







📌引言
在前一阶段的学习中,我们完成了数据预处理等上游操作,接下来就要开始进行模型的构建。
📌构建模型
sklearn中提供各种机器学习模型的类供我们使用,我们要根据我们的业务逻辑进行相关的筛选进行构建调参。
在本例中我将使用sklearn内置的数据集即california房价预测数据集做示范,来演示模型构建的过程,相关模型的总结也在更新中。首先我们引入数据集,代码如下:
from sklearn.datasets import fetch_california_housing
# 构建DataFrame数据类型
x = pd.DataFrame(x, columns=housing_california.feature_names)
y = pd.DataFrame(y, columns=['price'])
# 合并方便处理
data = pd.merge(x, y, left_index=True, right_index=True)
在读取数据后,我们暂时不对其进行相关的EDA操作,我们接下来构建一个简单的线性模型:
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model = model.fit(x,y)
在构建了相关模型之后,我们可以调用属性查看其截距以及权重,代码如下:
# 查看模型截距
print('intercept:'+ str(model.intercept_))
# 查看每一个特征的权重
print(x.columns)
print(model.coef_)
结果如下:
Index(['MedInc', 'HouseAge', 'AveRooms', 'AveBedrms', 'Population', 'AveOccup',
'Latitude', 'Longitude'],
dtype='object')
[[ 4.36693293e-01 9.43577803e-03 -1.07322041e-01 6.45065694e-01
-3.97638942e-06 -3.78654265e-03 -4.21314378e-01 -4.34513755e-01]]
📌交叉验证
在我们训练模型后,通常都需要把数据集分为训练集和测试集旨在于评估我们构建的模型。
交叉验证是非常常用的一种划分方式,我们通常会把数据集分成N个部分,每次都留下一个部分不进行训练并将其作为评估集,将其他的N-1个部分进行训练,这样我们就能进行N次的评估,最终能够反映出我们的模型的效果。
这个过程就成为N折交叉检验。
当然sklearn中也提供了相关代码,如下所示:
# 导入交叉验证的包
from sklearn.model_selection import cross_val_score
# 导入评价指标
from sklearn.metrics import mean_absolute_error, make_scorer
# 5折交叉验证
scores = cross_val_score(model, X=x, y=y, verbose=1, cv = 5, scoring=make_scorer(mean_absolute_error))
结果如下:
array([0.54599439, 0.5661782 , 0.57654952, 0.53190614, 0.5168527 ])
本节中主要函数说明:
🔖cross_val_score的主要参数及其说明:
- estimator:我们选择的模型,在本例中为线性模型。
- x:各特征的值即我们的数据
- y: 我们预测的目标
- verbose:显示日志的密集程度
- cv:验证的折数,默认为5折
- scoring:评分选项,可以使用字符串或者使用评分函数,默认为该模型的默认评价指标
🔖make_scorer的含义说明:可以简单理解为帮我们构建一个评价指标的函数,例如本题中我们使用了标准差相关的值作为评价指标,这时就需要我们构建一个评分函数。
📌绘制学习率曲线与验证曲线
绘制学习率曲线但能够帮助我们直观的观察到学习的效果,sklearn内置了相关的函数帮助我们返回绘图需要的参数等内容。与此同时也提供了相关示例函数,我们可以直接调用,代码如下:
def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None,n_jobs=1, train_size=np.linspace(.1, 1.0, 5 )):
plt.figure()
plt.title(title)
if ylim is not None:
plt.ylim(*ylim)
plt.xlabel('Training example')
plt.ylabel('score')
# 注意这里的参数
train_sizes, train_scores, test_scores = learning_curve(estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_size, scoring = make_scorer(mean_absolute_error))
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
plt.grid()#区域
plt.fill_between(train_sizes, train_scores_mean - train_scores_std,
train_scores_mean + train_scores_std, alpha=0.1,
color="r")
plt.fill_between(train_sizes, test_scores_mean - test_scores_std,
test_scores_mean + test_scores_std, alpha=0.1,
color="g")
plt.plot(train_sizes, train_scores_mean, 'o-', color='r',
label="Training score")
plt.plot(train_sizes, test_scores_mean,'o-',color="g",
label="Cross-validation score")
plt.legend(loc="best")
return plt
plot_learning_curve(LinearRegression(), 'Liner_model', train_X[:1000], train_y_ln[:1000], ylim=(0.0, 0.5), cv=5, n_jobs=1)
绘制结果如下:
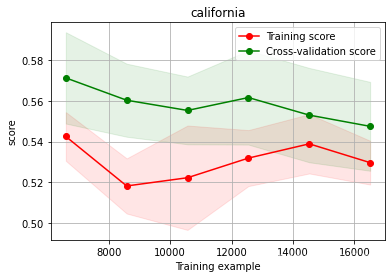
上图中,横轴表示训练的集合的规模,纵轴表示make_score表示的模型得分。上述红线和绿线分别表示训练集和验证集的得分情况。在整个函数中,核心代码如下所示:
train_sizes, train_scores, test_scores = learning_curve(estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_size, scoring = make_scorer(mean_absolute_error))
其中参数的含义和上述的多折交叉验证的函数内容相近。
📌调节参数
📄贪心调参
贪心调参的含义非常好理解,本质上就是先不去管参数之间的组合效果,只关注某一个参数的最优解,然后将每一个单个参数最优解组合起来作为最后的所有参数的”最优解“。
由于线性模型的参数有限,我们这里选择拟合一个LGM回归模型进行调节。首先定义参数的范围,代码如下:
objective = ['regression', 'regression_l1', 'mape', 'huber', 'fair']
num_leaves = [3,5,10,15,20,40, 55]
max_depth = [3,5,10,15,20,40, 55]
bagging_fraction = []
feature_fraction = []
drop_rate = []
接下来分别定义不同参数的字典,然后进行迭代组成各个参数对应的效果字典,代码如下:
from lightgbm.sklearn import LGBMRegressor
best_obj = dict()
for obj in objective:
model = LGBMRegressor(objective=obj)
score = np.mean(cross_val_score(model, X=x, y=y, verbose=0, cv = 5, scoring=make_scorer(mean_absolute_error)))
best_obj[obj] = score
best_leaves = dict()
for leaves in num_leaves:
model = LGBMRegressor(objective=min(best_obj.items(), key=lambda x:x[1])[0], num_leaves=leaves)
score = np.mean(cross_val_score(model, X=x, y=y, verbose=0, cv = 5, scoring=make_scorer(mean_absolute_error)))
best_leaves[leaves] = score
best_depth = dict()
for depth in max_depth:
model = LGBMRegressor(objective=min(best_obj.items(), key=lambda x:x[1])[0],
num_leaves=min(best_leaves.items(), key=lambda x:x[1])[0],
max_depth=depth)
score = np.mean(cross_val_score(model, X=x, y=y, verbose=0, cv = 5, scoring=make_scorer(mean_absolute_error)))
best_depth[depth] = score
结果如下:
{'regression': 0.43628000591656946, 'regression_l1': 0.43036655891586273, 'mape': 0.4495588880634272, 'huber': 0.4362415646147303, 'fair': 0.4434959169203731}
{3: 0.4692277776989088, 5: 0.4364924362811631, 10: 0.42957073060595763, 15: 0.42567112024190434, 20: 0.42211690780268585, 40: 0.4236164822111624, 55: 0.4236164822111624}
{3: 0.5071922196364568, 5: 0.4740398871234621, 10: 0.447550821972231, 15: 0.4335147707917598, 20: 0.4298314808260941, 40: 0.42771562788993445, 55: 0.4236164822111624}
为了更直观的观察我们调节参数的作用,可以绘制曲线观察:
sns.lineplot(x=['0_initial','1_turning_obj','2_turning_leaves','3_turning_depth'], y=[cross_val_score(LGBMRegressor(), X=x, y=y, verbose=0, cv = 5, scoring=make_scorer(mean_absolute_error)).mean() ,min(best_obj.values()), min(best_leaves.values()), min(best_depth.values())])
结果如下:

可以看到,效果还是比较显著的,但是由于数据处理和特征工程我们没有进行,所以最终的预测效果很有限,再一次说明了EDA的重要性。
📄网格调参
网格调参会考虑到多种不同的参数组合对最终效果的影响,但是耗费时间较长。代码如下:
from sklearn.model_selection import GridSearchCV
parameters = {'objective': objective , 'num_leaves': num_leaves, 'max_depth': max_depth}
model = LGBMRegressor()
clf = GridSearchCV(model, parameters, cv=5)
clf = clf.fit(train_X, train_y)
我们也可以查看其参数,代码如下:
clf.best_params_
结果如下:
{'max_depth': 5, 'num_leaves': 15, 'objective': 'fair'}
我们来看一下最优的效果如下:
model = LGBMRegressor(max_depth=5, num_leaves=15, objective='fair')
