






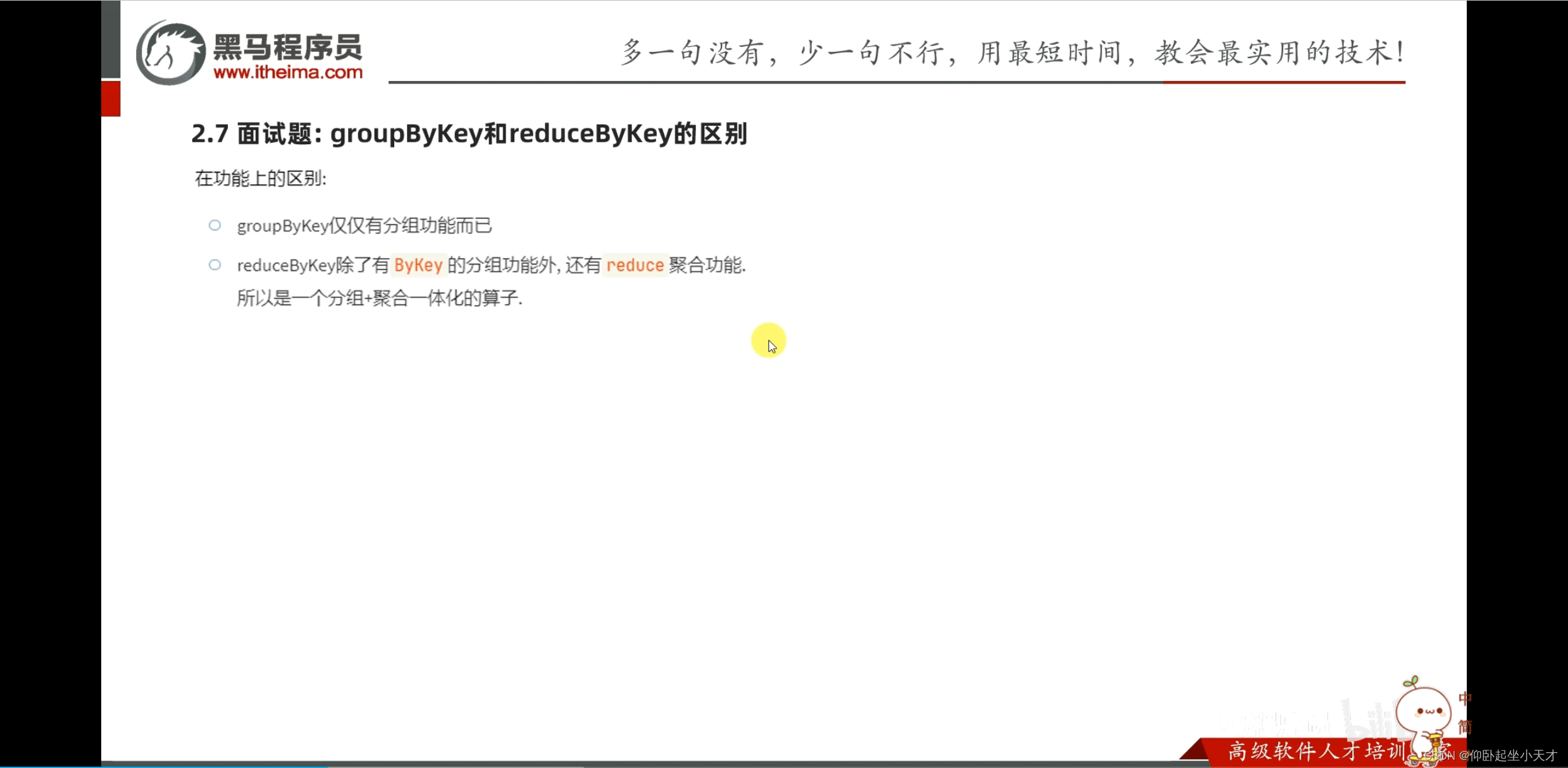
软件安装
写了,未保存
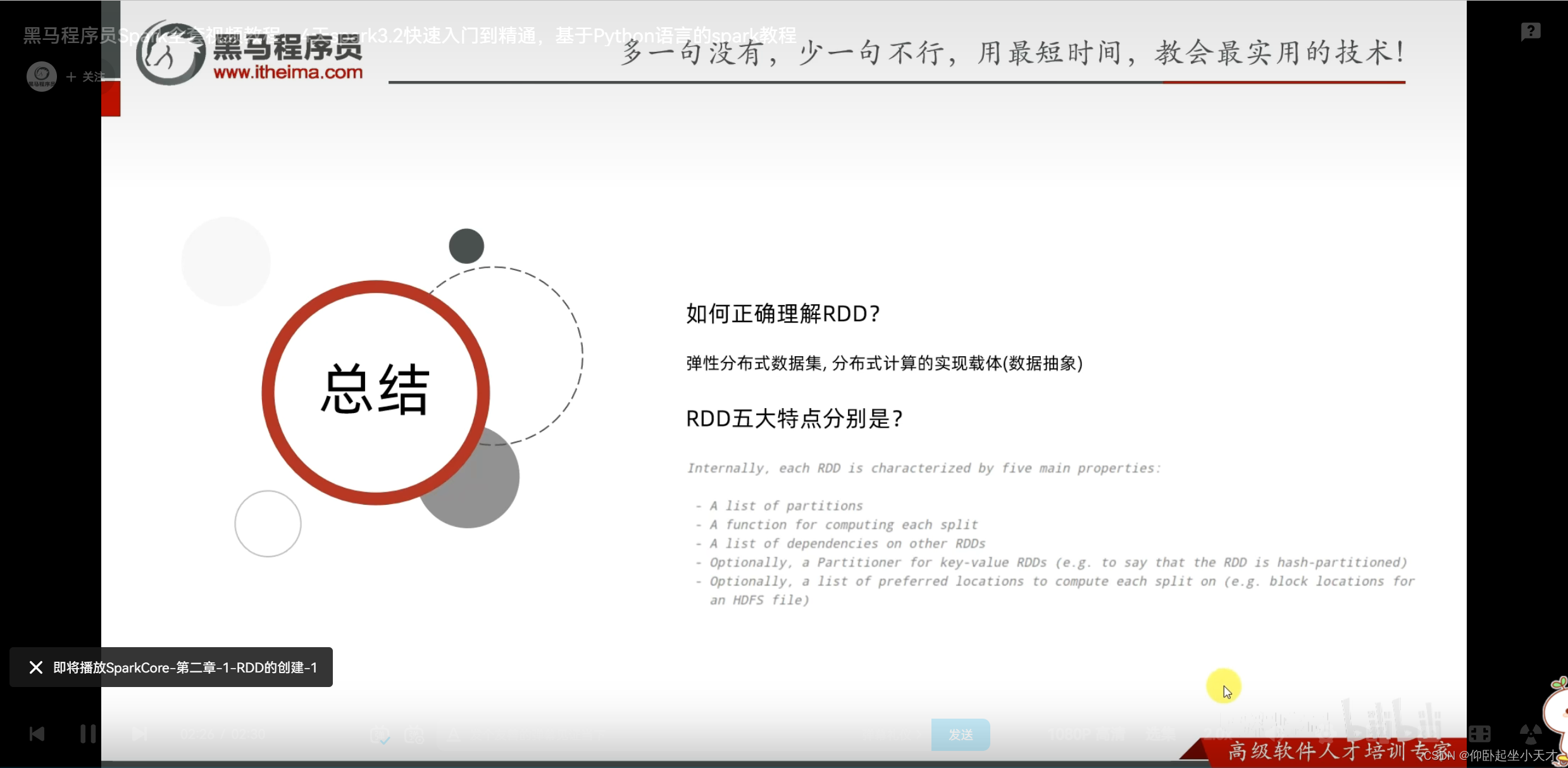
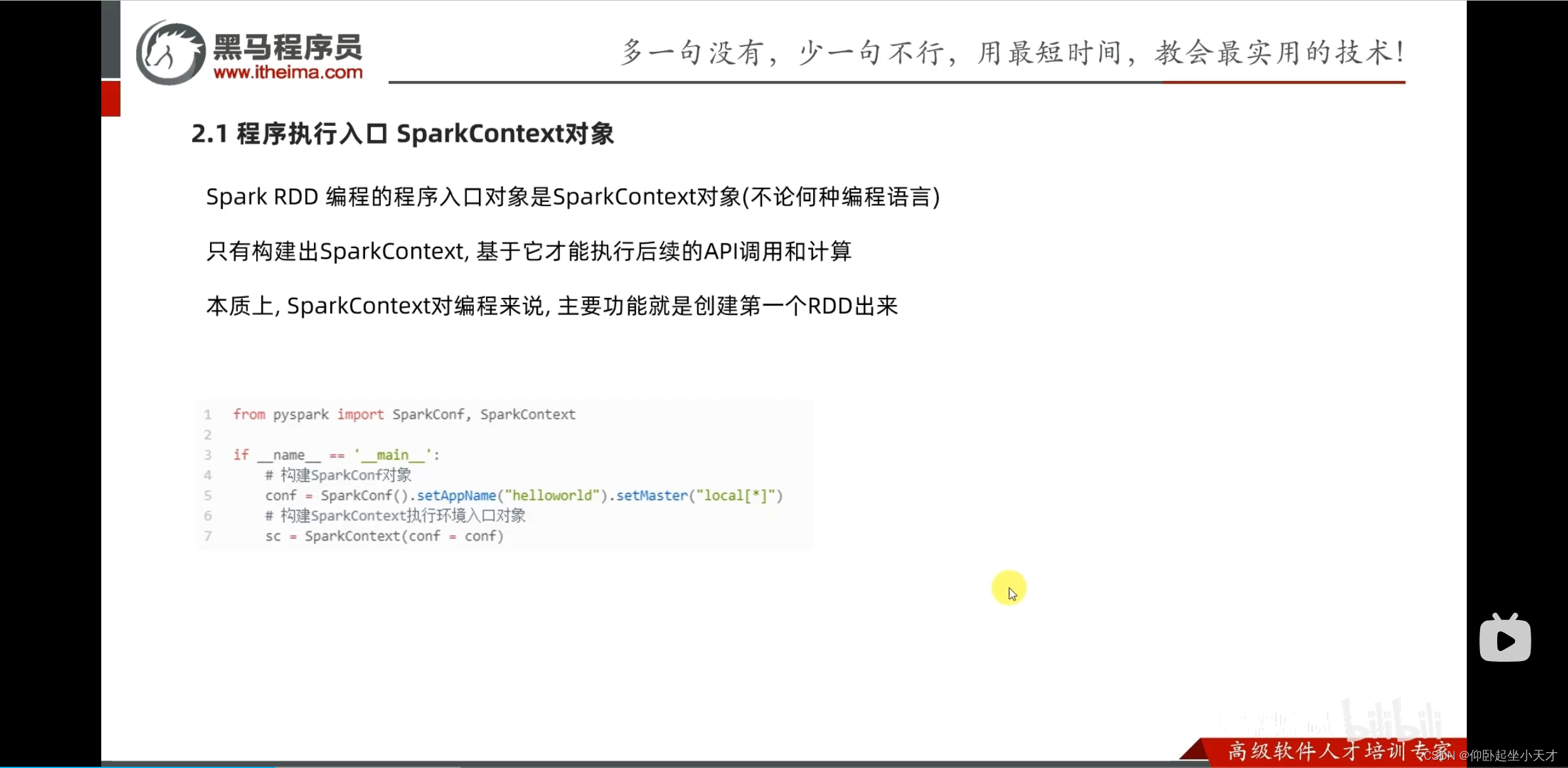
RDD入门
SparkCore-第一章-1.1-什么是RDD_哔哩哔哩_bilibili

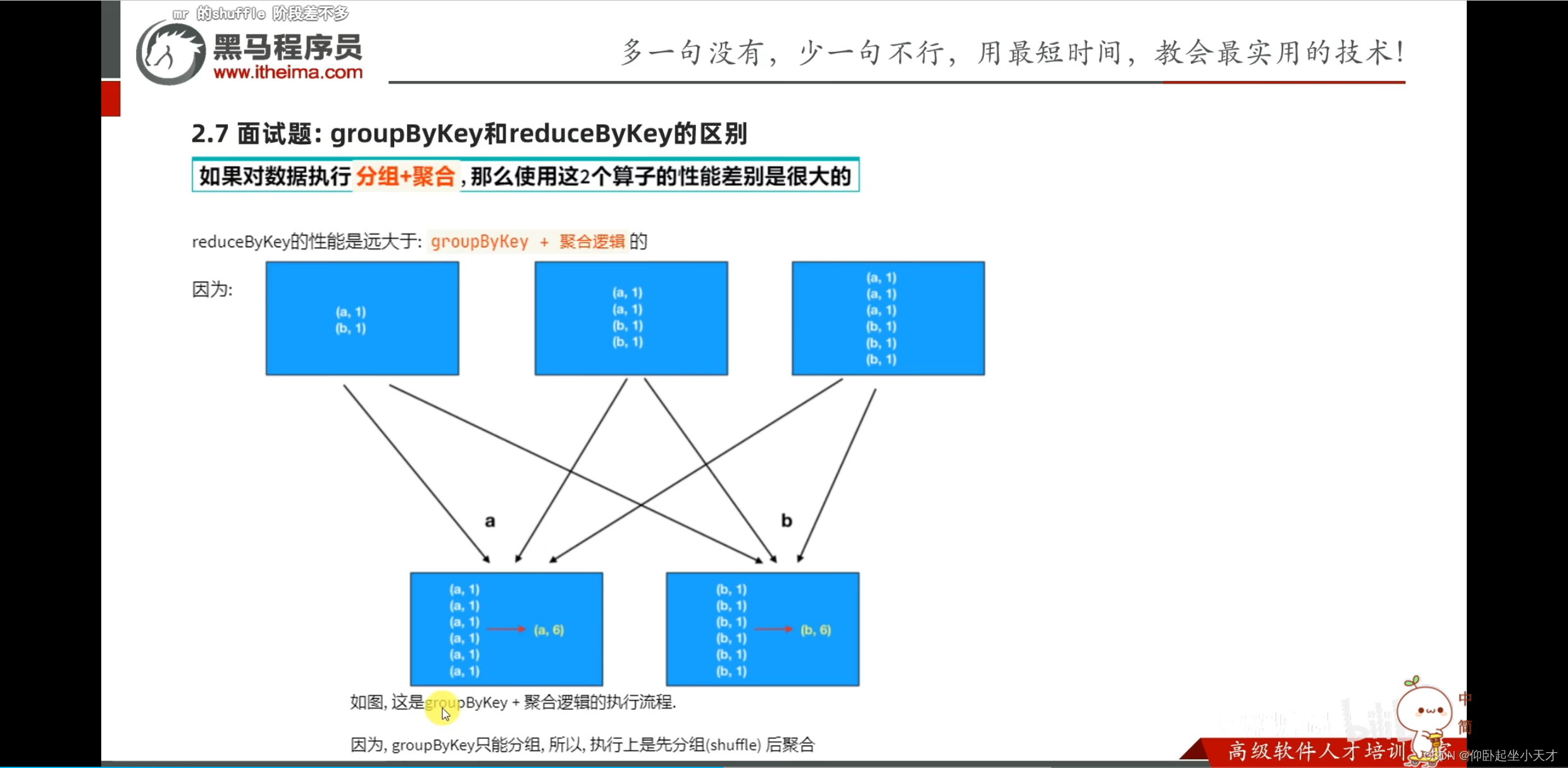
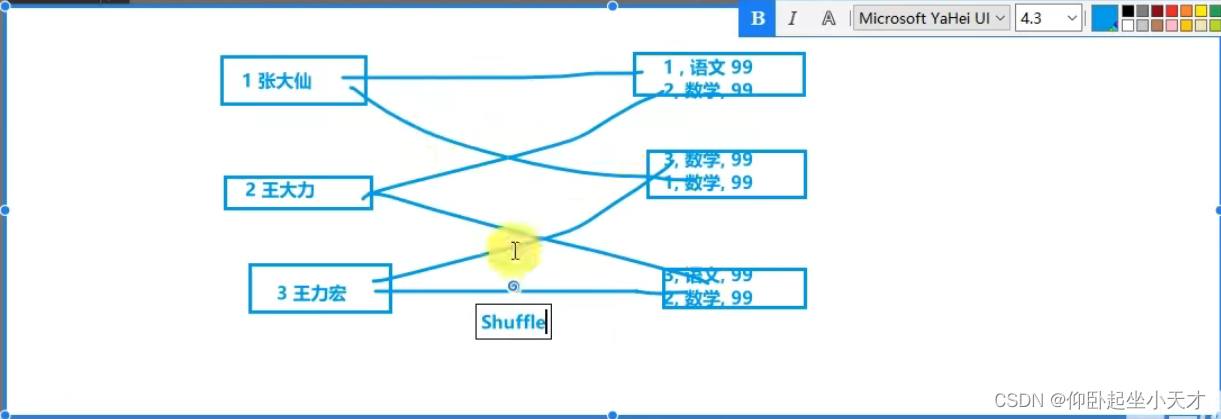
附:1. 不同的分区需要数据共享和传输。数据洗牌成为shuffle
2. 很难用python来做分布式。比如创建10个list来并行计算,太麻烦。而RDD可以实现
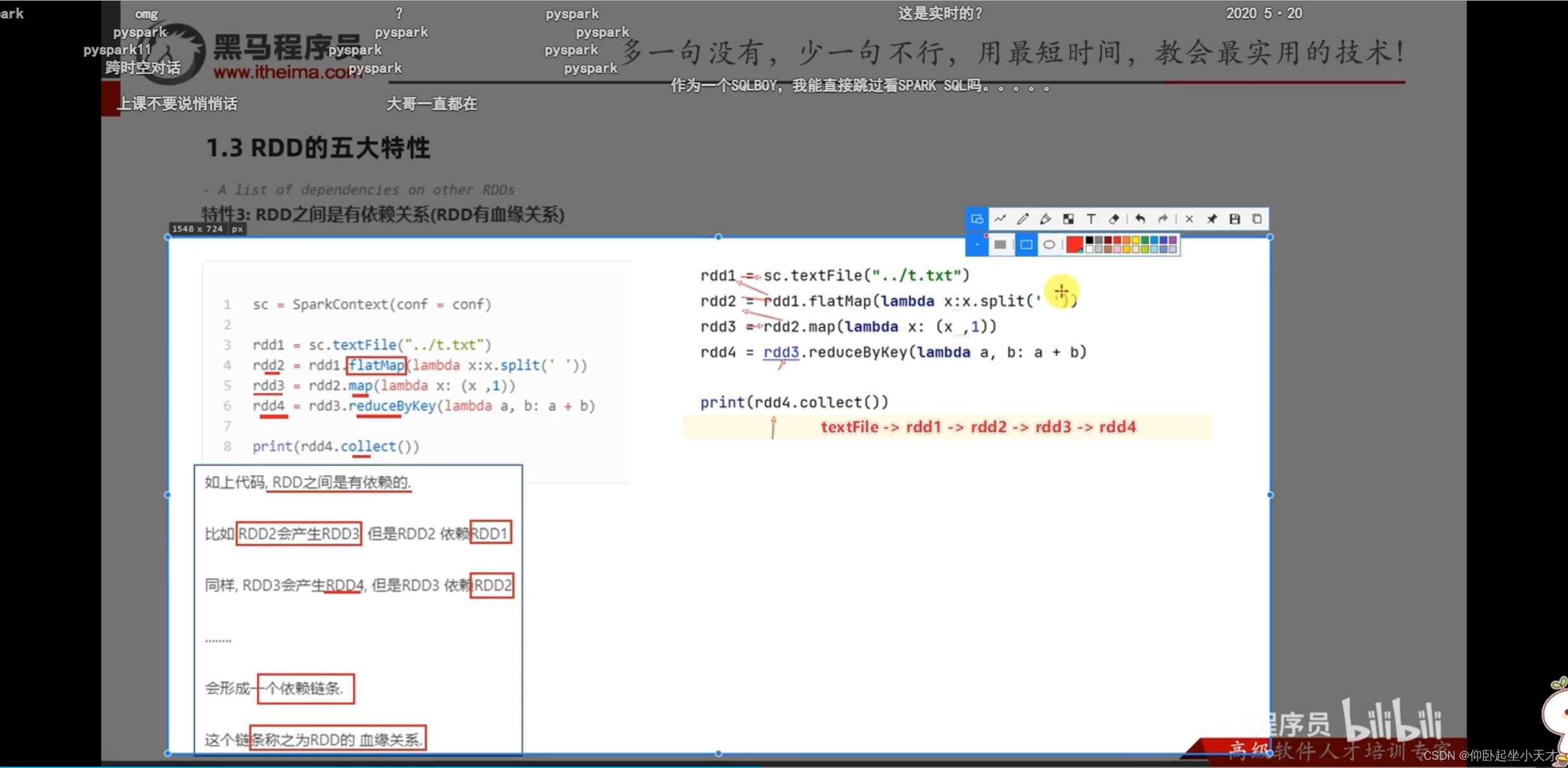
3. RDD是spark中最核心的数据抽象对象。
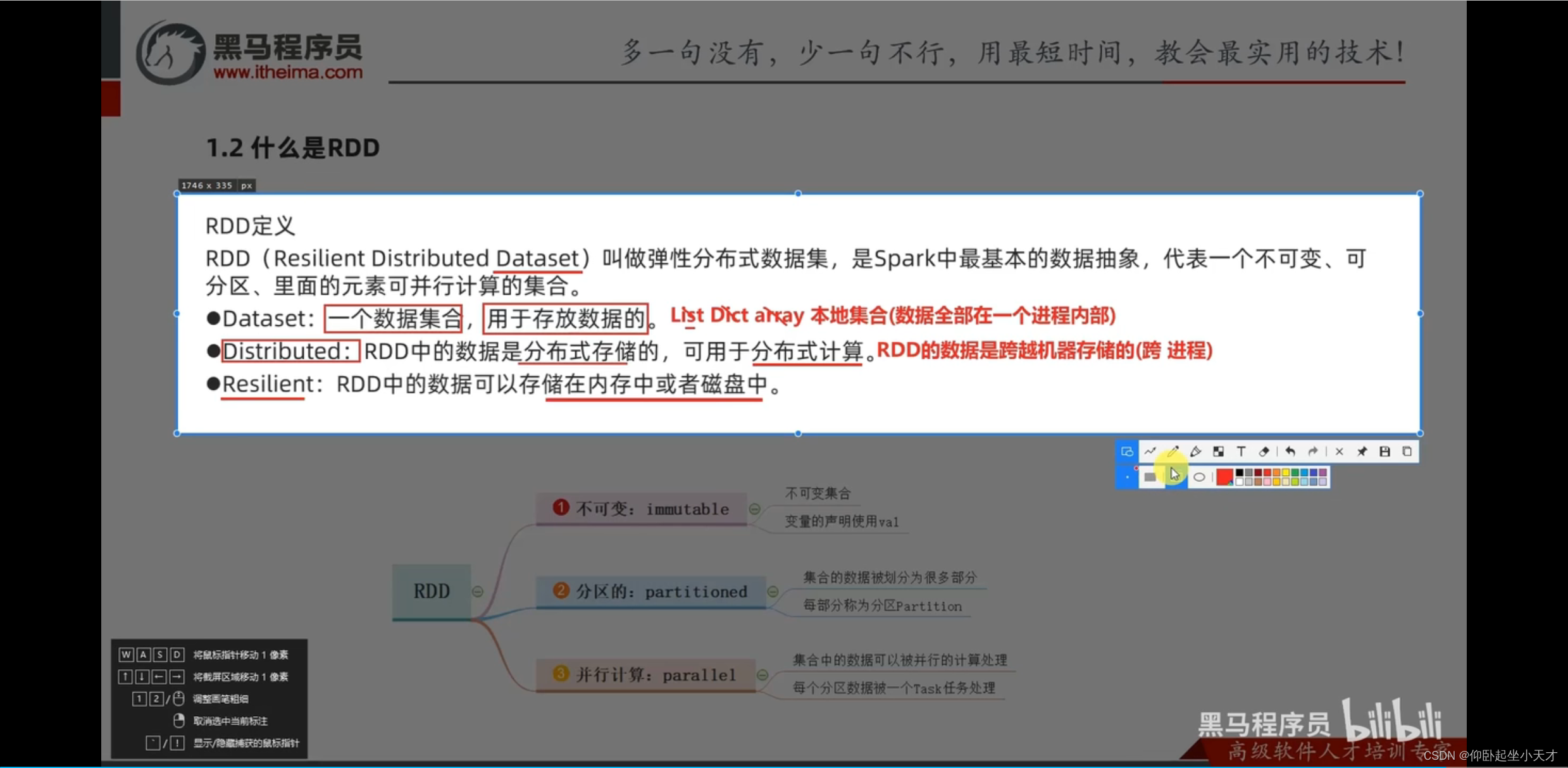
附:Resilient:数据可以存在内存或硬盘中,也可以互相传递,并且可以分区。可以进行动态扩容、缩容。(可以看做是增强的list对象)
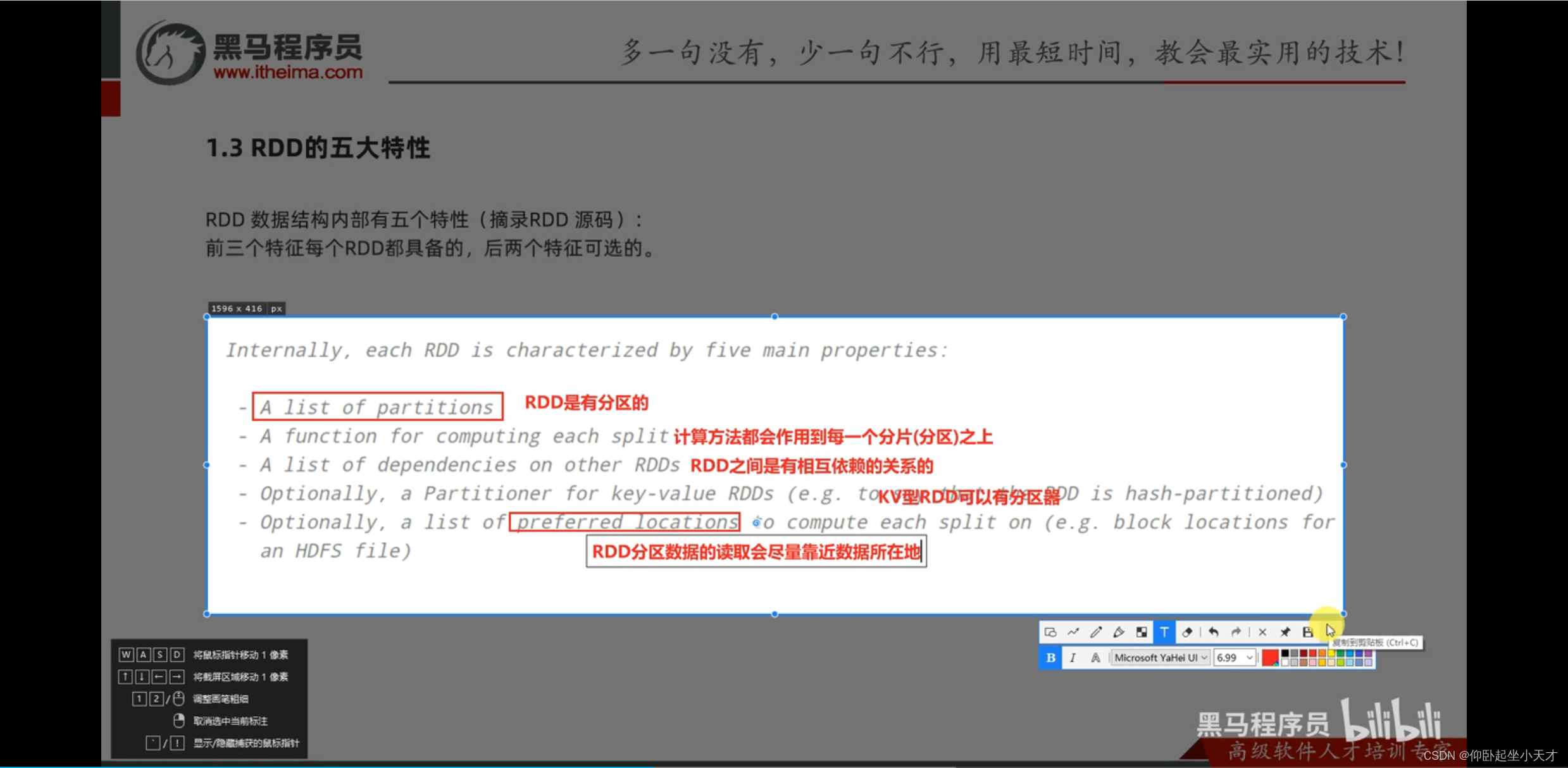
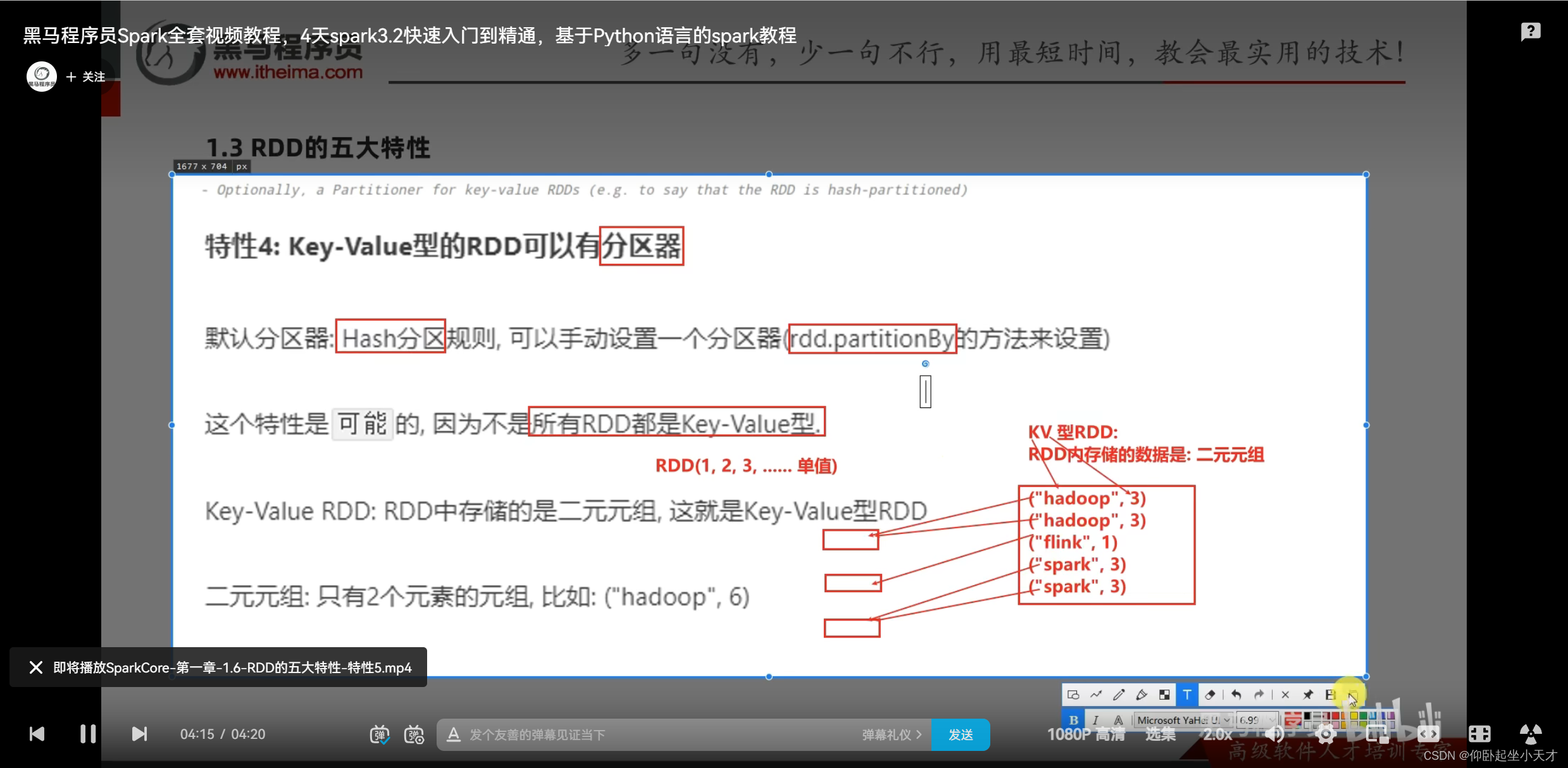
附:尽量确保,但不是百分百确保本地读取:如在例子中,若设定为2个executor,则会把分区规划在1和3上,这就是本地读取。若设定为3个executor,则会3个分区都有。此时如果百分百确保本地读取的话,则只会把分区规划在1和3,但因为数据读取只是一步,分区计算你是更重要的,所以不会采用这种做法,而是3个都规划,这就是尽量确保但不是百分百确保本地读取的意思。
worldcount代码执行的图示(可体现RDD五大特性)
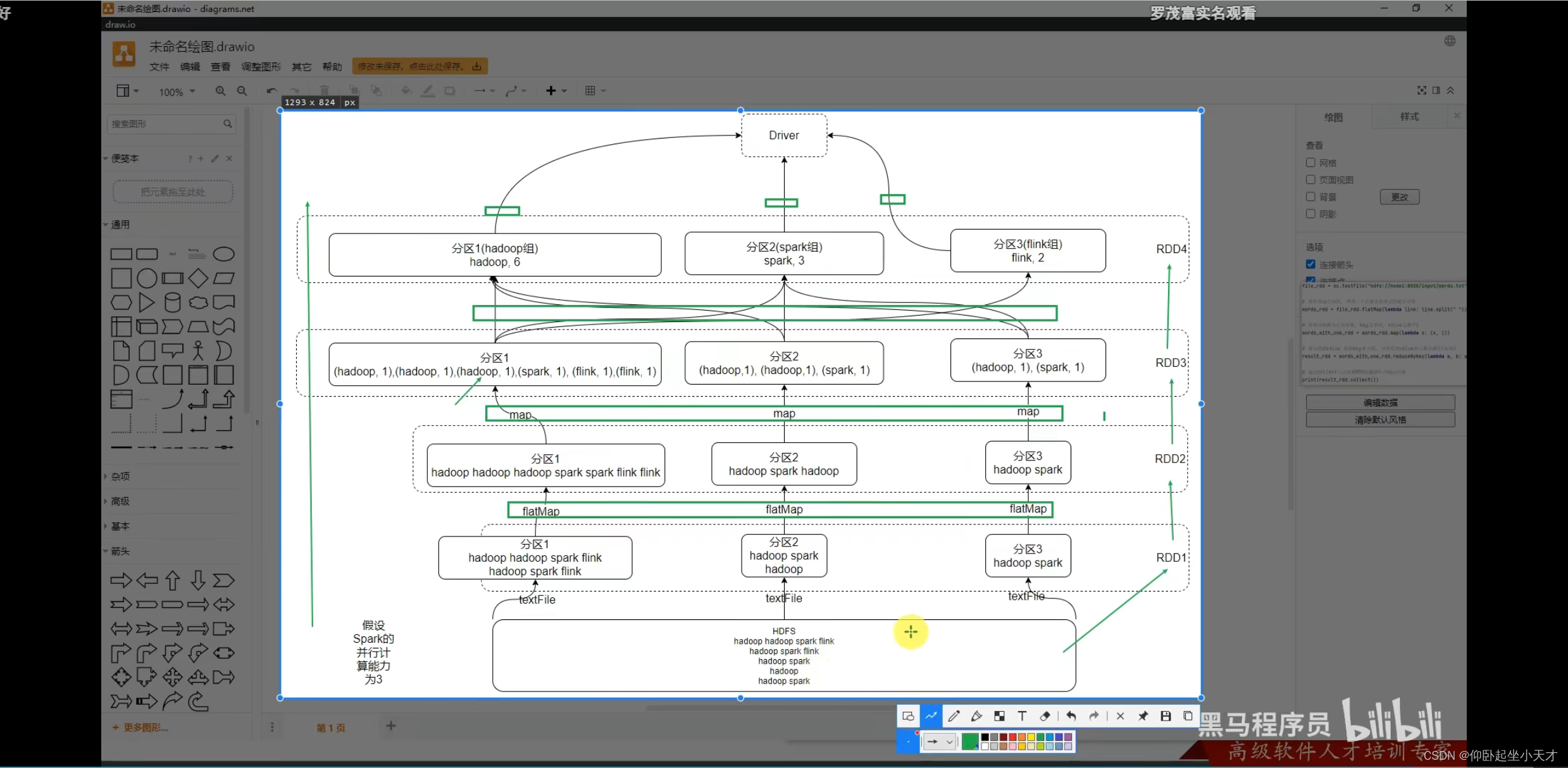
附:1. 并行计算能力为3:即3个分区。
2. 图中的分区是例子,可能不是实际的分区。
RDD编程入门
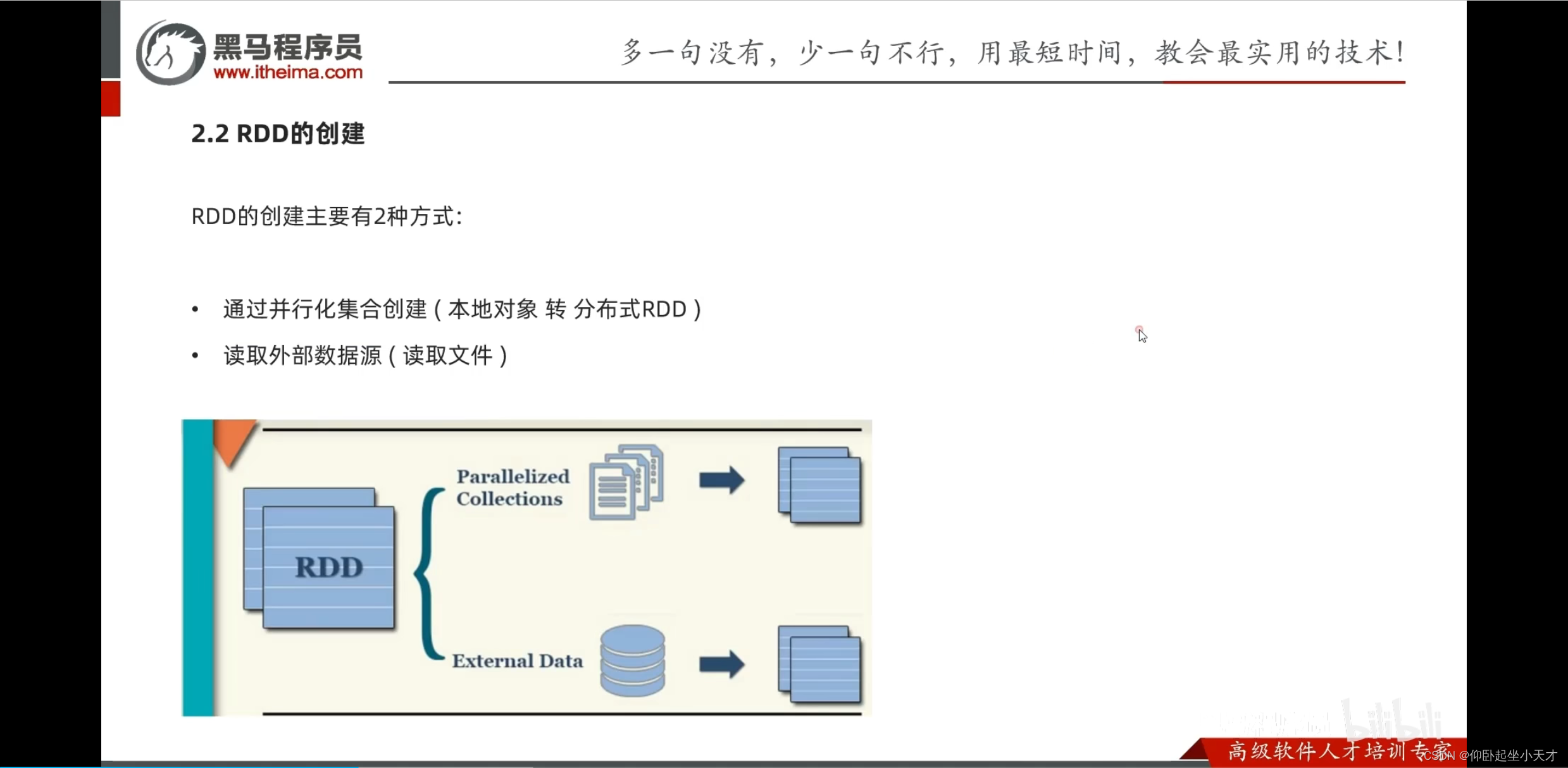
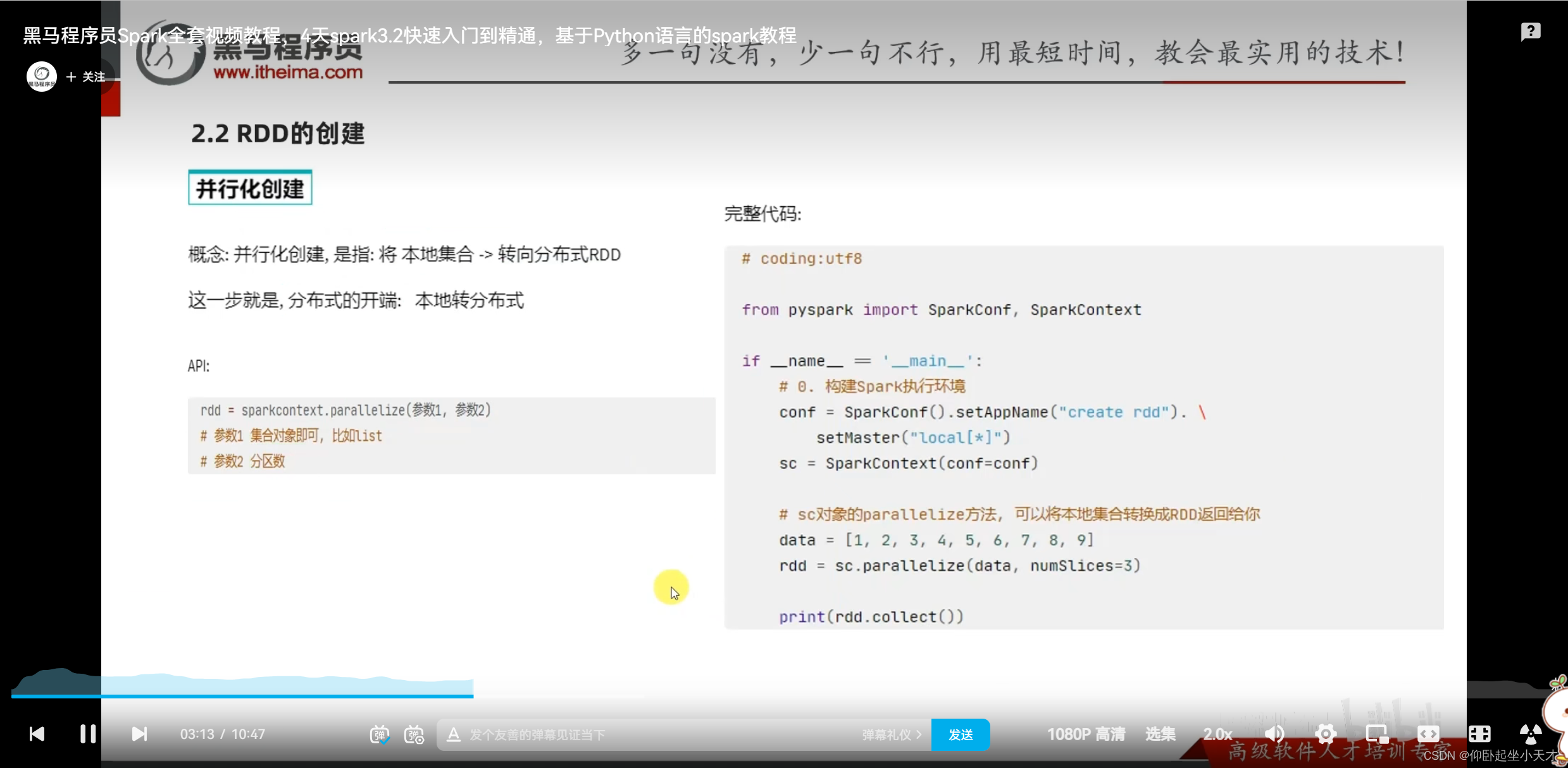
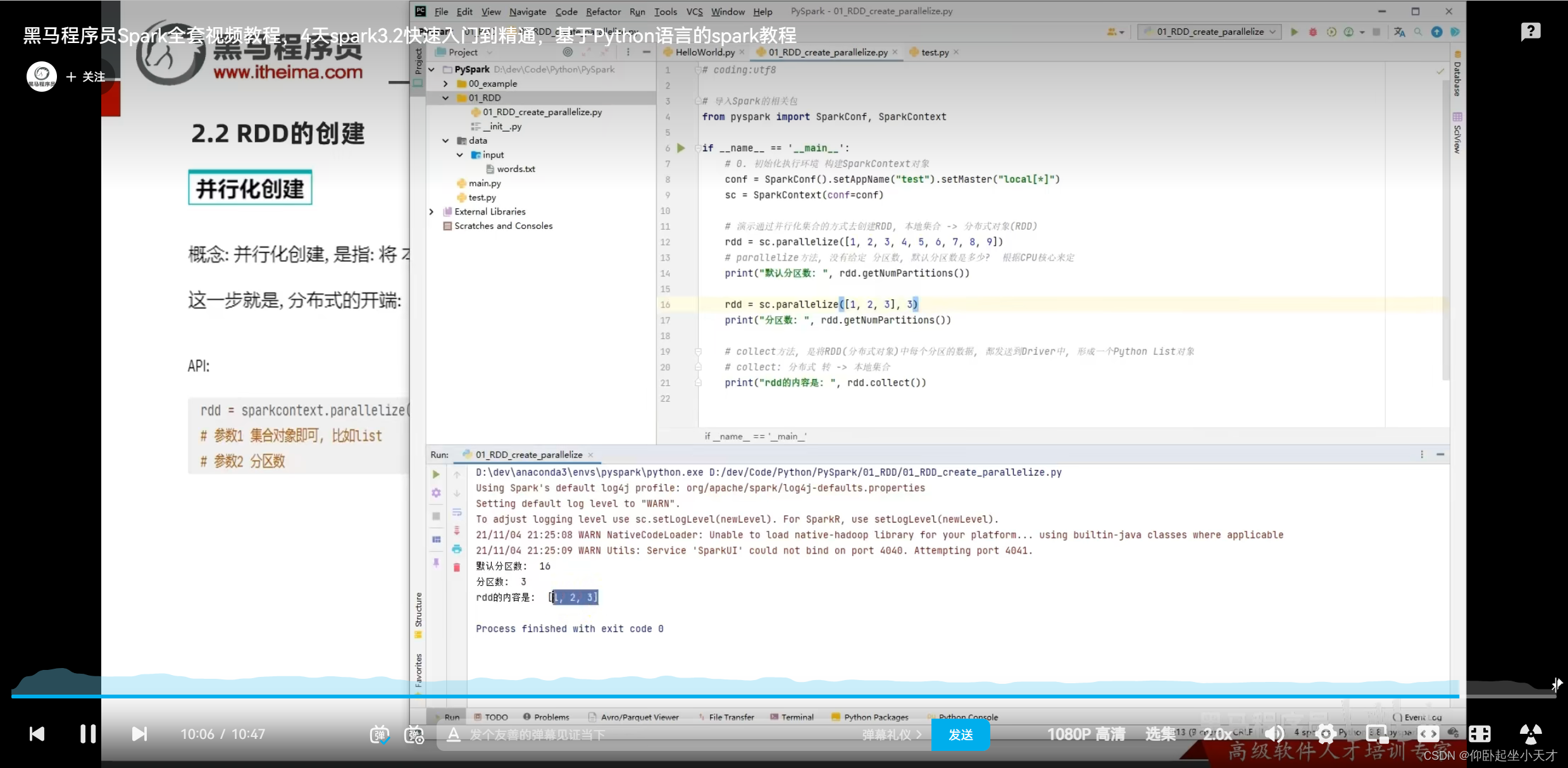
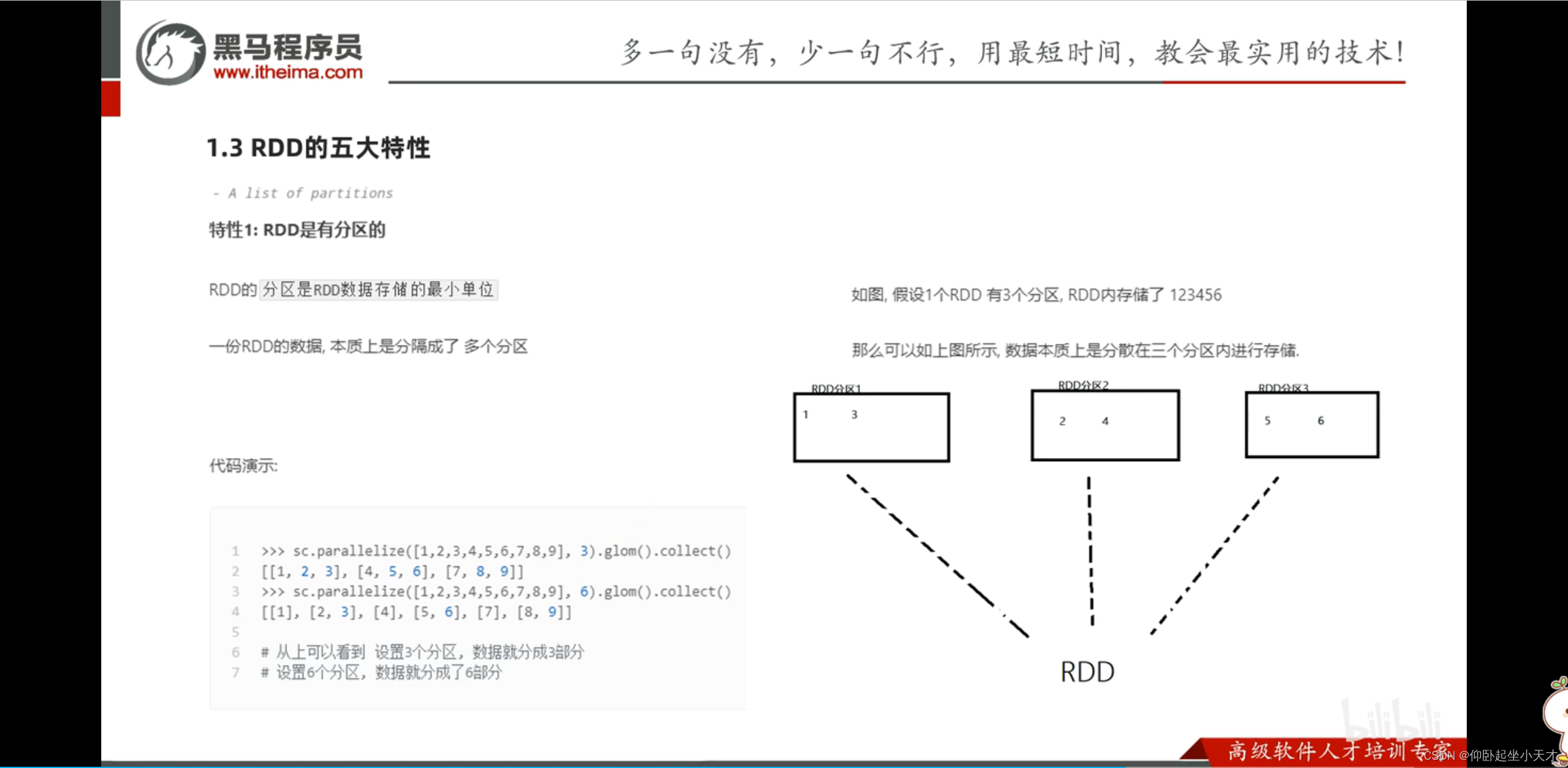
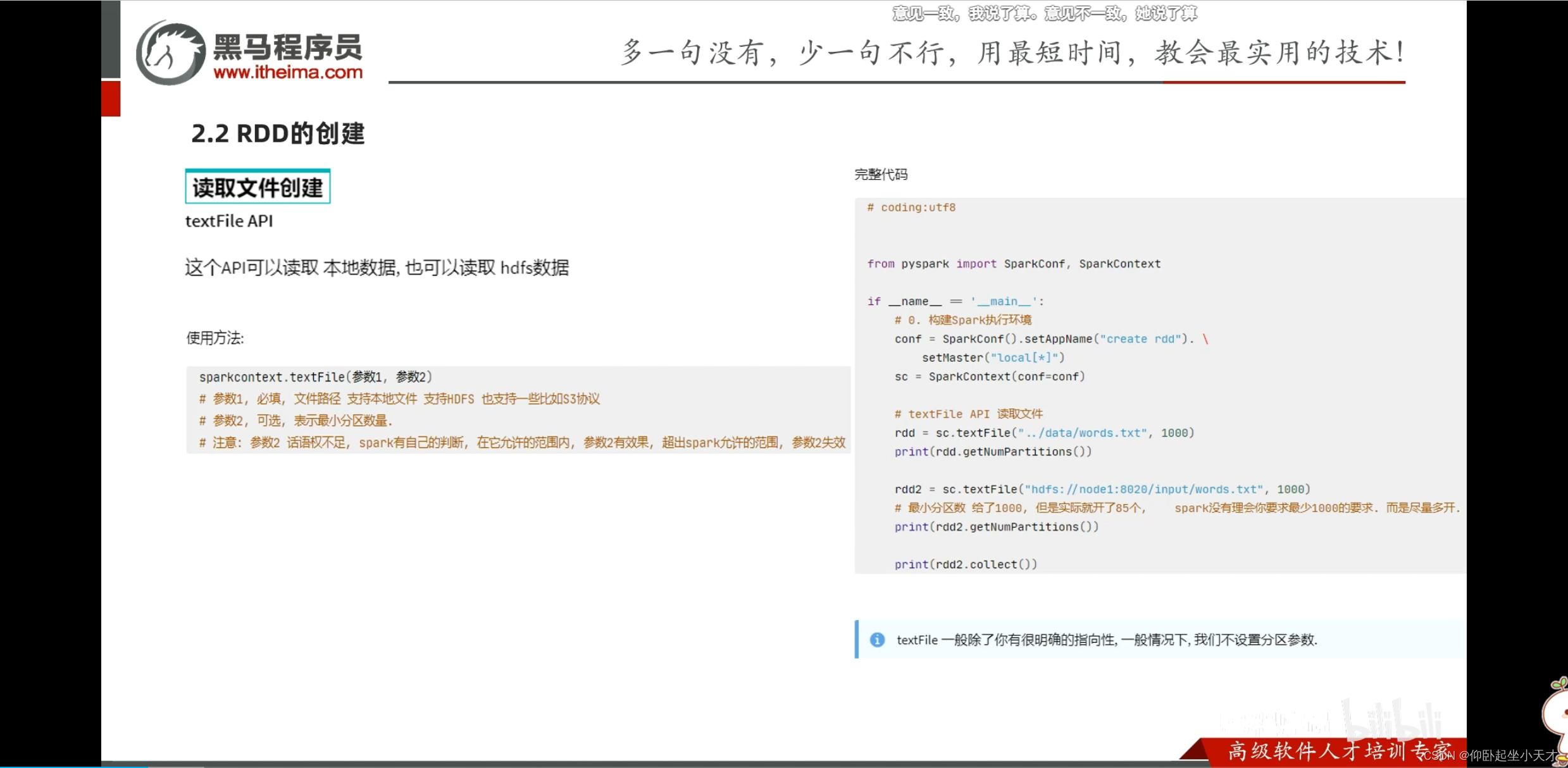
parallelize中不手动给分区数时,跟local[]指定的有关。如果用local[*],则默认分区数时CPU核心数。(比如16核的,默认分区就是16)
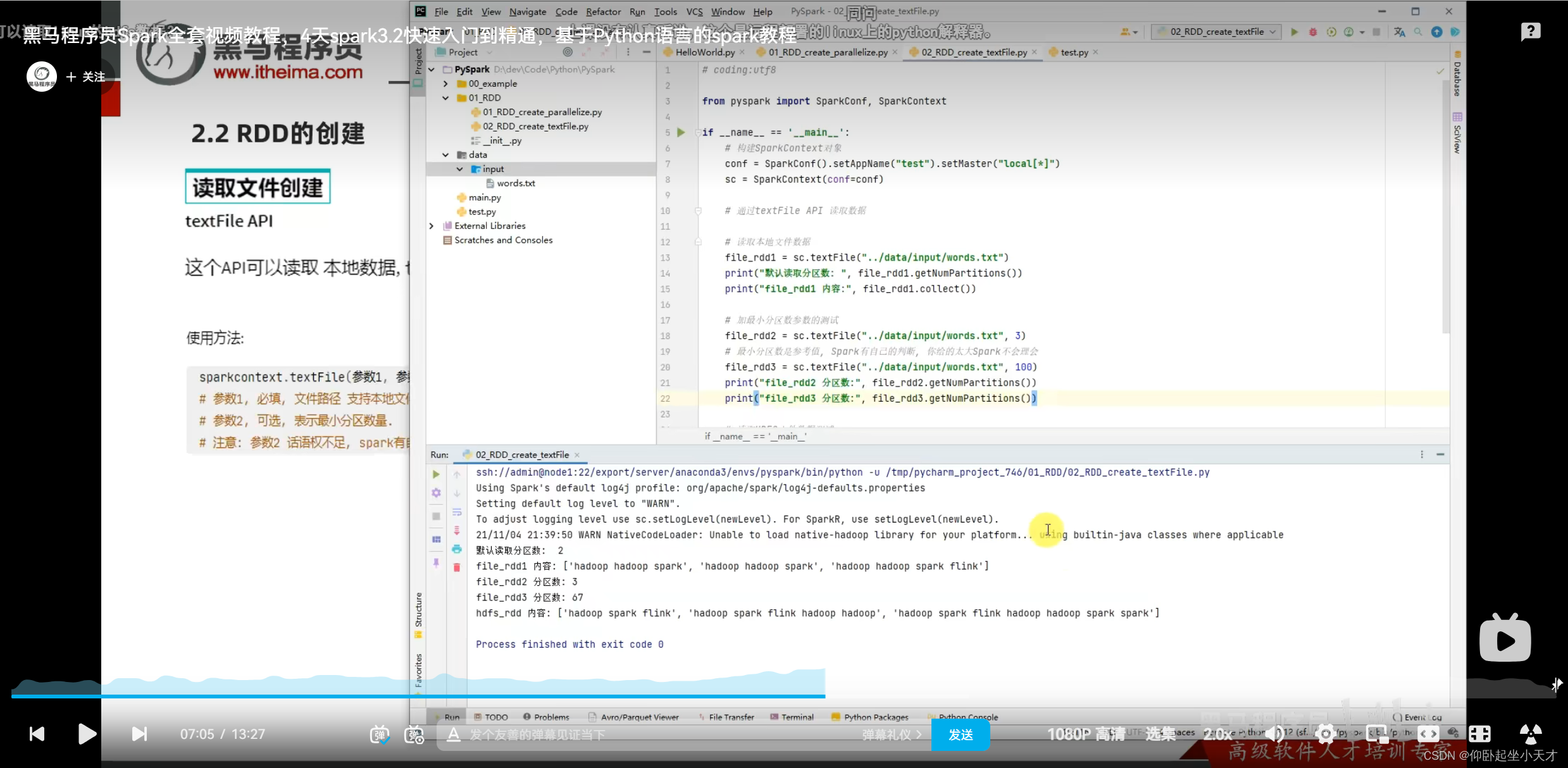

