









文章目录
一、机器学习(Machine Learning 简称ML)
机器学习的应用:
- 语音识别
- 自动驾驶
- 语言翻译
- 计算机视觉
- 推荐系统
- 无人机
二、深度学习(Deep Learning) - 机器学习中的一个领域
基于机器学习延伸出来的一个新的领域,由以人大脑结构为启发的神经网络算法为起源加以模型结构深度的增加发展,并伴随大数据和计算能力的提高而产生的一系列新的算法。
什么是神经网络
在机器学习里边有一个算法叫做神经网络算法,随着神经网络算法要求的计算能力越来越高,现在有一些突破性的影响。
深度学习能做什么?为什么近年来引起如此广泛的关注?
深度学习,作为机器学习中延伸出来的一个领域,被应用在图像处理与计算机视觉,自然语言处理以及语音识别等领域。自2006年至今,学术界和工业界合作在深度学习方面的研究与应用在以上几个领域取得了突破性的进展。以ImageNet为数据库的经典图像中的物体识别竞赛为例,击败了所有传统算法,取得了前所未有的精确度。
三、概念学习
人类学习概念:鸟,车,计算机
定义:概念学习是指有关某个布尔函数的输入输出训练样例中推断出该布尔函数
例子:学习“享受运动”这一概念:
小明进行水上运动是否享受运动取决于很多因素
天气:晴天、阴天、雨天
温度:冷、暖
湿度:普通、湿润
风力:强、弱
水温:暖、冷
预报:一样,变化
结果输出是
享受运动:是,否
概念定义在实例(instance)集合之上,这个集合表示为X。(X:所有可能的日子,每个日子的值由天气、温度、湿度、风力、水温,预报6个属性表示。)
待学习的概念或目标函数成为目标概念(target concept),记作c。
c(x)= 1当享受运动是,c(x)=0,当不享受运动时。c(x)也可以记作y
x:每一个实例
X:样例,所有实例的集合
学习目标:f:X->Y
训练集(training set/data)/训练样例(traning exanples)
用来进行训练,也就是产生模型或者算法的数据集
测试集(testing set/data)/测试样例(teating exanples)
用来专门进行测试已经学习好的模型或者算法的数据集
特征向量(features/fewturevertor)
属性的集合,通常用一个向量来表示,附属于一个实例
标记(label):c(x) ,实例类别的标记
正例(positive example)
反例(negative ezample)
信息获取量:
通过A来作为结点分类获取了多少信息量 gain(A) = info(D)- info_A(D) 有A的时候信息获取量减去,没有A的时候信息获取量,之差,就是A得信息度。
熵:
信息论的奠基人香农定义的用来信息量的单位。简单来说,熵就是“无序,混乱”的程度。
公式:H(X)=- Σ pi * logpi, i=1,2, … , n,pi为一个特征的概率
通过计算来理解:
原始样本数据的熵:
样例总数:4
好苹果:2
坏苹果:2
熵:-(1/2 * log(1/2) + 1/2 * log(1/2)) =1
信息熵为1表示当前处于最混乱,最无序的状态
上边用作判定树的构造中
噪音:
干扰项,在正确数据集里的错误数据
四、一些优秀的书籍
机器学习

深度学习

全球知名AI大赛

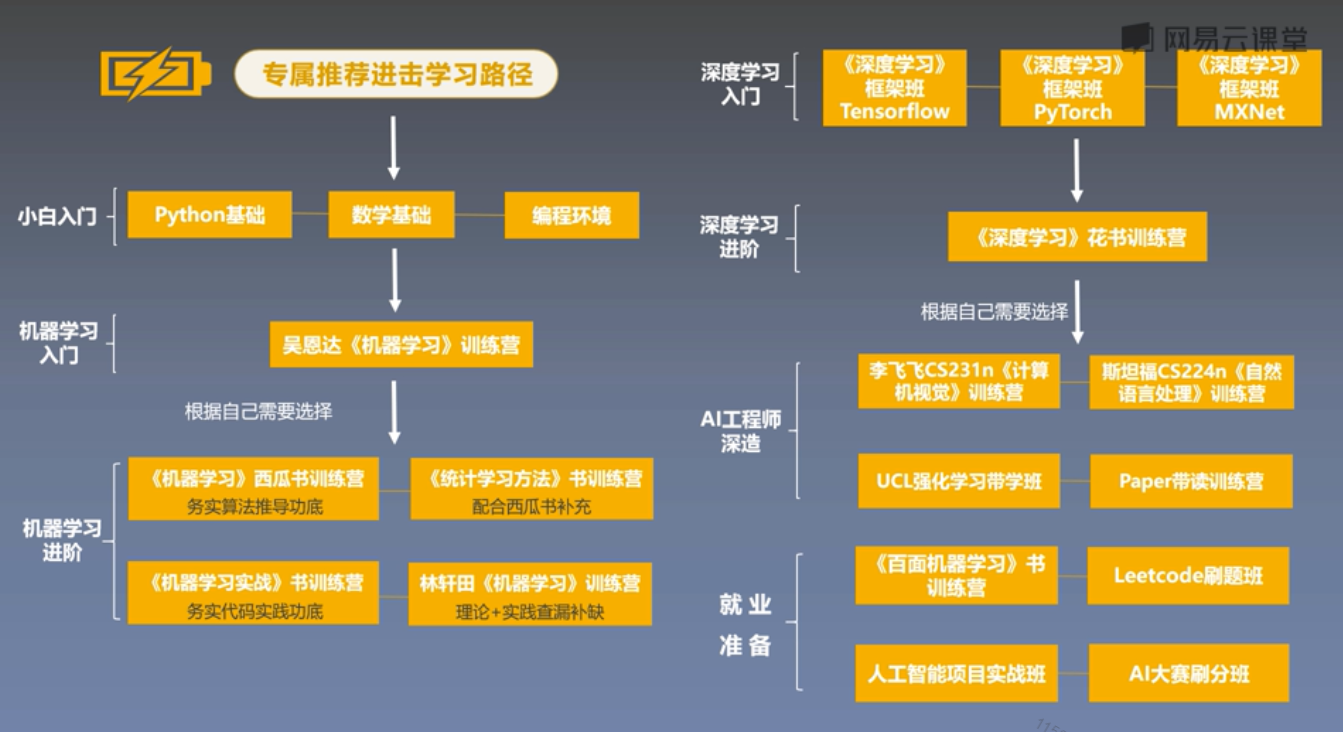
学习路径
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











