索引,如何进行连接合并?
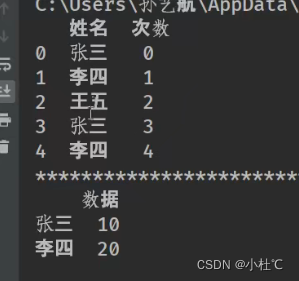
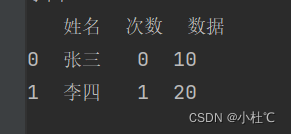
解决:使用左表的姓名列,右表的索引列进行连接【left_on='姓名', right_index=True】右图连接效果
import pandas as pd
data1 = pd.DataFrame({"姓名": ["张三", "李四", "王五", "赵六"], "次数": range(4)})
data2 = pd.DataFrame({"数据": [10, 20]}, index=["张三", "李四"])
print(data1)
print(data2)
data = pd.merge(data1, data2, left_on="姓名", right_index=True, how='inner')
print(data)
连接方式:how="inner", "outer", "left", "right"
以下内容引用UP主笔记内容:S02E08.连接查询之join与Merge总结_哔哩哔哩_bilibili
没有指定how的话默认使用inner方法,除了内连接,还包括左连接、右连接、全外连接
左连接:
result = pd.merge(left, right, how='left', on=['key1', 'key2'])
右连接:
result = pd.merge(left, right, how='right', on=['key1', 'key2'])
全外连接:
result = pd.merge(left, right, how='outer', on=['key1', 'key2'])
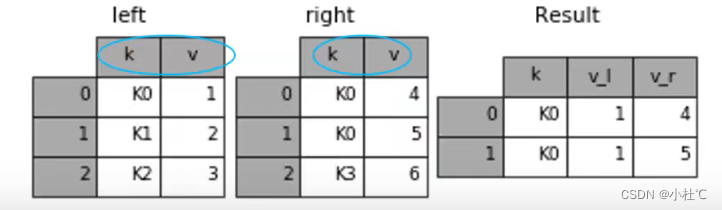
(2)suffix后缀参数
如果表合并的过程中遇到有一列两个表都同名,但是值不同,合并的时候又都想保留下来,就可以用suffixes给每个表的重复列名增加后缀。
result = pd.merge(left, right, on='k', suffixes=['_l', '_r'])
需求:网站导出数据时,数据过大分表导出,想将导出的表合并成一张表,表字段相同
解决:使用pandas的concat()函数进行多表的合并。
- 首先分别读取多个excel文件,将dataframe追加至列表中
- 使用pd.concat()函数,参数传入刚才的列表进行连接
- 将连接的表格进行写入文件
table_list = []
table1 = pd.read_excel(r"C:\Users\admin\Desktop\table1.xls", dtype={"订单编号":"str", "退款编号":"str", "商品编码":"str"})
table2 = pd.read_excel(r"C:\Users\admin\Desktop\table2.xls", dtype={"订单编号":"str", "退款编号":"str", "商品编码":"str"})
table3 = pd.read_excel(r"C:\Users\admin\Desktop\table3.xls", dtype={"订单编号":"str", "退款编号":"str", "商品编码":"str"})
table_list.append(table1)
table_list.append(table2)
table_list.append(table3)
table = pd.concat(table_list)
table.to_excel(r"C:\Users\admin\Desktop\table.xls", index=False)注意:由于订单编号等需要默认数字形式会以科学计数法显示,将这些列读取时按照字符串进行读取即可
知识点:Pandas如何遍历一列数据? data.at[0, 'a']
for i in data.index:
data["序号"].at[i]
需求:pandas删除表格一行或一列,多行或多列?
