






NUS-WIDE是一个多标签数据集,数据集中一共包含26,9648个样本,可以分为81个类。最近在做跨模态检索项目,发现有很多论文里面都用到了NUS-WIDE-10K数据集,但是在网上也没有搜索到相关的数据集下载链接或者是数据集制作代码,所以自己动手写了一个NUS-WIDE-10K数据集的制作代码。
更新
评论区有人提醒NUS-WIDE-10K的10个最大的类是通过统计该类单标签图片个数来排序得出的,但是在随机抽取样本时是没有区分多标签图片和单标签图片,有可能并不符合原文中的描述。我一开始写代码的时候考虑到如果只选择单标签图片可能某一类图片的总数无法到达1000张,但是今天重新尝试了一下发现是可以的。因此我重新修改了一下提取部分的代码以满足原文要求。
1.介绍
我在网上找到的最早关于NUS-WIDE-10K数据集描述的论文是:Cross-modal Retrieval with Correspondence Autoencoder。描述如下:作者选择了NUS-WIDE数据集中最大的10个类:animal、clouds、flowers、food、grass、person、sky、toy、water 和 window,并从每个类中选取1000张单标签图片(总共10000张)作为NUS-WIDE-10K数据集。NUS-WIDE-10K被随机分为3个子集:训练集、验证集和测试集,每个集合样本数分别为:8000、1000和1000。