附:1. 读取文件的默认分块数跟cpu无关,而是跟文件大小有关。
2. 给定的分区数是参考值,若给的太大,spark会按自己的来。
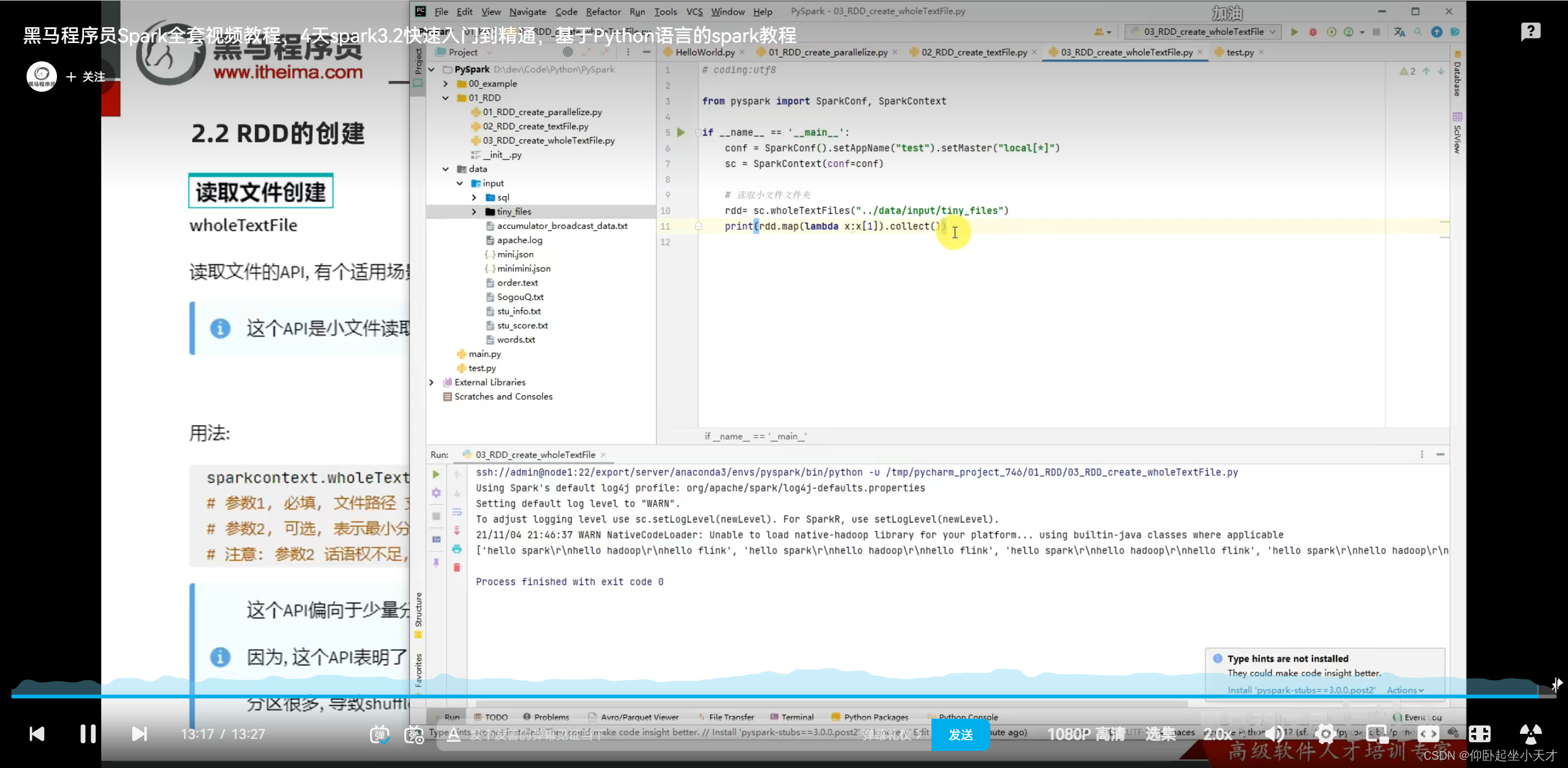
3. wholeTextFile有利于读小文件
4. API也可以读取文件夹,读出来是一个list,list掉不同的文件

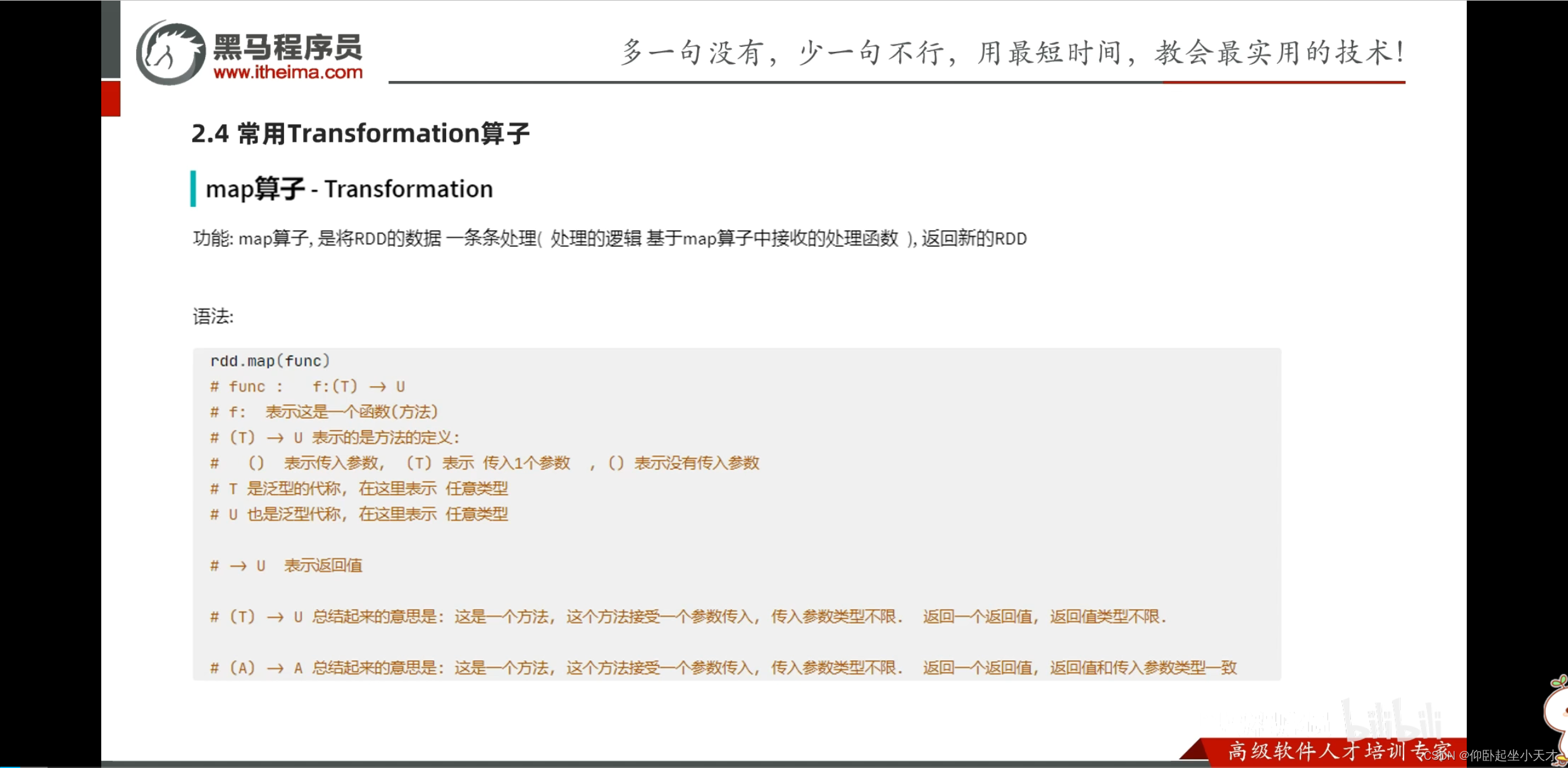
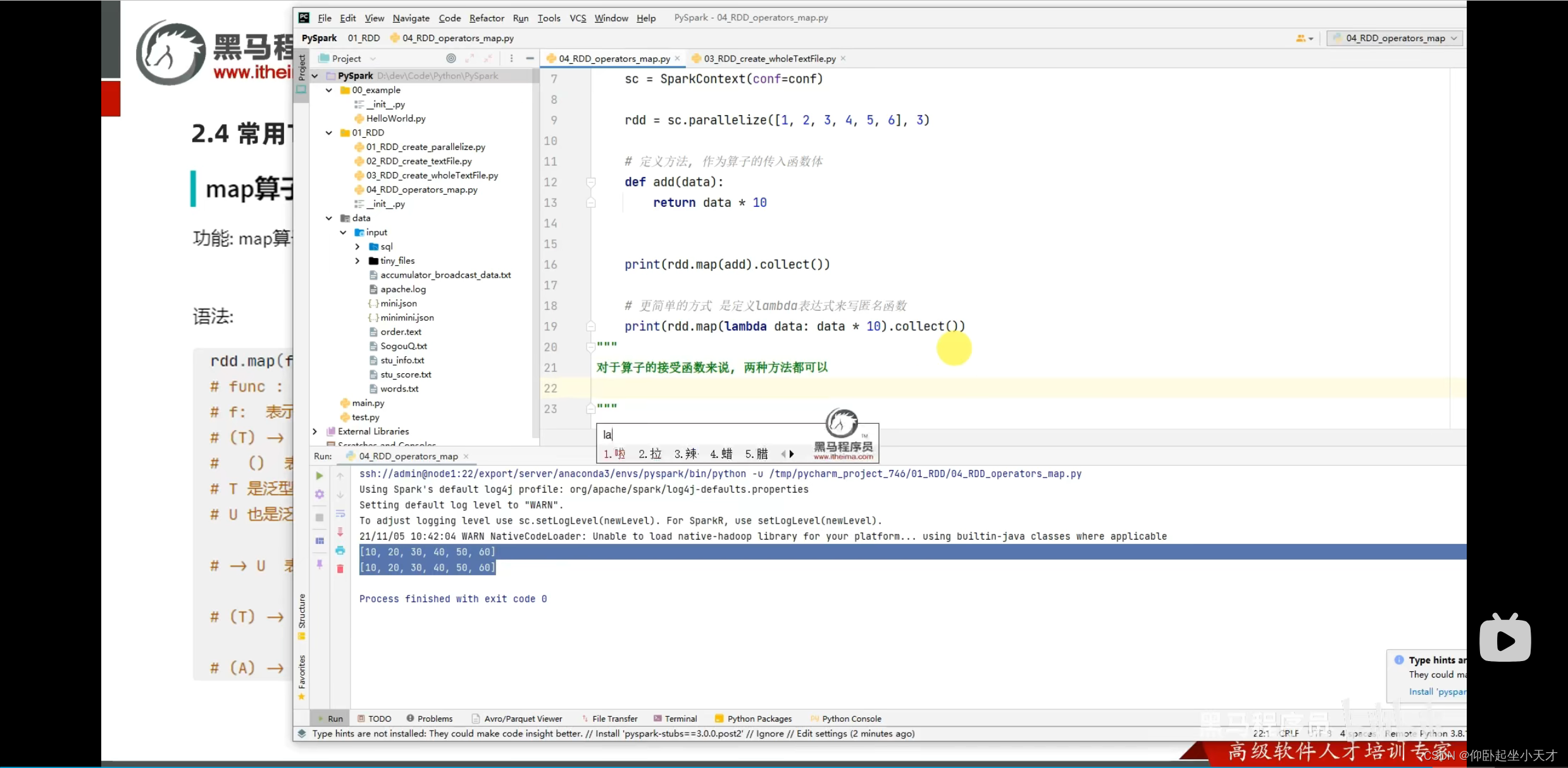