解决:使用pandas的drop函数进行表格的删除操作
import pandas as pd
file_path = r"C:\Users\YGJ ing7\Desktop\Pandas课件\pandas教程\课件015-016\删除.xlsx"
df = pd.read_excel(file_path, index_col="序号")
print(df)
# 删除第二行,并不会修改原来的df, 需要在原数据更改:inplace=True
print(df.drop(2))
# 删除多行
print(df.drop(labels=[1, 2]))
# 删除语文列,并不会修改原来的df
print(df.drop("语文", axis=1))
# 删除多列
print(df.drop(labels=["语文", "英语"], axis=1))- 删除一行直接在:drop()后跟参数第几行
- 删除多行使用参数:labels=[], 接受列表类型参数
- 删除列使用参数:axis=1,一轴表示列,默认0表示行操作
Pandas轴的理解
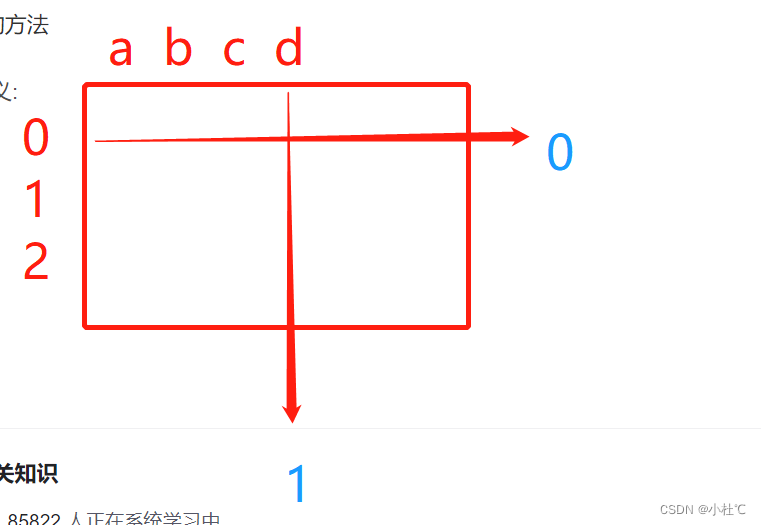
判断所有的空值
# 判断所有的空值
print(df.isnull())
print(df.notnull())需求:删除所有含空值的行/列
# 删除含有空值的行, 非原数据操作inplace=False: 默认的
print(df.dropna())
# 删除含有空值的列, 非原数据操作inplace=False: 默认的
print(df.dropna(axis=1))需求:一行或一列全部为空时进行删除
# 当一行或一列全部为空时候进行删除
print(df.dropna(how="all"))
print(df.dropna(how="all", axis=1))需求:删除语文,数学这二列包含空值的行
# 删除语文,数学这二列中包含空值的行/列
print(df.dropna(subset=["语文", "数学"]))需求:每一行/列空值个数不能超过二个
# 每一行/列 中非空值的个数不能超过2个
print(df.dropna(thresh=2))
print(df.dropna(thresh=2, axis=1))需求:所有的空值进行填充某一个值,或按列进行区分
# 所有的空值填充某一个值
print(df.fillna(60))
# 语文空值默认20, 数学空值默认30, 英语空值默认10
print(df.fillna({"语文": 20, "数学": 30, "英语": 10}))需求:空值按前后元素进行填充
# 将空值按该空值的上一行进行填充
print(df2.fillna(method='ffill', axis=0))
# 将空值按该空值的下一行进行填充
print(df2.fillna(method='bfill', axis=0))Pandas数学统计函数
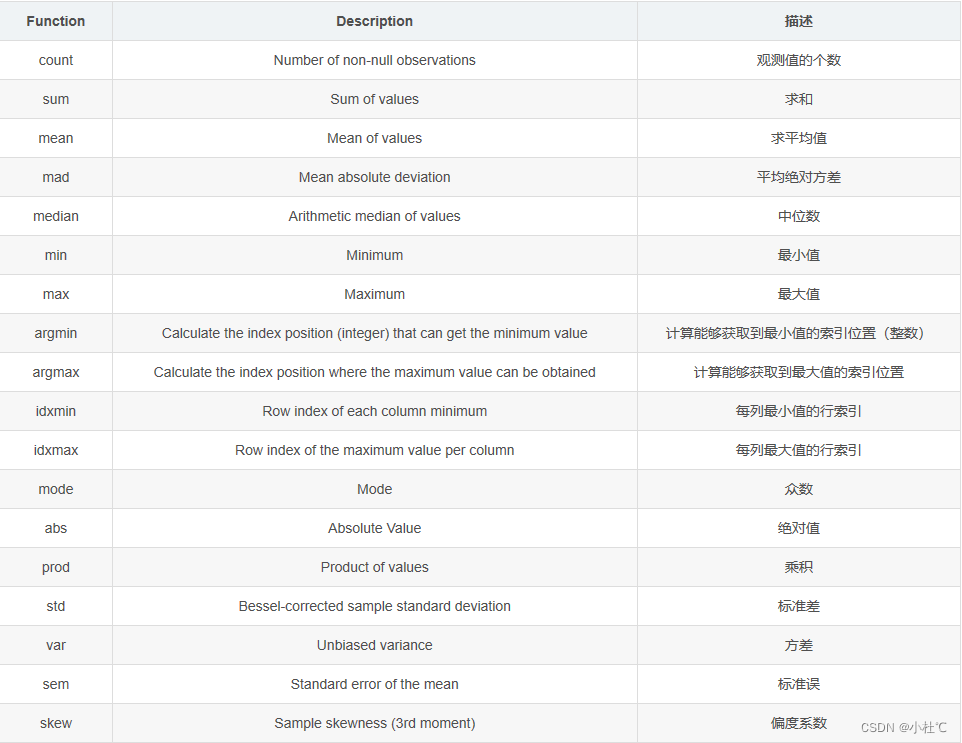
# 数据列的数学统计:最大最小值,数量,平均值,标准值
print(df.describe())
print(df["语文"].max())
print(df["语文"].mean())pandas统计函数汇总:使用方法如上
Pandas删除重复和提取重复
# 数据列【姓名】的去重--返回姓名去重的列表
print(df2["姓名"].unique())
# 数据列【姓名】的去重--返回姓名去重的索引+姓名
print(df2["姓名"].drop_duplicates())