2. 数据集分析
我们再来看一下NUS-WIDE数据集的主要结构

- Flickr文件夹:Flickr文件夹包含了NUS-WIDE数据集的所有图片,里面有704个文件夹,每个文件夹代表一类图片(还记得NUS-WIDE是一个多标签数据集吗?对因此每个图片都有两个标签)
- Groundtruth文件夹:解压后有 AllLabels/ 和 TrainTestLabels/ 两个目录,AllLabels/ 中一共有81个.txt文件,每个文件中包含的都是26,9648 行的 0/1 数据,代表该数据是否属于该类别。
- ImageList文件夹:该文件夹中有Imagelist.txt、TestImagelist.txt、TrainImagelist.txt三个文件,我们只用到Imagelist.txt,该文件按序排放了数据集所有图片的存放地址。
- NUS_WID_Tags文件夹:文件夹有多个文件,但是我们只用到All_Tags.txt,该文件按序存储了所有图片的文本描述。
- Concepts81.txt:包含81个类别的类名。
3.代码
提取
- 提取animal、clouds、flowers、food、grass、person、sky、toy、water 和 window每个类别样本的id值。
- 从每个类别中随机抽取1000个样本。
import os
import numpy as np
import random
from tqdm import tqdm
import shutil
import sys
N_SAMPLE = 269648
label_dir = "Groundtruth/AllLabels"
image_dir = 'ImageList/ImageList.txt'
txt_dir = 'NUS_WID_Tags/All_Tags.txt'
output_dir = 'NUS_WIDE_10K/NUS_WIDE_10k.list'
classes = ['animal', 'clouds', 'flowers', 'food', 'grass', 'person', 'sky', 'toy', 'water', 'window'] #NUS-WIDE-10K数据集的10个类别
print('loading all class names')
cls_id = {}
with open("Concepts81.txt", "r") as f:
for cid, line in enumerate(f):
cn = line.strip()
cls_id[cn] = cid
id_cls = {cls_id[k]: k for k in cls_id}
print('Finished, with {} classes.'.format(len(id_cls)))
'''
### 原来的提取代码
print('Extract and sample id from label files')
data_list = {}
class_files = os.listdir(label_dir)
class_files.remove('Labels_waterfall.txt') #手动取掉Labels_waterfall.txt这个文件防止出现错误
for class_file in class_files:
for clas in classes:
if clas in class_file:
print('class_file:' + class_file)
with open(os.path.join(label_dir, class_file), "r") as f:
i = []
for sid, line in enumerate(f):
if int(line) > 0:
i.append(sid)
print('total samples of {}:'.format(clas) + str(len(i)))
data_list[clas] = random.sample(i, 1000) #对每个类别随机抽取1000个数据
print('sample number of ' + clas + ':{}\n'.format(len(data_list[clas])))
'''
print('Extract and sample id from label files')
data_list = {}
fids = {}
lab_matri = []
class_files = os.listdir(label_dir)
for fid, class_file in enumerate(class_files):
clas = class_file.split('_')[1].split('.')[0]
if clas in classes:
fids[clas] = fid
with open(os.path.join(label_dir, class_file), "r") as f:
i = []
for sid, line in enumerate(f):
i.append(int(line))
lab_matri.append(i)
lab_matri = np.array(lab_matri).T
single_lab = np.sum(lab_matri, axis=1)==1
ind = np.arange(lab_matri.shape[0])
for clas in classes:
cid = fids[clas]
cla_lab = lab_matri[:, cid]==1
i = ind[cla_lab & single_lab].tolist() #统计出所有只有单标签的样本
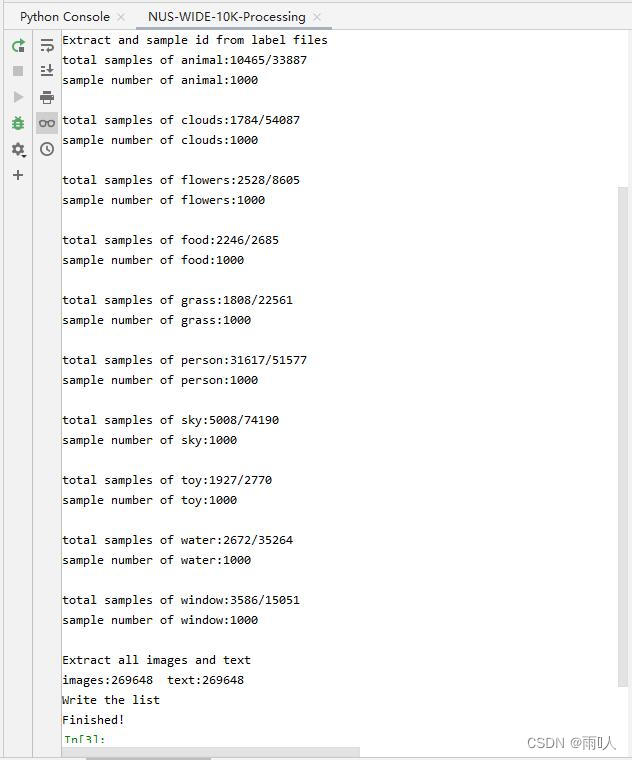
print('total samples of {}:'.format(clas) + str(len(i)) + '/' + str(np.sum(cla_lab)))
data_list[clas] = random.sample(i, 1000) # 对每个类别随机抽取1000个数据
print('sample number of ' + clas + ':{}\n'.format(len(data_list[clas])))生成NUS_WIDE_10k.list文件
- 为了方便使用,我们创建了NUS_WIDE_10k.list文件用于存储(图片地址,文本描述,样本类别)。
images = []
txts = []
with open(image_dir, "r") as f:
for line in f:
line = line.strip()
images.append(line)
with open(txt_dir, "r", encoding='utf-8') as f:
for line in f:
line = line.strip().split(' ')
txts.append(line[-1])
print('images:{} text:{}'.format(len(images), len(txts)))
print('Write the list')
with open(output_dir, "w", encoding='utf-8') as f:
for clas in classes:
for i in data_list[clas]:
f.write('{} {} {}\n'.format(images[i].split('\\')[0] + '/' + images[i].split('\\')[1], txts[i], clas))划分图片训练集和测试集
- 对于每个类别,有800、100、100张图片用于训练、验证和测试。
def split_train_val_nus_wide_10k(): #划分图片的训练集和测试集
count = 0
print('Split training and test set for images')
with open(output_dir, 'r', encoding='utf-8') as f:
for i, line in enumerate(f):
print("\r", end="")
print("Download progress: {}%: ".format(i/100), "▋" * (i // 100), end="")
sys.stdout.flush()
count += 1
line = line.strip().split(' ')
img = line[0]
doc = line[-1]
