






 本文深入探讨了 Meta 的 Llama 3 系列语言模型,介绍其性能亮点,如扩展词汇量、实施分组查询注意力等。还详细讲解了使用 HuggingFace 和 Ollama 等开源工具在本地部署和运行 Llama 3 模型的步骤,为开发者提供了实用的操作指南。
本文深入探讨了 Meta 的 Llama 3 系列语言模型,介绍其性能亮点,如扩展词汇量、实施分组查询注意力等。还详细讲解了使用 HuggingFace 和 Ollama 等开源工具在本地部署和运行 Llama 3 模型的步骤,为开发者提供了实用的操作指南。
引言
使用 Meta 的 Llama 3 系列探索 AI 语言模型的最新里程碑。从增加词汇量等进步到使用开源工具的实际实现,本文深入探讨了 Llama 3 的技术细节和基准测试。了解如何在本地部署和运行这些模型,释放它们在消费类硬件中的潜力。
学习目标
- 了解 Llama 3 系列模型的主要进步和基准,包括它们与以前的迭代和该领域其他模型相比的性能。
- 了解如何使用 HuggingFace Transformers 和 Ollama 等开源工具在本地部署和运行 Llama 3 模型,从而实现大型语言模型的实践体验。
- 探索 Llama 3 中的技术增强功能,例如增加的词汇量和分组查询注意力的实现,并了解它们对文本生成任务的影响。
- 深入了解 Llama 3 模型的潜在应用和未来发展,包括它们的开源性质、多模式功能以及微调和性能方面的持续进步。
Llama3 介绍
Llama 3 系列简介:语言模型的新时代。凭借 8B 和 70B 大小的预训练基础和聊天模型,它带来了重大进步。其中包括扩展的词汇量,现在为 128k 令牌,提高令牌编码效率并实现更好的多语言文本生成。此外,它还在所有模型中实施了分组查询注意力 (GQA),确保与其前身相比,响应更加连贯和扩展。
此外,Meta 严格的训练方案,仅为 8B 模型就使用了 15 万亿个代币,这表明它致力于突破自然语言处理的界限。随着多模态模型和更大的 400B+ 模型的计划即将到来,Llama 3 系列预示着 AI 语言建模的新时代,有望彻底改变各行各业的各种应用。
您可以点击这里访问模型:https://llama.meta.com/llama3/
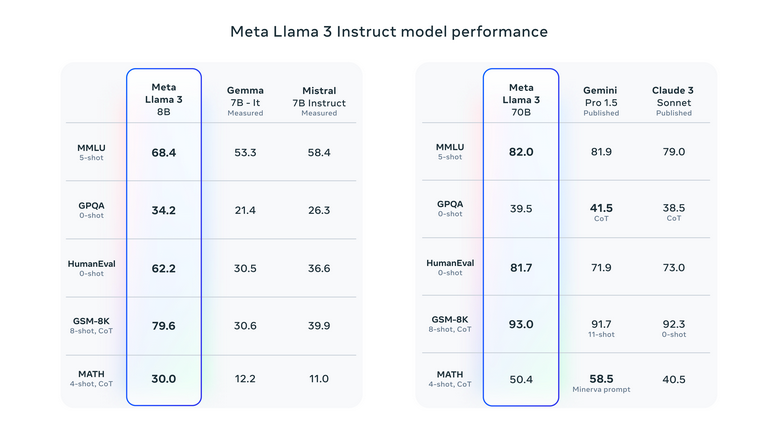
性能亮点
- Llama 3 模型在创意写作、编码和头脑风暴等各种任务中表现出色,设定了新的性能基准。
- 8B Llama 3 型号的性能明显优于以前的型号,接近 Llama 2 70B 型号的性能。
- 值得注意的是,Llama 3 70B 型号在基准测试中超过了 Gemini Pro 1.5 和 Claude Sonnet 等封闭型号。
- 开源性质允许轻松访问、微调和商业用途,模型提供自由许可。
在本地运行 Llama 3
具有所有这些性能指标的 Llama 3 是最适合在本地运行的模型。由于模型量化方法的进步,我们可以在消费类硬件内部运行 LLM。根据硬件规格,有不同的方法可以在本地运行这些模型。如果您的系统有足够的 GPU 内存 (~48GB),您可以舒适地运行全精度的 8B 模型和 4 位量化的 70B 模型。输出可能偏慢。您也可以使用云实例进行推理。在这里,我们将使用带有 16GB T4 GPU 的免费层 Colab 来运行量化的 8B 模型。4 位量化模型需要 ~5.7 GB 的 GPU 内存,这对于在 T4 GPU 上运行来说很好。
为了运行这些模型,我们可以使用不同的开源工具。下面是一些用于在本地运行模型的工具。
使用 HuggingFace
HuggingFace 已经推出了对 Llama 3 模型的支持。我们可以使用变形金刚库轻松地从 HuggingFace Hub 中提取模型。您可以安装全精度模型或 4 位量化模型。这是在 Colab 免费层上运行它的示例。
Step1:安装库
安装 accelerate 和 bitsandbytes 库并升级 transformers 库。
!pip install -U "transformers==4.40.0" --upgrade
!pip install accelerate bitsandbytes
Step2:安装模型
现在我们将安装模型并开始查询。
import transformers
import torch
model_id = "unsloth/llama-3-8b-Instruct-bnb-4bit"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={
"torch_dtype": torch.float16,
"quantization_config": {"load_in_4bit": True},
"low_cpu_mem_usage": True,
},
)
Step3:发送查询
现在向模型发送查询以进行推理。
messages = [
{"role": "system", "content": "You are a helpful assistant!"},
{"role": "user", "content": """Generate an approximately fifteen-word sentence
that describes all this data:
Midsummer House eatType restaurant;
Midsummer House food Chinese;
Midsummer House priceRange moderate;
Midsummer House customer rating 3 out of 5;
Midsummer House near All Bar One"""},
]
prompt = pipeline.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
terminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = pipeline(