# 统计相同【姓名】出现的次数
print(df2["姓名"].value_counts())- unique()函数是类似于set,返回一个数值不重复的列表
- drop_duplicates()函数会删除重复的行数据
- value_counts() 统计值出现的次数
# 姓名重复的那一行删除,保留第一次出现的数据
print(df2.drop_duplicates(subset=["姓名"], keep="first"))
# 姓名重复的那一行删除,保留最后一次出现的数据
print(df2.drop_duplicates(subset=["姓名"], keep="last"))# 提取姓名没有重复的数据
print(df2.drop_duplicates(subset=["姓名"], keep=False))
# 提取姓名重复的数据
is_duplicates = df2.duplicated(subset=["姓名"])
print(df2[is_duplicates])- drop_duplicates()函数一些重要的参数:
- subset=["姓名", "班级"] 处理多列数据
- keep = "first"【保留第一次出现的值】
- keep = "last" 【保留最后一次出现的值】
- keep = False 【不保留重复的值,就是删除所有重复的数据】
算数运算与数据对齐
1,空值填充为0:使用filena()函数进行填充
df.fillna(0, inplace=True)
res = df["1店"] + df["2店"]
print(res)2,正负无穷大转化为NaN: 需要在脚本开头添加一句
# 将无穷大转变为NaN
pd.options.mode.use_inf_as_na = True
res2 = df2["1店"].div(df2["2店"], fill_value=0)
print(res2.fillna(0))多层索引
1, 设置分层索引
设置分层索引前: 设置分层索引后

# df = pd.read_excel(file_path, sheet_name="有序")
df = pd.read_excel(file_path, sheet_name="有序", index_col=[0, 1])
print(df)- 多行索引:header=[0, 1]
- 多列索引:index_col=[0, 1]
2, 多层索引查看值,例如查看1班所有的值
# 查看一班所有的信息
data = df.loc[(("1班"), slice(None)), :]
print(data)- slice(None)作用等同于【:】 表示所有的行,但是不能换用
索引无序时,上面方法获取可能会报错,查看索引是否有序?df2.index.is_lexsorted()
file_path2 = r"C:\Users\admin\Desktop\pandas教程\课件020\多层索引.xlsx"
df2 = pd.read_excel(file_path2, sheet_name="无序", index_col=[0, 1])
print(df2.index.is_lexsorted())无序索引查询之前先进行排序处理
df2.sort_index(level="科目")
print(df2.loc[("语文", slice(None)), :])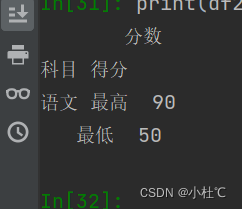
分组聚合groupby
情形1:按照城市和区进行人数 / 金额 分组求和
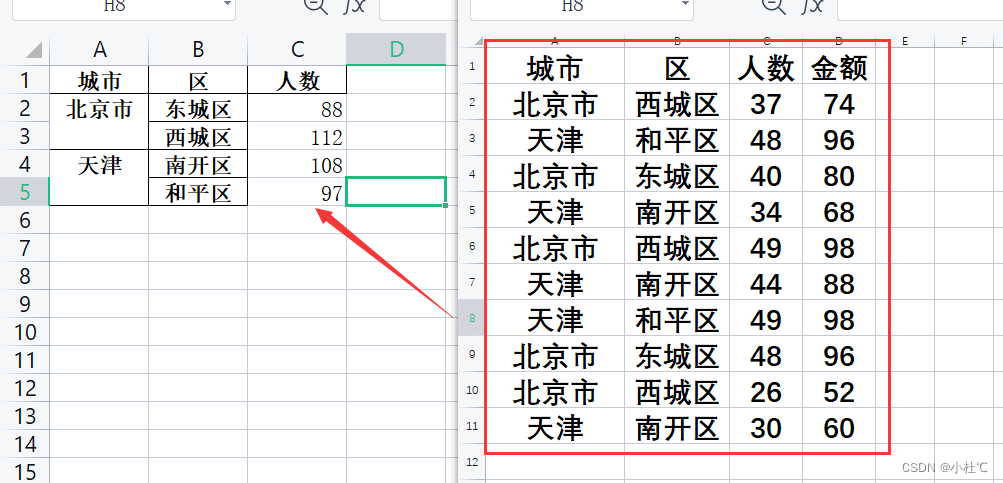
解决思路:
- groupby()函数的基本使用