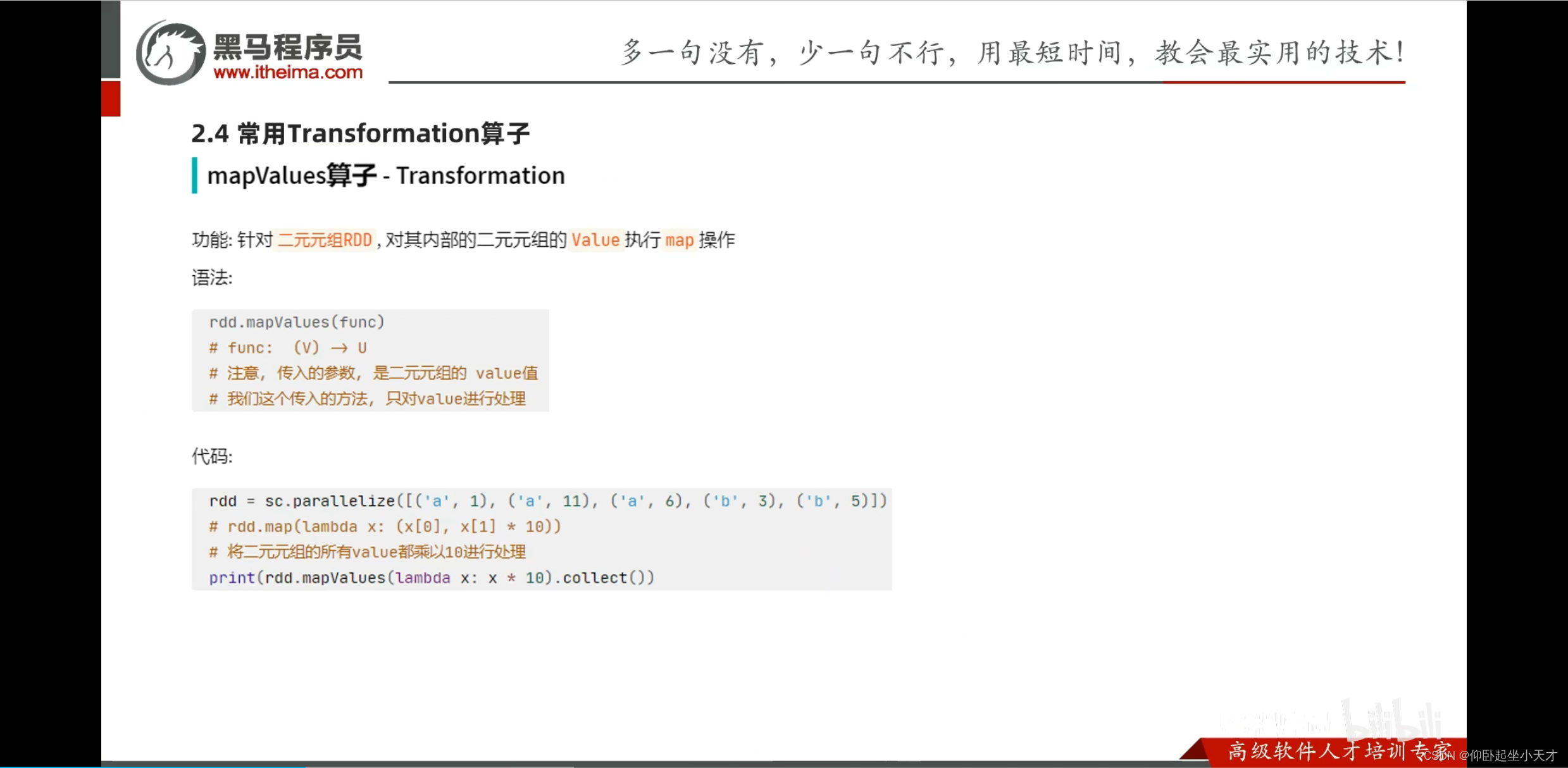
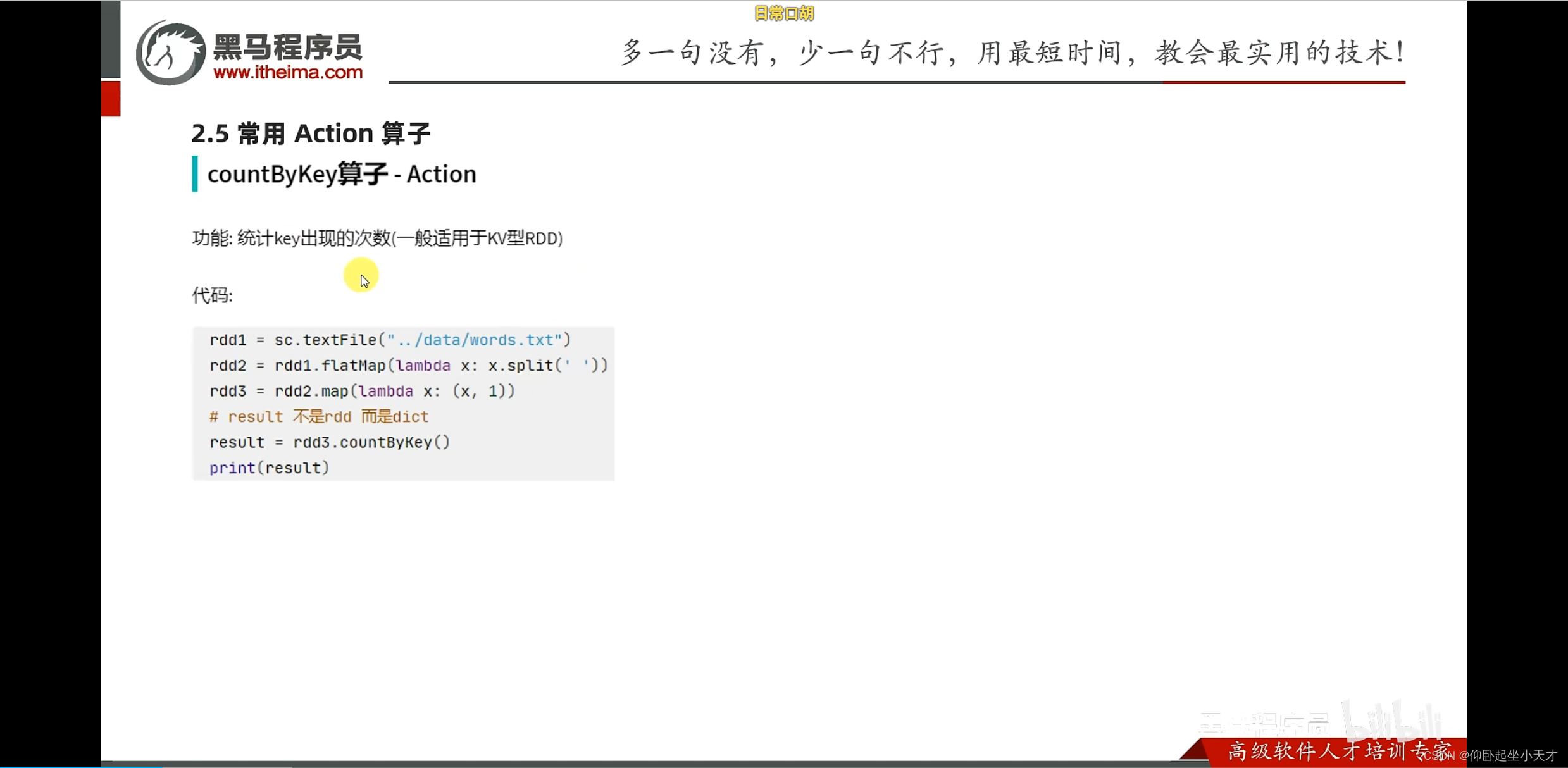
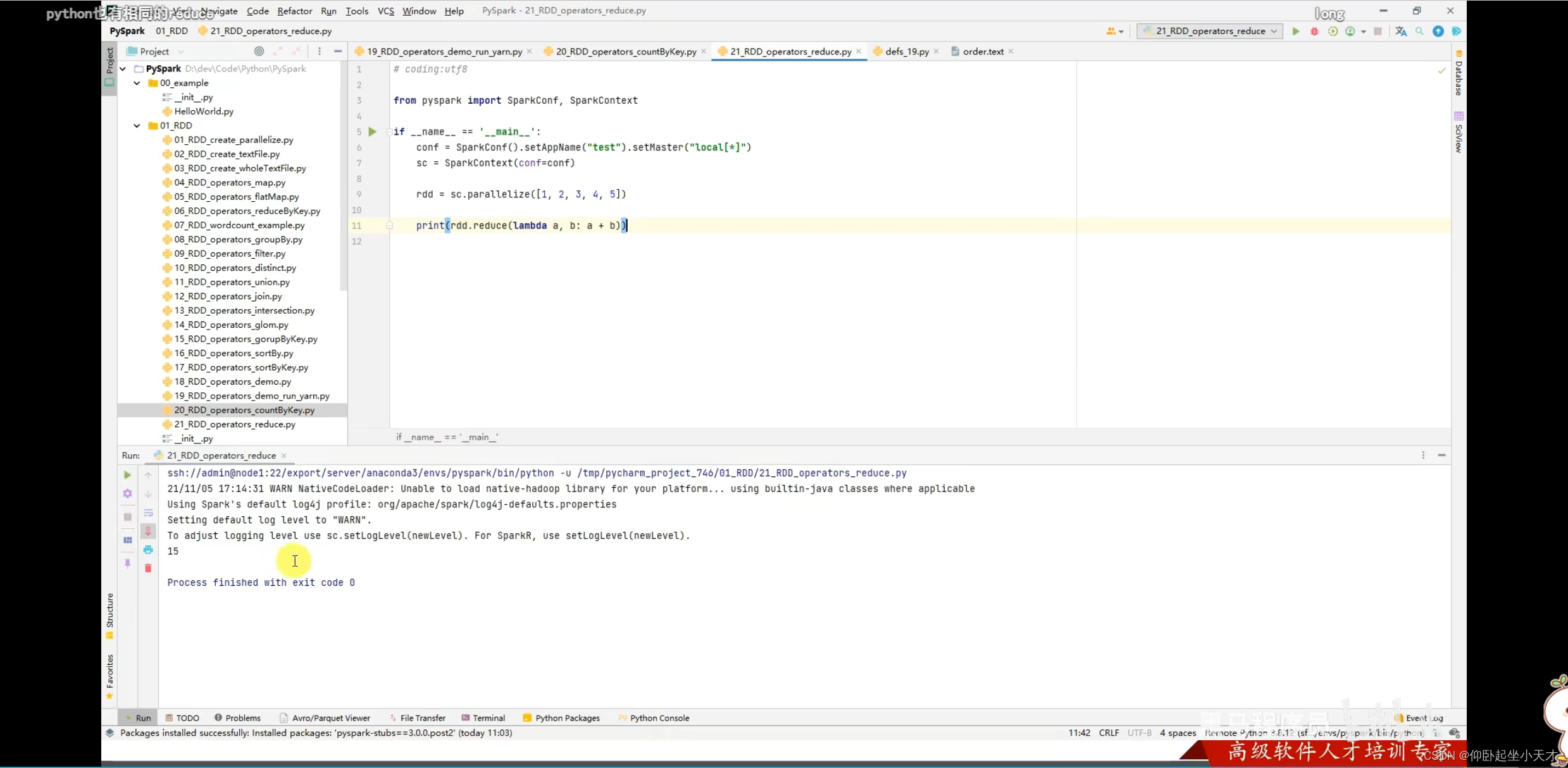
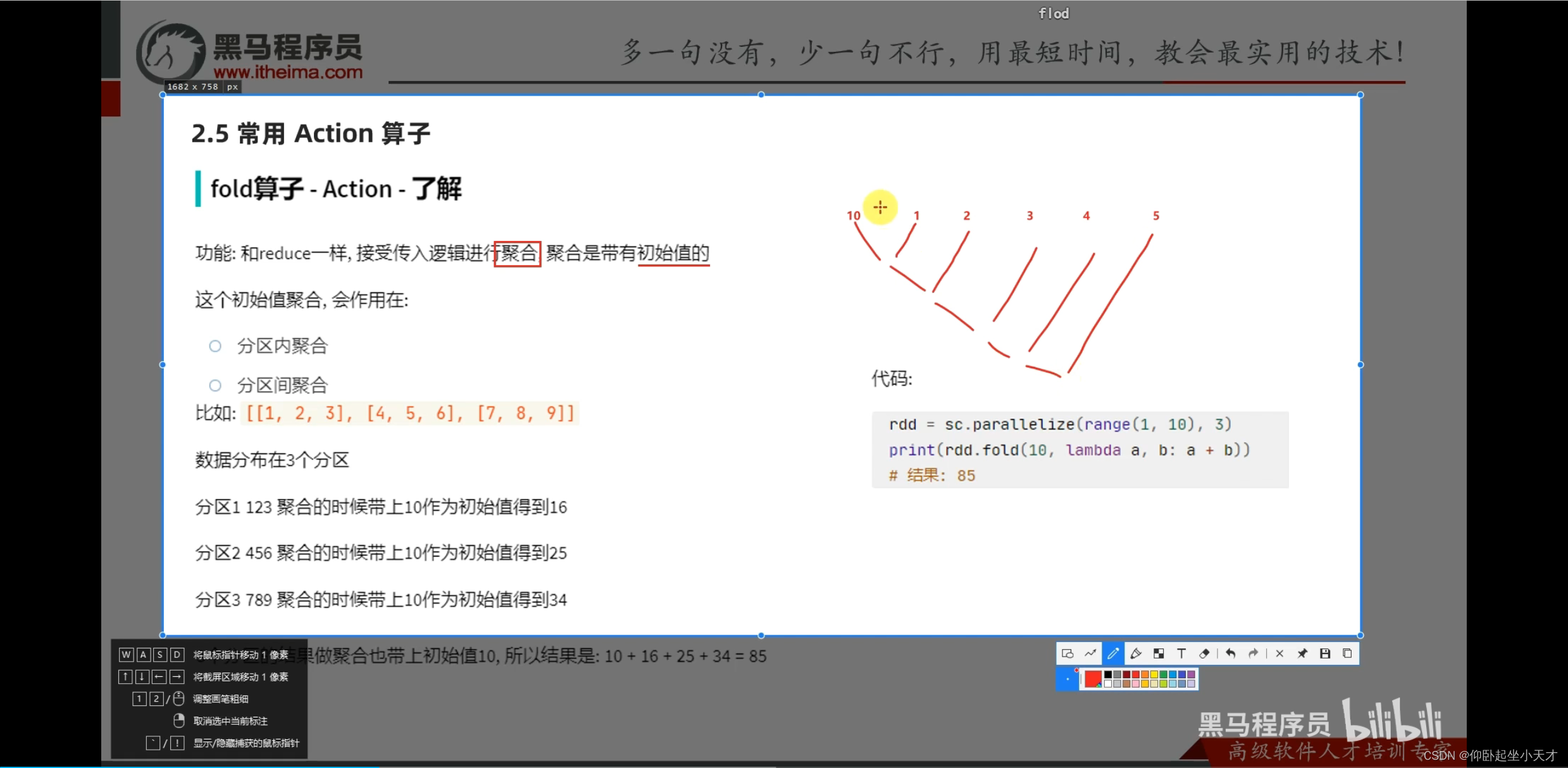
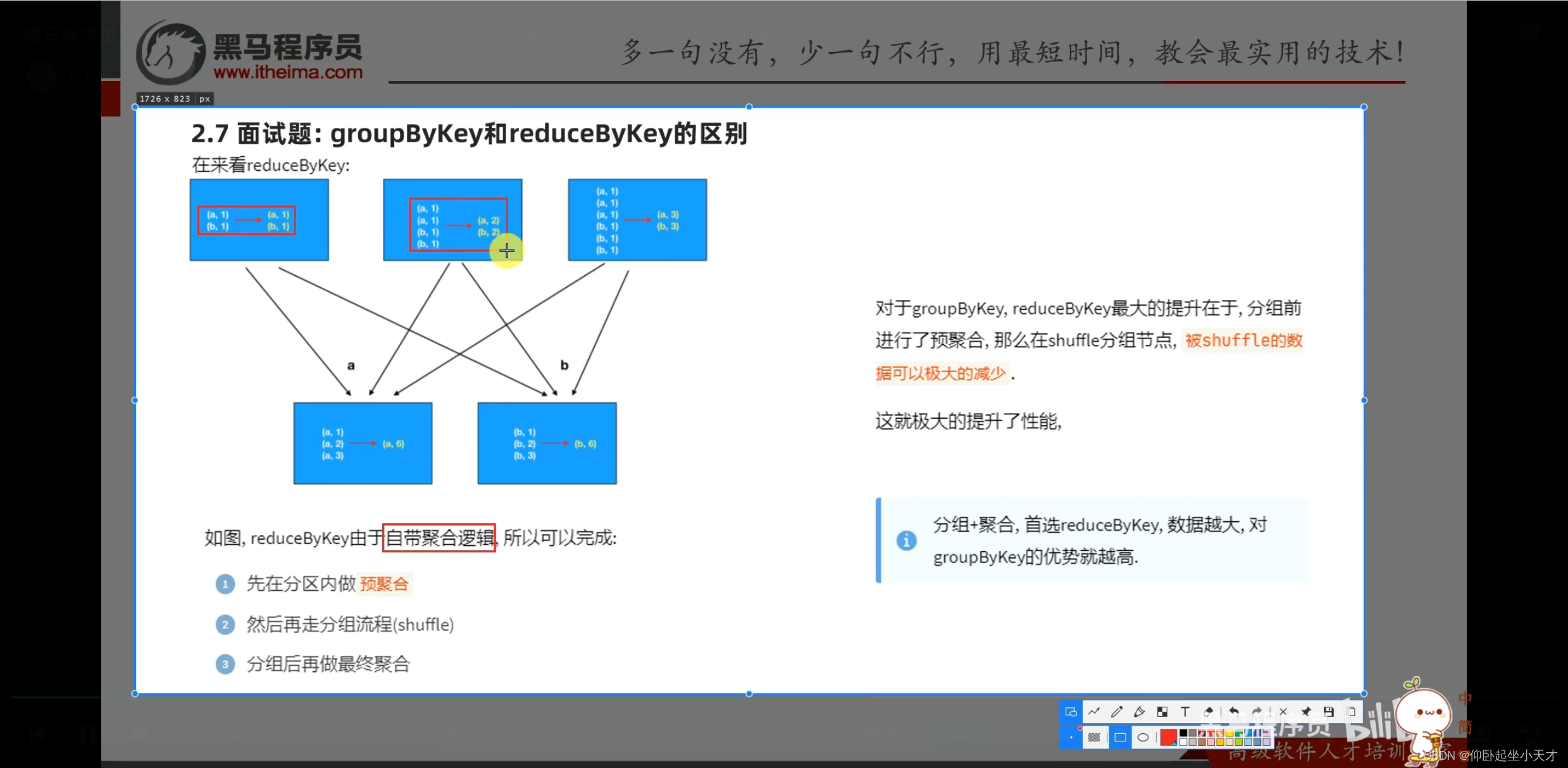
附:reduce是聚合的意思


