







 本文介绍了使用MapReduce实现基于TF-IDF的精准广告推送算法。通过TF-IDF计算用户对华为手机的关注度权重,筛选出优质用户进行广告投放。实验详细步骤包括数据准备、MapReduce任务的编写与执行,最终得出各关键字的权重,实现精准广告推送功能。
本文介绍了使用MapReduce实现基于TF-IDF的精准广告推送算法。通过TF-IDF计算用户对华为手机的关注度权重,筛选出优质用户进行广告投放。实验详细步骤包括数据准备、MapReduce任务的编写与执行,最终得出各关键字的权重,实现精准广告推送功能。
TF-IDF的主要思想是,如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TF词频(Term Frequency)指的是某一个给定的词语在该文件中出现的次数。IDF反文档频率(Inverse Document Frequency)的主要思想是:如果包含词条的文档越少,IDF越大,则说明词条具有很好的类别区分能力。
要想精准的向用户推送广告。我们需要知道的一个重要因素是,用户对产品的关注程度,我们可以使用数据建模来将‘关注程度’这样一个抽象的名次转化为一个具体的数字。本次实验我们使用的关注度权重公式为:
W = TF * Log(N/DF)
TF:当前关键字在该条记录中出现的总次数;
N:总的记录数;
DF:当前关键字在所有记录中出现的条数;
实验环境
Linux Ubuntu 14.04
jdk-7u75-linux-x64
Hadoop 2.6.0-cdh5.4.5
实验内容
传统的广告形式有很多种,但是由于没有区分用户,盲目大量投送广告导致费用增大且收效甚微,在大数据时代,我们使用协同过滤算法和TF-IDF算法来实现精准广告推送功能,合理分类哪些是确切需要本产品的用户,向其投送相关产品的广告,降低成本且提高成功率。
本实验使用微博数据,找出哪些用户对华为手机感兴趣,关注程度是怎样的,计算出权重值。从而实现选出优质用户,向优质用户精准推送华为手机广告的功能。

结果数据为:

通过结果数据我们可以发现,每个关键字的权重已经计算出来了,如果我们想找到比较关注华为手机的用户,我们只需要把‘手机’、‘华为’、‘买’等关键字权重值高的用户提取出来即可。
1.首先,我们来准备实验需要用到的数据,切换到/data/mydata目录下,使用vim编辑一个tj_data.txt文件
- cd /data/mydata
- vim tj_data.txt
将如下数据写入其中:
- 小时光***糖你好 我最近发现我的华为p10后置摄像头照相模糊。这个对于我个只会手机支付身上不带钱的用户造成很大的困扰。我刚去花粉俱乐部看了下,不只有我一个人有这样的问题。请问下p10的后置摄像头是否是批次硬件问题。以及如何解决,求回应
- 小媳***结成风5 我的P10耗电太快
- 人***花u 凤凰古镇
- 全***信他 360全景图 教你手机拍微博全景图哦。
- 你说***了没 想去拍茶卡盐湖,一望无际
- 路***锡 岳麓山
- 让***忧1 世界任你拍
- 小***峰 我想去拍青海湖!华为P10plus有了,能送个机票吗
- 19***潮 喜马拉雅
- leo***海 最想和她在长江大桥上一起拍摄全景~
- 花生***商 我微薄有【落霞脆】冬枣转发抽奖哦,欢迎前来围观
- 愿我***有但是 想去大草原
- EX***的 我用的去年买的华为 nova现在用着挺好的,以后也会继续支持华为手机的,我想去杭州西湖,可是路上缺一个充电宝
- 捕风***冷 西藏,超漂亮的!!!而且已经去过了,可惜评论不能发图,不是会员
- Msh***kp 香港
- ting***15 北京 北京 上海
- 没钱***食了 天安门?
- 御***殿 华山
- 梁天***博 全景
- 星***R 迪士尼
- 毛***狼叼走 转发微博
- 滑***师 站在鼓楼紫峰大厦楼顶拍一张
2.使用wget命令下载IKAnalyzer2012_u6.jar包
- wget http://192.168.1.250:60000/allfiles/mr_sf/IKAnalyzer2012_u6.jar
3.切换到/apps/hadoop/sbin目录下,开启Hadoop相关进程
- cd /apps/hadoop/sbin
- ./start-all.sh
4.输入JPS查看一下相关进程是否已经启动。
- jps
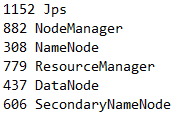
5.在HDFS的根下创建一个/tj/input目录,并将tj_data.txt文件上传到HDFS上的/tj/input文件夹下
- hadoop fs -mkdir /tj
- hadoop fs -mkdir /tj/input
- hadoop fs -put /data/mydata/tj_data.txt /tj/input
6.打开Eclipse,创建一个Java项目
项目名为:mr_sf
7.右键单击mr_sf项目,创建一个名为:mr_tj的包
8.创建一个名为:libs 的文件夹,用于存放项目所需的jar包
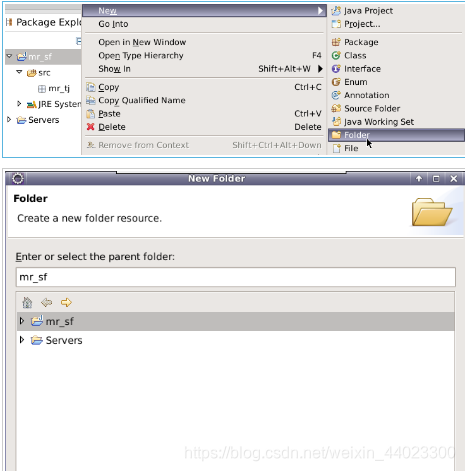
9.将/data/mydata文件夹下的IKAnalyzer2012_u6.jar包导入到libs文件夹下
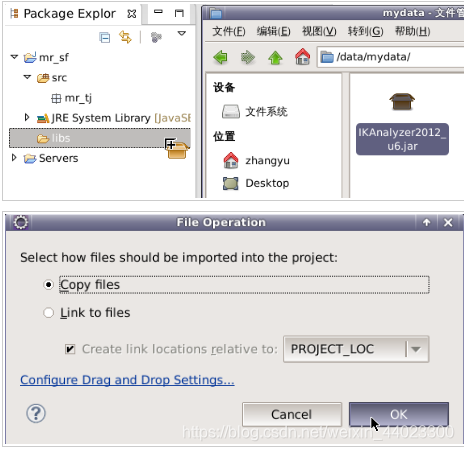
10.右键选中IKAnalyzer2012_u6.jar,依次选择Build Path=>Add to Build Path
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2286
2286

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









