







听老师讲了很多,并结合天池正式赛里面的lgb与xgb模型baseline与特征工程,进行代码试验.
目录
一.MLP
1.1总览:机器学习与深度学习的区别与适用范围:
机器学习:
1模型构建:自己写
2:模型权重求解:自己写(需要用大量的数学公式来推导,每个模型都是有自己的方法)
3:使用方法:掉包scikit-learn/lightgbm/xgboost/catboost
深度学习
1:模型构件:自己写
2:模型权重求解:框架打包已经求解好了
3:使用情况:大量基于框架(torch/tf/paddle...)开发
有自动求导backforward等操作,直接搭积木就好。
1.2注意细节:
对于torch而言:一数据处理:1数据编码,将数据转换成计算机可认的形式;2dl中,每次都是batch小批训练,所以要进行dataset于loader构造;二模型设计:1需要于loader吐出来的数据形式对其;2实现模型里面的子模块;3把子模块拼成最终的模型。三跑模型:八股文形式,1训练流程、2验证/测试流程。
将掉包参数进行分离,避免动代码,config是偏数据集的参数。区分连续特征与离散特征(地区,性别...);model要不要使用离散特征,embedding,隐藏层。。
#参数配置
config = {
"train_path":'../data/used_car_train_20200313.csv',
"test_path":'../data/used_car_testB_20200421.csv',
"epoch" : 15,
"batch_size" : 512,
"lr" : 0.001,
"model_ckpt_dir":'./',
"device" : 'cuda',
"num_cols" : ['power', 'kilometer', 'v_0', 'v_1', 'v_2', 'v_3', 'v_4', 'v_5', 'v_6', 'v_7', 'v_8', 'v_9', 'v_10', 'v_11', 'v_12', 'v_13', 'v_14'],
"cate_cols" : ['model','brand','bodyType','fuelType','gearbox','seller','notRepairedDamage']
}
model_config = {
"is_use_cate_cols" : True,
"embedding_dim" : 4,
"hidden_units" : [256,128,64,32]
}
model_config["num_cols"] = config['num_cols']
model_config['cate_cols'] = config['cate_cols']num有:发动机频率,公里数,v系列特征;
cate有:1.车型;2.品牌;3.车身类型;4.燃油类型;5.变速箱;6.销售方;7.是否有尚未修复的损坏
train_df = pd.read_csv(config['train_path'],sep=' ')
test_df = pd.read_csv(config['test_path'],sep=' ')
print('Train data shape:',train_df.shape)
print('TestA data shape:',test_df.shape)
'''
Train data shape: (150000, 31)
TestA data shape: (50000, 30)
'''1.3EDA
对具体的参数进行可视化查看,方便总体掌握数据情况:
# 连续特征
for col in config['num_cols']:
# 绘制密度图
sns.kdeplot(df[col], fill=True)
# 设置图形标题和标签
plt.title(f'{col} Distribution')
plt.xlabel(col)
plt.ylabel('Density')
plt.show()# 离散特征
for col in config['cate_cols']:
# 统计特征频次
counts = df[col].value_counts()
# 绘制条形图
counts.plot(kind='bar')
# 设置图形标题和标签
plt.title(f'{col} Frequencies')
plt.xlabel(col)
plt.ylabel('Frequency')
# 显示图形
plt.show()1.4特征编码
遍历离散特征,补充缺失值,使用embedding操作,将每个城市变成向量,比如将not这个类中的每一个str值,进行一个取值索引。
代码中,unique是去除重复的值,然后再range进行赋值value。
# 离散特征编码
vocab_map = defaultdict(dict)
for col in tqdm(config['cate_cols']):
df[col] = df[col].fillna('-1')
map_dict = dict(zip(df[col].unique(), range(df[col].nunique())))
# label enc
df[col] = df[col].map(map_dict)
vocab_map[col]['vocab_size'] = len(map_dict)
model_config['vocab_map'] = vocab_map输出结果看一下:
model_config['vocab_map']
'''
defaultdict(dict,
{'model': {'vocab_size': 249},
'brand': {'vocab_size': 40},
'bodyType': {'vocab_size': 9},
'fuelType': {'vocab_size': 8},
'gearbox': {'vocab_size': 3},
'seller': {'vocab_size': 2},
'notRepairedDamage': {'vocab_size': 3}})
'''vocab_size表示这个key对应有多少类的赋值
将train与test拆分开,并对标签进行log变换,便于dl拟合。dl更适合参数量大的任务,本次任务数据量较小,所以要进行一些优化。
train_df = df[df['price'].notna()].reset_index(drop=True)
# 标签范围太大不利于神经网络进行拟合,这里先对其进行log变换
train_df['price'] = np.log(train_df['price'])
test_df = df[df['price'].isna()].reset_index(drop=True)
del test_df['price']将连续数据进行归一化处理:
modifycol = config['num_cols']
df[modifycol] = df[modifycol].apply(
lambda x: (x - x.mean()) / (x.std()))2.1构造dataset与loader
构造dataset
继承父类,len的方法是返回数据集的长度,这是为了后续取batch用的。getitem方法要输出第index个数据,告诉它如何取出对应数据。
此处适配个数不确定的情况,使用字典更好。
#Dataset构造
class SaleDataset(Dataset):
def __init__(self,df,cate_cols,num_cols):
self.df = df
self.feature_name = cate_cols + num_cols
def __getitem__(self, index):
data = dict()
for col in self.feature_name:
data[col] = torch.Tensor([self.df[col].iloc[index]]).squeeze(-1)
if 'price' in self.df.columns:
data['price'] = torch.Tensor([self.df['price'].iloc[index]]).squeeze(-1)
return data
def __len__(self):
return len(self.df)
def get_dataloader(df, cate_cols ,num_cols, batch_size=256, num_workers=2, shuffle=True):
dataset = SaleDataset(df,cate_cols,num_cols)
dataloader = D.DataLoader(dataset, batch_size=batch_size, shuffle=shuffle, num_workers=num_workers)
return dataloader看一下getitem用法:
# sample
train_dataset = SaleDataset(train_df,config['cate_cols'],config['num_cols'])
train_dataset.__getitem__(888)
'''
{'model': tensor(11.),
'brand': tensor(6.),
'bodyType': tensor(0.),
'fuelType': tensor(1.),
'gearbox': tensor(2.),
'seller': tensor(0.),
'notRepairedDamage': tensor(1.),
'power': tensor(0.1167),
'kilometer': tensor(1.),
'v_0': tensor(0.5566),
'v_1': tensor(0.1054),
'v_2': tensor(0.1718),
'v_3': tensor(0.4344),
'v_4': tensor(0.4444),
'v_5': tensor(0.8196),
'v_6': tensor(0.0012),
'v_7': tensor(0.0715),
'v_8': tensor(0.3914),
'v_9': tensor(0.3532),
'v_10': tensor(0.5796),
'v_11': tensor(0.2046),
'v_12': tensor(0.3767),
'v_13': tensor(0.3404),
'v_14': tensor(0.5267),
'price': tensor(7.5959)}
'''2.2Embedding:
使用例子每一行是每一个用户的信息,把每个离散特征变成向量:
## 定义model
### user进行embedding化,有4个user,想把每个user编码成一个8维的向量.
num_user = 4
emb_dim = 8
user1 = nn.Embedding(num_user, emb_dim)
user1.weight
'''
Parameter containing:
tensor([[-0.1036, 0.8381, 1.7820, -0.0637, -0.1190, 1.2010, -1.0078, -0.8894],
[ 2.1646, -0.1769, -0.2203, -0.6339, -0.2730, -1.0055, -0.5780, -0.6274],
[-0.5666, 0.6833, 0.2136, -0.4713, 1.7233, 1.2173, 0.4182, -0.3625],
[-0.6290, 2.0706, 0.9059, -0.4362, -0.3190, 1.1176, -0.6189, 1.1477]],
requires_grad=True)
'''# Embedding层:用于对离散特征进行编码映射
class EmbeddingLayer(nn.Module):
def __init__(self,
vocab_map = None,
embedding_dim = None):
super(EmbeddingLayer, self).__init__()
self.vocab_map = vocab_map
self.embedding_dim = embedding_dim
self.embedding_layer = nn.ModuleDict()
self.emb_feature = []
# 使用字典来存储每个离散特征的Embedding标
for col in self.vocab_map.keys():
self.emb_feature.append(col)
self.embedding_layer.update({col : nn.Embedding(
self.vocab_map[col]['vocab_size'],
self.embedding_dim,
)})
def forward(self, X):
#对所有的sparse特征挨个进行embedding
feature_emb_list = []
for col in self.emb_feature:
inp = X[col].long().view(-1, 1)
feature_emb_list.append(self.embedding_layer[col](inp))
return torch.cat(feature_emb_list,dim=1)2.3Model定义
MLP代码模板编写,生成多层MLP,使用sequential串起来。
#MLP
class MLP(nn.Module):
def __init__(self,