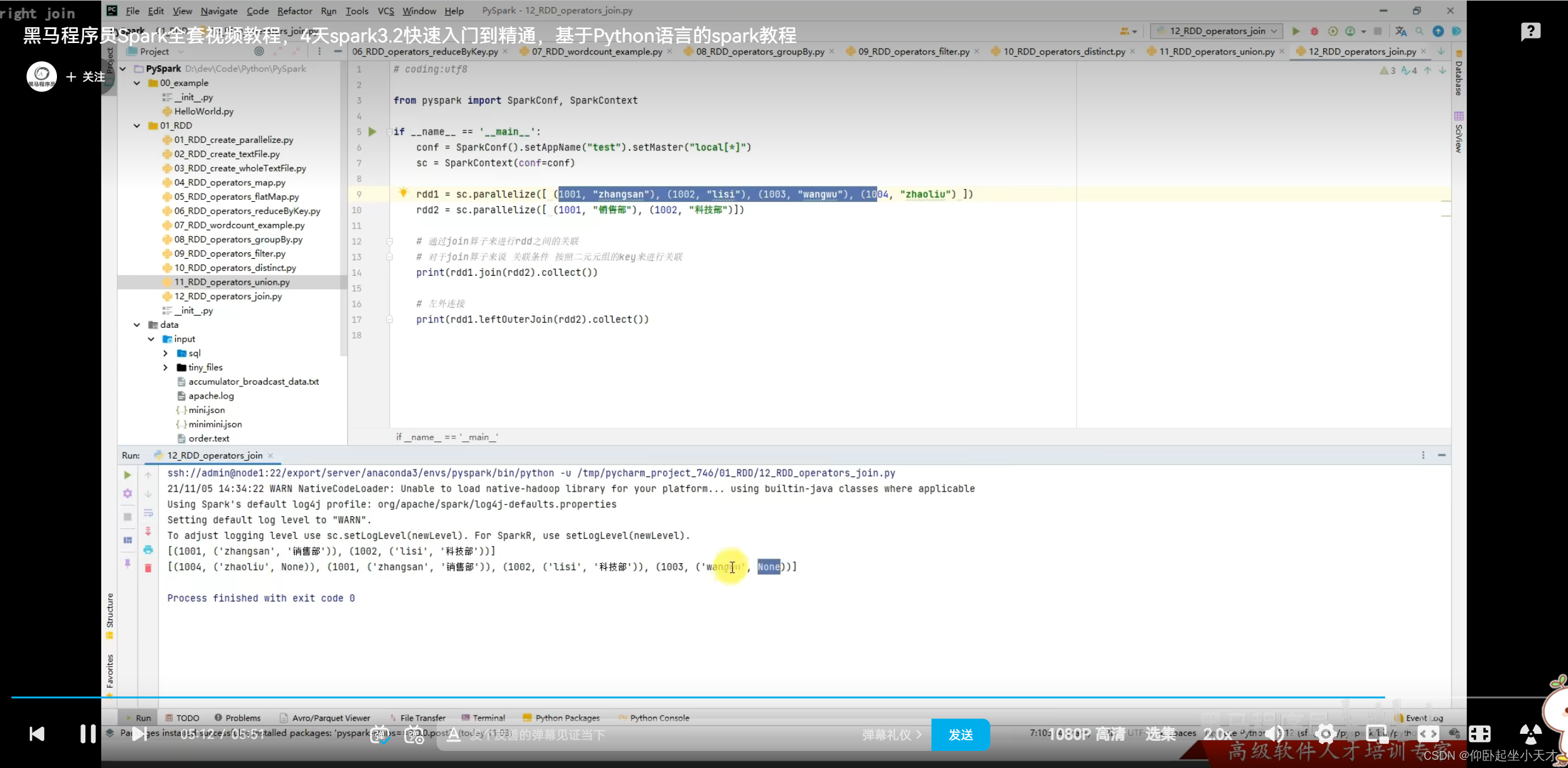
附:join关联只关于key关联
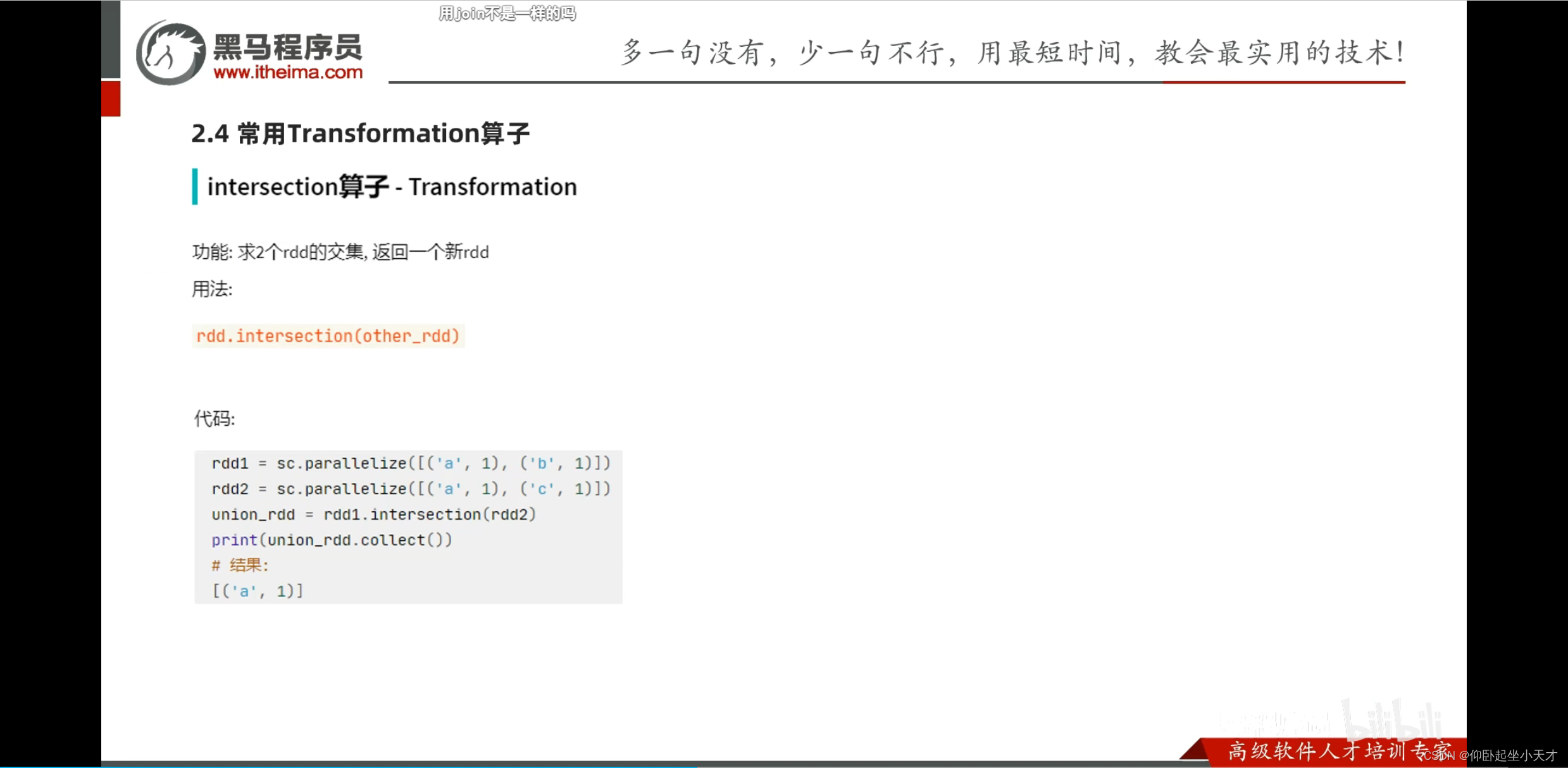
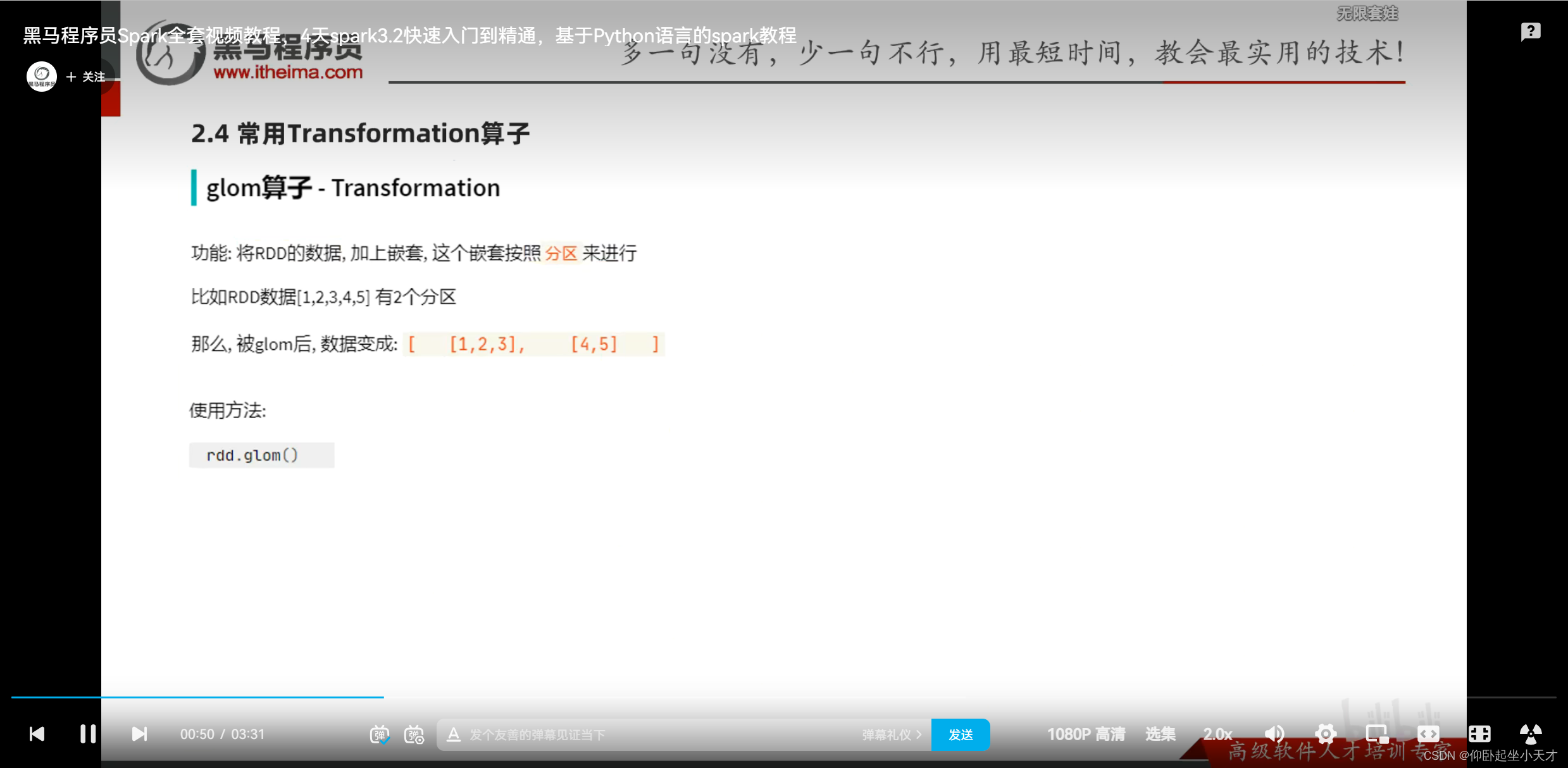
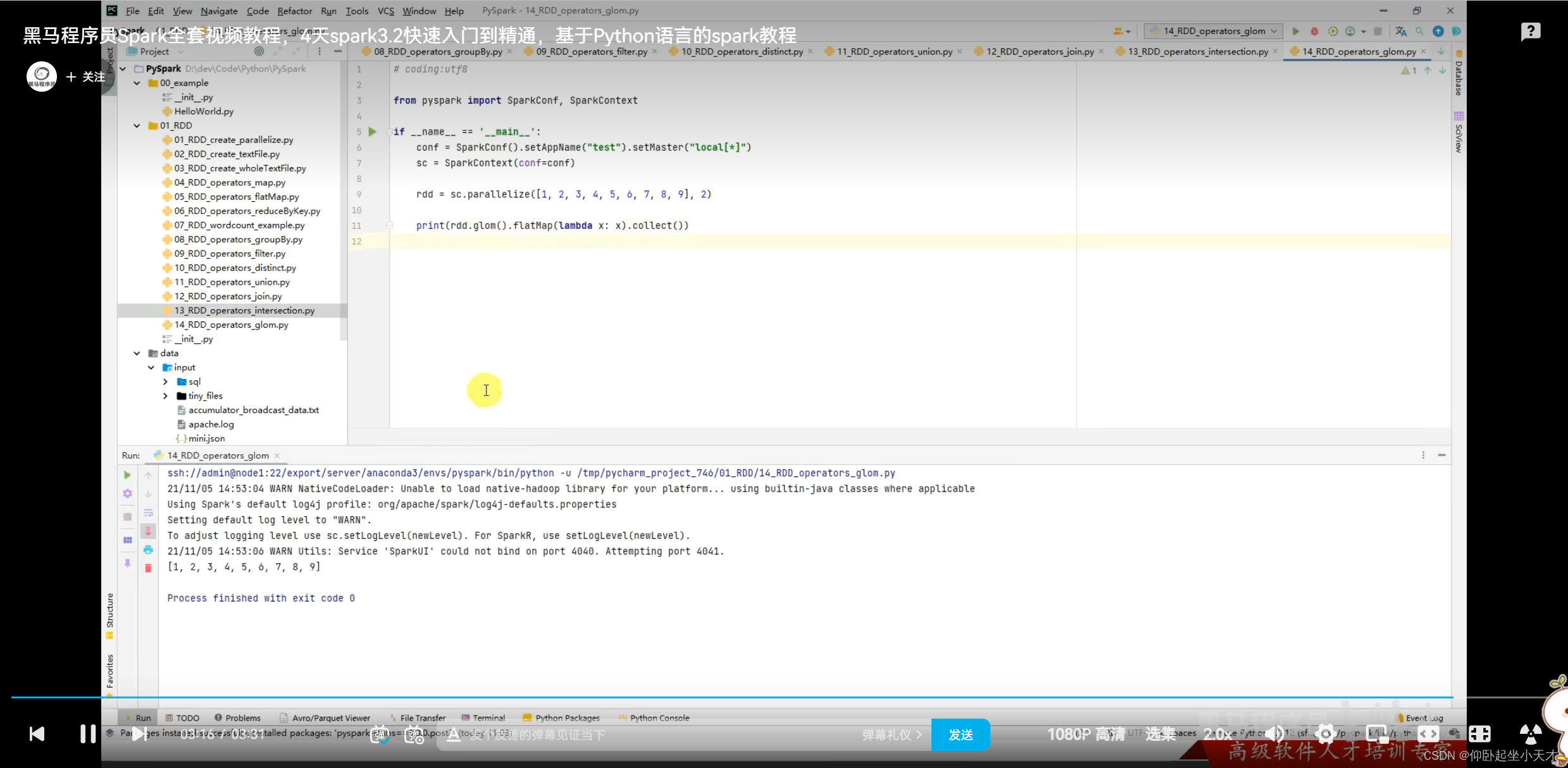
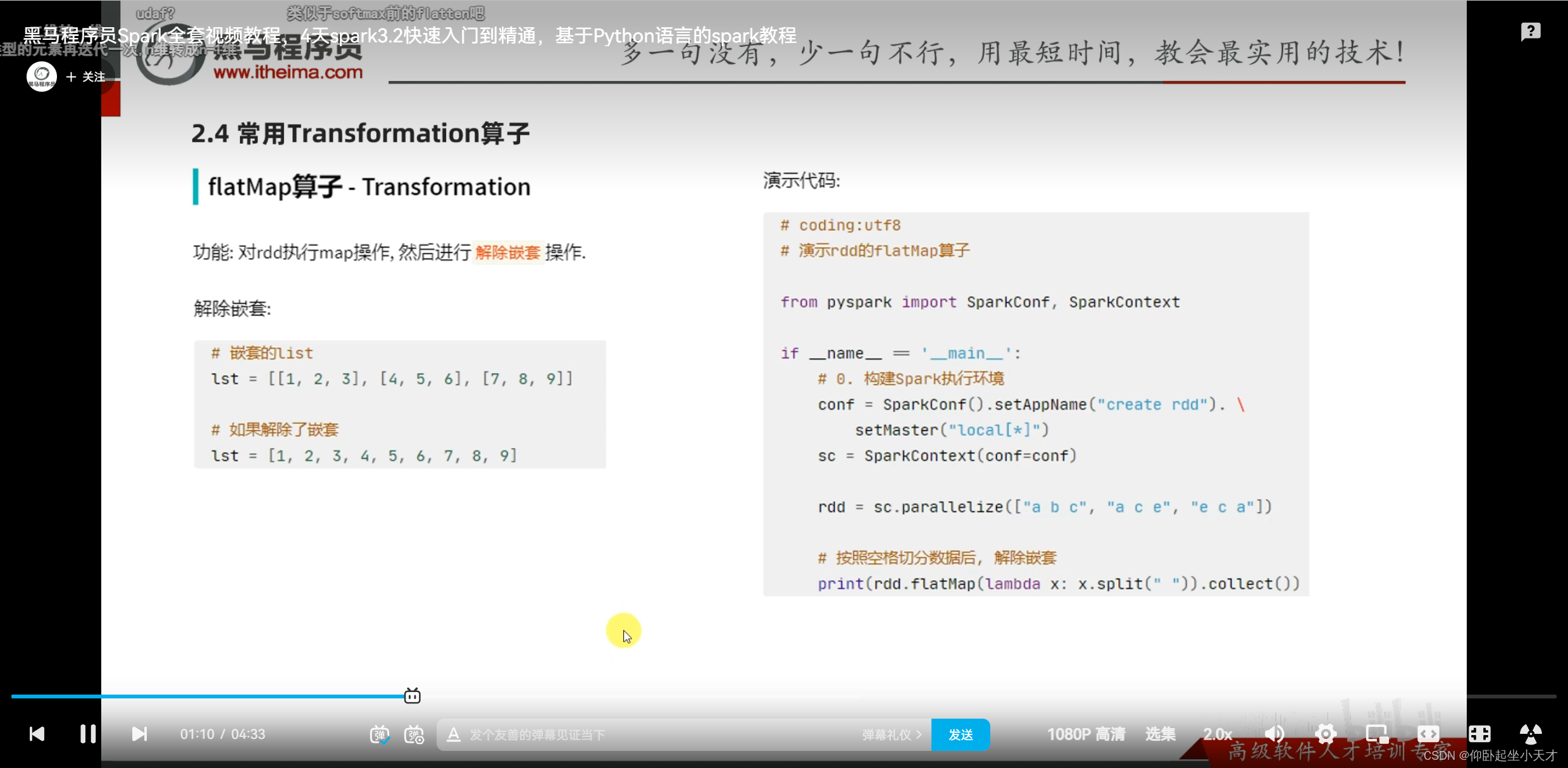
附:解嵌套,可以直接flapMap(lambda x: x) 来做
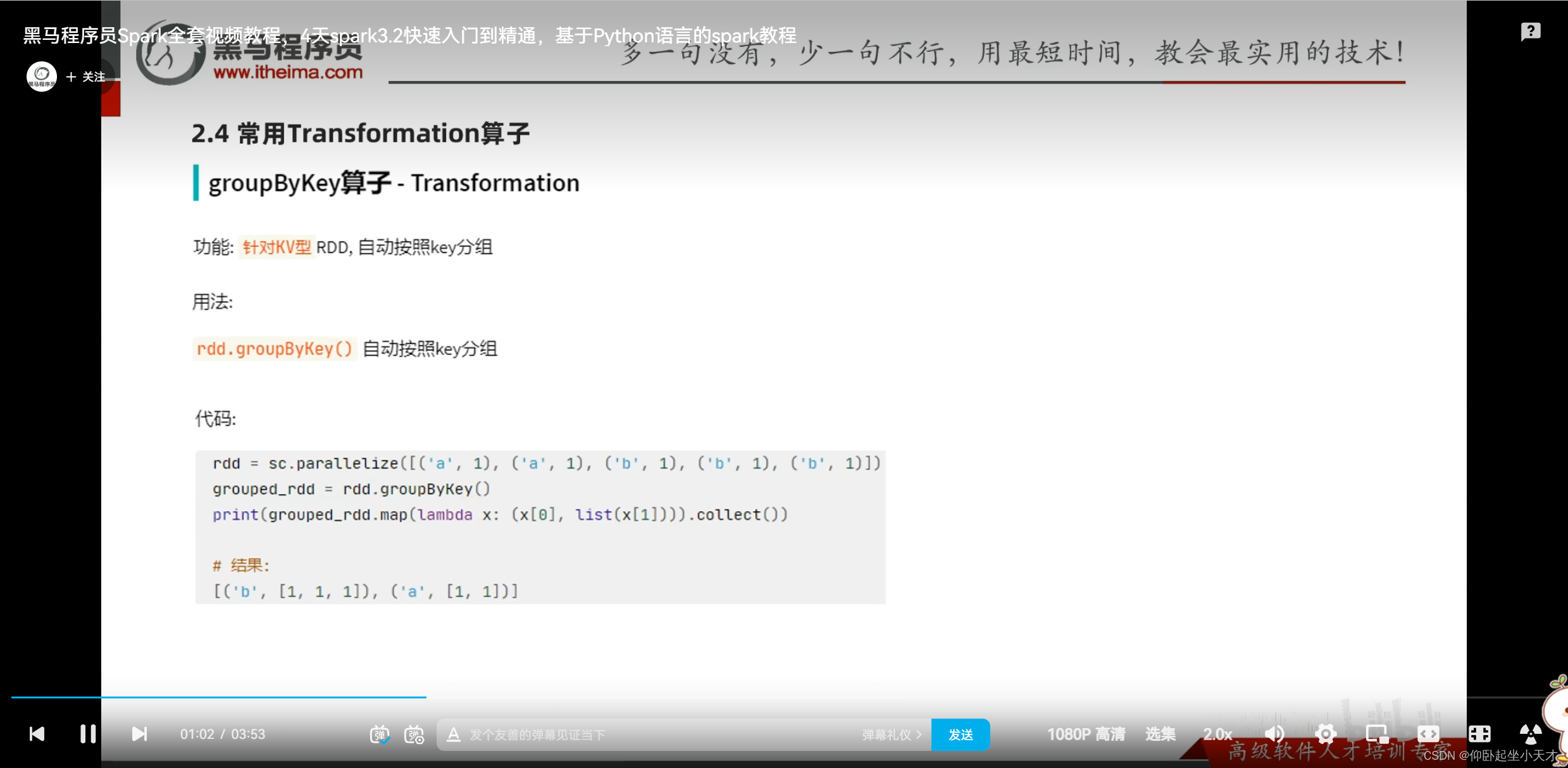
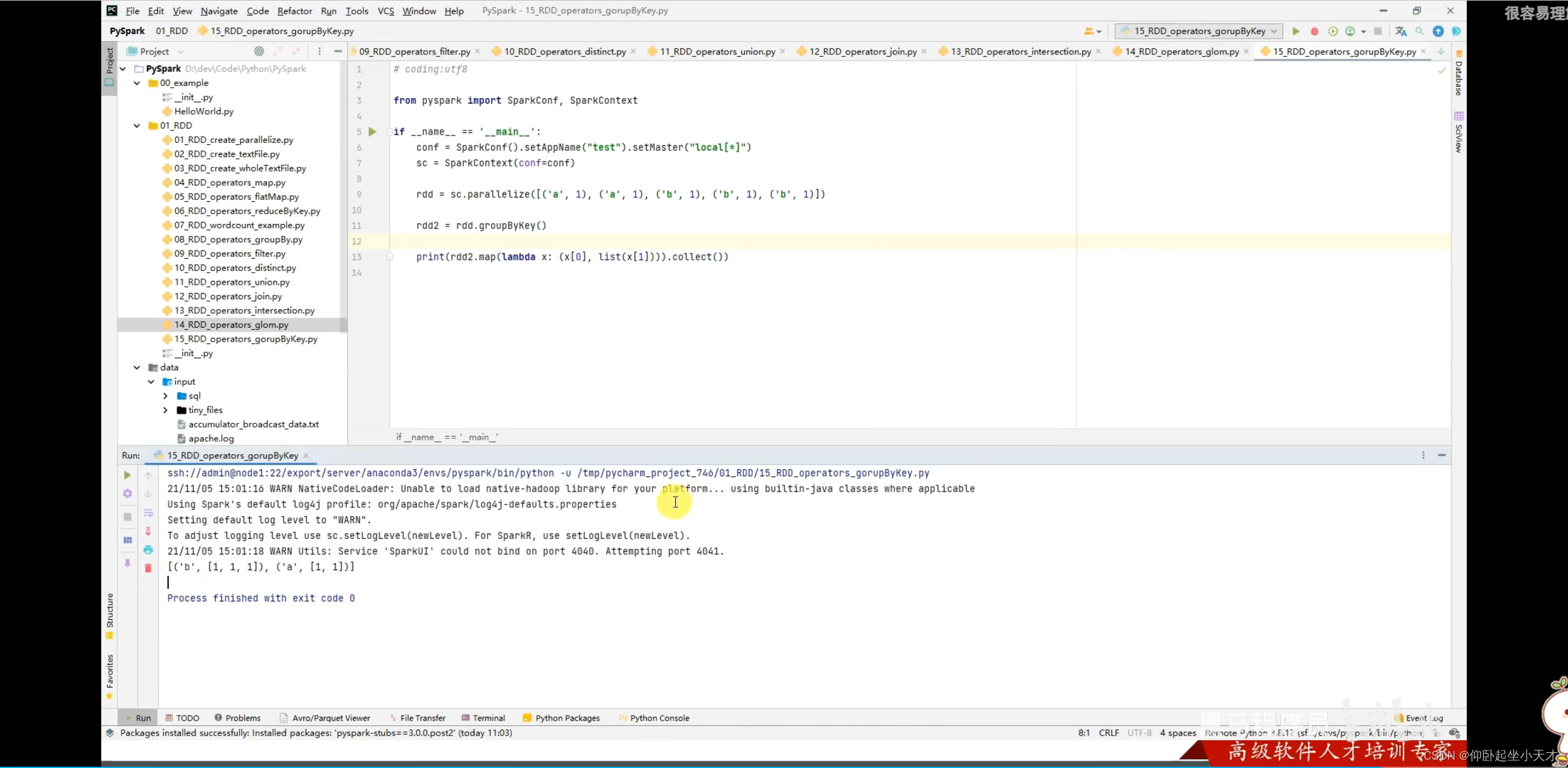
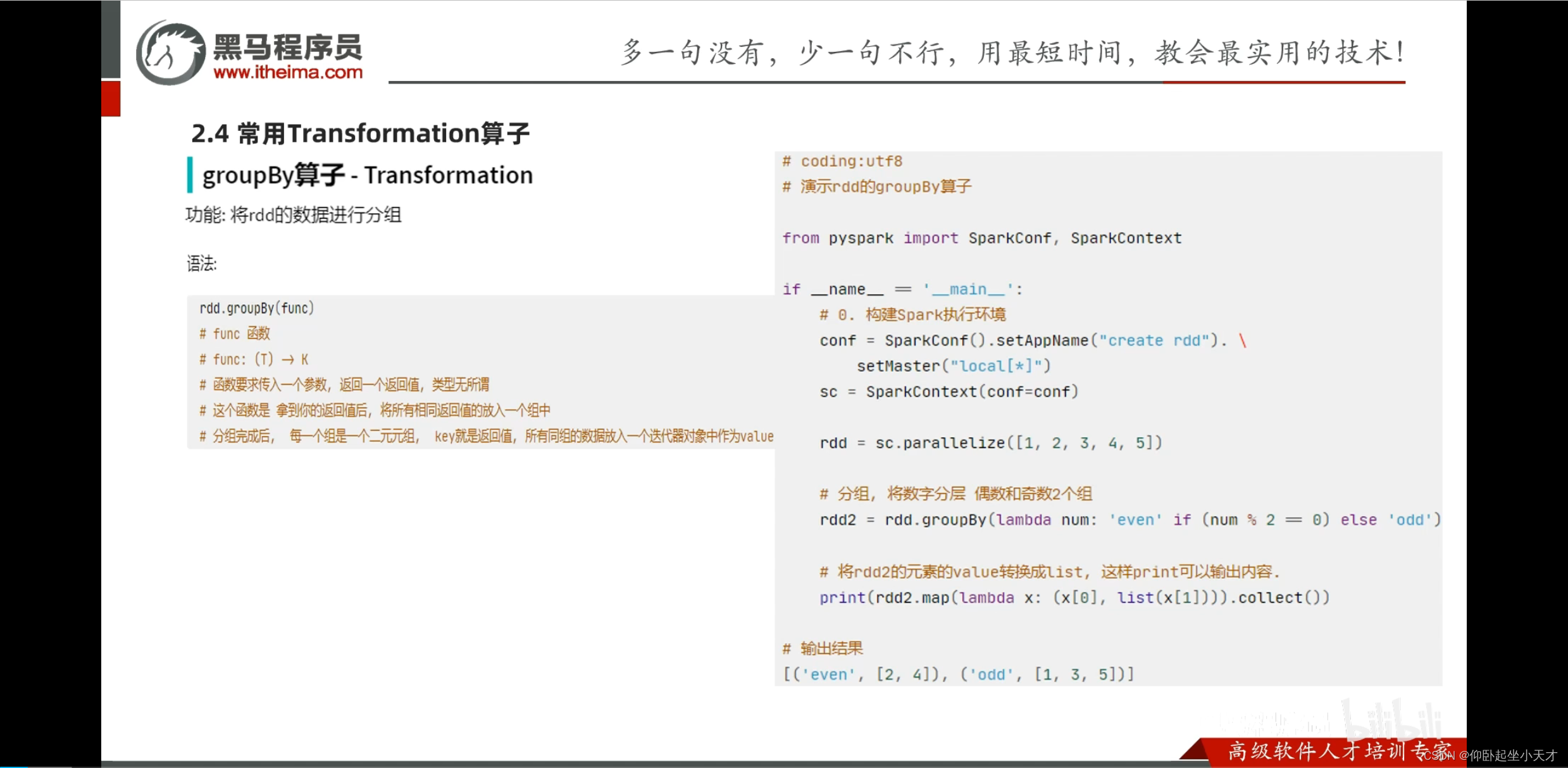
附:groupByKey只保留了key,并直接返回成一个list,groupBy是把整个都保留了 ??
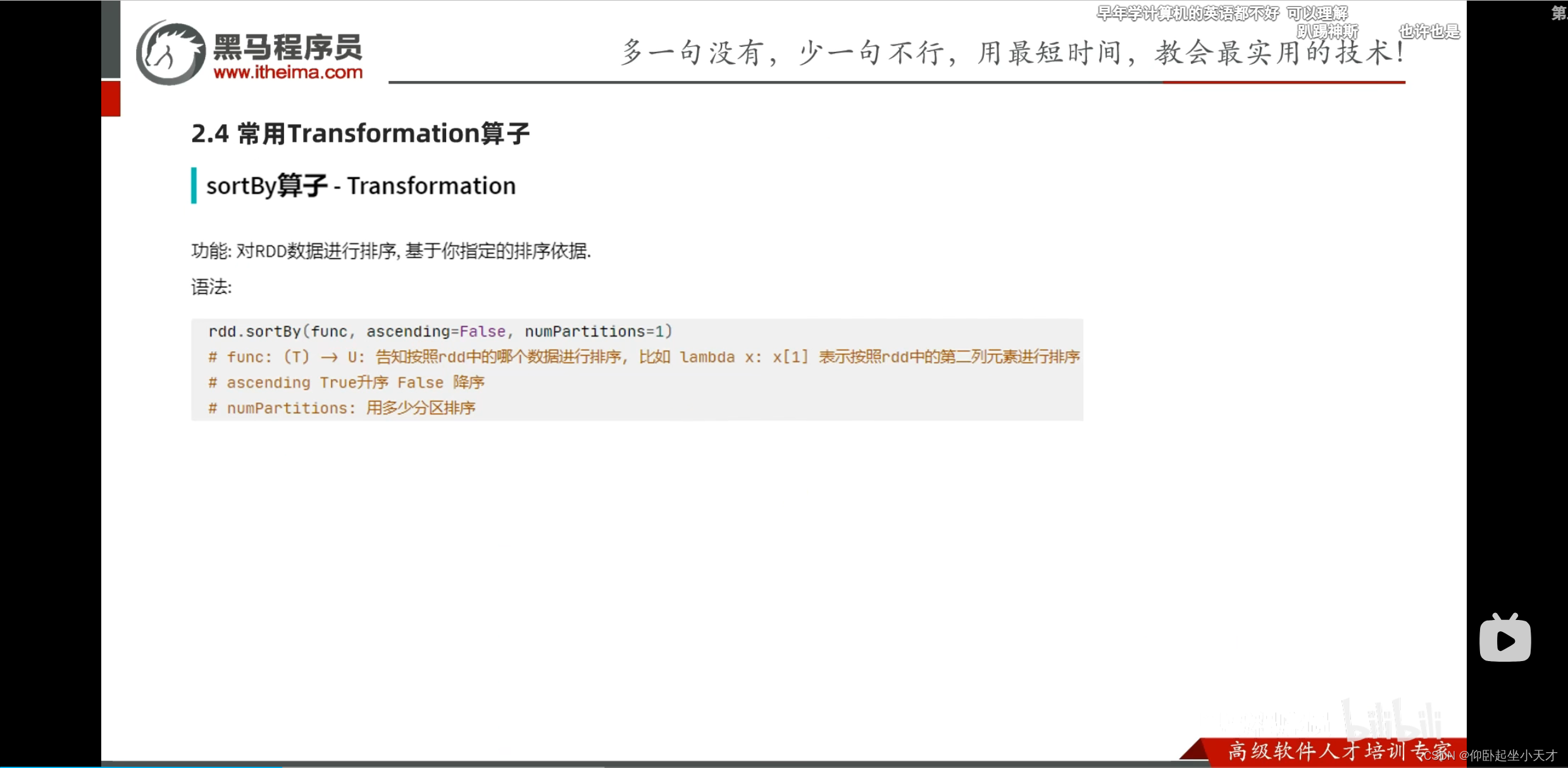
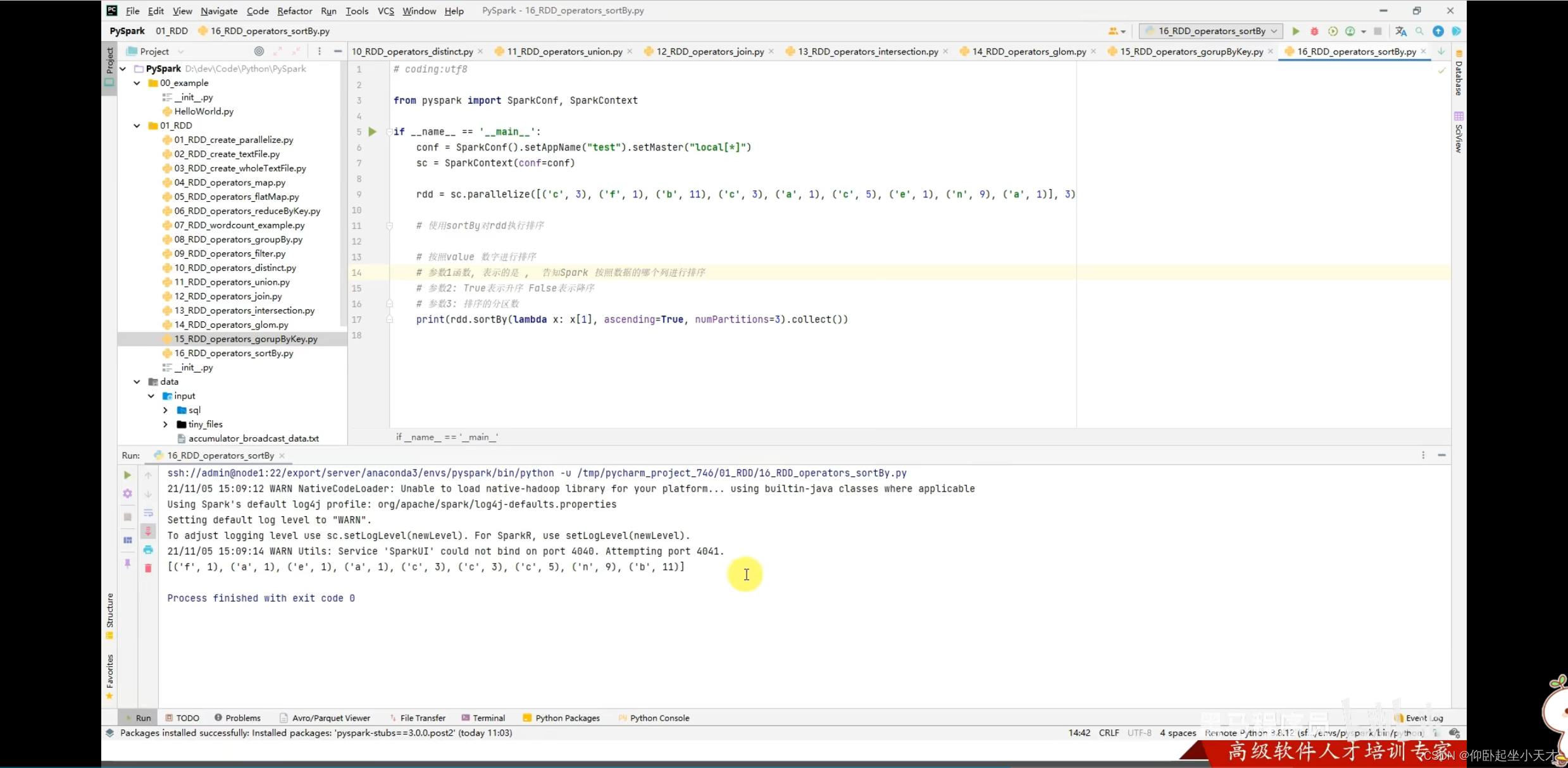
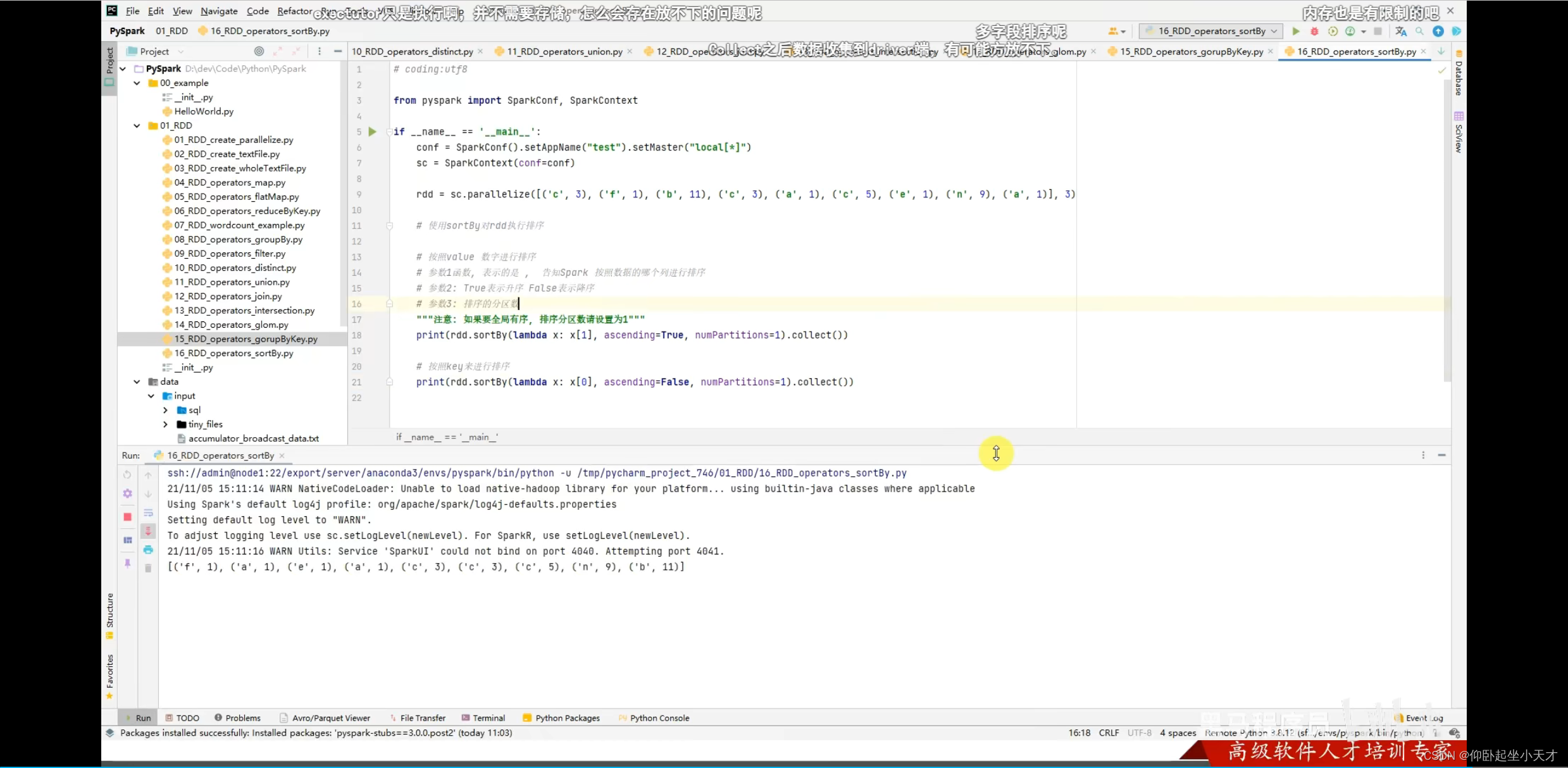
附:排序分区数要设置为1。在工程中是有很多executor的,若设置成别的,可能只能达成局部排序,但是总体不是严格排序的。
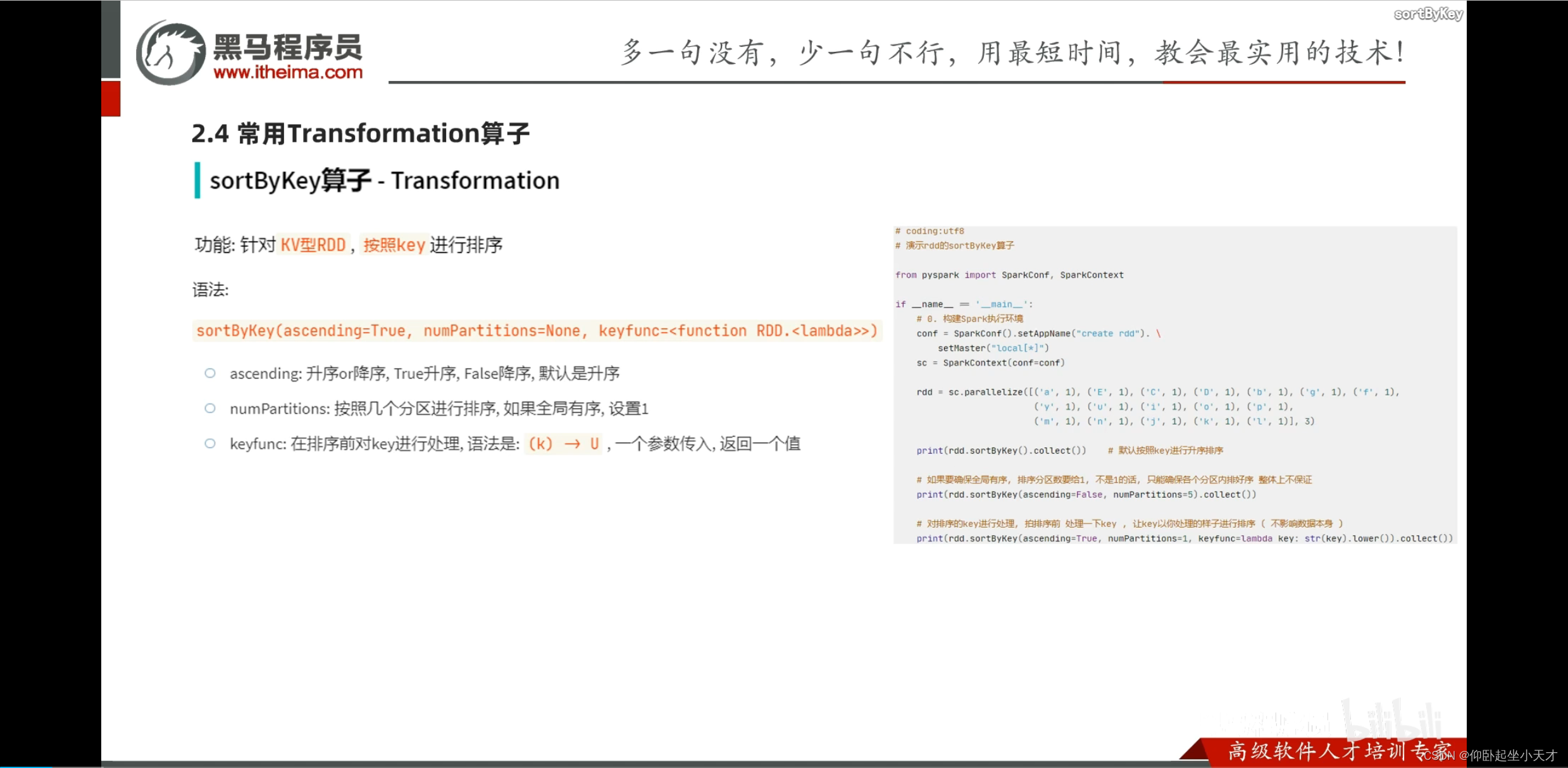
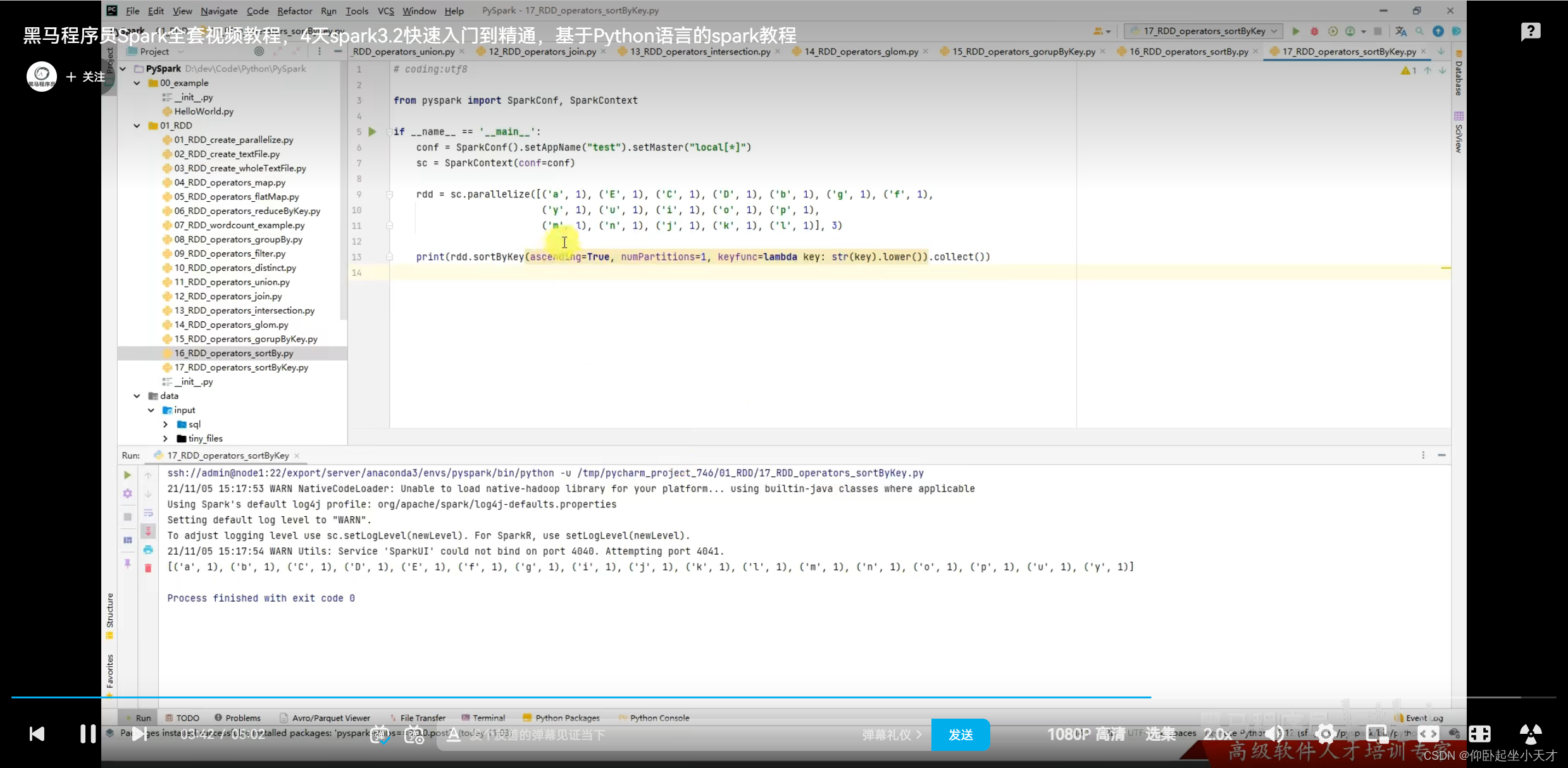
附:第三个参数在排序的时候对key进行处理。比如要排序的是字符串的时候,如果不想有大小写的影响,则可以用第三个参数处理。
处理时只在排序的时候改变,但是不改变原本的值,即输出的还是原值。
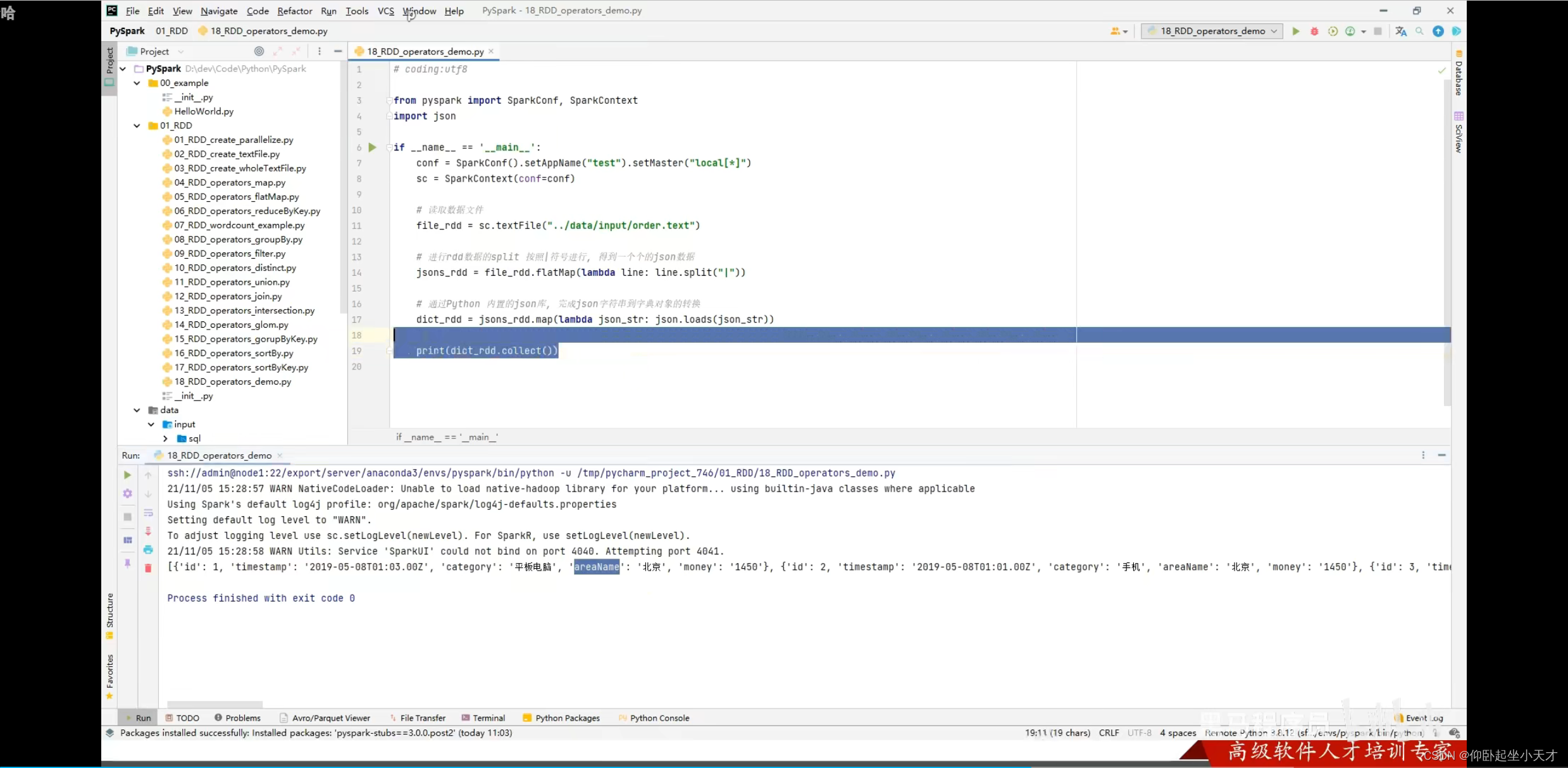
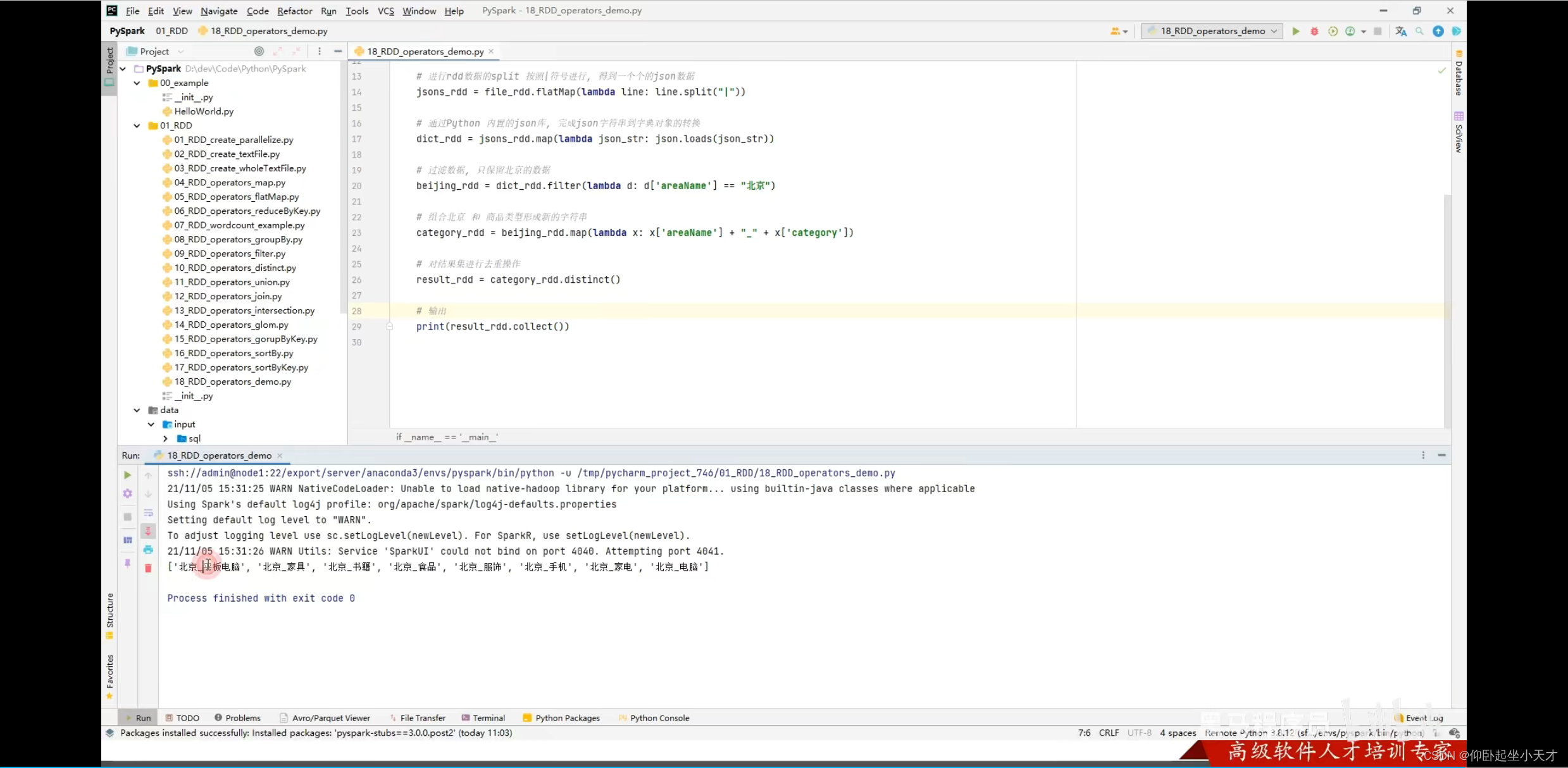
这里我跳过了 ![]()
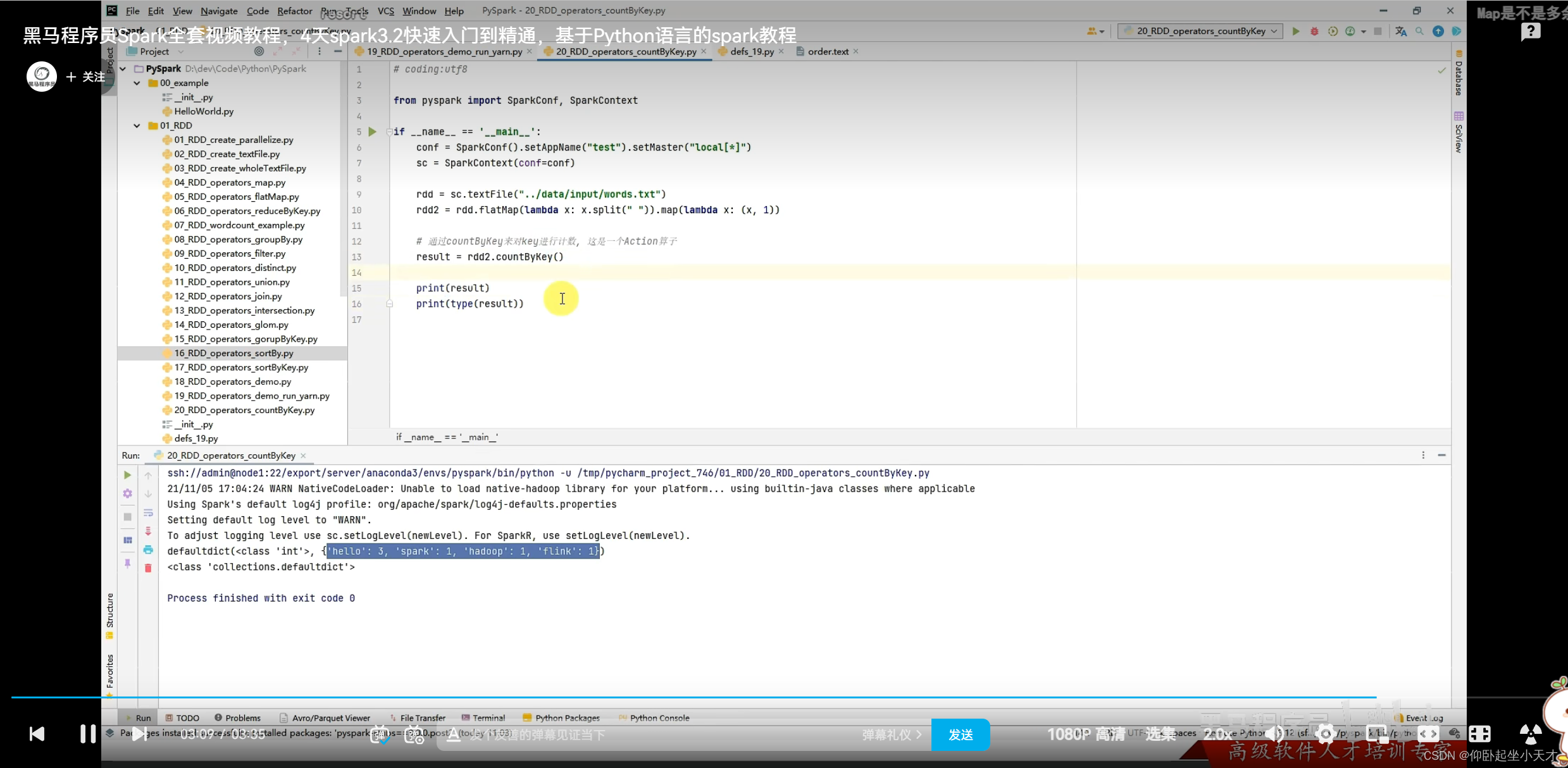
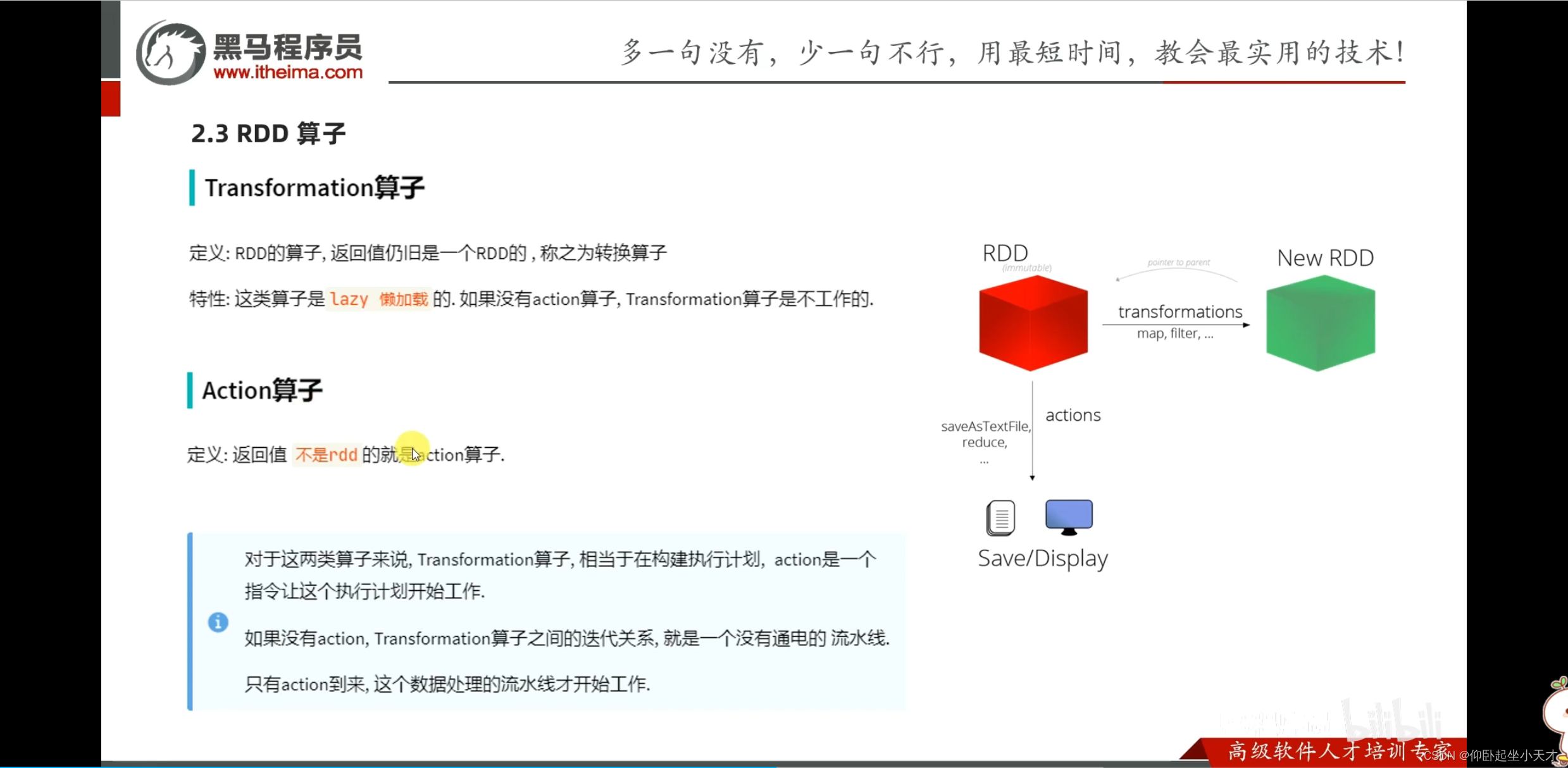
附:Action出来的就不是rdd了
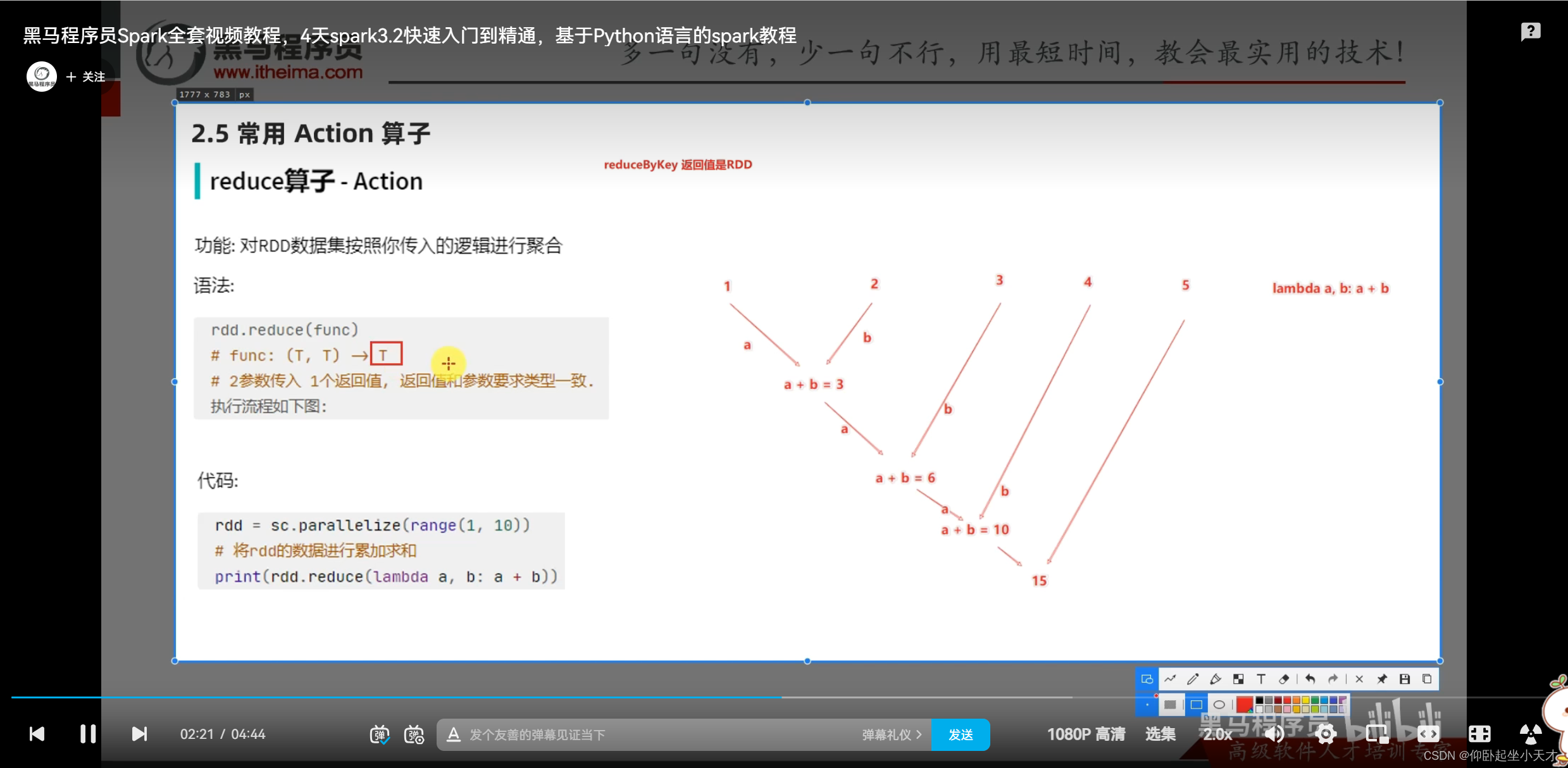
附:reduceByKey是转换算子,出来是rdd
reduce是action算子