prompt,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
print(outputs[0]["generated_text"][len(prompt):])
查询的输出:“下面是一个 15 字的句子,总结了数据:
Midsummer House是一家价格适中的中餐馆,在All Bar One附近拥有三星级评级。
Step4:安装 Gradio 并运行代码
您可以将其包装在 Gradio 中以具有交互式聊天界面。安装 Gradio 并运行以下代码。
import gradio as gr
messages = []
def add_text(history, text):
global messages #message[list] is defined globally
history = history + [(text,'')]
messages = messages + [{"role":'user', 'content': text}]
return history
def generate(history):
global messages
prompt = pipeline.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
terminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = pipeline(
prompt,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
response_msg = outputs[0]["generated_text"][len(prompt):]
for char in response_msg:
history[-1][1] += char
yield history
pass
with gr.Blocks() as demo:
chatbot = gr.Chatbot(value=[], elem_id="chatbot")
with gr.Row():
txt = gr.Textbox(
show_label=False,
placeholder="Enter text and press enter",
)
txt.submit(add_text, [chatbot, txt], [chatbot, txt], queue=False).then(
generate, inputs =[chatbot,],outputs = chatbot,)
demo.queue()
demo.launch(debug=True)
这是 Gradio 应用程序和 Llama 3 的演示。
使用 Ollama
Ollama 是另一个用于在本地运行 LLM 的开源软件。要使用 Ollama,您必须下载该软件。
Step1:启动本地服务器
下载后,使用此命令启动本地服务器。
ollama run llama3:instruct #for 8B instruct model
ollama run llama3:70b-instruct #for 70B instruct model
ollama run llama3 #for 8B pre-trained model
ollama run llama3:70b #for 70B pre-trained
Step2:通过API查询
curl http://localhost:11434/api/generate -d '{
"model": "llama3",
"prompt": "Why is the sky blue?",
"stream": false
}'
Step3:JSON响应
您将收到 JSON 响应。
{
"model": "llama3",
"created_at": "2024-04-19T19:22:45.499127Z",
"response": "The sky is blue because it is the color of the sky.",
"done": true,
"context": [1, 2, 3],
"total_duration": 5043500667,
"load_duration": 5025959,
"prompt_eval_count": 26,
"prompt_eval_duration": 325953000,
"eval_count": 290,
"eval_duration": 4709213000
}
结论
我们不仅发现了语言建模的进步,还发现了 Llama 3 的有用实现策略。现在,由于采用了 HuggingFace Transformers 和 Ollama 等技术,现在可以在本地运行 Llama 3,这为各行各业开辟了广泛的应用。展望未来,Llama 3 的开源设计鼓励创新和可访问性,为世界各地的开发人员都可以访问高级语言模型打开了大门。
关键要点
- Meta 推出了 Llama 3 系列模型,其中包含四个模型、8B 和 70B 预训练和指令调整模型。
- 这些模型在各自重量类别的多个基准测试中表现非常出色。
- Llama 3 现在使用与 Llama 2 不同的分词器,但增加了声音大小。现在,所模型都配备了分组查询注意力 (GQA),以便更好地生成文本。
- 虽然这些模型很大,但可以使用Llama和HiggingFace Transformers等开源工具使用量化在消费类硬件上运行它们。
本文中显示的媒体不归 Analytics Vidhya 所有,由作者自行决定使用。
来源:https://www.analyticsvidhya.com/blog/2024/04/how-to-run-llama-3-locally/



















 987
987

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