input_dim,
output_dim=None,
hidden_units=[],
hidden_activations="ReLU",
final_activation=None,
dropout_rates=0,
batch_norm=False,
use_bias=True):
super(MLP, self).__init__()
dense_layers = []
if not isinstance(dropout_rates, list):
dropout_rates = [dropout_rates] * len(hidden_units)
if not isinstance(hidden_activations, list):
hidden_activations = [hidden_activations] * len(hidden_units)
hidden_activations = [self.set_activation(x) for x in hidden_activations]
hidden_units = [input_dim] + hidden_units
for idx in range(len(hidden_units) - 1):
dense_layers.append(nn.Linear(hidden_units[idx], hidden_units[idx + 1], bias=use_bias))
if batch_norm:
dense_layers.append(nn.BatchNorm1d(hidden_units[idx + 1]))
if hidden_activations[idx]:
dense_layers.append(hidden_activations[idx])
if dropout_rates[idx] > 0:
dense_layers.append(nn.Dropout(p=dropout_rates[idx]))
if output_dim is not None:
dense_layers.append(nn.Linear(hidden_units[-1], output_dim, bias=use_bias))
if final_activation is not None:
dense_layers.append(set_activation(final_activation))
self.dnn = nn.Sequential(*dense_layers) # * used to unpack list
def set_activation(self,activation):
if isinstance(activation, str):
if activation.lower() == "relu":
return nn.ReLU()
elif activation.lower() == "sigmoid":
return nn.Sigmoid()
elif activation.lower() == "tanh":
return nn.Tanh()
else:
return getattr(nn, activation)()
else:
return activation
def forward(self, inputs):
return self.dnn(inputs)将各个模块搭积木搭起来,注意,回归任务最后一个out为1,且最后一层不使用激活函数
class SaleModel(nn.Module):
def __init__(self,
is_use_cate_cols = True,
vocab_map = None,
embedding_dim = 16,
num_cols = None,
cate_cols = None,
hidden_units = [256,128,64,32],
loss_fun = 'nn.L1Loss()'):
super(SaleModel, self).__init__()
self.is_use_cate_cols = is_use_cate_cols
self.vocab_map = vocab_map
self.embedding_dim = embedding_dim
self.num_cols = num_cols
self.num_nums_fea = len(num_cols)
self.hidden_units = hidden_units
self.loss_fun = eval(loss_fun) # self.loss_fun = torch.nn.MSELoss()
if is_use_cate_cols:
self.emb_layer = EmbeddingLayer(vocab_map=vocab_map,embedding_dim=embedding_dim)
self.mlp = MLP(
self.num_nums_fea + self.embedding_dim*len(vocab_map),
output_dim=1,
hidden_units=self.hidden_units,
hidden_activations="ReLU",
final_activation=None,
dropout_rates=0,
batch_norm=True,
use_bias=True)
else:
self.mlp = MLP(
self.num_nums_fea,
output_dim=1,
hidden_units=self.hidden_units,
hidden_activations="ReLU",
final_activation=None,
dropout_rates=0,
batch_norm=True,
use_bias=True)
self.apply(self._init_weights)
def _init_weights(self, module):
if isinstance(module, nn.Embedding):
xavier_normal_(module.weight.data)
elif isinstance(module, nn.Linear):
xavier_normal_(module.weight.data)
def get_dense_input(self, data):
dense_input = []
for col in self.num_cols:
dense_input.append(data[col])
return torch.stack(dense_input,dim=-1)
def forward(self,data):
dense_fea = self.get_dense_input(data)
if self.is_use_cate_cols:
sparse_fea = self.emb_layer(data) # [batch,num_cate_cols,emb]
sparse_fea = torch.flatten(sparse_fea,start_dim=1) # [batch,num_cate_cols*emb]
mlp_input = torch.cat([sparse_fea, dense_fea],axis=-1)
else:
mlp_input = dense_fea
y_pred = self.mlp(mlp_input)
if 'price' in data.keys():
loss = self.loss_fun(y_pred.squeeze(),data['price'])
output_dict = {'pred':y_pred,'loss':loss}
else:
output_dict = {'pred':y_pred}
return output_dict2.4训练函数
在训练时,可使用logger.info代替print,能够输出更多可溯源信息
#训练模型,验证模型,这里就是八股文,熟悉基础pipeline
def train_model(model, train_loader, optimizer, device, metric_list=['mean_absolute_error']):
model.train()
pred_list = []
label_list = []
max_iter = int(train_loader.dataset.__len__() / train_loader.batch_size)
for idx,data in enumerate(train_loader):
for key in data.keys():
data[key] = data[key].to(device)
output = model(data)
pred = output['pred']
loss = output['loss']
if idx%50==0:
logger.info(f"Iter:{idx}/{max_iter} Loss:{round(loss.item(),4)}")
loss.backward()
optimizer.step()
model.zero_grad()
pred_list.extend(pred.squeeze(-1).cpu().detach().numpy())
label_list.extend(data['price'].squeeze(-1).cpu().detach().numpy())
res_dict = dict()
for metric in metric_list:
res_dict[metric] = eval(metric)(label_list,pred_list)
return res_dict
def valid_model(model, valid_loader, device, metric_list=['mean_absolute_error']):
model.eval()
pred_list = []
label_list = []
for data in (valid_loader):
for key in data.keys():
data[key] = data[key].to(device)
output = model(data)
pred = output['pred']
pred_list.extend(pred.squeeze(-1).cpu().detach().numpy())
label_list.extend(data['price'].squeeze(-1).cpu().detach().numpy())
res_dict = dict()
for metric in metric_list:
res_dict[metric] = eval(metric)(label_list,pred_list)
return res_dict
def test_model(model, test_loader, device):
model.eval()
pred_list = []
for data in test_loader:
for key in data.keys():
data[key] = data[key].to(device)
output = model(data)
pred = output['pred']
pred_list.extend(pred.squeeze().cpu().detach().numpy())
return np.array(pred_list)之后是一样的交叉验证,预测等操作。
二.特征工程选建
1.使用年限与报废判断
def regDateFalse(x):
if str(x)[4:6] == '00':
return 1
else:
return 0
df['regDateFalse'] = df['regDate'].apply(lambda x: regDateFalse(x))
# 这里是改正错误字段
def changeFalse(x):
x = str(x)
if x[4:6] == '00':
x = x[0:4] + '01' + x[6:]
x = int(x)
return x
df['regDate'] = df['regDate'].apply(lambda x: changeFalse(x))
# 使用时间:data['creatDate'] - data['regDate'],反应汽车使用时间,一般来说价格与使用时间成反比
# 不过要注意,数据里有时间出错的格式,所以我们需要 errors='coerce'
df['used_time'] = (pd.to_datetime(df['creatDate'], format='%Y%m%d') -
pd.to_datetime(df['regDate'], format='%Y%m%d')).dt.days
# 修改错误
# 但是需要加上那一个月
df.loc[df.regDateFalse==1, 'used_time'] += 30
# 删除标记列
del df['regDateFalse']df['used_time'] = df['used_time'] / 365.0
df['Is_scrap'] = df['used_time'].apply(lambda x: 1 if x>=10 else 0)
bins = [0, 3, 7, 10, 20, 30]
df['estivalue'] = pd.cut(df['used_time'], bins, labels=False)查看一下列变成了什么样:使用时间差来得到汽车使用年限,再将离散的使用年限进行数据分桶,分成了六段,再追加一个超过十年的报废信息!