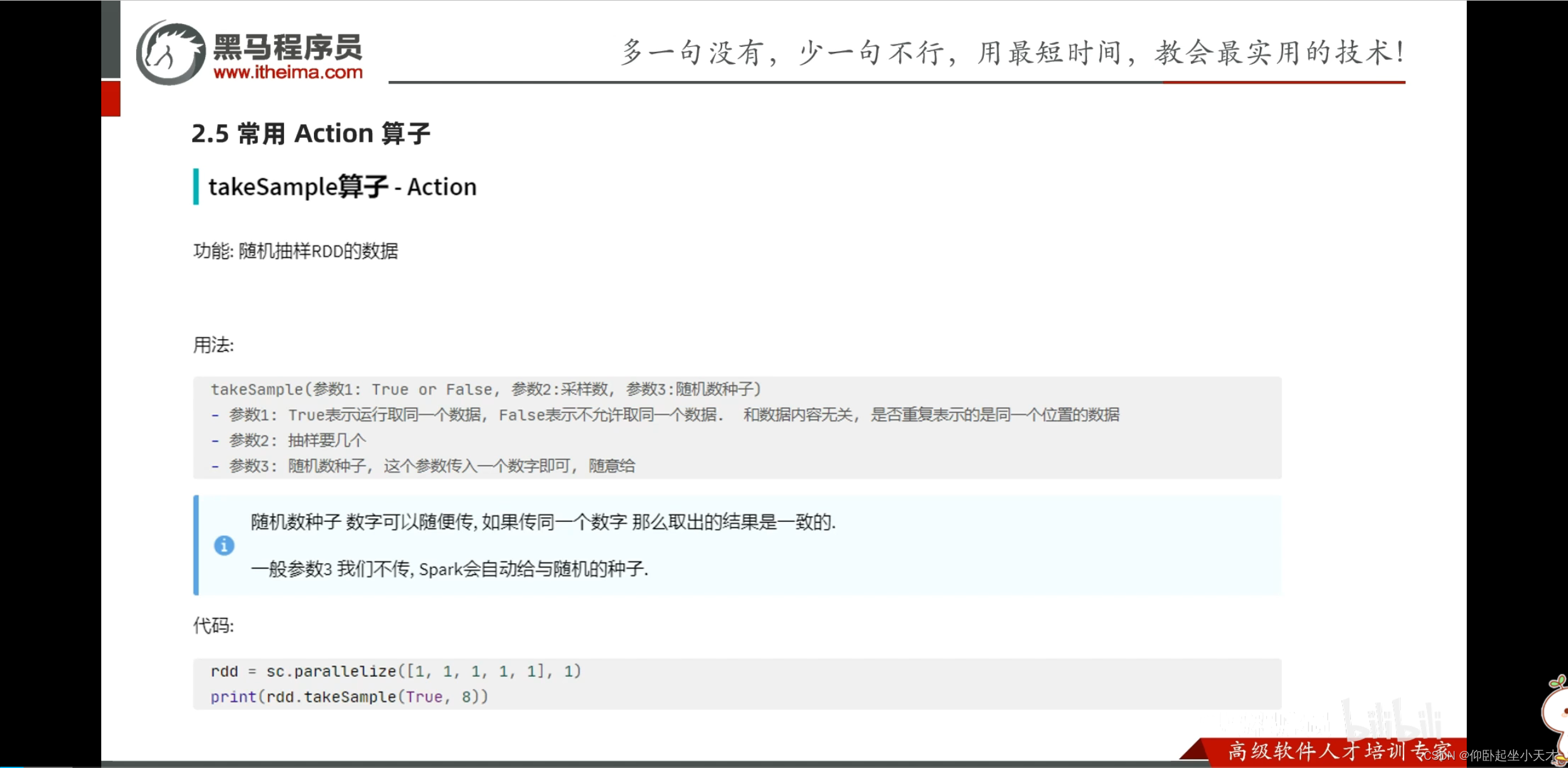
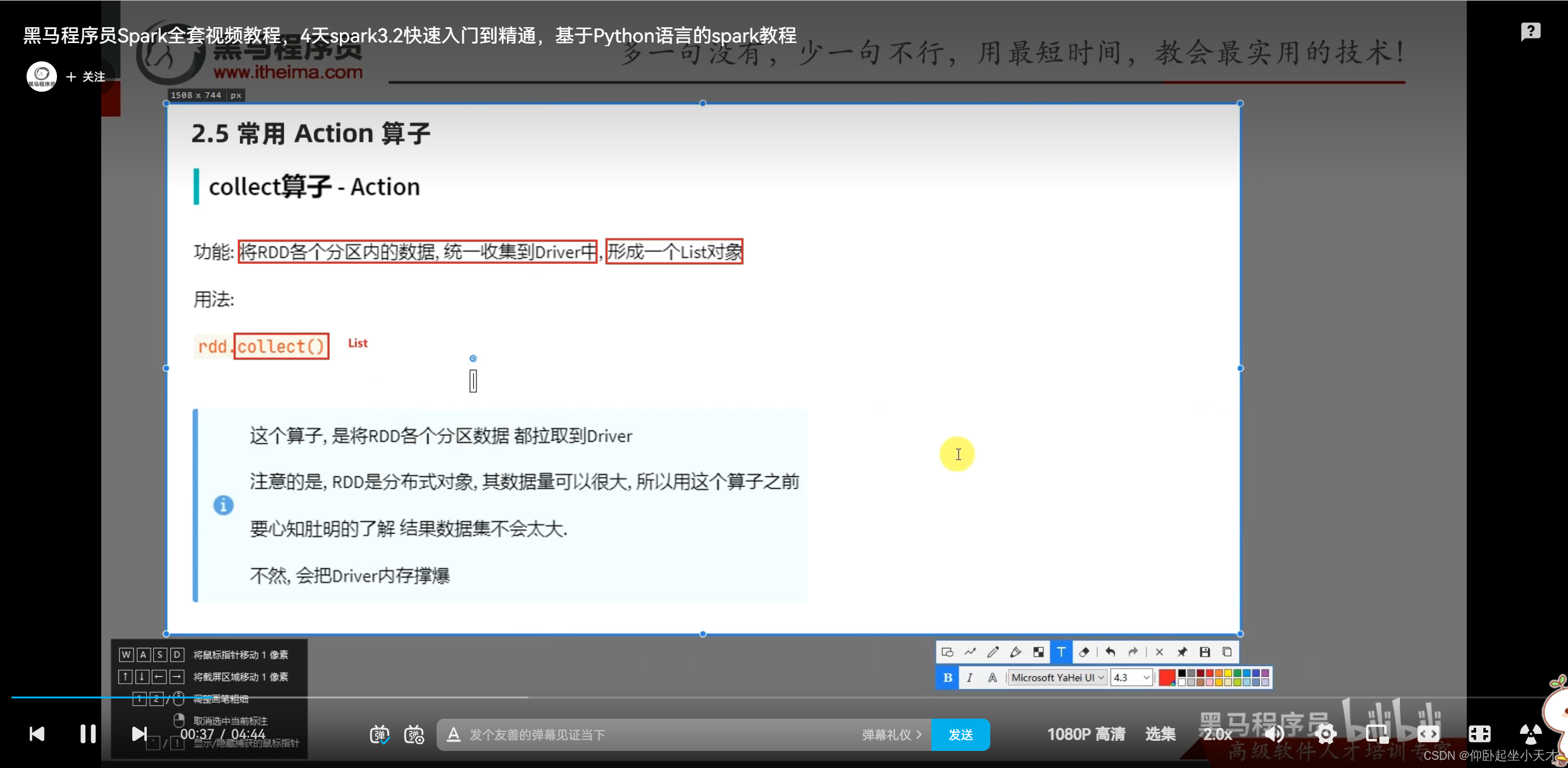
附:1. 数据量大的时候,用collect可能会爆。所以可以用takeSample随机抽几个出来看看。
2. 例有10个数,写取20个,若写的有放回,则可以取出来;若写的无放回,则会报错
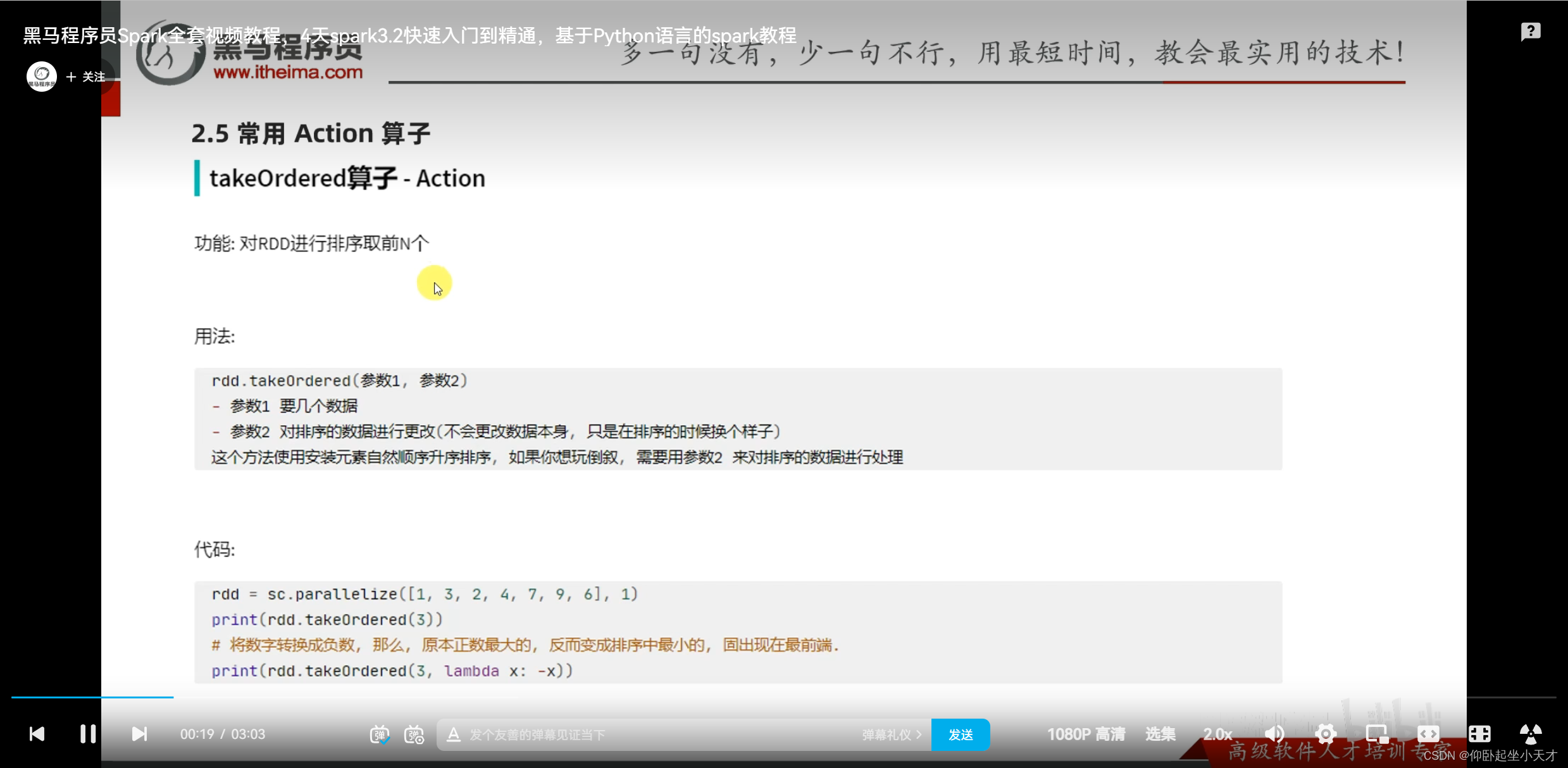
附:和top的区别;takeOrdered能升序也能降序,是通过能在排序的时候操作数据实现的(没有直接的参数)
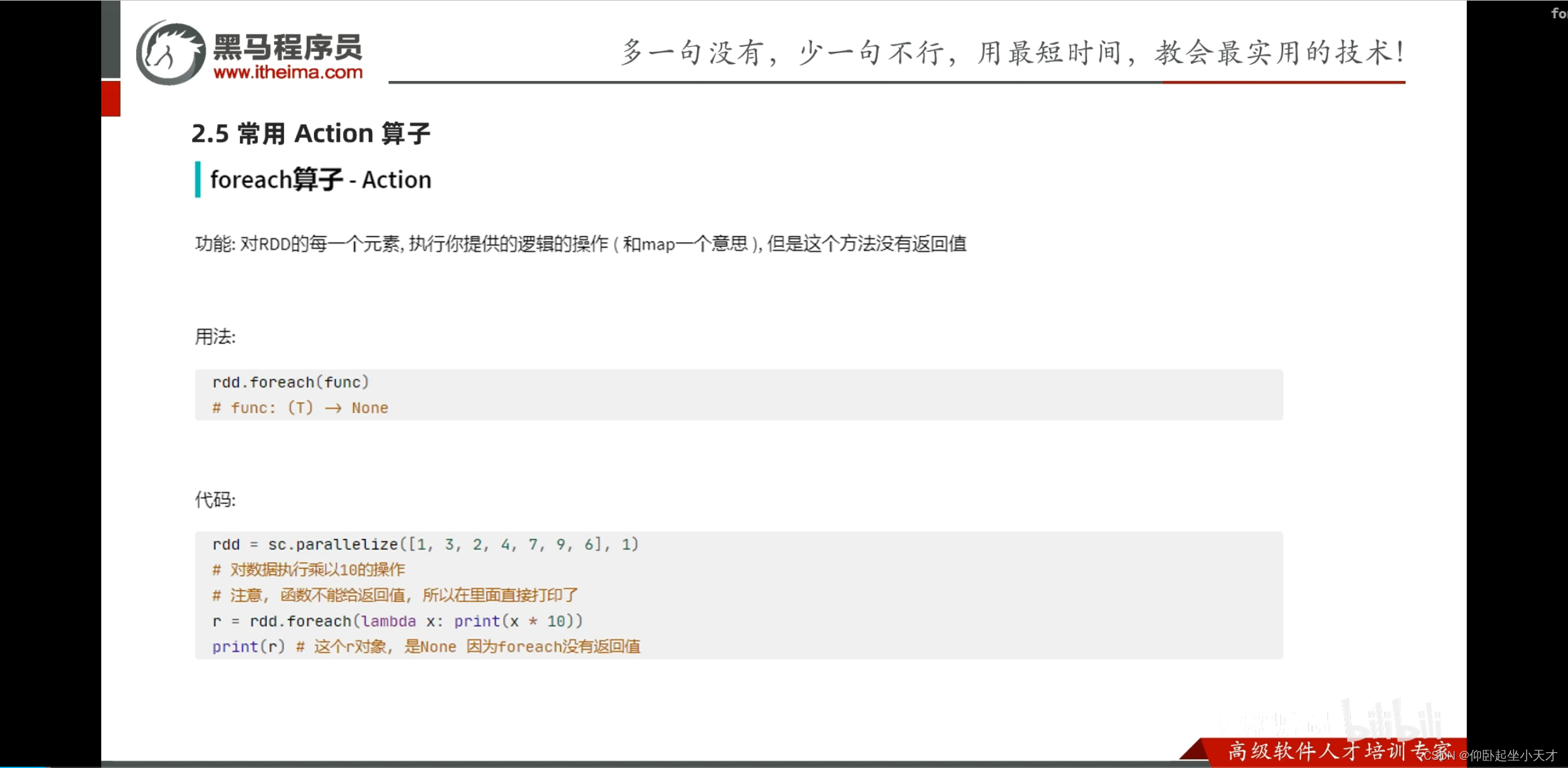