if count % 1000 < 900:
new_path = 'NUS_WIDE_10K/image_split/train/'
else:
new_path = 'NUS_WIDE_10K/image_split/val/'
if not os.path.exists(new_path + doc):
os.mkdir(new_path + doc)
image_path = 'Flickr/' + img
shutil.copyfile(image_path, new_path + doc + '/' + img.split('/')[-1])提取的输出结果
完整代码
import os
import numpy as np
import random
from tqdm import tqdm
import shutil
import sys
N_SAMPLE = 269648
label_dir = "Groundtruth/AllLabels"
image_dir = 'ImageList/ImageList.txt'
txt_dir = 'NUS_WID_Tags/All_Tags.txt'
output_dir = 'NUS_WIDE_10K/NUS_WIDE_10k.list'
classes = ['animal', 'clouds', 'flowers', 'food', 'grass', 'person', 'sky', 'toy', 'water', 'window'] #NUS-WIDE-10K数据集的10个类别
print('loading all class names')
cls_id = {}
with open("Concepts81.txt", "r") as f:
for cid, line in enumerate(f):
cn = line.strip()
cls_id[cn] = cid
id_cls = {cls_id[k]: k for k in cls_id}
print('Finished, with {} classes.'.format(len(id_cls)))
'''
### 原来的提取代码
print('Extract and sample id from label files')
data_list = {}
class_files = os.listdir(label_dir)
class_files.remove('Labels_waterfall.txt') #手动取掉Labels_waterfall.txt这个文件防止出现错误
for class_file in class_files:
for clas in classes:
if clas in class_file:
print('class_file:' + class_file)
with open(os.path.join(label_dir, class_file), "r") as f:
i = []
for sid, line in enumerate(f):
if int(line) > 0:
i.append(sid)
print('total samples of {}:'.format(clas) + str(len(i)))
data_list[clas] = random.sample(i, 1000) #对每个类别随机抽取1000个数据
print('sample number of ' + clas + ':{}\n'.format(len(data_list[clas])))
'''
print('Extract and sample id from label files')
data_list = {}
fids = {}
lab_matri = []
class_files = os.listdir(label_dir)
for fid, class_file in enumerate(class_files):
clas = class_file.split('_')[1].split('.')[0]
if clas in classes:
fids[clas] = fid
with open(os.path.join(label_dir, class_file), "r") as f:
i = []
for sid, line in enumerate(f):
i.append(int(line))
lab_matri.append(i)
lab_matri = np.array(lab_matri).T
single_lab = np.sum(lab_matri, axis=1)==1
ind = np.arange(lab_matri.shape[0])
for clas in classes:
cid = fids[clas]
cla_lab = lab_matri[:, cid]==1
i = ind[cla_lab & single_lab].tolist() #统计出所有只有单标签的样本
print('total samples of {}:'.format(clas) + str(len(i)) + '/' + str(np.sum(cla_lab)))
data_list[clas] = random.sample(i, 1000) # 对每个类别随机抽取1000个数据
print('sample number of ' + clas + ':{}\n'.format(len(data_list[clas])))
print('Extract all images and text')
images = []
txts = []
with open(image_dir, "r") as f:
for line in f:
line = line.strip()
images.append(line)
with open(txt_dir, "r", encoding='utf-8') as f:
for line in f:
line = line.strip().split(' ')
txts.append(line[-1])
print('images:{} text:{}'.format(len(images), len(txts)))
print('Write the list')
with open(output_dir, "w", encoding='utf-8') as f:
for clas in classes:
for i in data_list[clas]:
f.write('{} {} {}\n'.format(images[i].split('\\')[0] + '/' + images[i].split('\\')[1], txts[i], clas))
print('Finished!')
def split_train_val_nus_wide_10k(): #划分图片的训练集和测试集
count = 0
print('Split training and test set for images')
with open(output_dir, 'r', encoding='utf-8') as f:
for i, line in enumerate(f):
print("\r", end="")
print("Download progress: {}%: ".format(i/100), "▋" * (i // 100), end="")
sys.stdout.flush()
count += 1
line = line.strip().split(' ')
img = line[0]
doc = line[-1]
if count % 1000 < 900:
new_path = 'NUS_WIDE_10K/image_split/train/'
else:
new_path = 'NUS_WIDE_10K/image_split/val/'
if not os.path.exists(new_path + doc):
os.mkdir(new_path + doc)
image_path = 'Flickr/' + img
shutil.copyfile(image_path, new_path + doc + '/' + img.split('/')[-1])
split_train_val_nus_wide_10k()













 4399
4399











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