np.mean(cross_val_score(model, X=x, y=y, verbose=0, cv = 5, scoring=make_scorer(mean_absolute_error), n_jobs=-1))
效果:
0.4392431898809616
📄贝叶斯调参
贝叶斯调参会根据当前的参数组合情况再次拟合一个新的概率函数,为我们搜索最佳组合参数的过程节省很多时间。代码如下:
from bayes_opt import BayesianOptimization
# 构建一个目标函数
def rf_cv(num_leaves, max_depth, subsample, min_child_samples):
val = cross_val_score(
LGBMRegressor(objective = 'regression_l1',
num_leaves=int(num_leaves),
max_depth=int(max_depth),
subsample = subsample,
min_child_samples = int(min_child_samples)
),
X=train_X, y=train_y_ln, verbose=0, cv = 5, scoring=make_scorer(mean_absolute_error)
).mean()
return 1 - val
# 构建一个参数范围的对象
f_bo = BayesianOptimization(
rf_cv,
{
'num_leaves': (2, 100),
'max_depth': (2, 100),
'subsample': (0.1, 1),
'min_child_samples' : (2, 100)
}
)
注意:由于这里的贝叶斯只能做最大化的优化,因为我们希望我们的平均绝对误差尽可能地小,所以我们在最后的返回值取了反数。
然后即可开始搜索,代码如下:
rf_bo.maximize()
结果如下:
| iter | target | max_depth | min_ch... | num_le... | subsample |
-------------------------------------------------------------------------
| 1 | 0.4984 | 16.15 | 13.16 | 3.084 | 0.4561 |
| 2 | 0.5601 | 32.17 | 26.8 | 32.27 | 0.4607 |
| 3 | 0.5514 | 47.0 | 86.45 | 76.86 | 0.7586 |
| 4 | 0.544 | 35.24 | 3.962 | 59.98 | 0.6889 |
| 5 | 0.4967 | 57.87 | 92.19 | 3.118 | 0.957 |
| 6 | 0.5418 | 38.1 | 2.988 | 60.51 | 0.3509 |
| 7 | 0.5572 | 34.04 | 40.22 | 53.17 | 1.0 |
| 8 | 0.5592 | 61.94 | 32.95 | 37.47 | 1.0 |
| 9 | 0.5507 | 77.05 | 51.96 | 74.87 | 0.5208 |
| 10 | 0.5528 | 28.18 | 53.3 | 100.0 | 1.0 |
| 11 | 0.5155 | 2.0 | 72.38 | 72.06 | 0.1 |
| 12 | 0.5503 | 73.47 | 82.27 | 100.0 | 0.1 |
| 13 | 0.5488 | 56.16 | 33.08 | 100.0 | 1.0 |
| 14 | 0.5629 | 100.0 | 18.31 | 39.3 | 1.0 |
| 15 | 0.5484 | 100.0 | 8.808 | 7.173 | 0.1 |
| 16 | 0.5499 | 98.16 | 4.917 | 73.32 | 0.4577 |
| 17 | 0.5565 | 100.0 | 48.37 | 39.62 | 1.0 |
| 18 | 0.5136 | 2.0 | 8.164 | 100.0 | 1.0 |
| 19 | 0.5542 | 100.0 | 100.0 | 69.57 | 1.0 |
| 20 | 0.549 | 76.4 | 2.0 | 33.25 | 0.4593 |
| 21 | 0.5492 | 99.08 | 46.1 | 98.18 | 0.8922 |
| 22 | 0.5507 | 100.0 | 100.0 | 100.0 | 1.0 |
| 23 | 0.551 | 37.12 | 100.0 | 100.0 | 1.0 |
| 24 | 0.445 | 100.0 | 44.99 | 2.0 | 1.0 |
| 25 | 0.562 | 100.0 | 35.62 | 61.27 | 0.1 |
| 26 | 0.5586 | 100.0 | 68.91 | 60.88 | 1.0 |
| 27 | 0.445 | 2.0 | 100.0 | 2.0 | 0.1 |
| 28 | 0.5568 | 71.21 | 100.0 | 54.19 | 0.1 |
| 29 | 0.5604 | 100.0 | 100.0 | 36.36 | 0.1 |
| 30 | 0.5607 | 68.4 | 66.12 | 47.9 | 0.1 |
=========================================================================
由于我们上边取了反数,所以我们最后的最优结果需要取反数看一下:
1 - rf_bo.max['target']
结果如下:
0.43707281089760364
最优的参数组合在实际代码中会变色,但是这里由于文字格式的原因没有区别。
📕总结
在本文中我们从实践的角度出发介绍了构建模型,调节参数,绘制曲线的方法。
在实际的应用中,我们还需要根据具体业务选择不同的模型,绘制不同的图表来更好地表现我们的结果。
最后,模型的内部理论也是非常重要的,在接下来我会一直更新相关模型的内部理论。
另外,从数据处理到构建高效模型系列已经全部更新完毕,感兴趣的朋友可以点击下列链接进行支持一下:

















 665
665











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