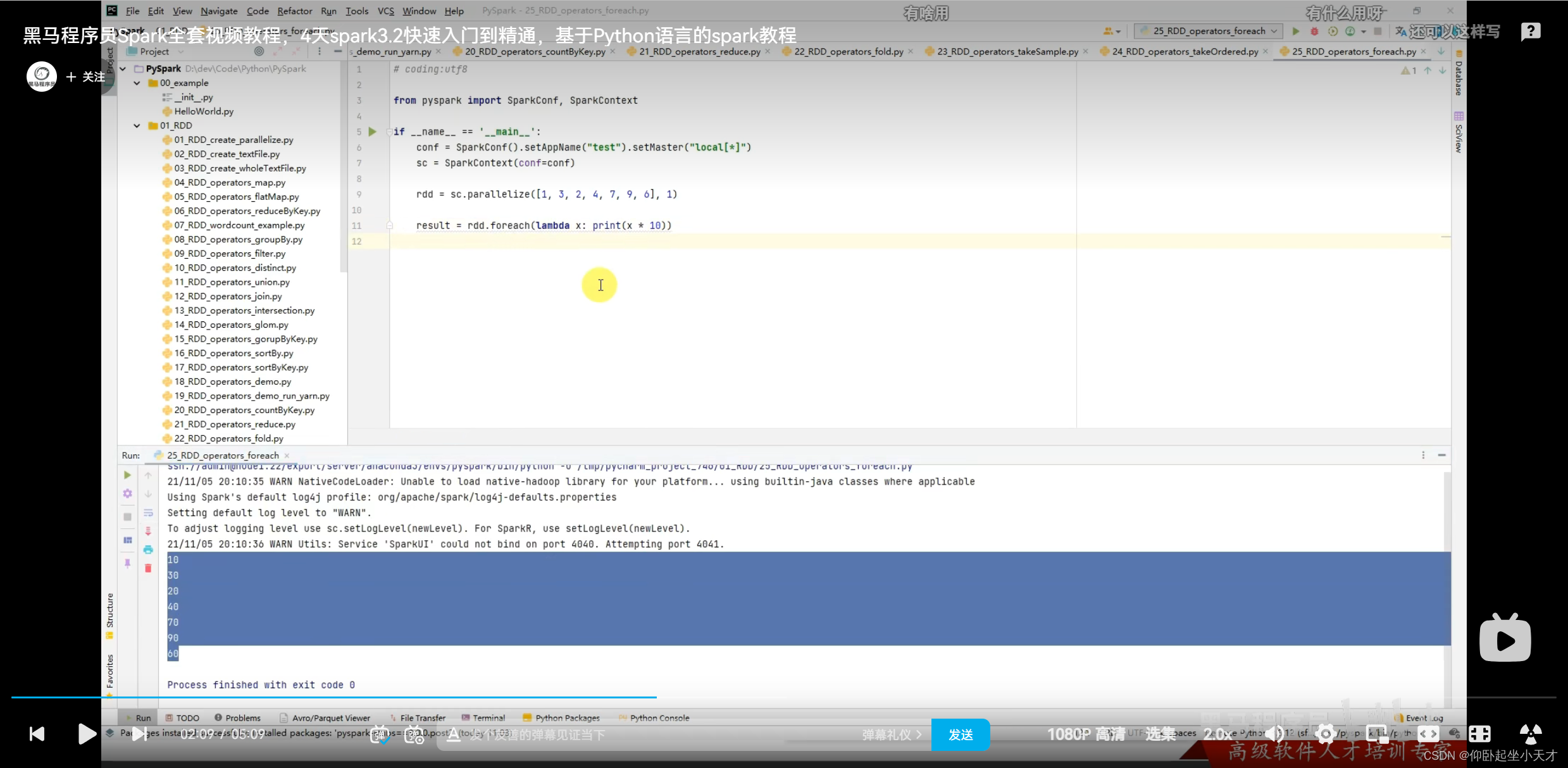
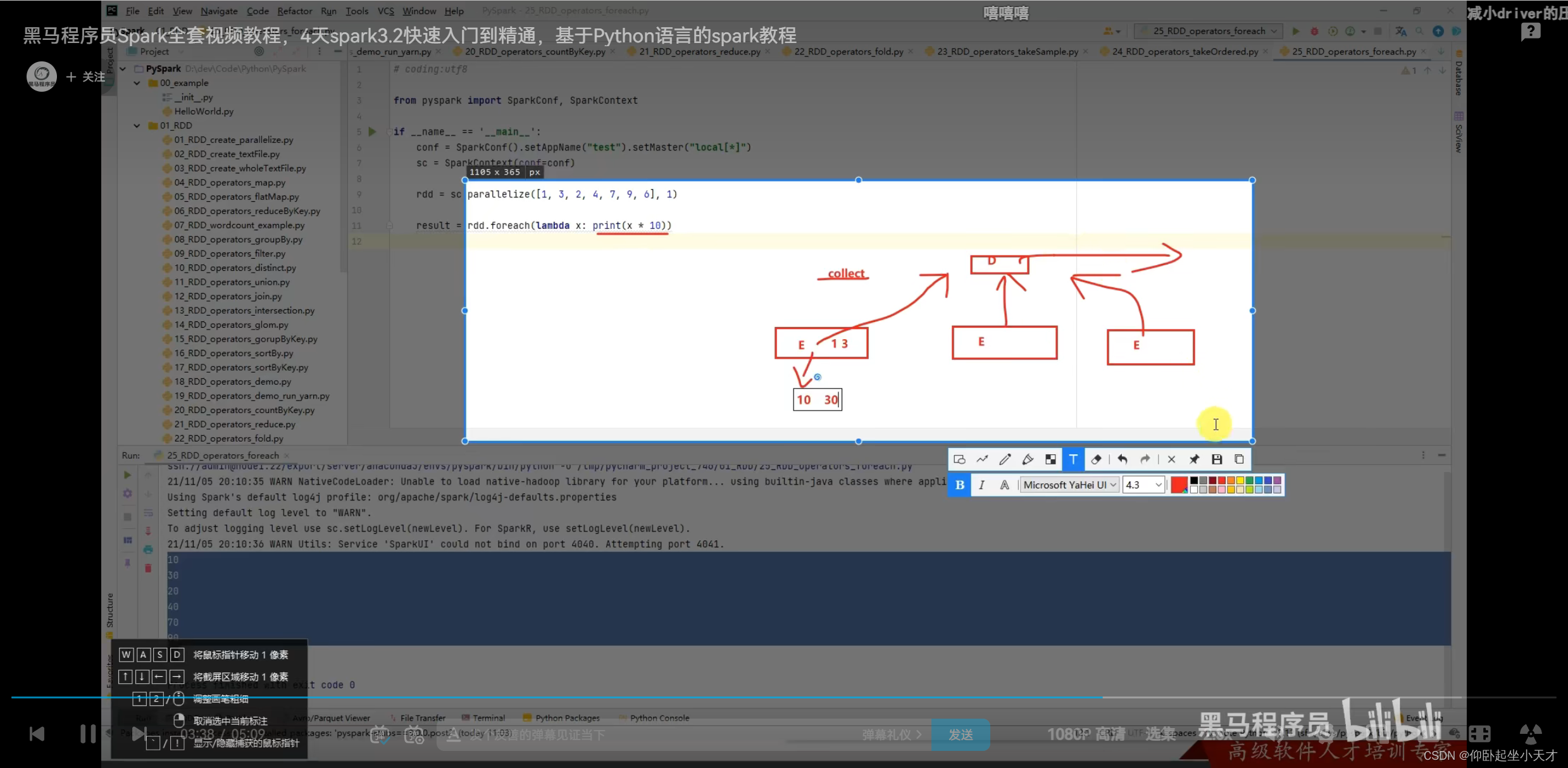
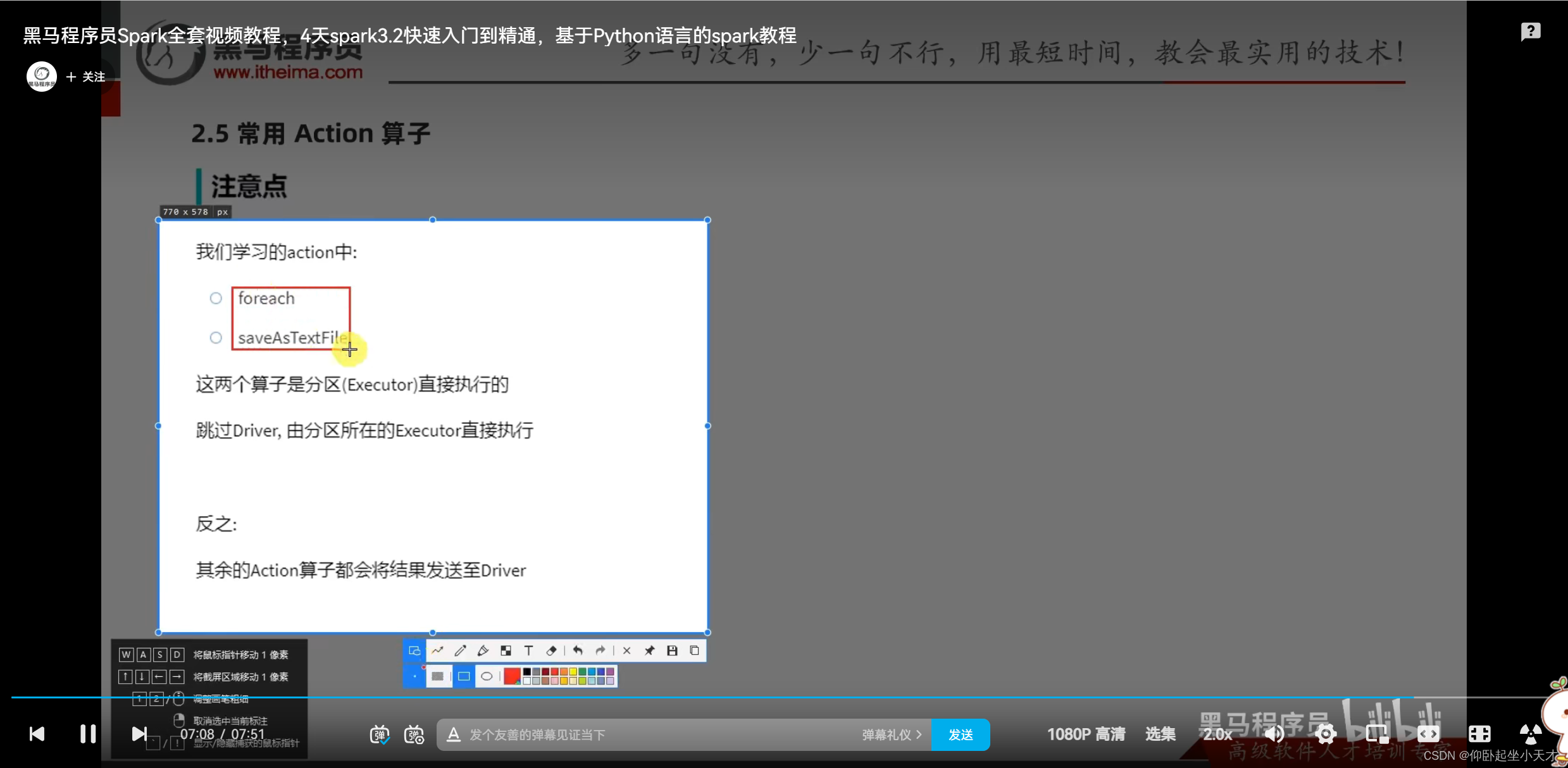
附:foreach是executor直接输入的,和以前的不一样;不上传driver里面,效率高一点,相当于有并行。
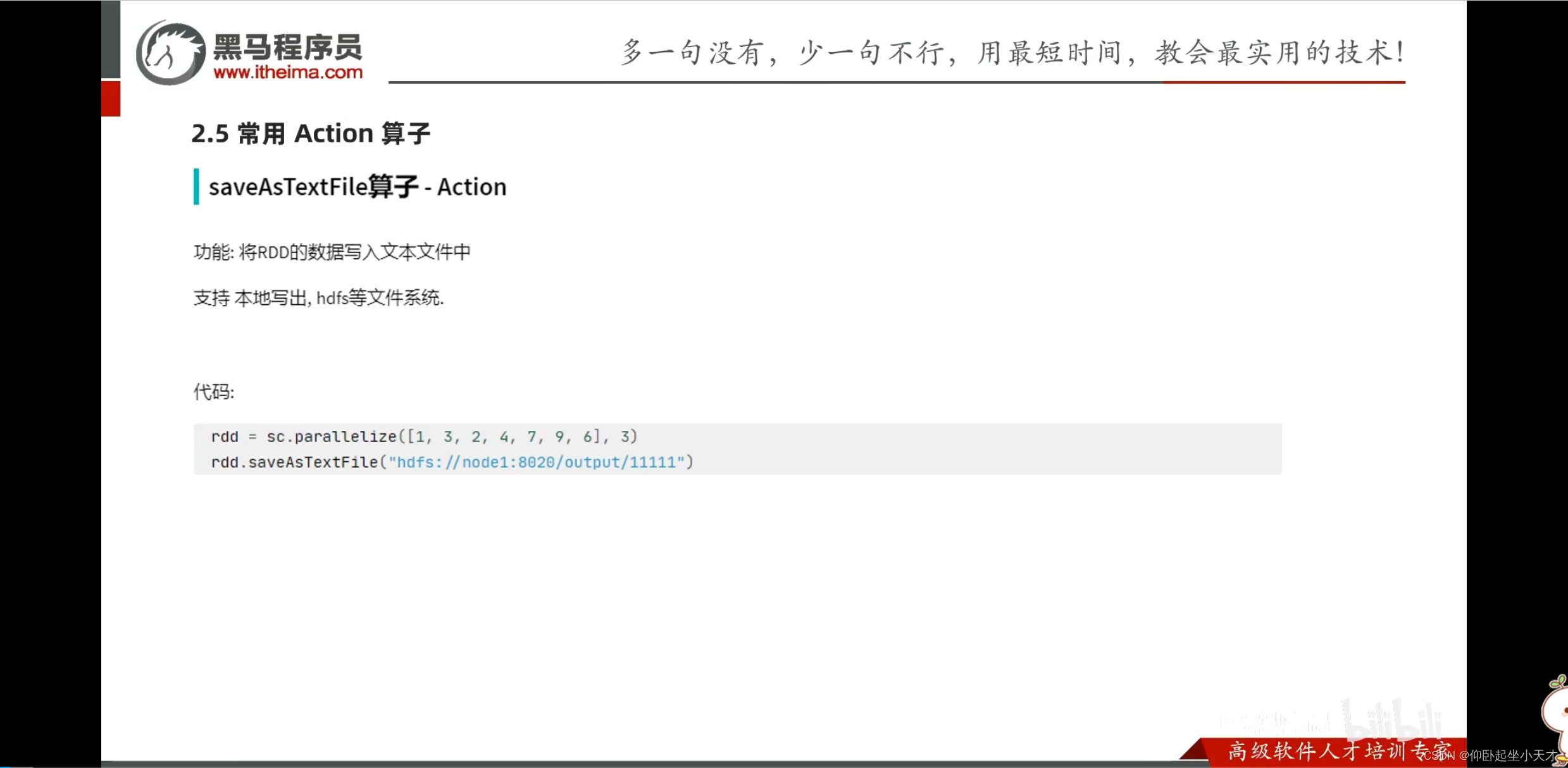
附:1. 有几个分区,则输出几个文件;因为也是用executor直接写出的,和foreach一样
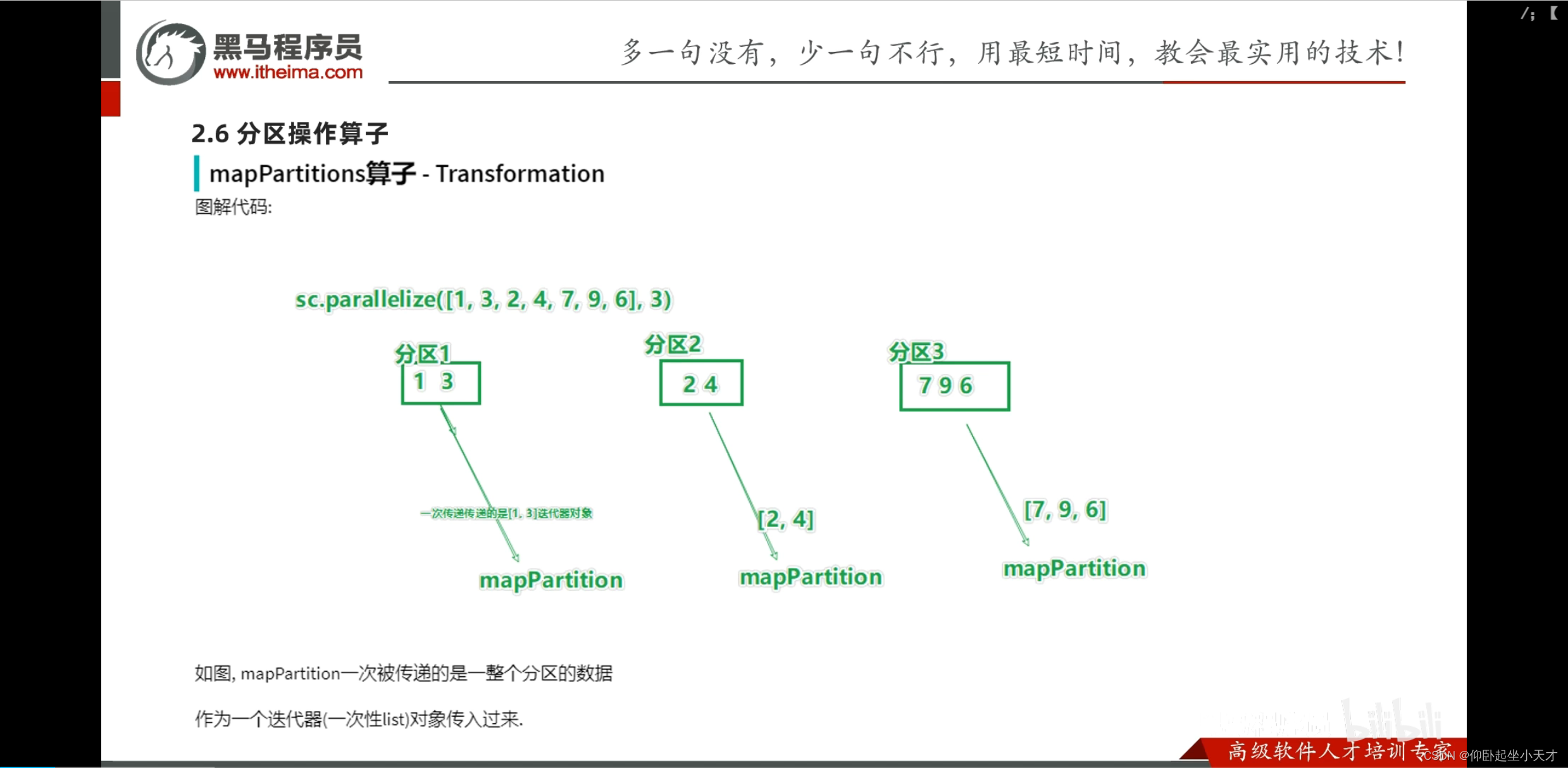
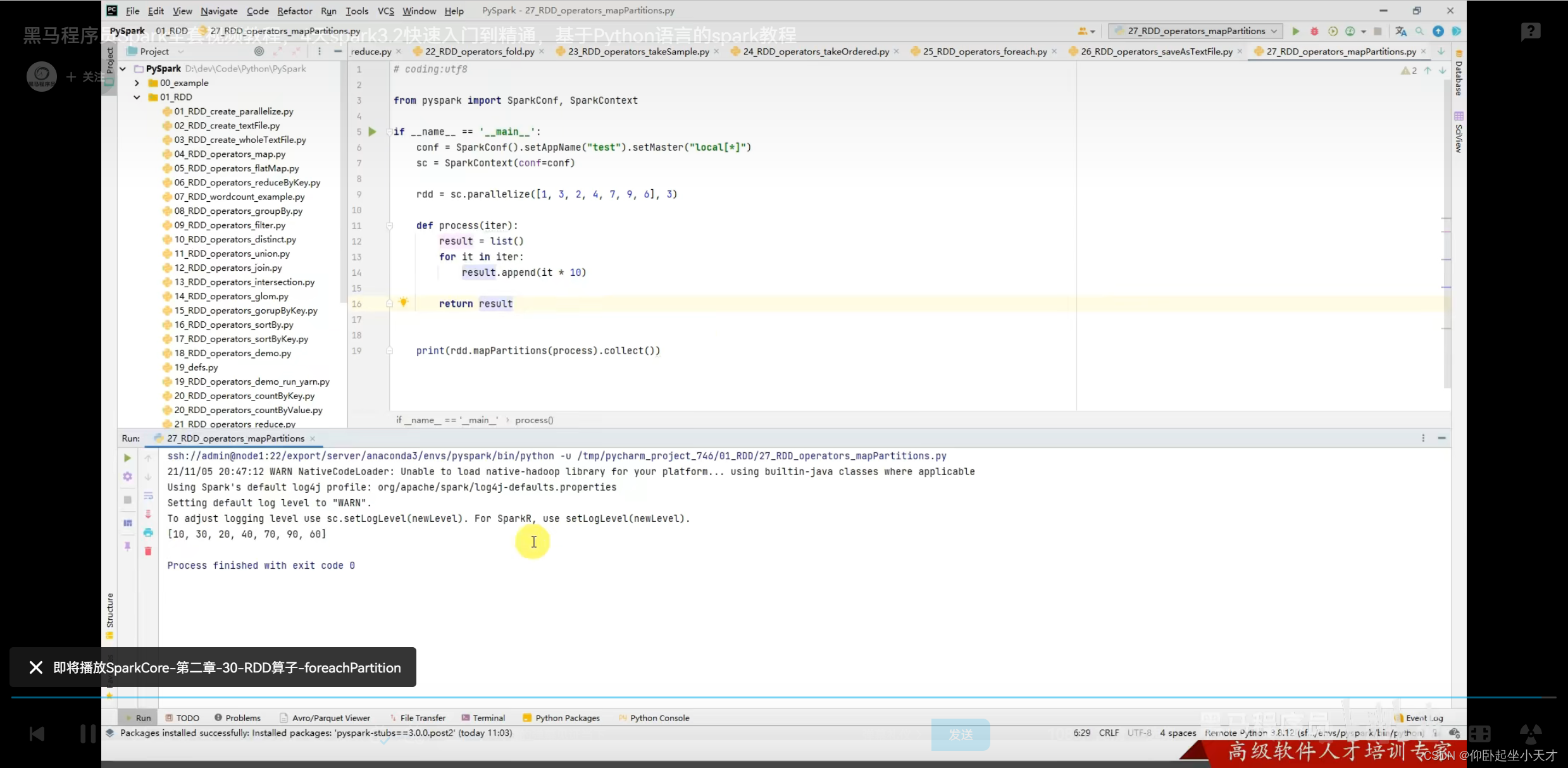
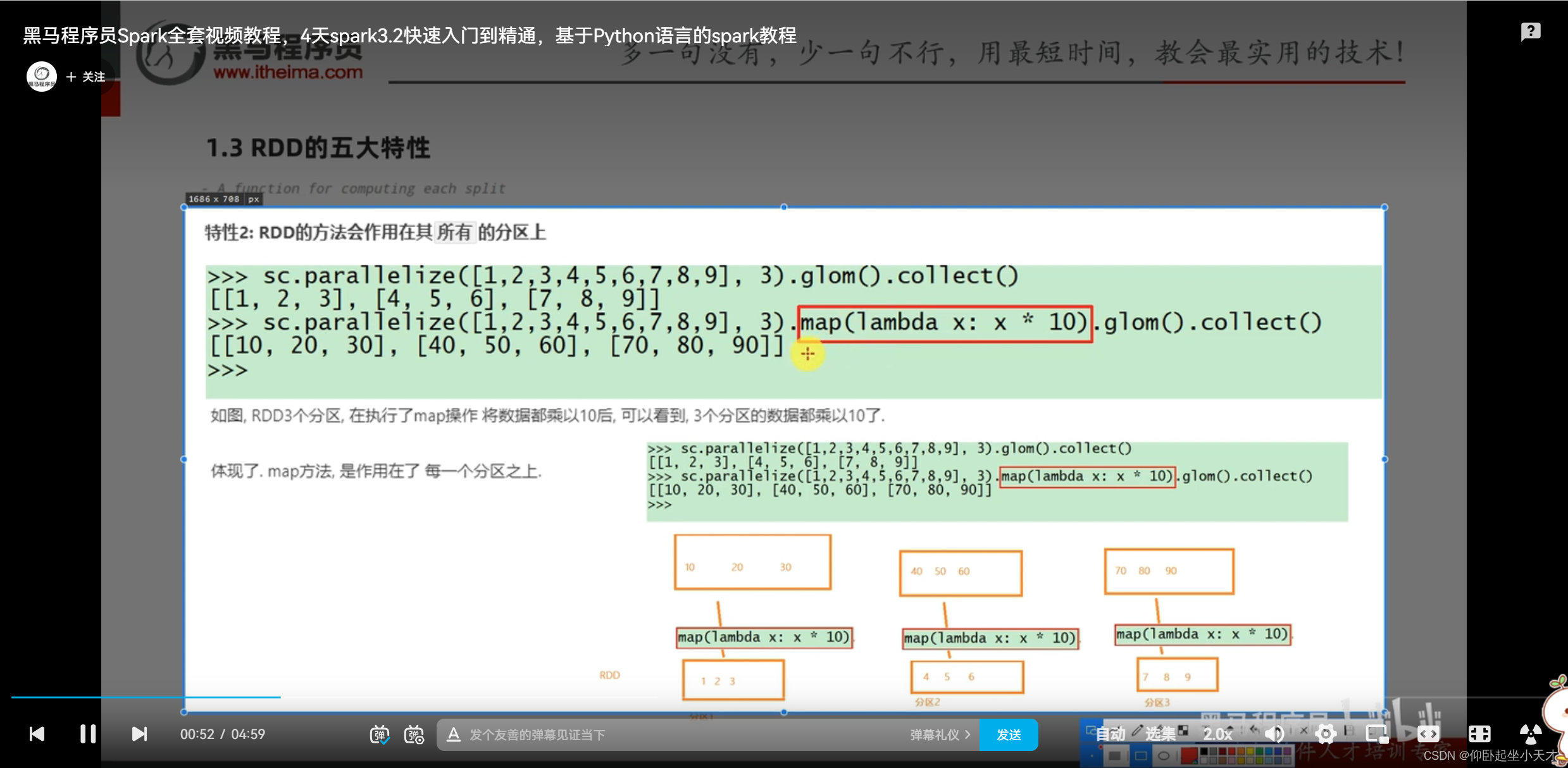
附:例子中, map是有6次调用处理6个数据;mapPartitions是一整个分区一起处理,只用了3次数据传输(即一次处理一个迭代器对象iterable);优点是如果网络之间是隔开的,无法走网络进行统一处理的话,这种分区处理就是有效的;空间利用率上有提升
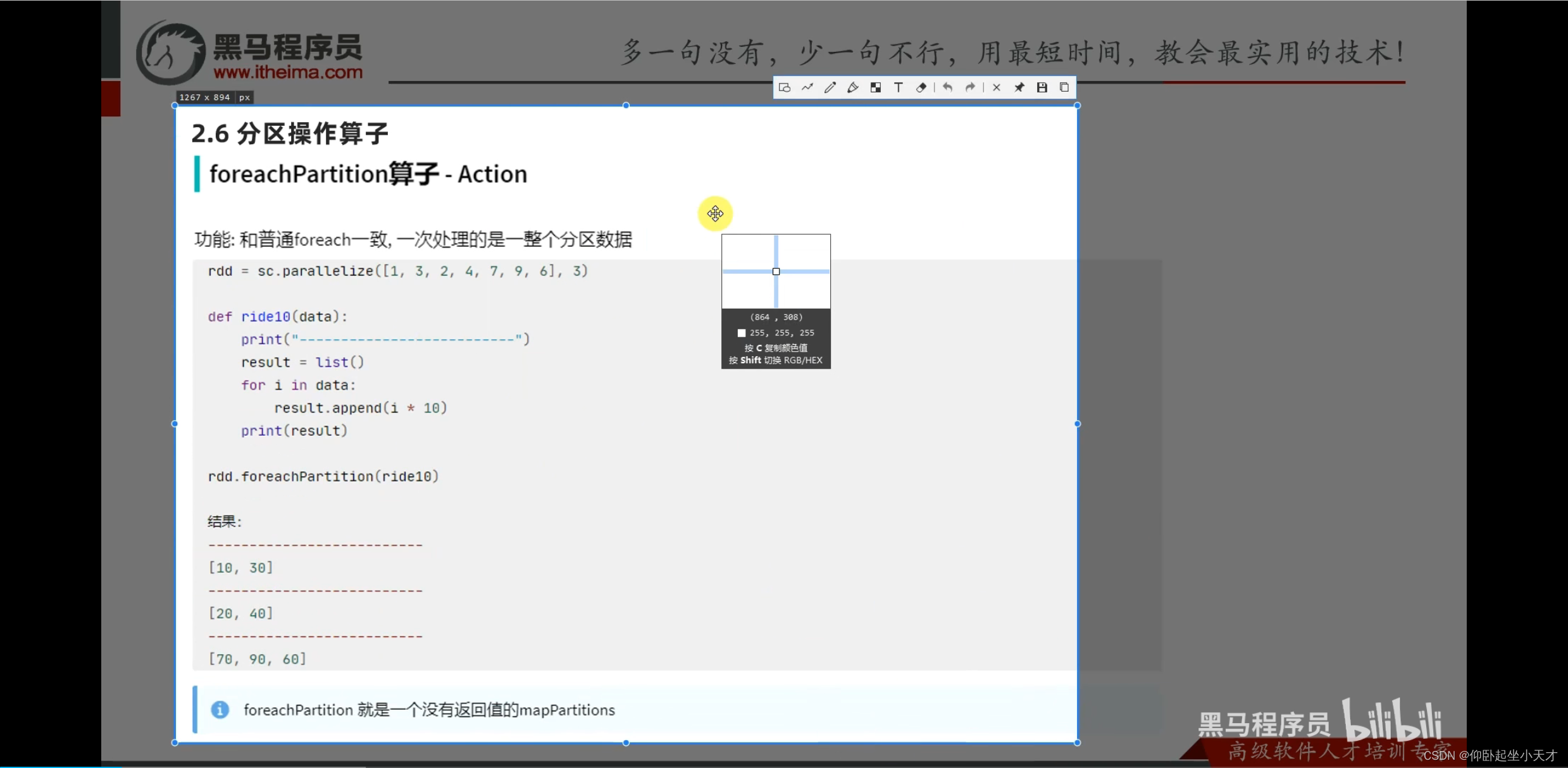
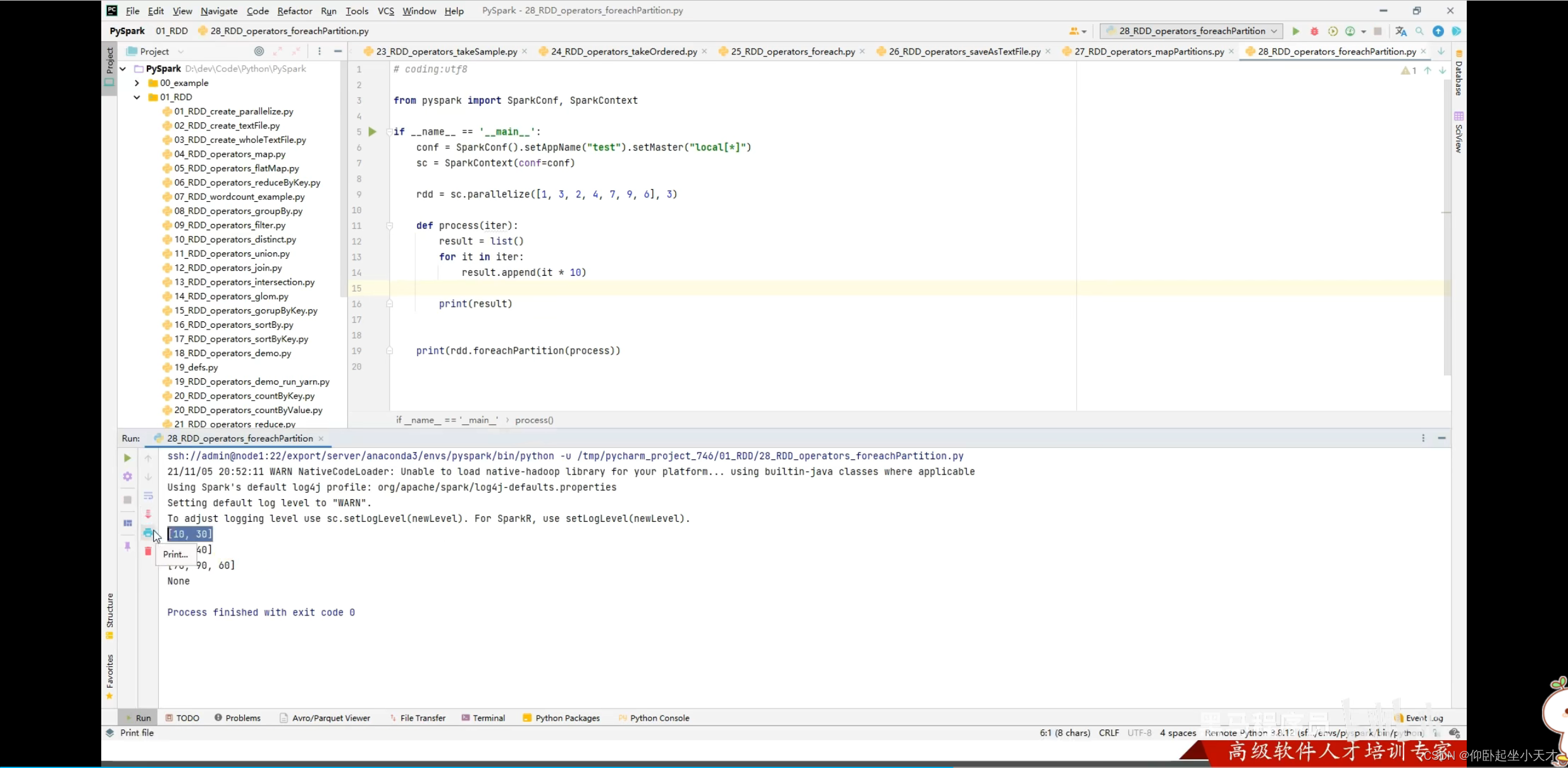
附:没有返回值的时候,用print会直接出none
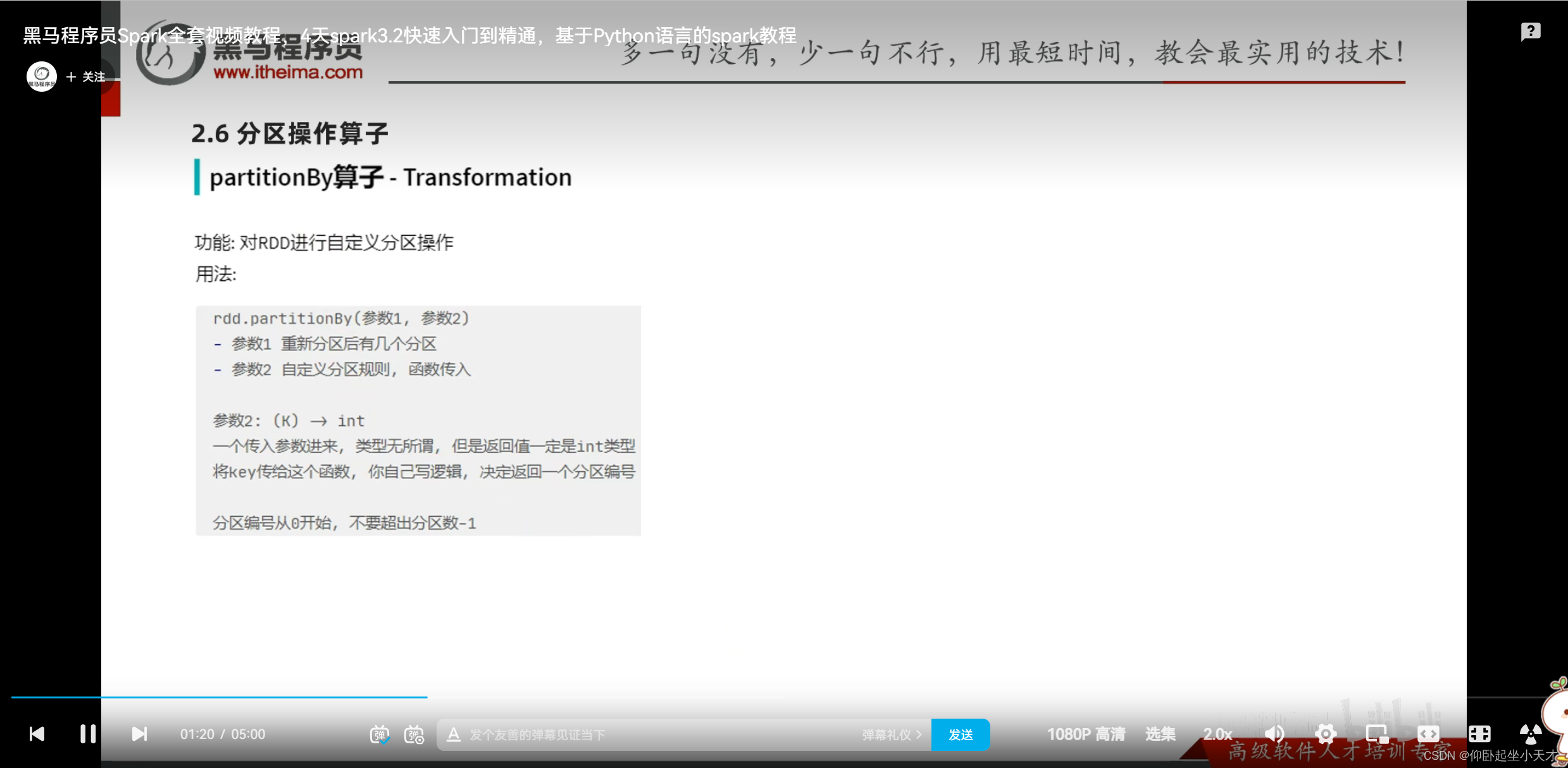
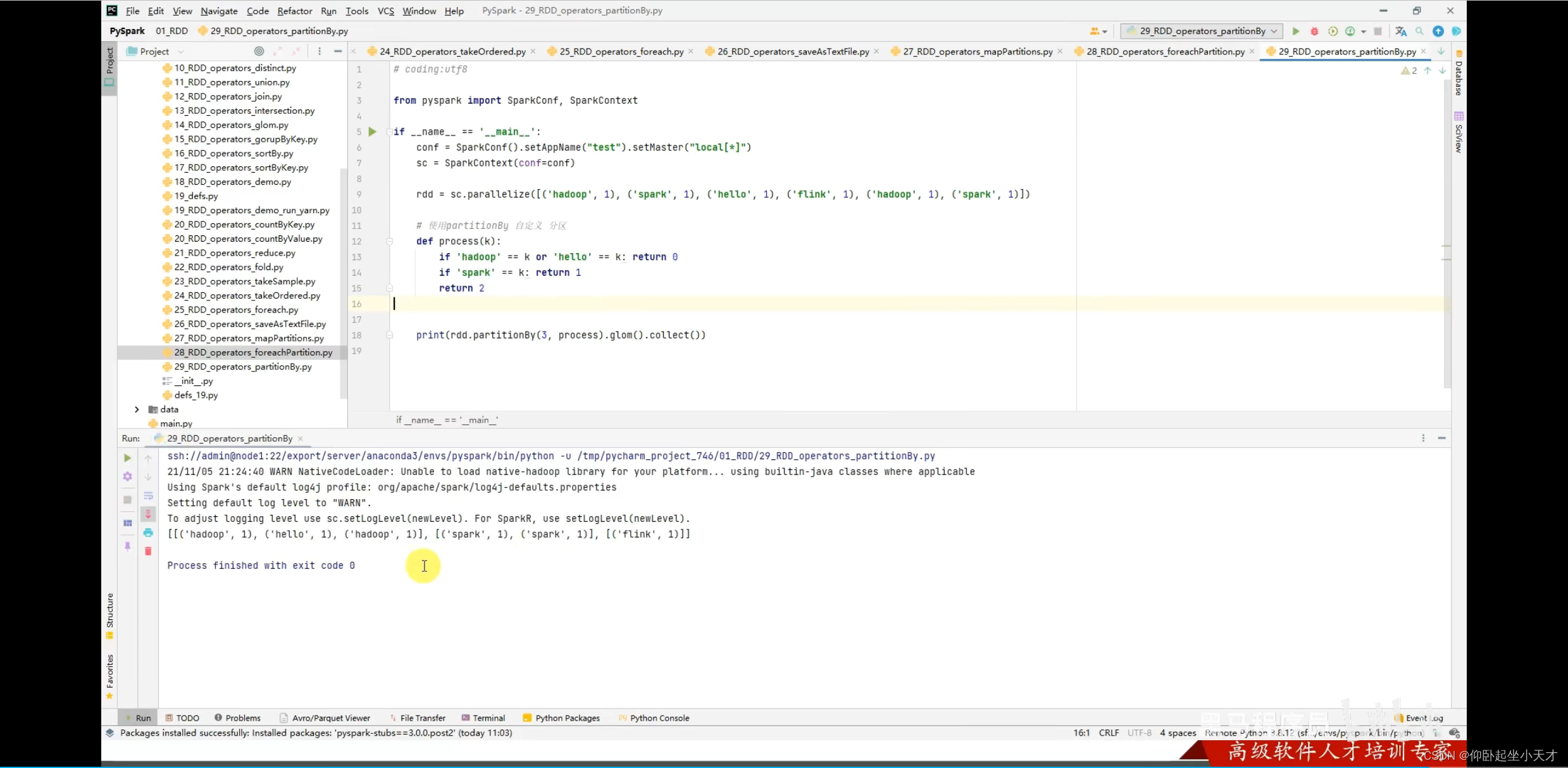
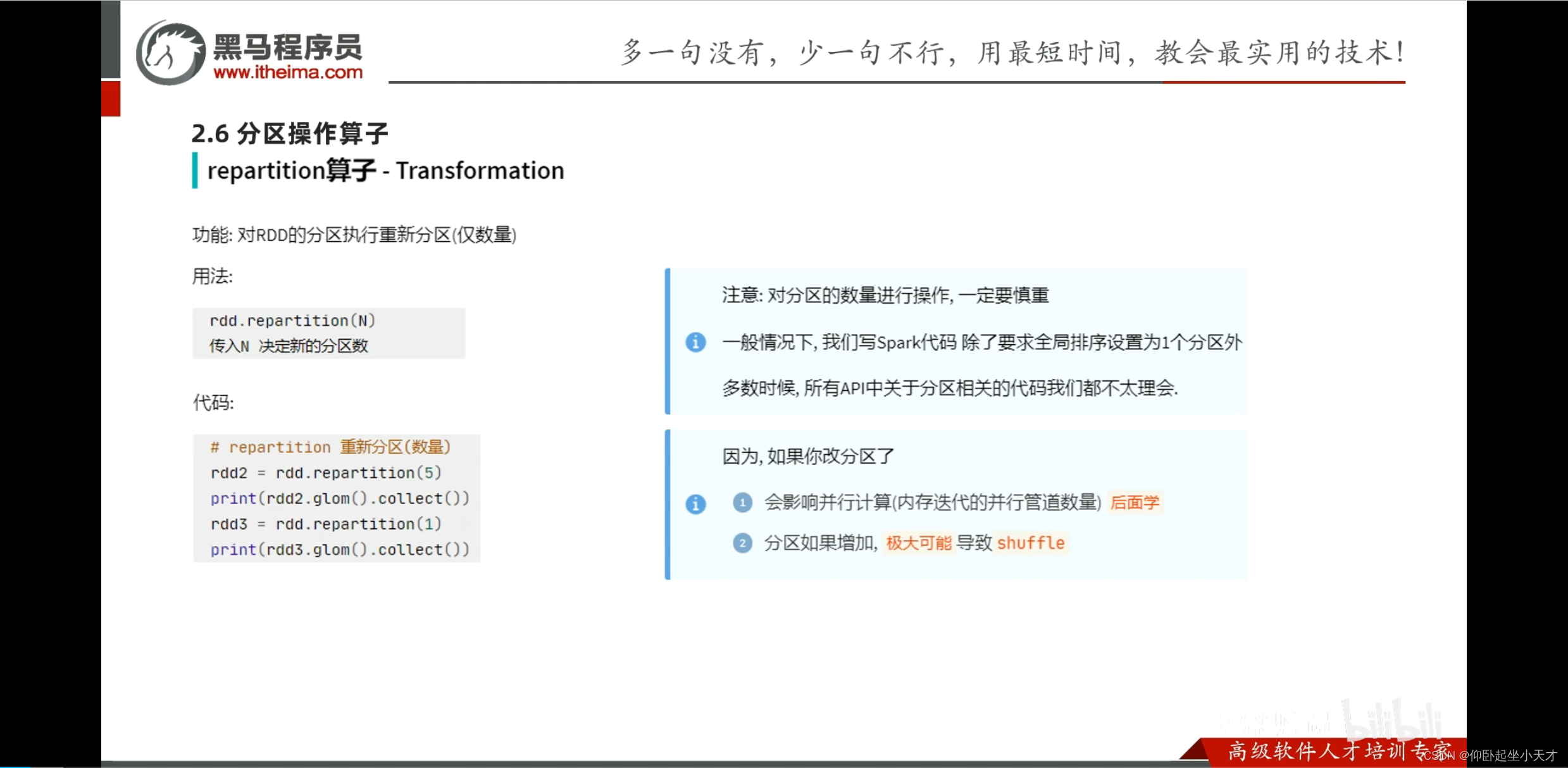
附:1. 一般不要动分区,除非是要全局排序时指定为1;特别是尽量不要增加分区
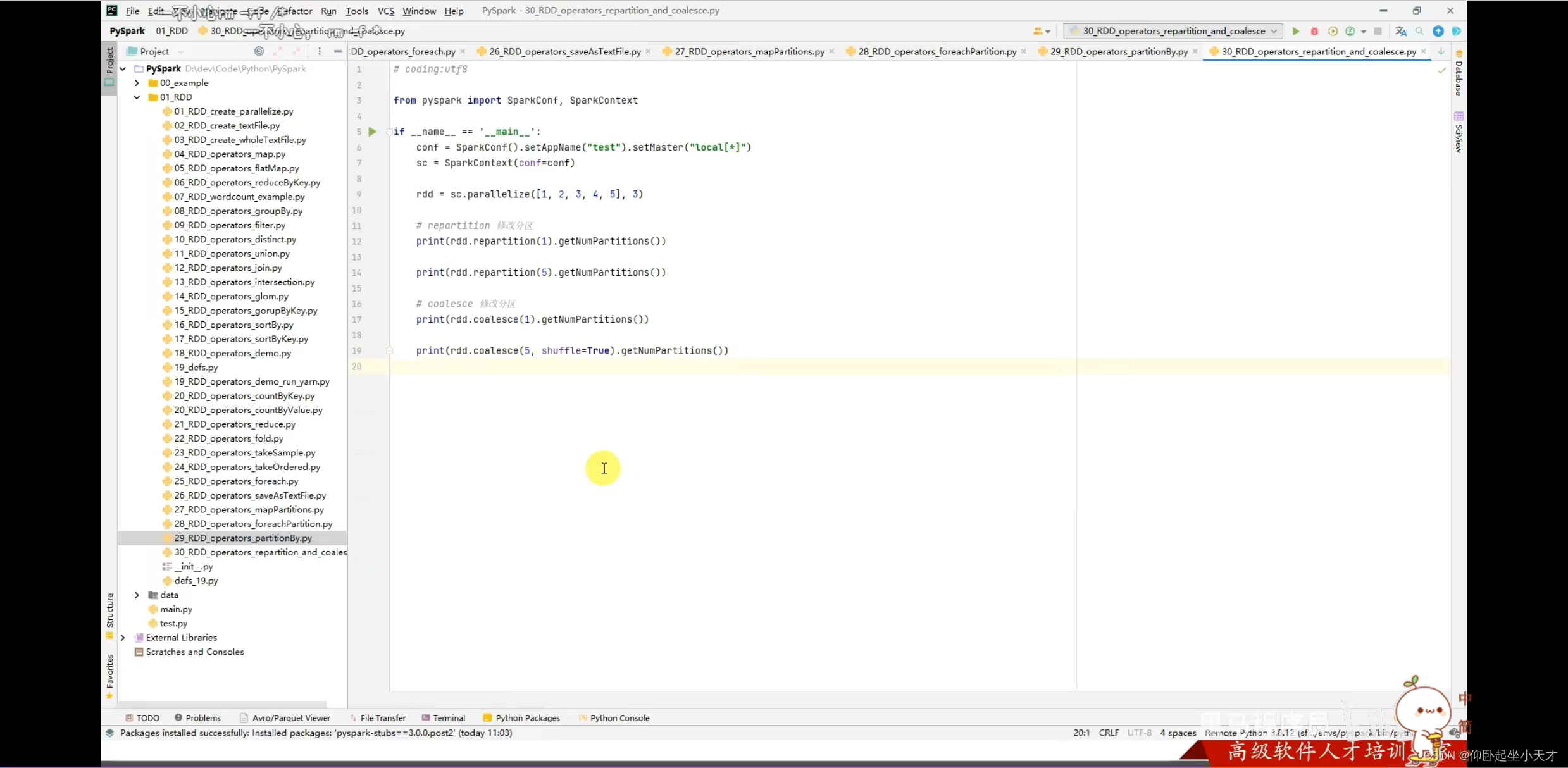
2.rePartition和coalesce是一个API,但是后者有一个安全阀Shuffle