df['estivalue'].describe()
'''
count 200000.000000
mean 2.517900
std 0.960143
min 0.000000
25% 2.000000
50% 3.000000
75% 3.000000
max 4.000000
Name: estivalue, dtype: float64
'''2.车的类型
仔细阅读赛题的信息表,可以看到不同种车的信息
com_car = [2.0, 3.0, 6.0] # 商用车
GL_car = [0.0, 4.0, 5.0] # 豪华系列
self_car = [1.0, 7.0]
def class_bodyType(x):
if x in GL_car:
return 0
elif x in com_car:
return 1
else:
return 2
df['car_class'] = df['bodyType'].apply(lambda x : class_bodyType(x))看一下输出结果:
df['car_class'][150:160]
'''
150 2
151 2
152 2
153 2
154 0
155 1
156 0
157 0
158 1
159 0
Name: car_class, dtype: int64
'''3.是否新能源
同样也是通过赛题中不同的信息进行挖掘
# 是否是新能源
is_fuel = [0.0, 1.0, 2.0, 3.0]
df['is_fuel'] = df['fuelType'].apply(lambda x: 1 if x in is_fuel else 0)4.销售淡旺季
通过销售日期,进而提取购车的淡旺季,从而提取出特征。
# 选出淡旺季
low_seasons = ['3', '6', '7', '8']
df['is_low_seasons'] = df['creatDate'].apply(lambda x: 1 if str(x)[5] in low_seasons else 0)
# 独热一下
df = pd.get_dummies(df, columns=['is_low_seasons'])
# 这样时间特征构造完毕,删除日期了
del df['regDate']
del df['creatDate']5.地区编码
通过地区编码提取出销售所在的城市,不同城市繁华程度与购买力不一样,故可提取为特征。
df['city'] = df['regionCode'].apply(lambda x: str(x)[0])
df['city'] = df['city'].apply(lambda X: float(X))三.xgb与lgb
正如第一节讲到,对于此数据量较小的问题,使用ml的模型可能更适合,故也使用了机器学习中的xgb与lgb模型进行调试。
1.数据读取
## 通过Pandas对于数据进行读取 (pandas是一个很友好的数据读取函数库)
Train_data = pd.read_csv('../data/used_car_train_20200313.csv', sep=' ')
TestA_data = pd.read_csv('../data/used_car_testB_20200421.csv', sep=' ')
## 输出数据的大小信息
print('Train data shape:',Train_data.shape)
print('TestA data shape:',TestA_data.shape)检查是否出现一些异常值,如发现异常,则后续可照着减少异常影响的方向努力。
## 通过 .info() 简要可以看到对应一些数据列名,以及NAN缺失信息
Train_data.info()
## 通过 .columns 查看列名
Train_data.columns2.特征选择
这里写的是原始数据集中的数据列名,如果进行了自己的特征工程,则可视情况进行列名的添加。
## 选择特征列
feature_cols = [col for col in numerical_cols if col not in ['SaleID','name','regDate','creatDate','price','model','brand','regionCode','seller']]
feature_cols = [col for col in feature_cols if 'Type' not in col]
## 提前特征列,标签列构造训练样本和测试样本
X_data = Train_data[feature_cols]
Y_data = Train_data['price']
X_test = TestA_data[feature_cols]## 定义了一个统计函数,方便后续信息统计
def Sta_inf(data):
print('_min',np.min(data))
print('_max:',np.max(data))
print('_mean',np.mean(data))
print('_ptp',np.ptp(data))
print('_std',np.std(data))
print('_var',np.var(data))举个例子,统计标签的基本分布信息(以price列为例)
print('Sta of label:')
Sta_inf(Y_data)
'''
Sta of label:
_min 11
_max: 99999
_mean 5923.327333333334
_ptp 99988
_std 7501.973469876438
_var 56279605.94272992
'''训练的样本分布与预测的应该是比较接近的才正常!