- 按照城市、区进行分组:参数列表形式
- 分组完成后取[["人数"]]当然可以添加金额字段
- 求和使用.sum()函数
import pandas as pd
file_path = r"C:\Users\admin\Desktop\pandas教程\课件026\分组聚合.xlsx"
df = pd.read_excel(file_path)
res = df.groupby(["城市", "区"])[["人数"]].sum()
res.to_excel(r"C:\Users\admin\Desktop\聚合.xlsx")
print(res)情形2:店铺营销额分析,按照季度进行分组求和
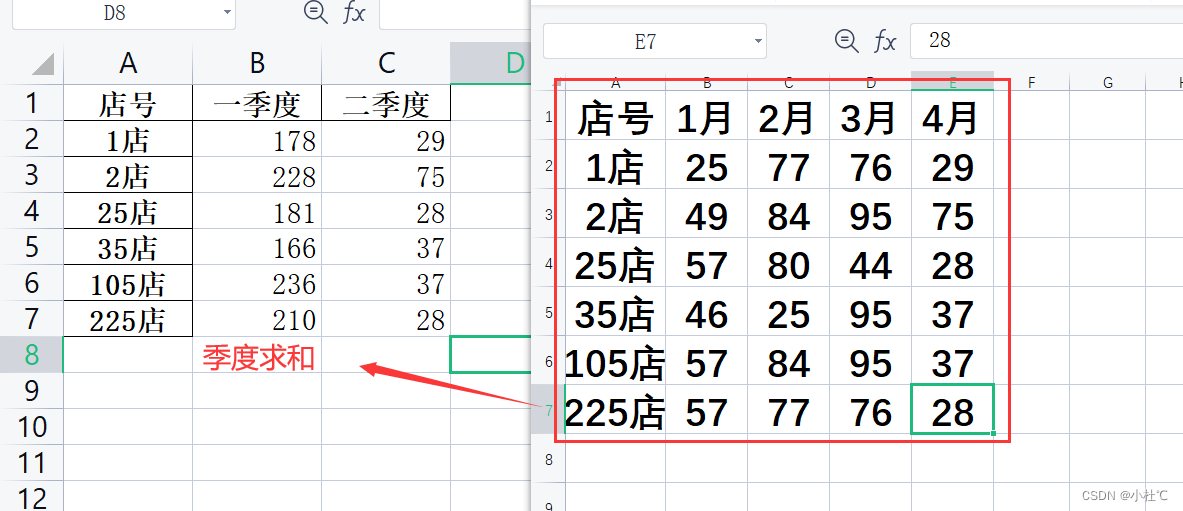
解决思路:
- groupby()函数的基本应用
- 创建一个月份和季度的对应关系 month_to_quarter
- 使用分组聚合函数进行分组,axis=1表示处理列
- 求和使用.sum()函数
import pandas as pd
file_path = r"C:\Users\admin\Desktop\pandas教程\课件026\分组聚合2.xlsx"
df = pd.read_excel(file_path, index_col="店号")
month_to_quarter= {"1月": "一季度", "2月": "一季度", "3月": "一季度", "4月": "二季度", "5月": "二季度", "6月": "二季度", "7月": "三季度", "8月": "三季度", "9月": "三季度", "10月": "四季度", "11月": "四季度", "12月": "四季度"}
res = df.groupby(month_to_quarter, axis=1).sum()
res.to_excel(r"C:\Users\admin\Desktop\合并2.xlsx")数据筛选
需求1:筛选出序号2-6的行数据, 取姓名,性别,地址这三列的数据
- 就是取序号为2,3,4,5,6的行数据,使用loc[]进行取值
# 取2,3,4,5,6行的数据
df.loc[2:6]- 取列数据使用列表形式:["姓名", "性别", "地址"]
df[["姓名", "性别", "地址"]]需求2:【单条件】选择性别为“男” 的全部数据
- 涉及pandas的条件筛选,首先是创建一个条件变量is_male【布尔类型】
- 将布尔类型变量传入df
# 选择性别为男的数据
is_male = df["性别"] == "男"
df[is_male]需求3:【多条件】选择性别为“男”并且总分大于150的数据
- 多条件筛选也类似单条件筛选,is_mm【字符串类型】
- 使用.query()进行筛选
is_mm = "性别 == '男' and 总分 >= 150"
df.query(is_mm)需求4:【模糊查询】选择姓名“王”开头的数据
- 条件变量is_startswith,字符串开头函数startswith,df["姓名"].str.startswith('王')
- 选择df[is_startswith]
is_startswith = df["姓名"].str.startswith("王")
res = df[is_startswith]- 开头函数:startswith()
- 结尾函数:endswith()
- 包含函数:contains()















 1949
1949











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