避免链条被两次执行,用下面两种持续性方法
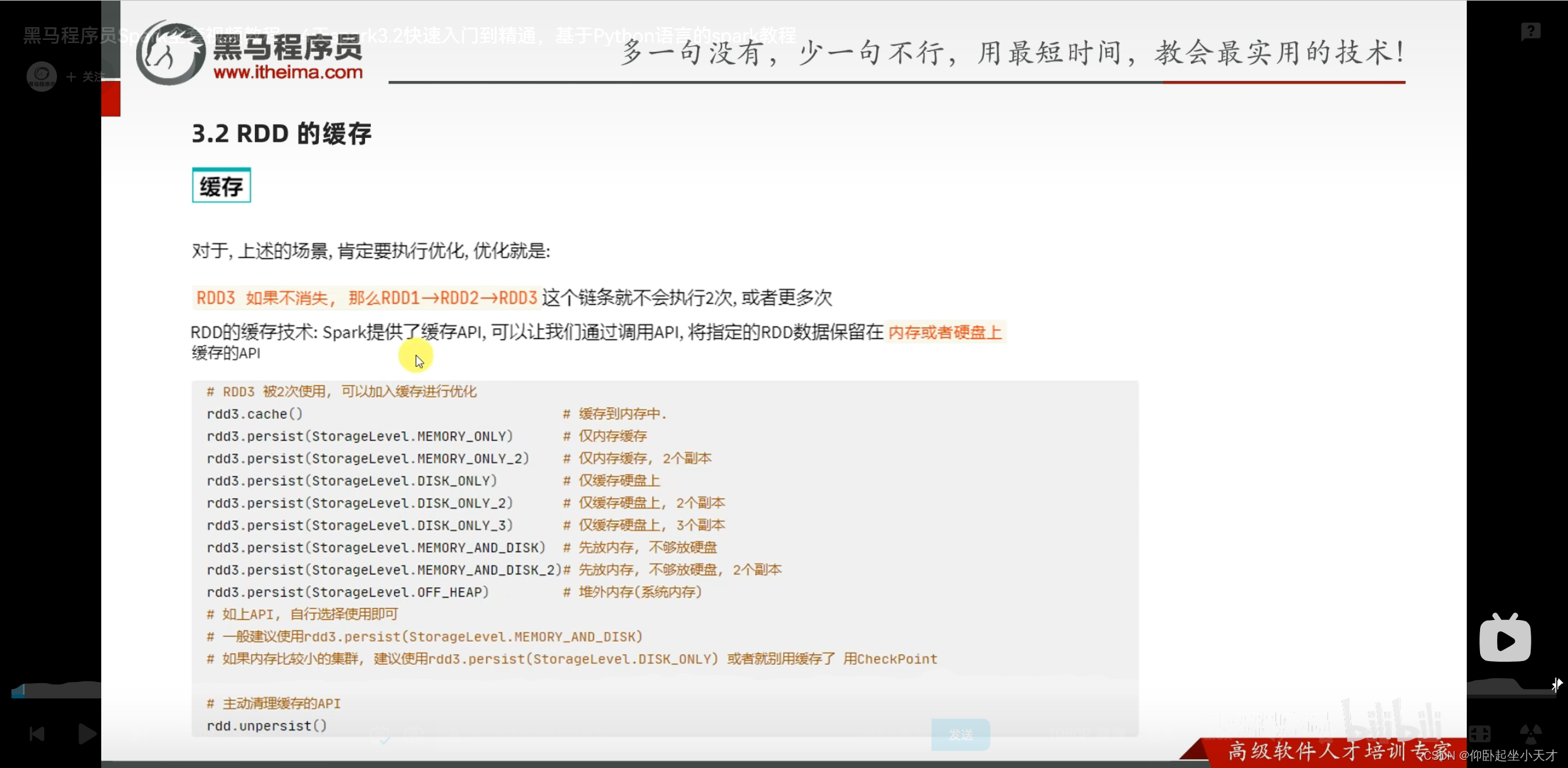

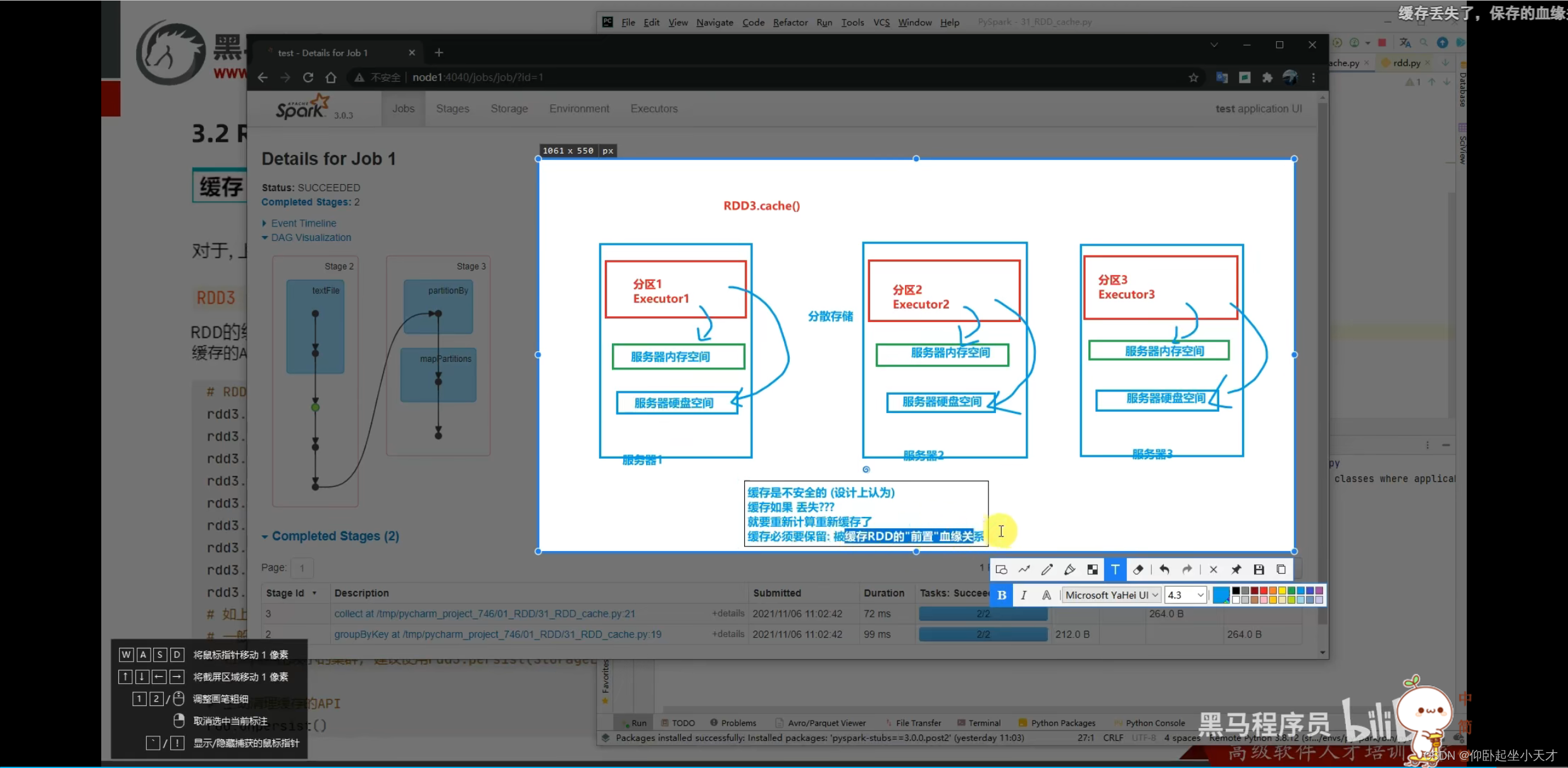
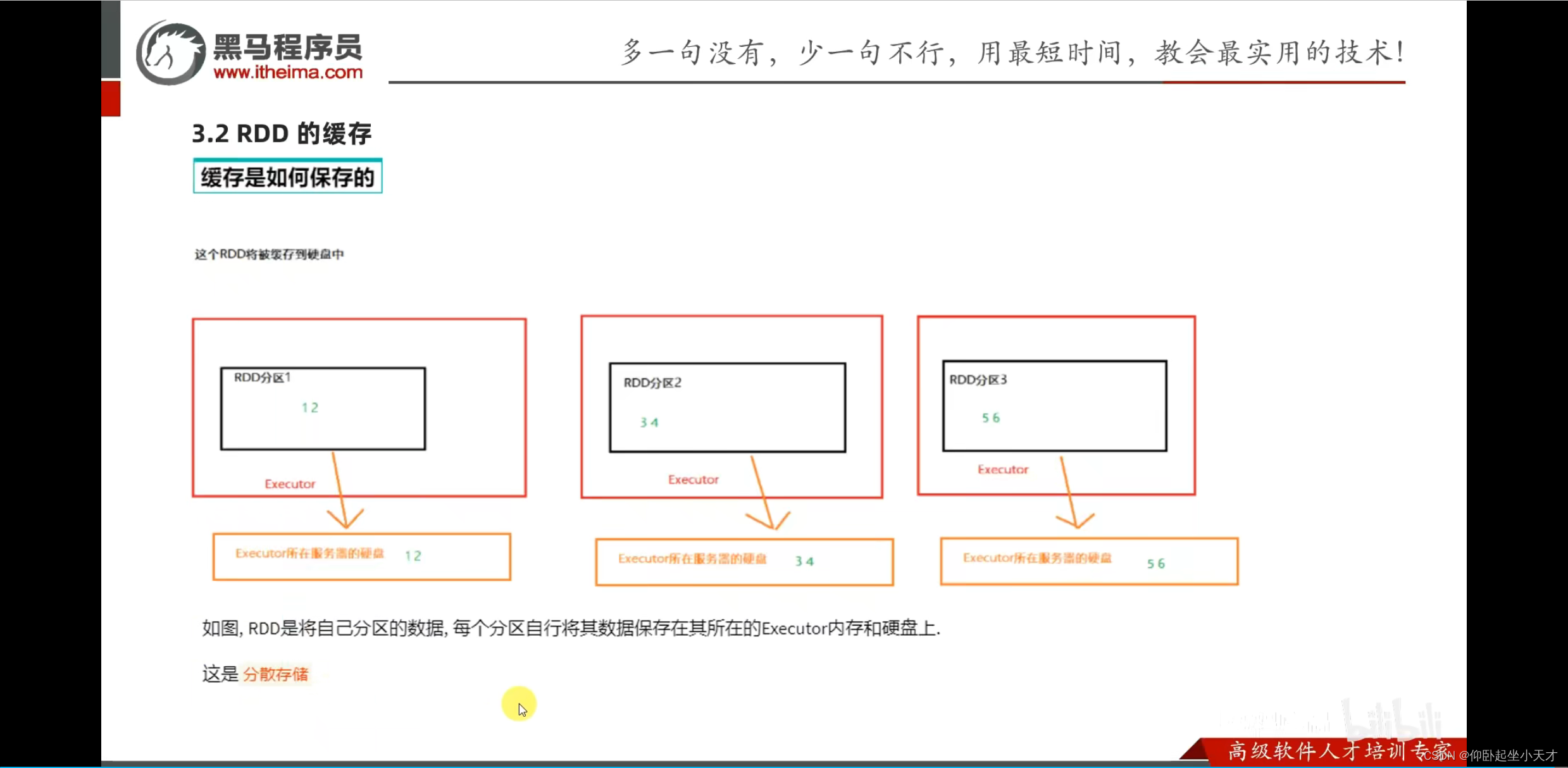
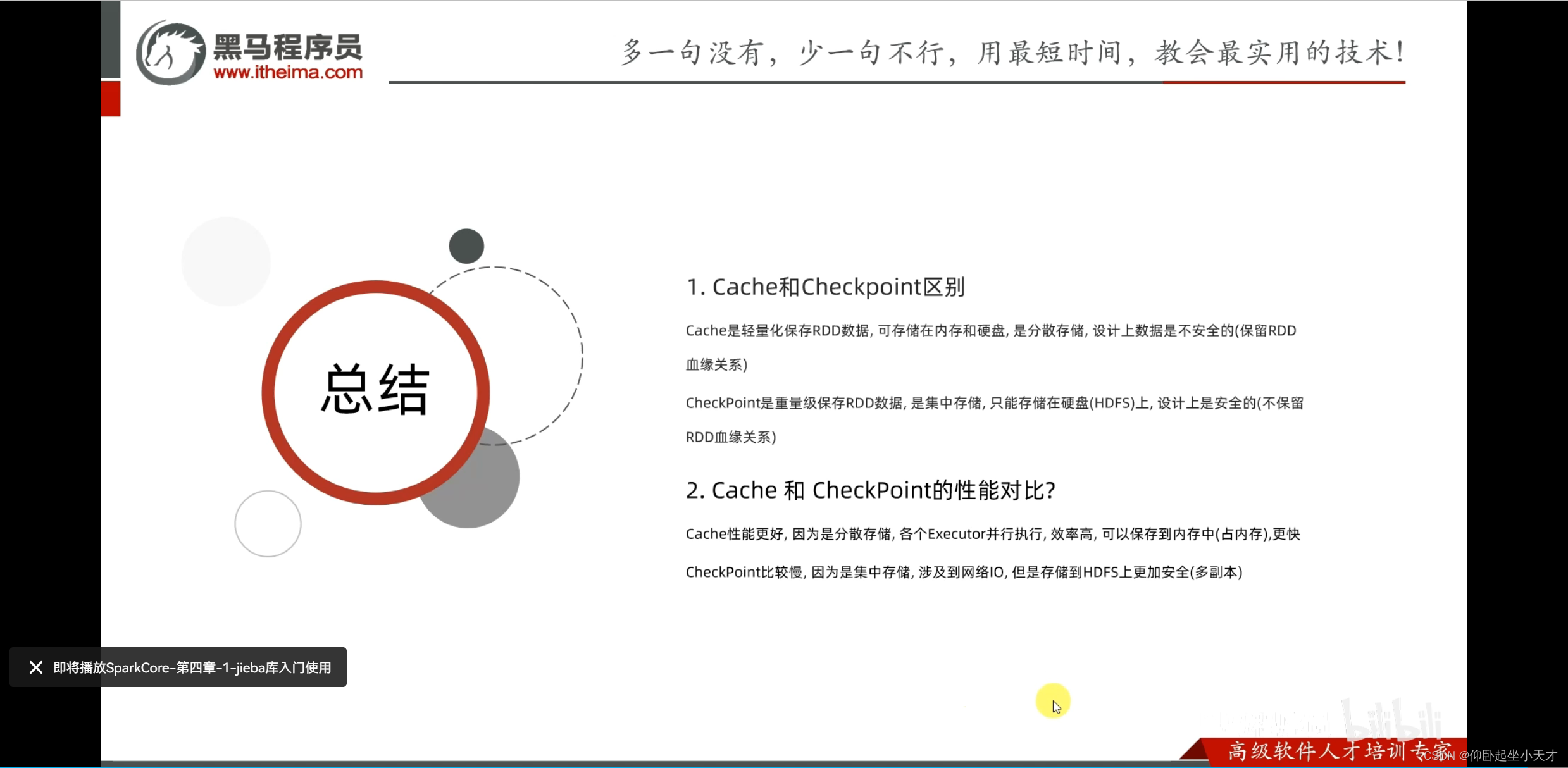
缓存保留血缘关系;是分散存储的。

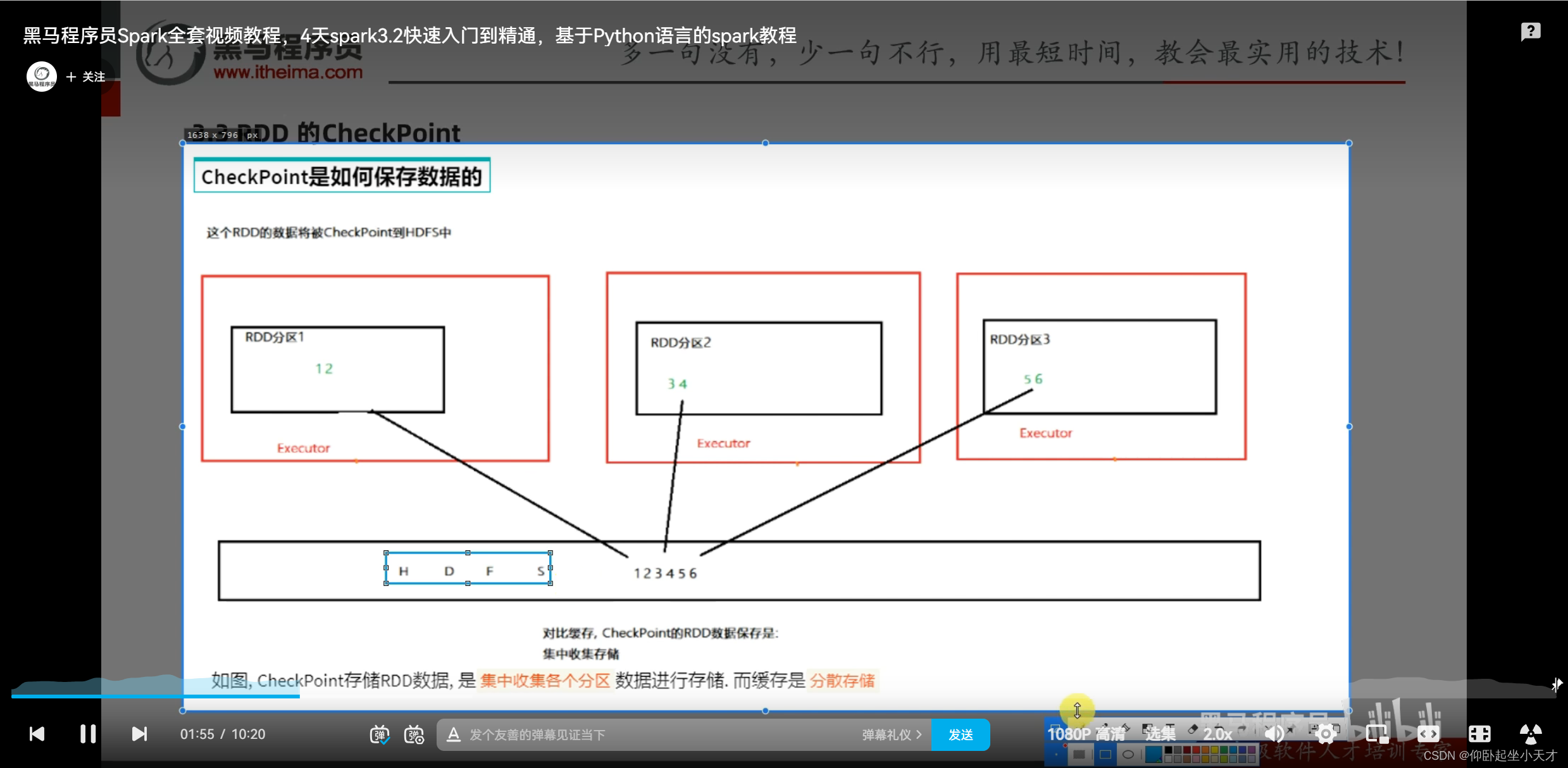
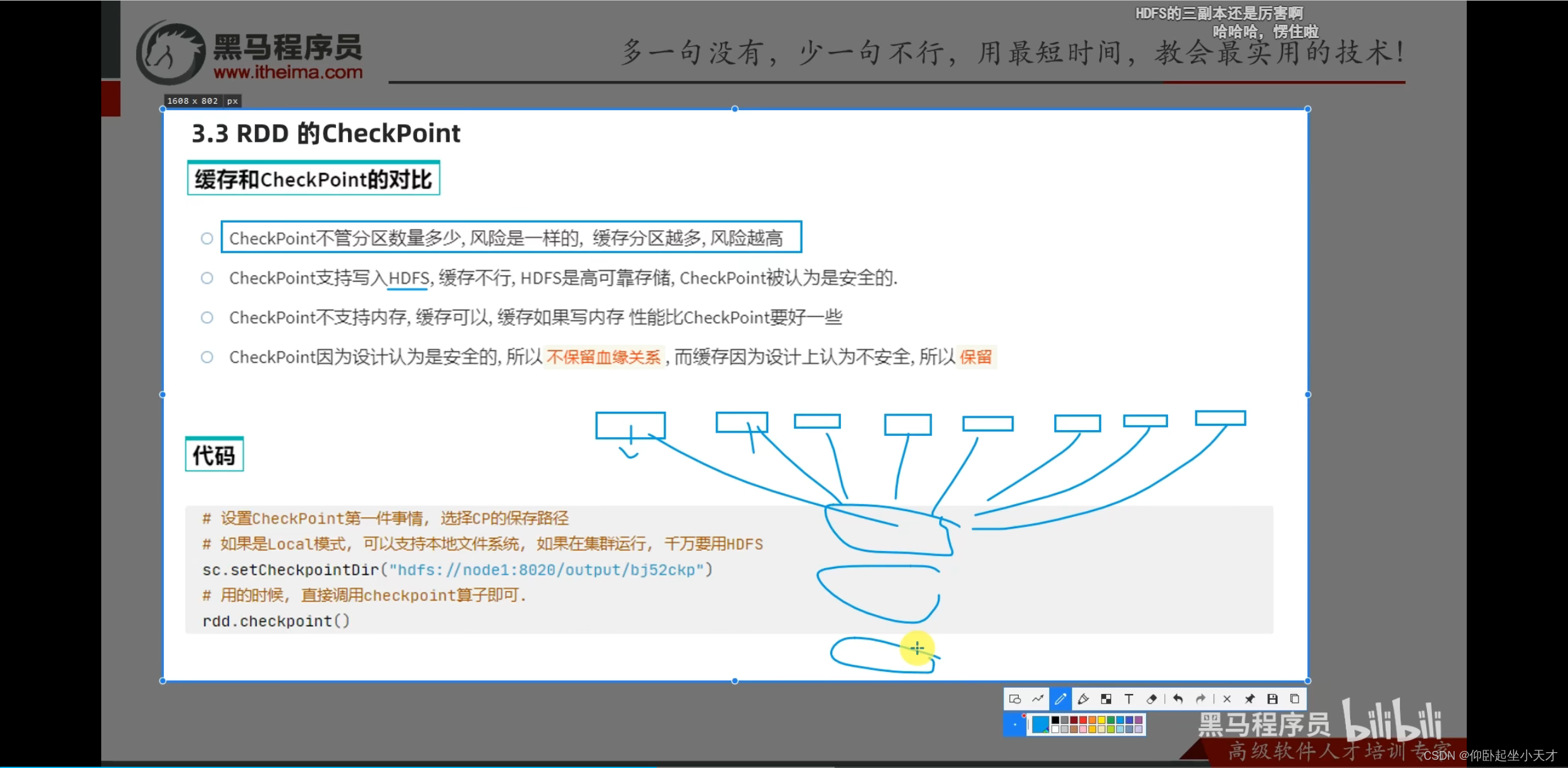
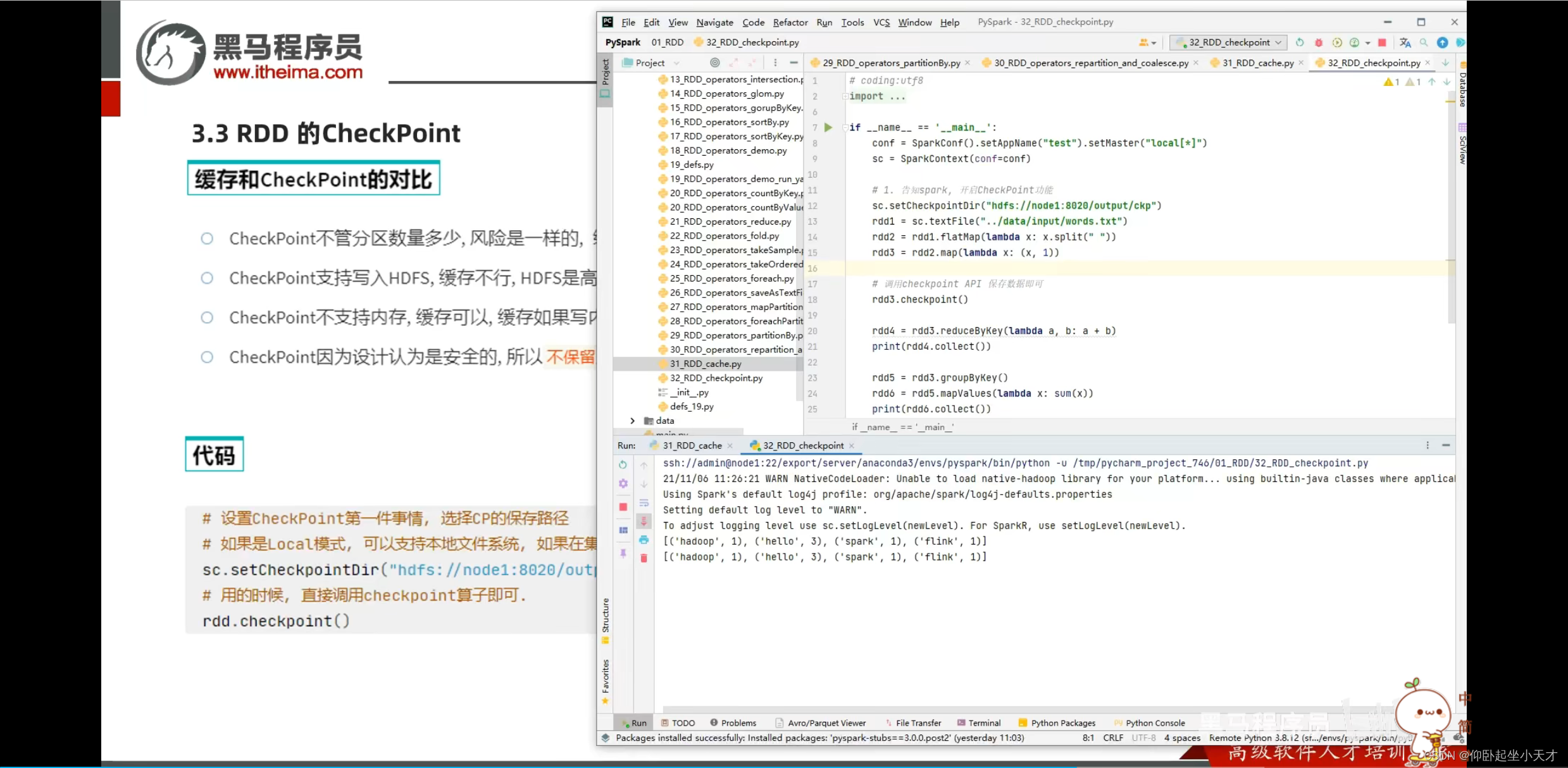
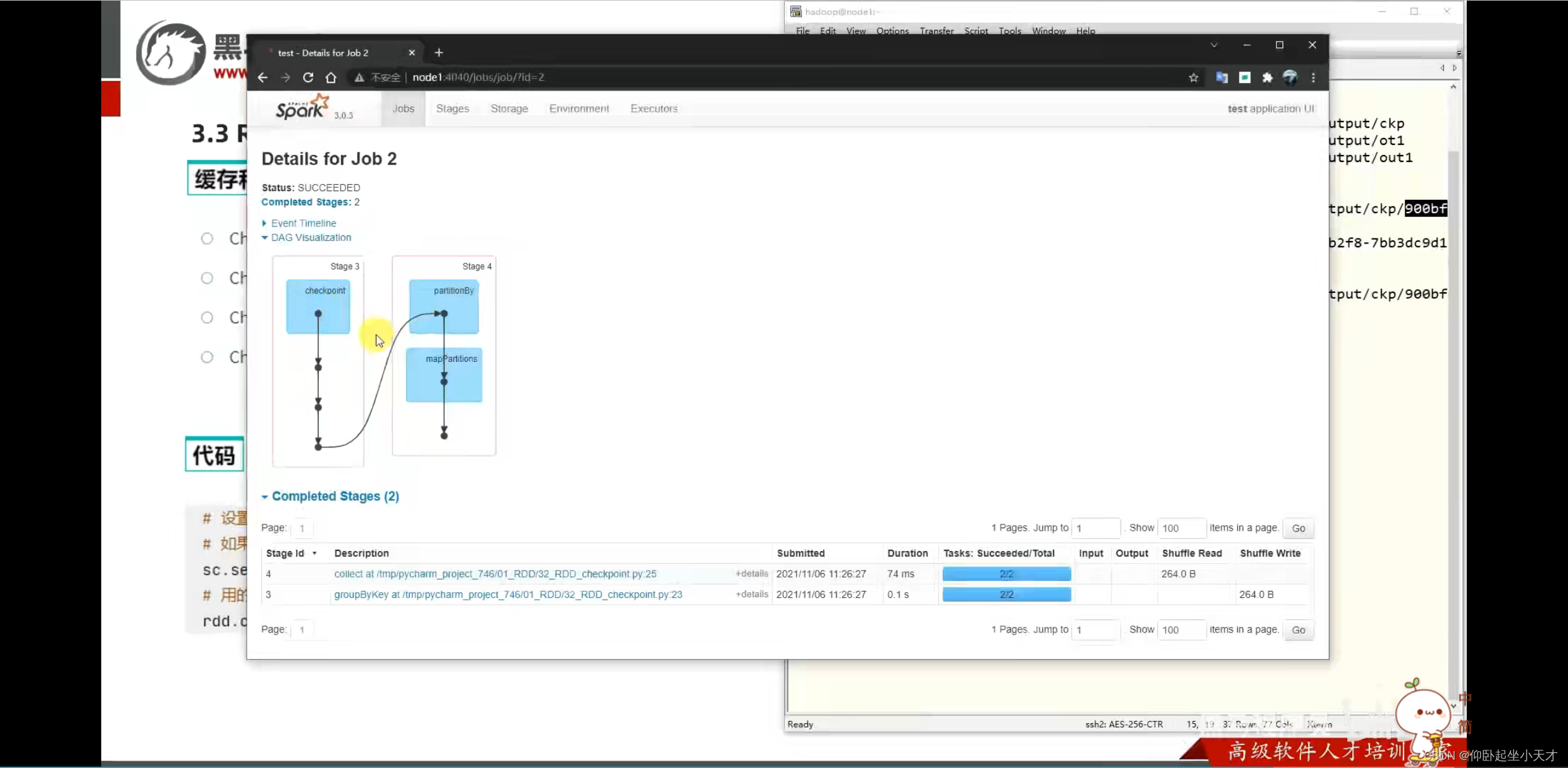
附:缓存更灵活但不安全,用于轻量数据,就算丢了也容易计算的;checkpoint更安全
下面的跳了前后两章
附:一个进程里的线程可以共享变量
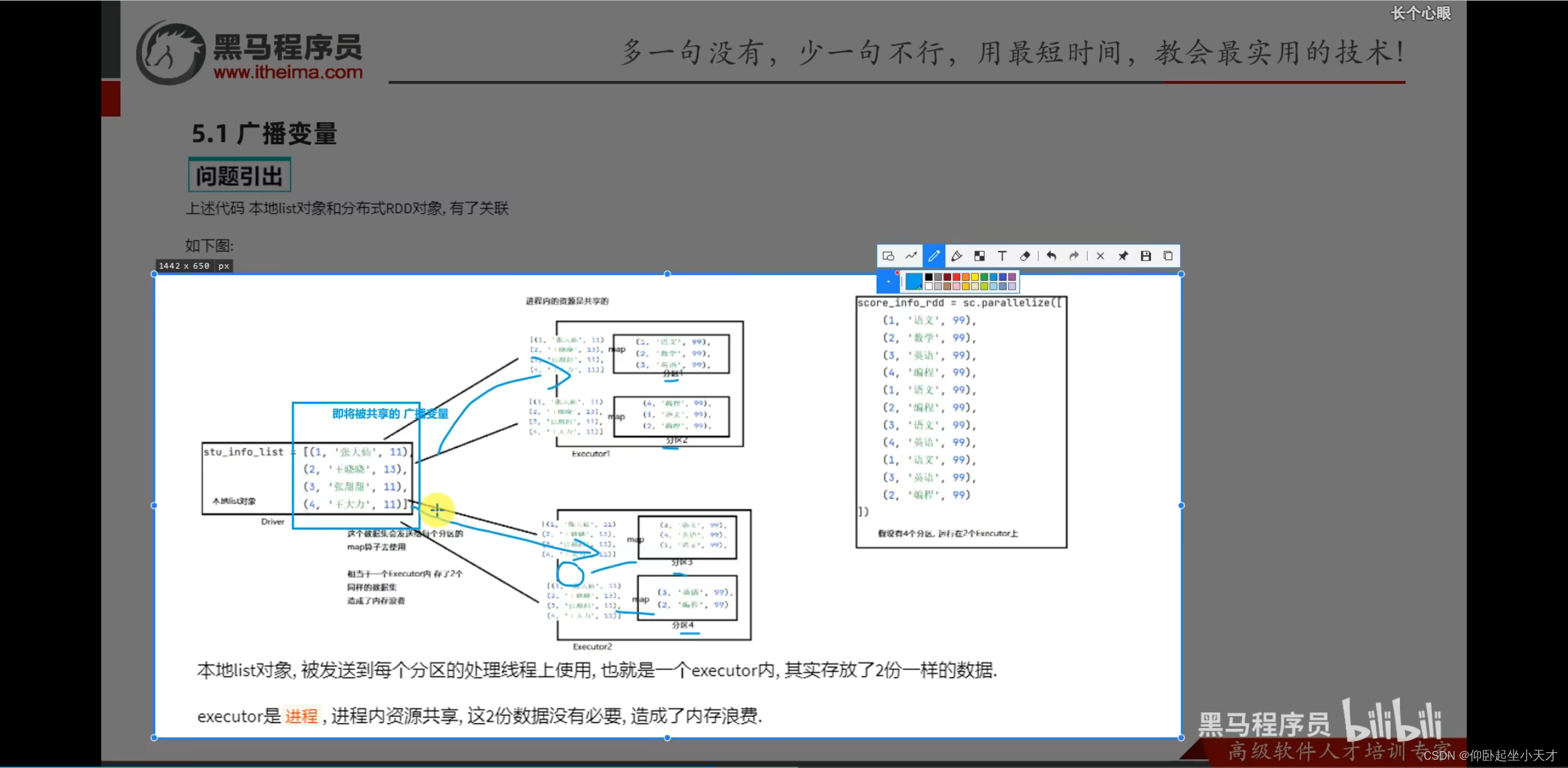
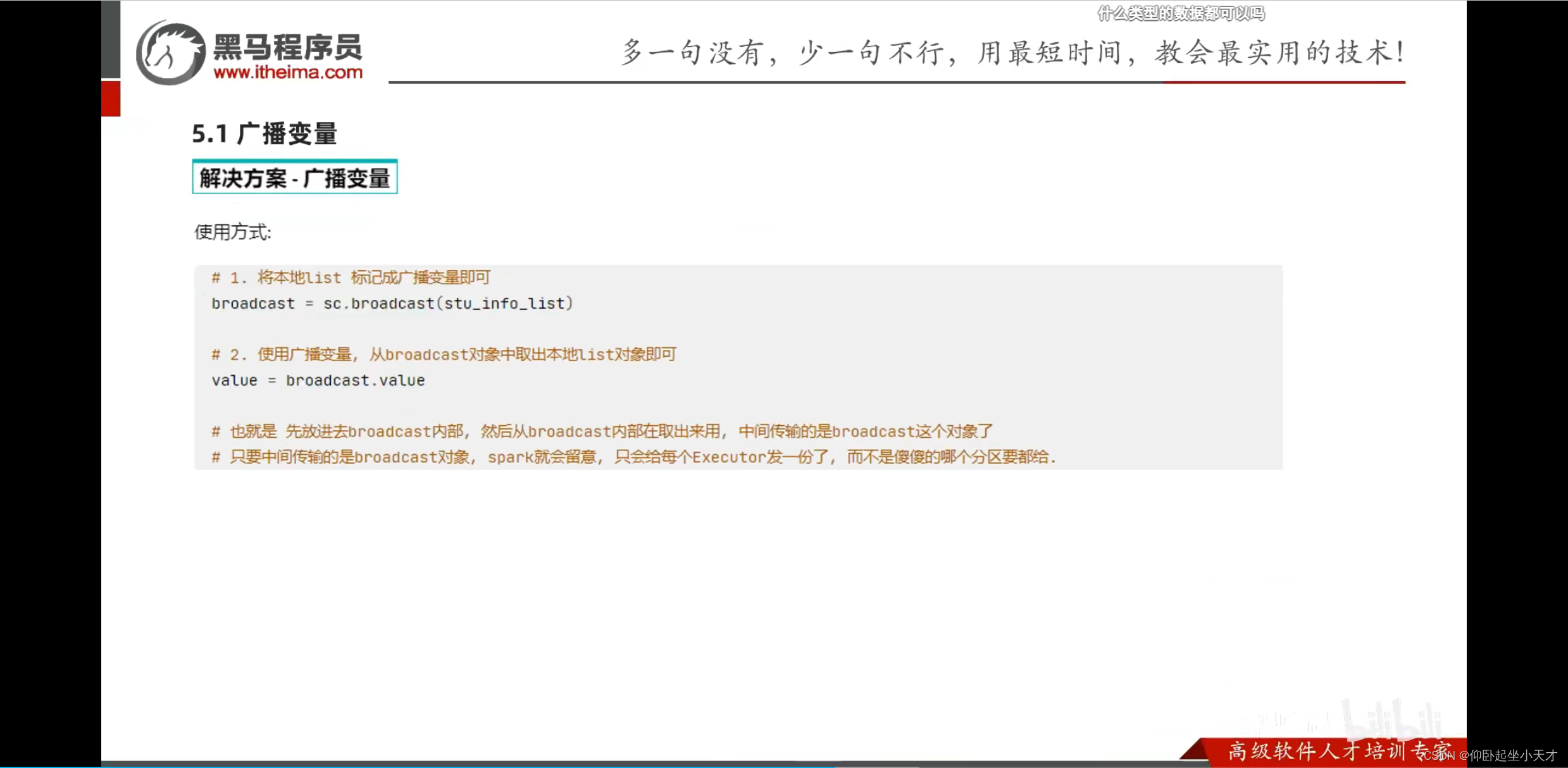
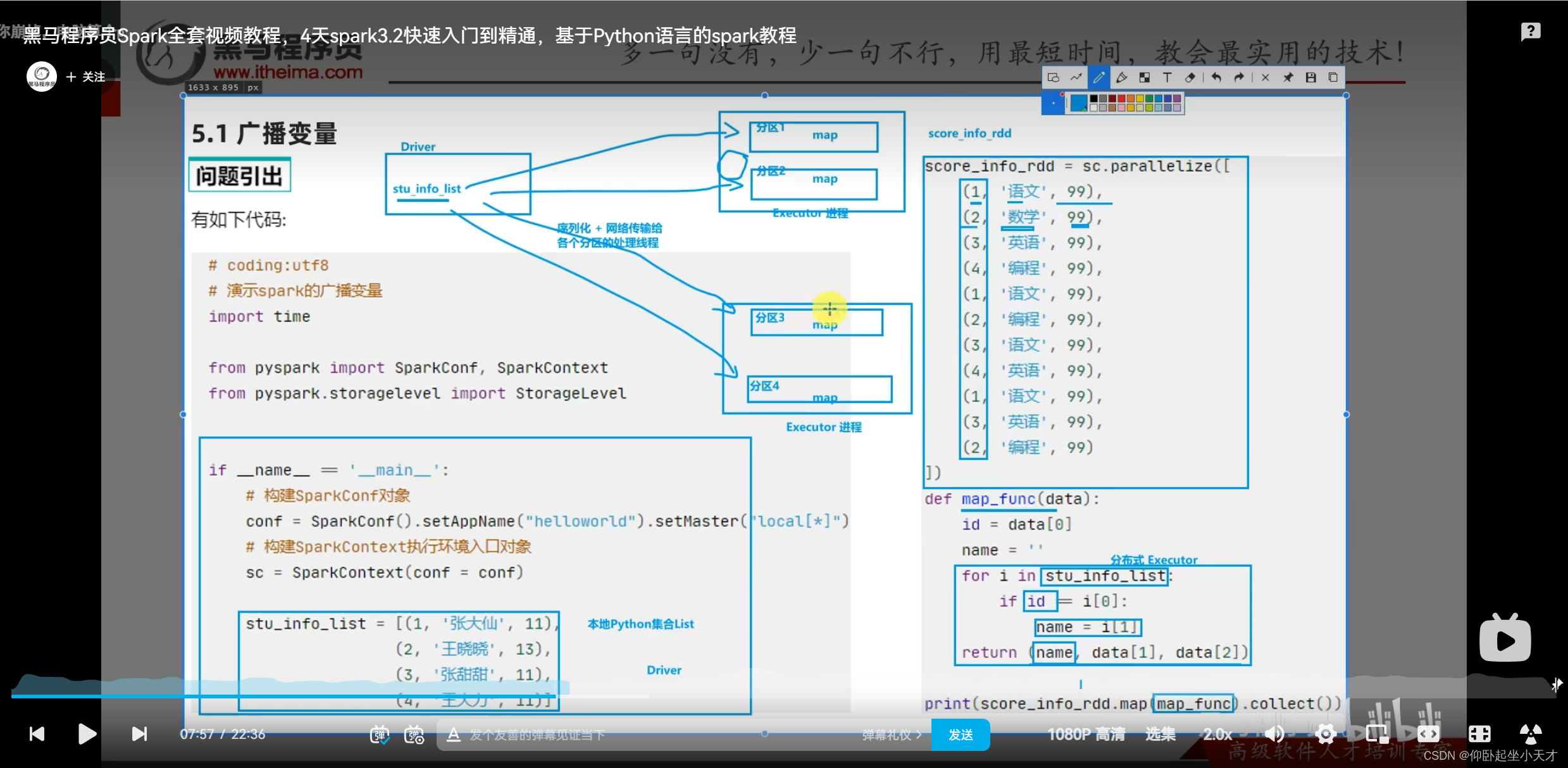
没有用广播变量:
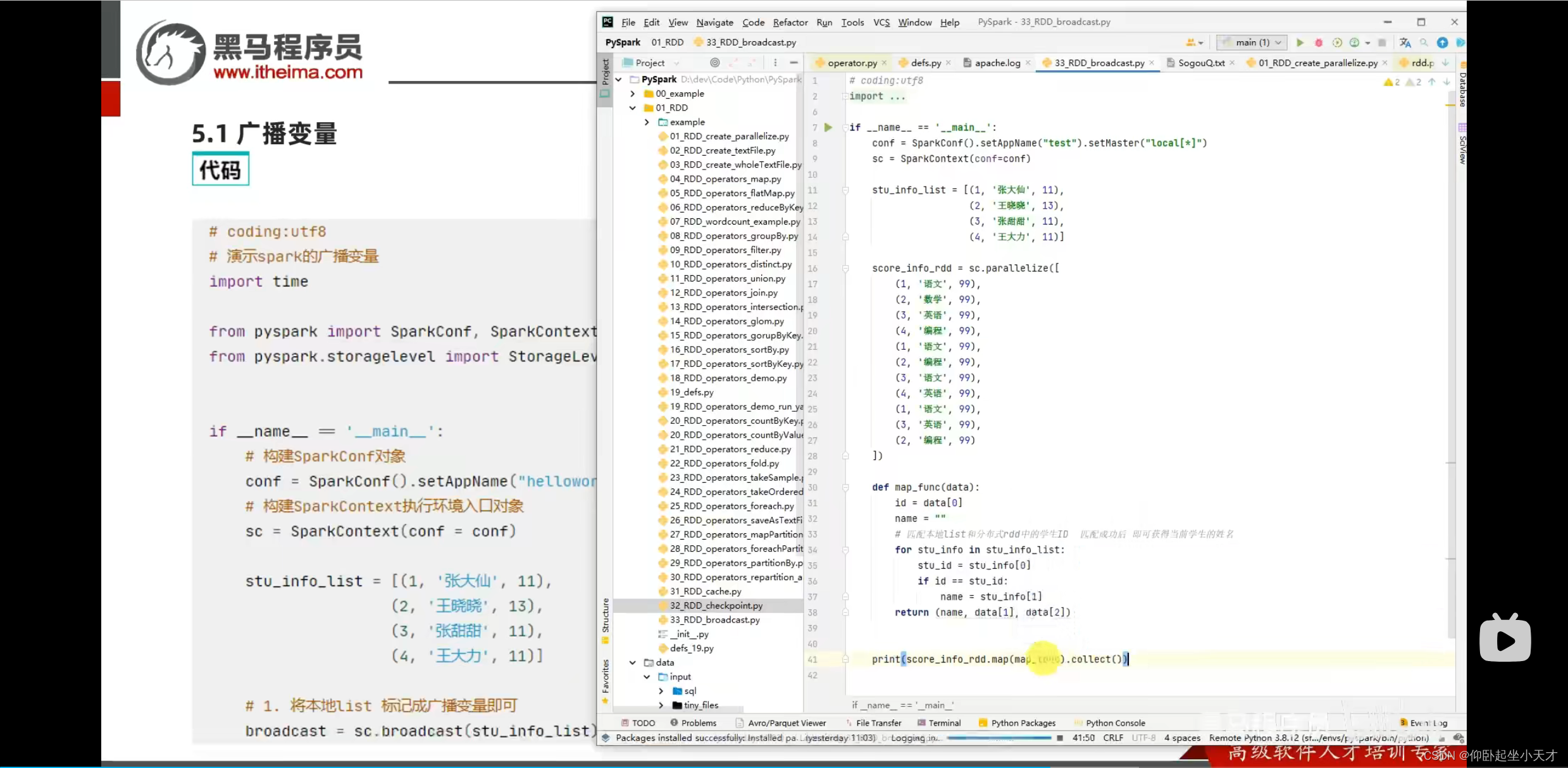
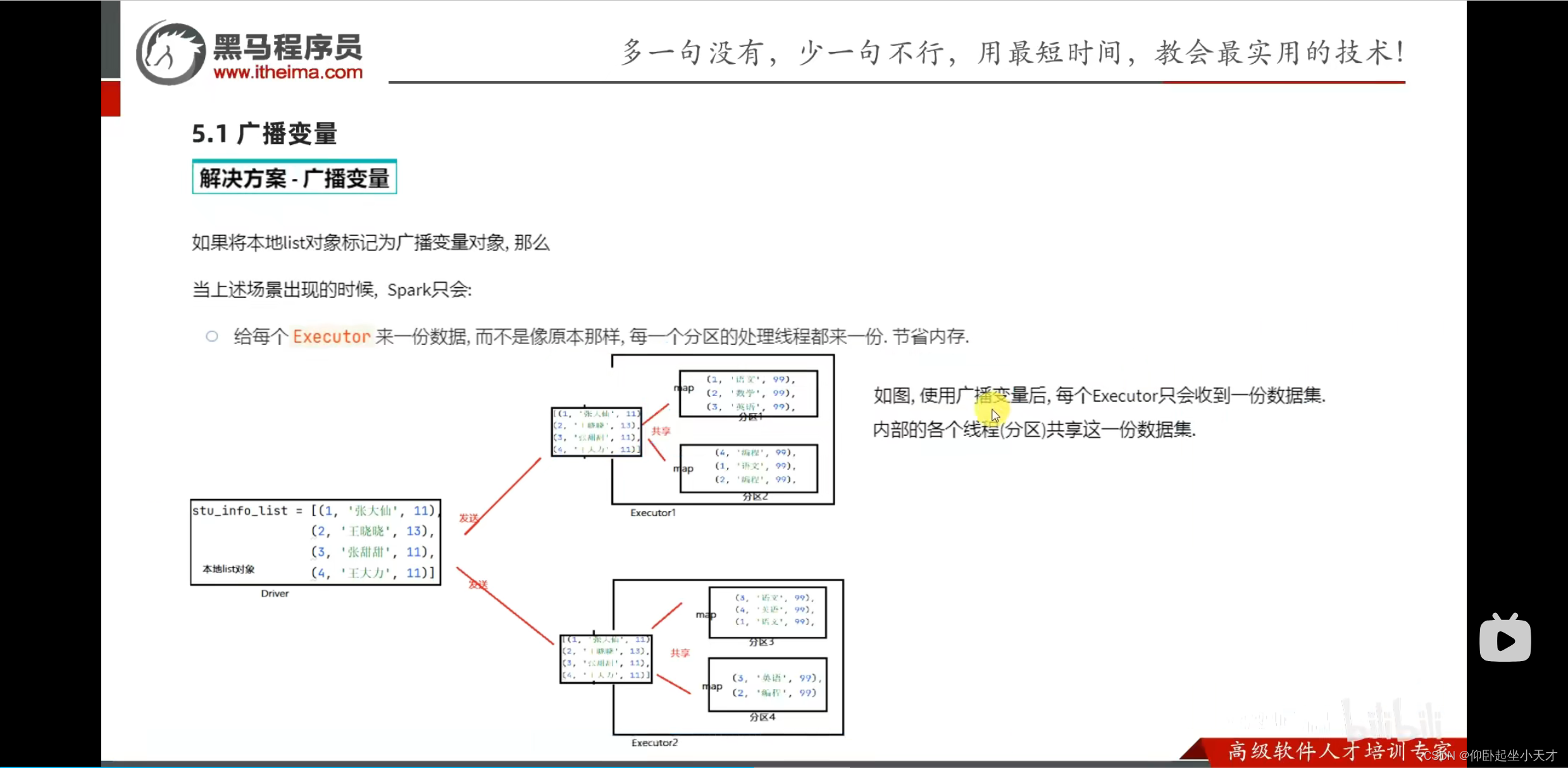
使用广播变量: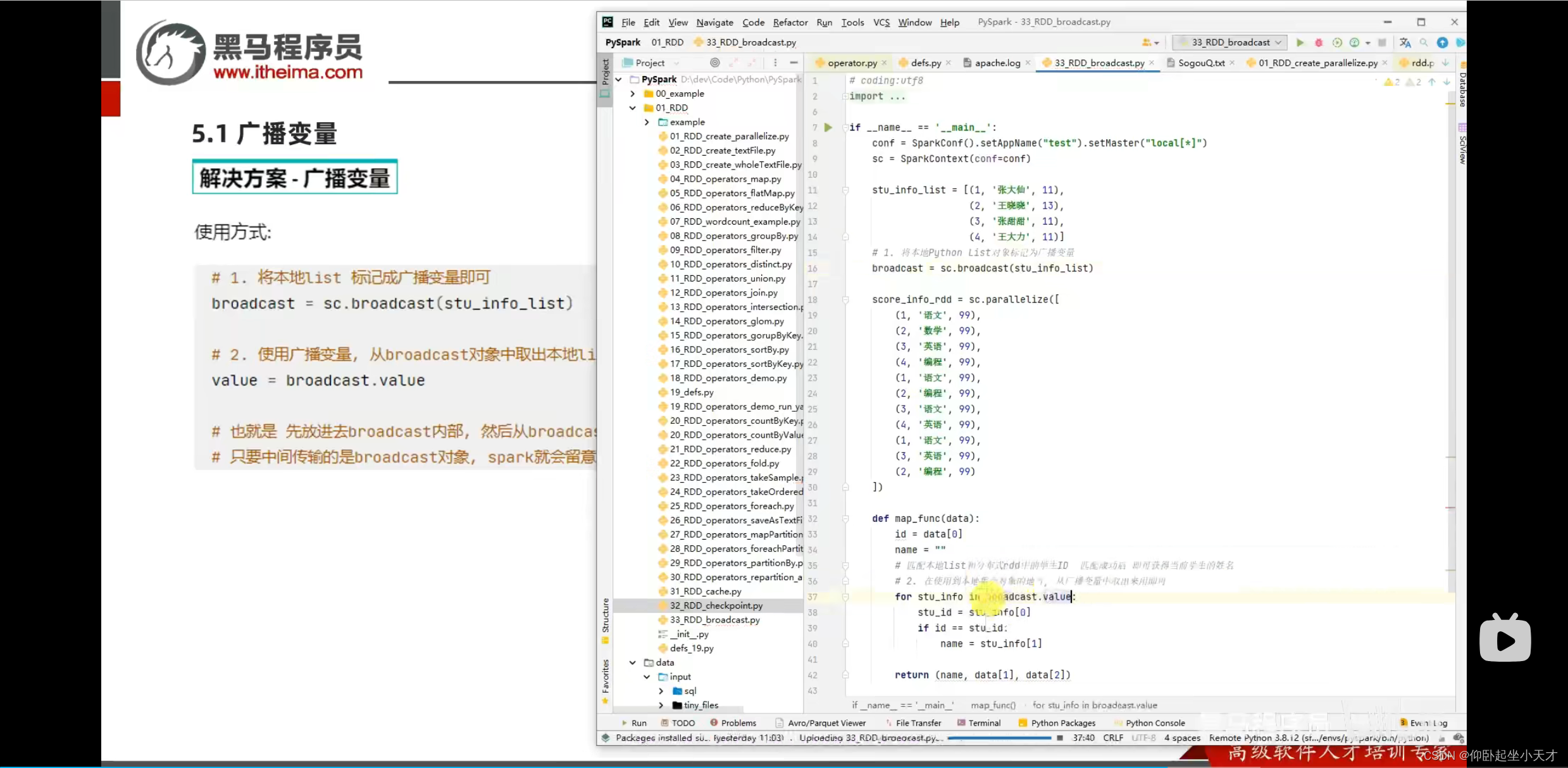