缺少的值(null)用-1填补
但如果用xgb,其实可以不用填补缺失值,因为它会单独读取为一个类别。
X_data = X_data.fillna(-1)
X_test = X_test.fillna(-1)检验查看缺失值
X_data.isnull().sum()
'''
gearbox 5981
power 0
kilometer 0
v_0 0
v_1 0
v_2 0
v_3 0
v_4 0
v_5 0
v_6 0
v_7 0
v_8 0
v_9 0
v_10 0
v_11 0
v_12 0
v_13 0
v_14 0
dtype: int64
'''3. 模型训练与预测
3.1单模型训练
利用xgb进行5折交叉验证并查看参数结果:
k折交叉验证,使每一部分都做了训练与验证,防止过拟合,xgb可以调参试一试mae会不会下降
## xgb-Model
xgr = xgb.XGBRegressor(n_estimators=120, learning_rate=0.1, gamma=0, subsample=0.8,\
colsample_bytree=0.9, max_depth=7) #,objective ='reg:squarederror'
scores_train = []
scores = []
## 5折交叉验证方式
sk=StratifiedKFold(n_splits=5,shuffle=True,random_state=0)
for train_ind,val_ind in sk.split(X_data,Y_data):
train_x=X_data.iloc[train_ind].values
train_y=Y_data.iloc[train_ind]
val_x=X_data.iloc[val_ind].values
val_y=Y_data.iloc[val_ind]
xgr.fit(train_x,train_y)
pred_train_xgb=xgr.predict(train_x)
pred_xgb=xgr.predict(val_x)
score_train = mean_absolute_error(train_y,pred_train_xgb)
scores_train.append(score_train)
score = mean_absolute_error(val_y,pred_xgb)
scores.append(score)
print('Train mae:',np.mean(score_train))
print('Val mae',np.mean(scores))3.2融合训练
定义xgb和lgb模型函数
def build_model_xgb(x_train,y_train):
model = xgb.XGBRegressor(n_estimators=150, learning_rate=0.1, gamma=0, subsample=0.8,\
colsample_bytree=0.9, max_depth=7) #, objective ='reg:squarederror'
model.fit(x_train, y_train)
return model
def build_model_lgb(x_train,y_train):
estimator = lgb.LGBMRegressor(num_leaves=127,n_estimators = 150)
param_grid = {
'learning_rate': [0.01, 0.05, 0.1, 0.2],
}
gbm = GridSearchCV(estimator, param_grid)
gbm.fit(x_train, y_train)
return gbmgbm中GridSearchCV会在para_grid里面的参数都训练一边,如果是两组4个的参数list,则会组合16次,最终选训练结果最好的参数。
切分数据集(train,val),进行模型训练、评价和预测
这里是直接切分的,没有进行交叉验证,这里0.3表示train与val7:3
## Split data with val
x_train,x_val,y_train,y_val = train_test_split(X_data,Y_data,test_size=0.3)第一块train lgb:1.首先拿到train的x和y进行训练;2.再用x的val部分做预测,3.进而对预测值与标签值做mae。
print('Train lgb...')
model_lgb = build_model_lgb(x_train,y_train)
val_lgb = model_lgb.predict(x_val)
MAE_lgb = mean_absolute_error(y_val,val_lgb)
print('MAE of val with lgb:',MAE_lgb)
print('Predict lgb...')
model_lgb_pre = build_model_lgb(X_data,Y_data)
subA_lgb = model_lgb_pre.predict(X_test)
print('Sta of Predict lgb:')
Sta_inf(subA_lgb)
'''
Train lgb...
MAE of val with lgb: 687.8455405107986
Predict lgb...
Sta of Predict lgb:
_min -589.8793550785414
_max: 90760.26063584947
_mean 5906.935218383807
_ptp 91350.13999092802
_std 7344.644970956768
_var 53943809.749400534
'''观察sta打印输出值,预测的min最小值有负数,真实车价不可能是负的,所以要对其进行后续处理。
第二个Predict lgb是把所有的train数据拿来训练,再对test数据进行预测
再对比一下两个模型的均值与方差,再对比一下mean与std,看到是5900多和7300多,看一看上面的price训练列的均值和方差也是5k多7k多,差不多.
再进行xgb训练。同上一样的操作:
print('Train xgb...')
model_xgb = build_model_xgb(x_train,y_train)
val_xgb = model_xgb.predict(x_val)
MAE_xgb = mean_absolute_error(y_val,val_xgb)
print('MAE of val with xgb:',MAE_xgb)
print('Predict xgb...')