如果将本地的list变成rdd,可能反而会性能降低,因为有shuffle的问题
但是如果用本地直接发,就不会有和其他分区的shuffle:
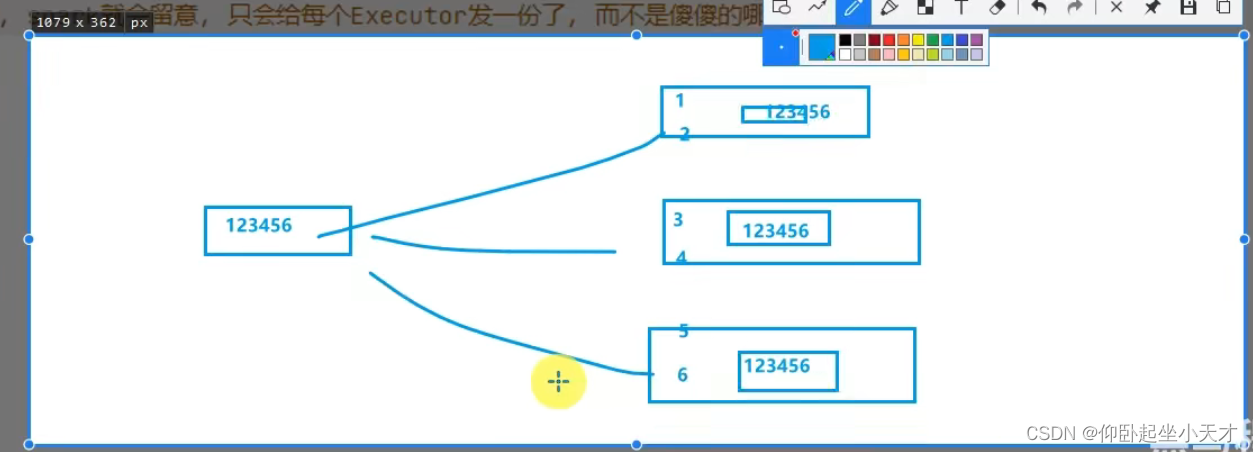
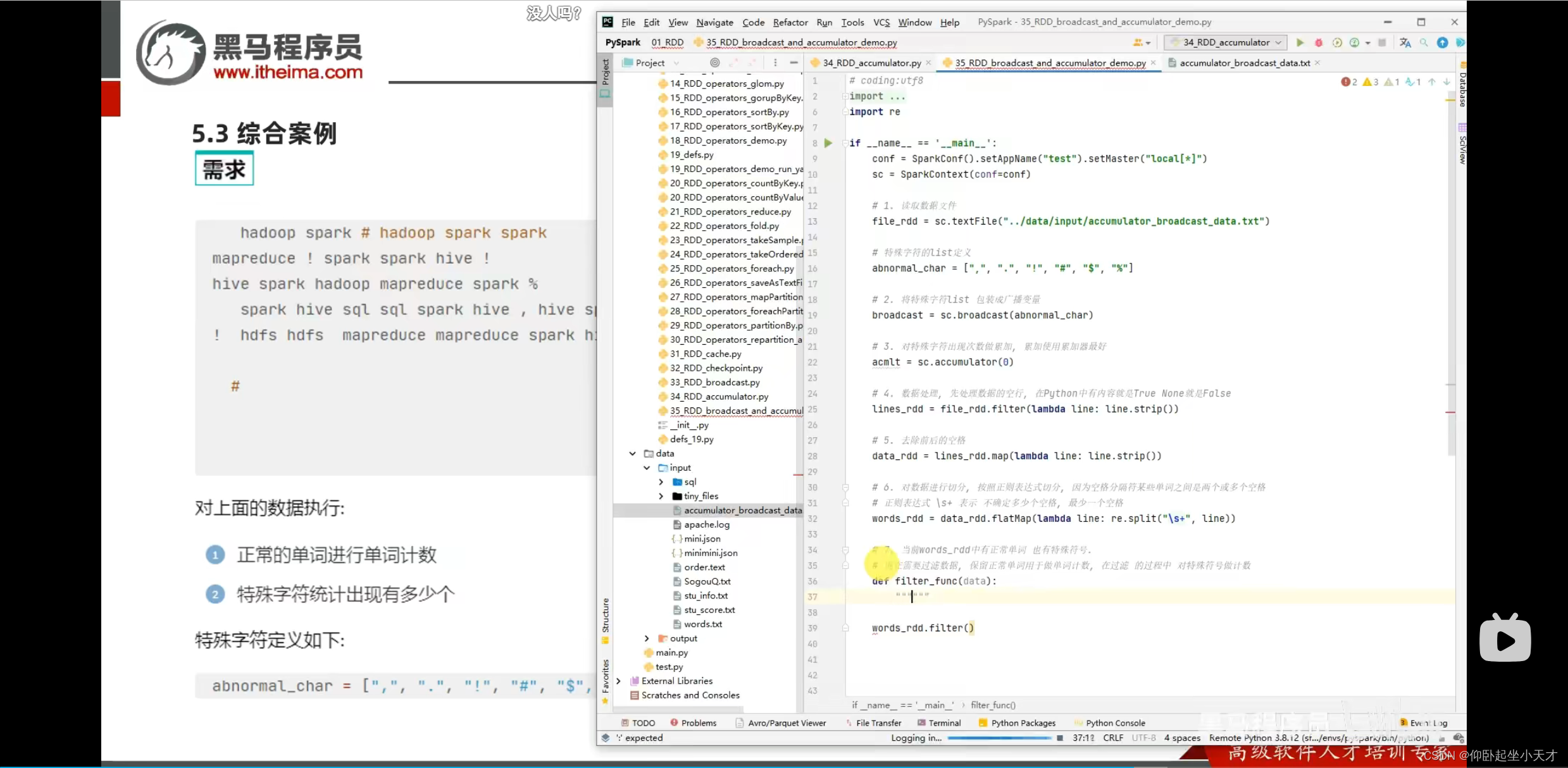
对比:数据大,用分布式,join
数据不太大,用广播变量

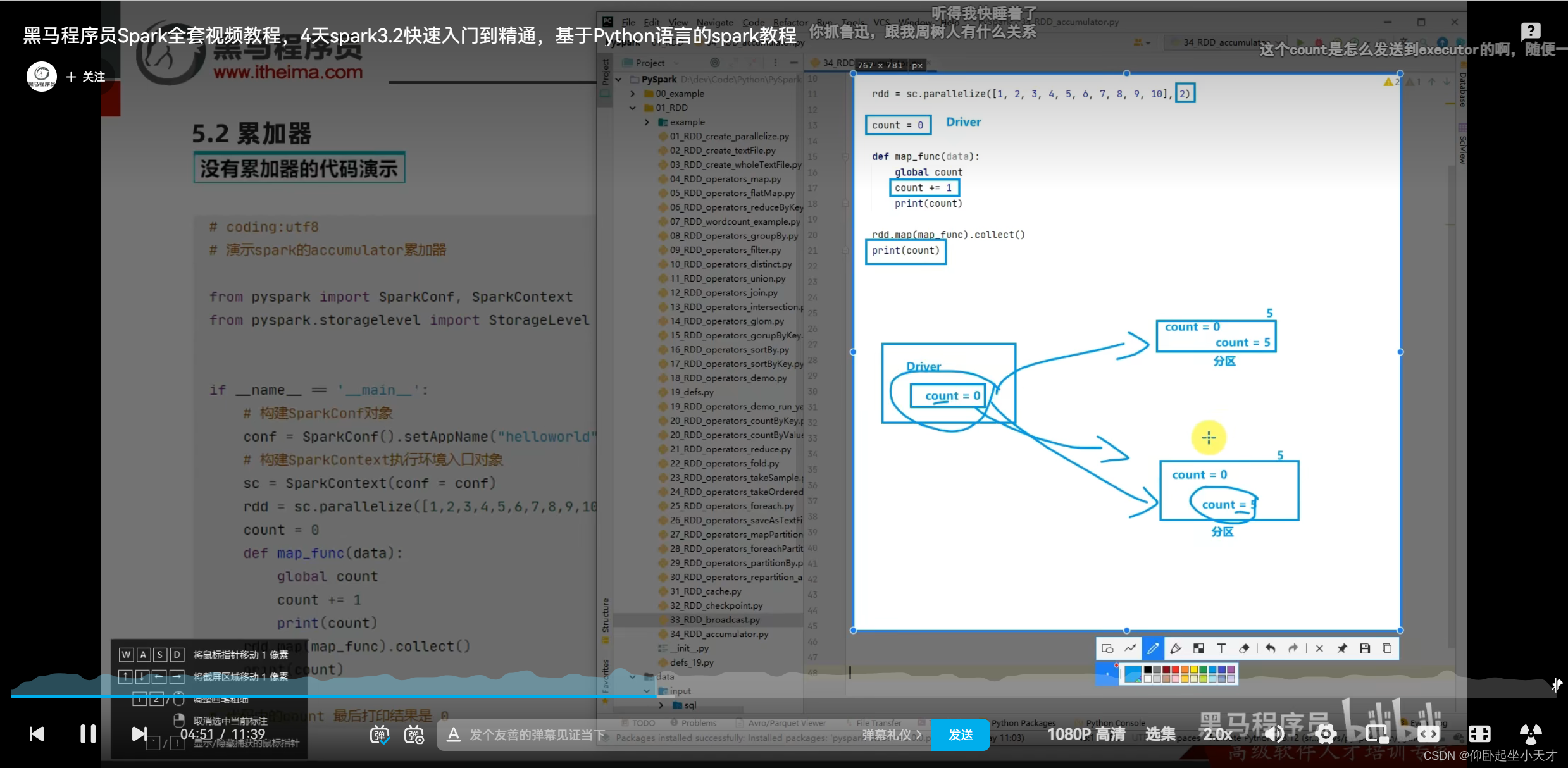
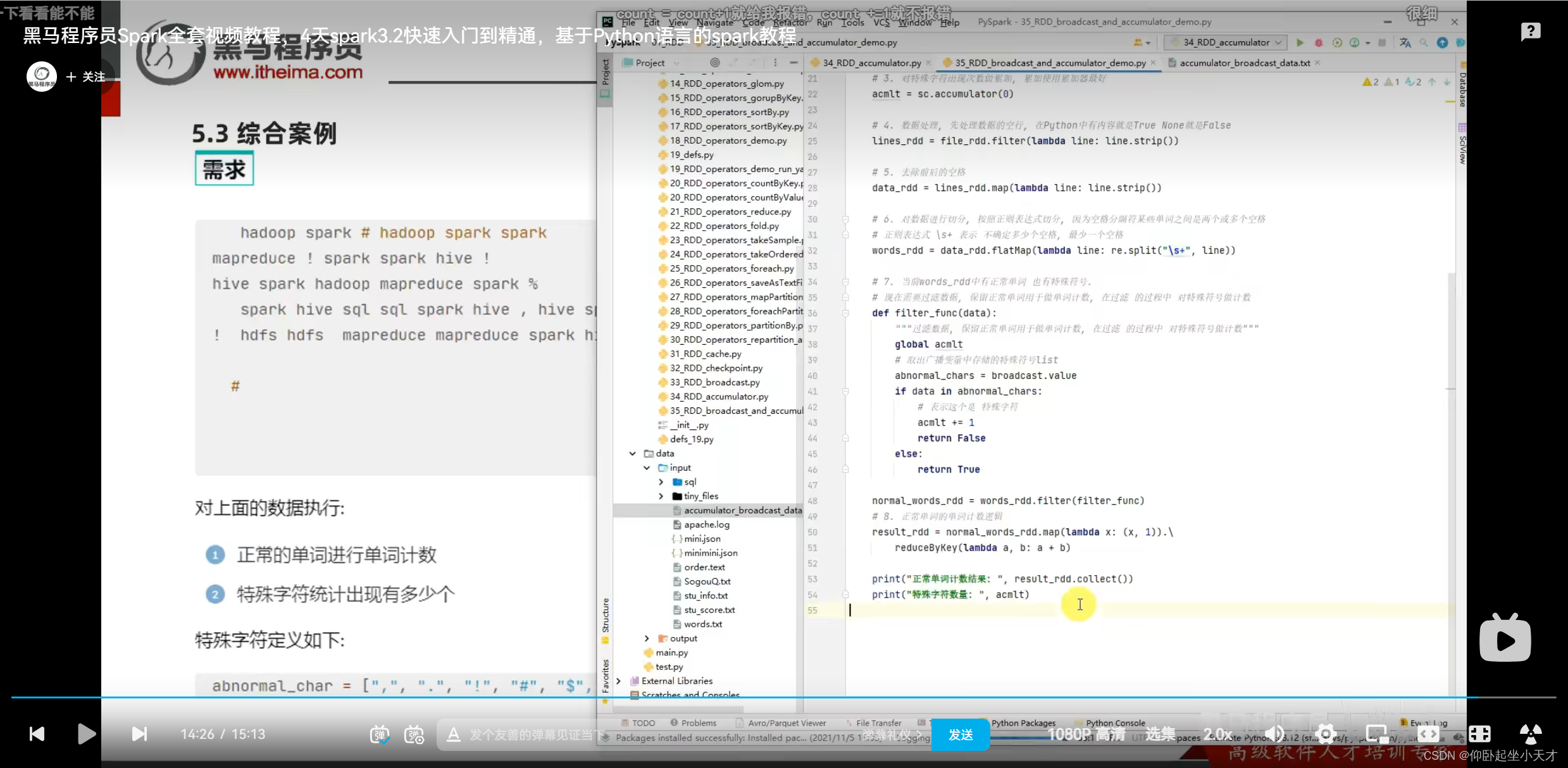
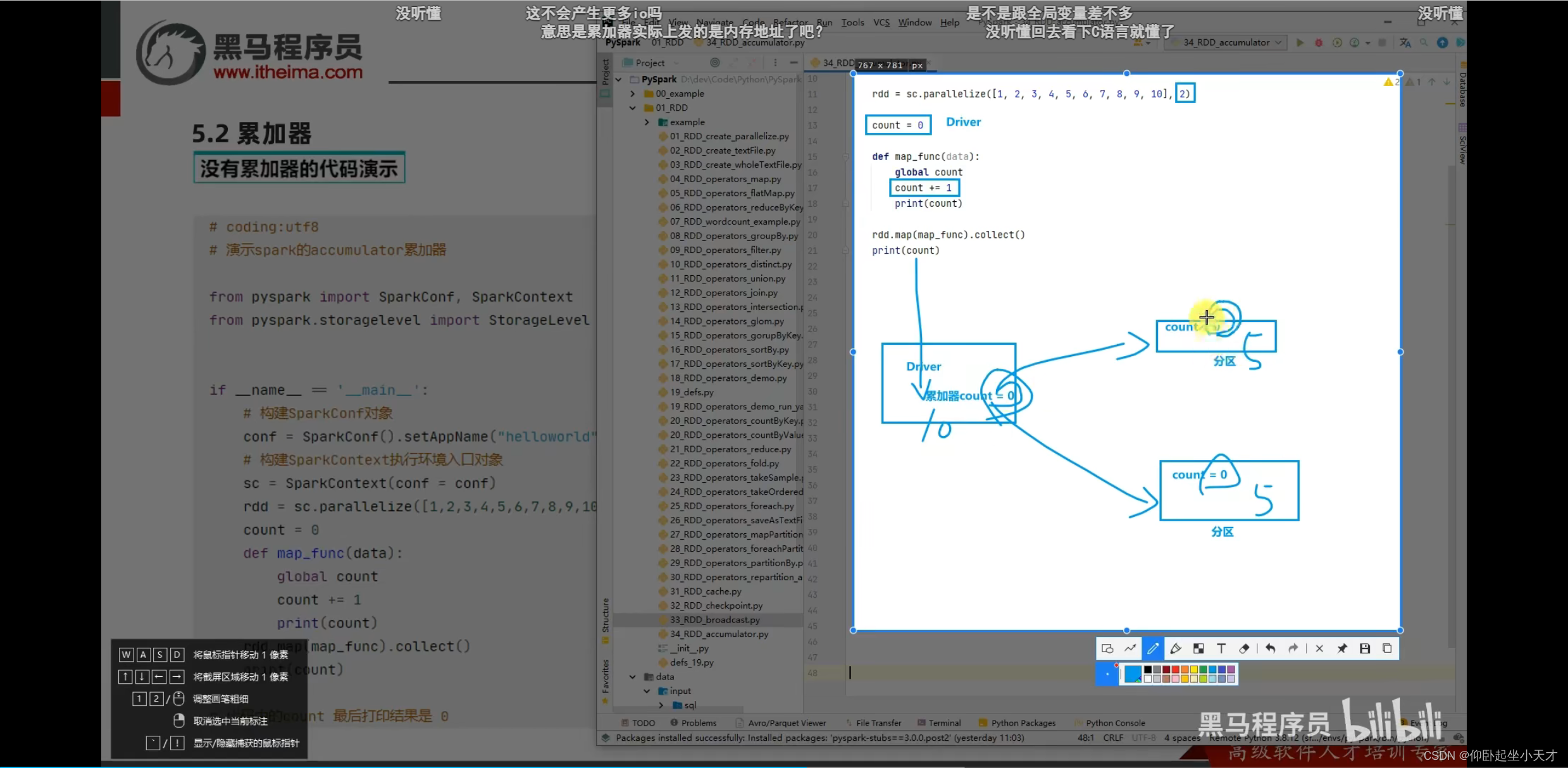 用spark提供的累加器,就能同步
用spark提供的累加器,就能同步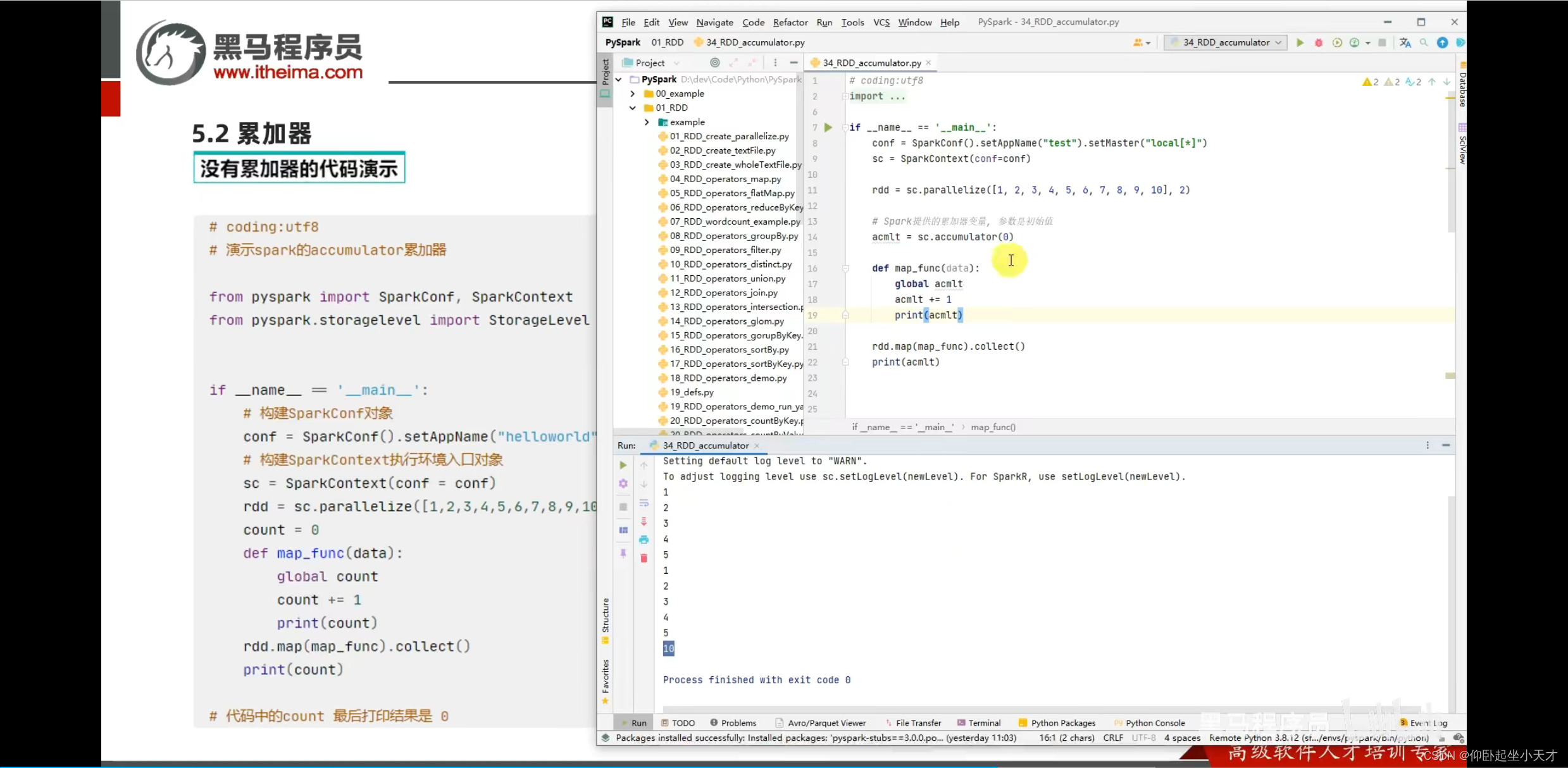

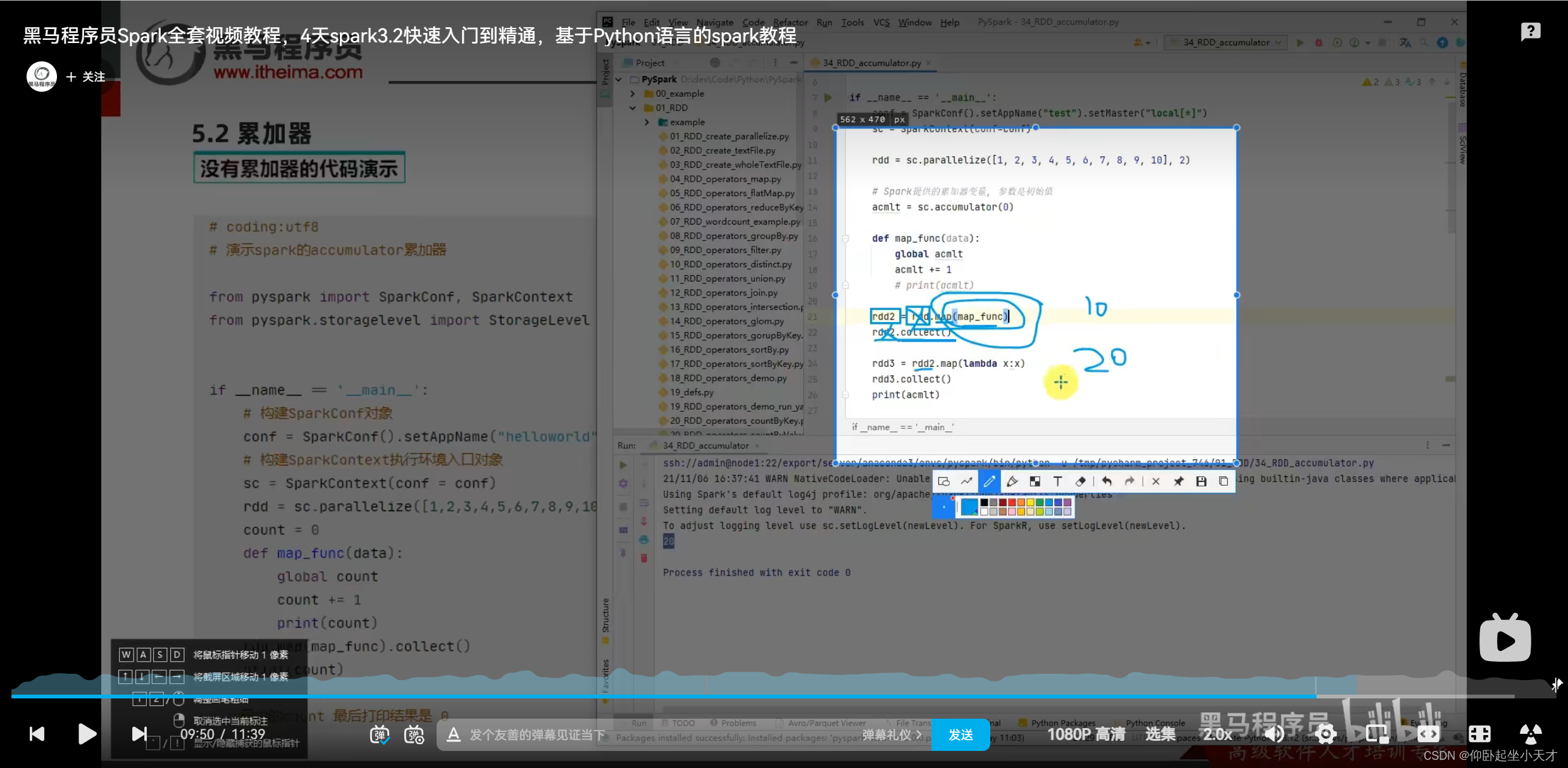
附:得到rdd2,此时acmlt=10。rdd2.collect()之后,rdd2就会被销毁。rdd3又调用了rdd2,但此时已经没有rdd2了,所以要从rdd1开始从头跑一遍,此时acmlt的初值变成了10。所以最后得到20.
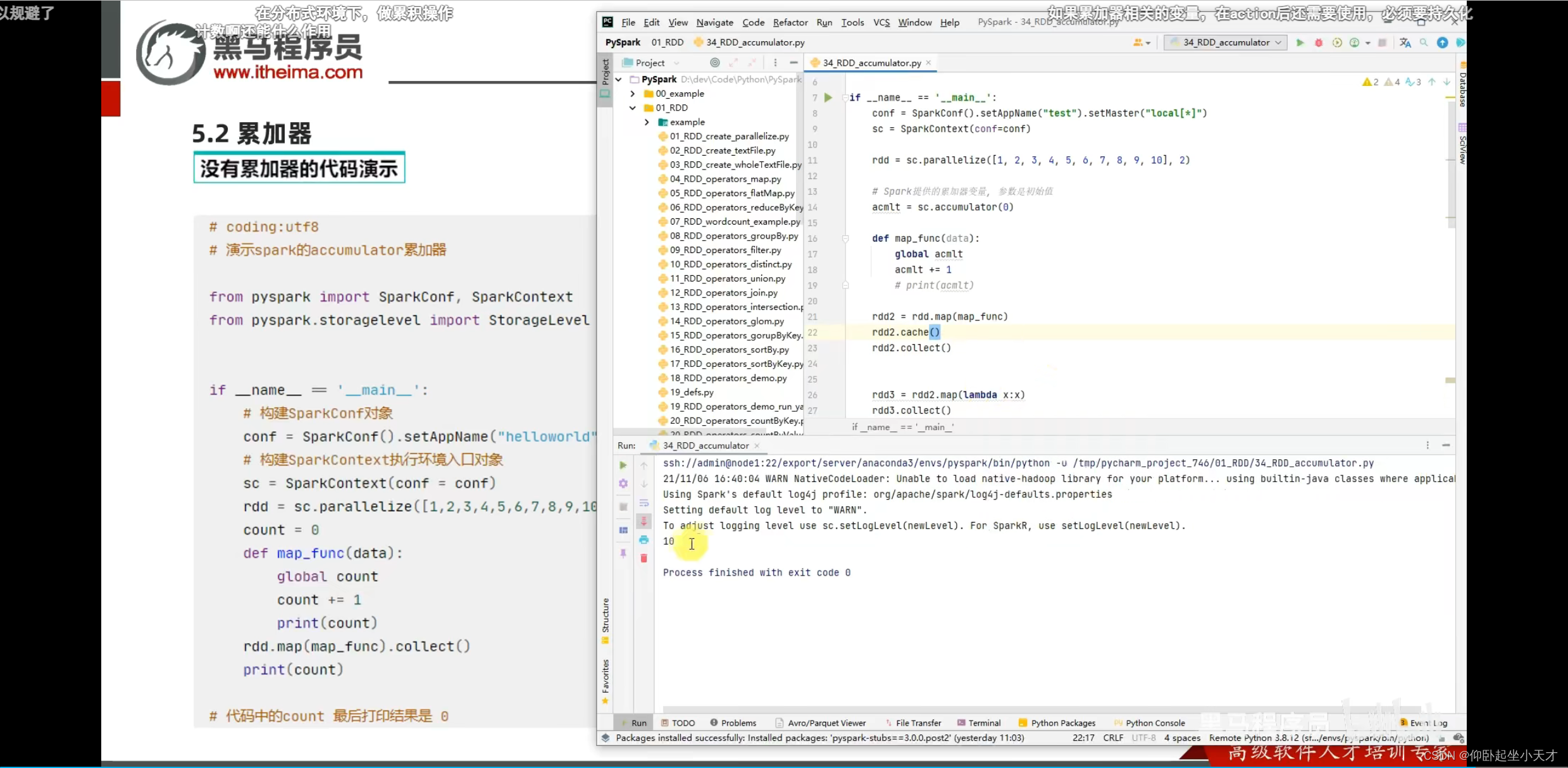
解决方法:用cache缓存
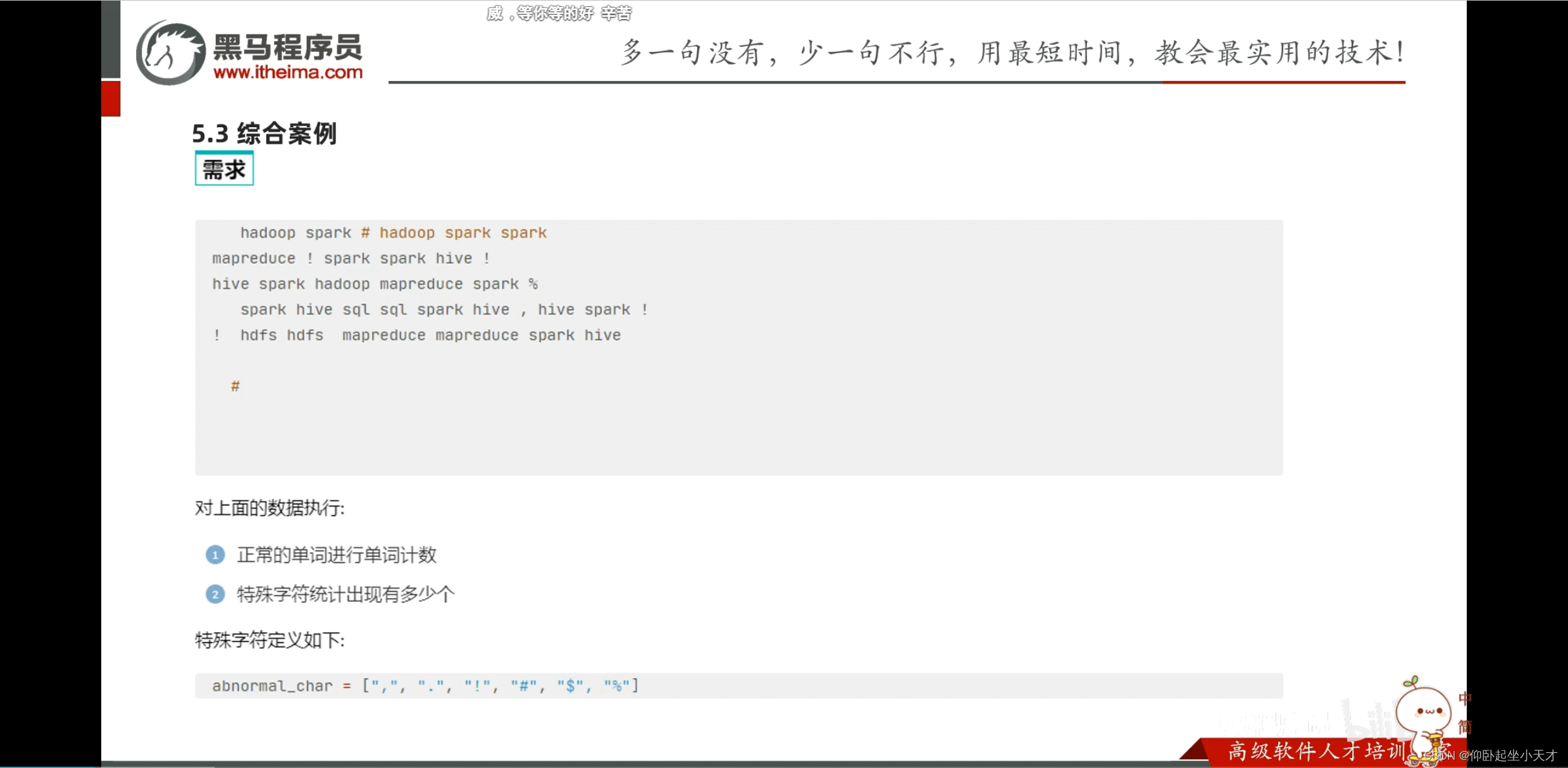
















 491
491











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