model_xgb_pre = build_model_xgb(X_data,Y_data)
subA_xgb = model_xgb_pre.predict(X_test)
print('Sta of Predict xgb:')
Sta_inf(subA_xgb)4.模型结果融合
使用加权融合,Maelgb和Maexbg,谁的mae大则其占的权重就小,具体公式见下面的第一行。
第二行是对赋值小于0的,取10,第三行是在验证集上,实验一下模型结果融合后的误差MAE
## 这里我们采取了简单的加权融合的方式
val_Weighted = (1-MAE_lgb/(MAE_xgb+MAE_lgb))*val_lgb+(1-MAE_xgb/(MAE_xgb+MAE_lgb))*val_xgb
val_Weighted[val_Weighted<0]=10 # 由于我们发现预测的最小值有负数,而真实情况下,price为负是不存在的,由此我们进行对应的后修正
print('MAE of val with Weighted ensemble:',mean_absolute_error(y_val,val_Weighted))再对test集上的结果也进行相同的结果融合
sub_Weighted = (1-MAE_lgb/(MAE_xgb+MAE_lgb))*subA_lgb+(1-MAE_xgb/(MAE_xgb+MAE_lgb))*subA_xgb5输出结果
注意没有index列,所以要选成false。
sub = pd.DataFrame()
sub['SaleID'] = TestA_data.SaleID
sub['price'] = sub_Weighted
sub.to_csv('./sub1.csv',index=False)结果:
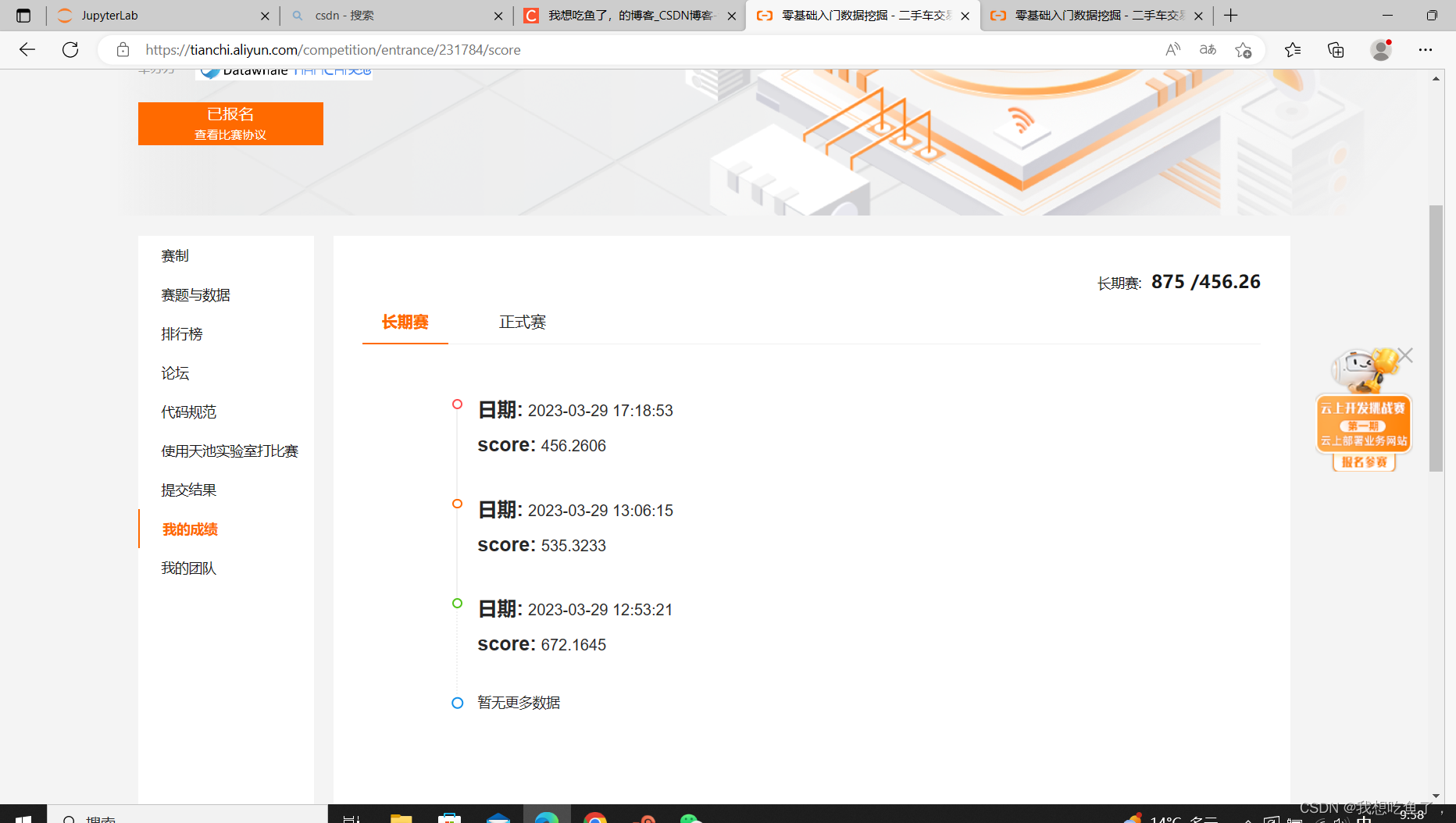

















 525
525

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









