







EarlyStopping(早停)作用:如果设置了一个很大的epochs的时候,在模型训练到一半epochs的时候,accuracy或者loss已经不再变化,模型甚至有出现过拟合迹象。EarlyStopping就可以提前终止训练。
参数:
keras.callbacks.EarlyStopping( monitor='val_loss', patience=0, verbose=0, mode='auto')
monitor:指可监测的值,如:accuracy,val_loss , val_accuracy
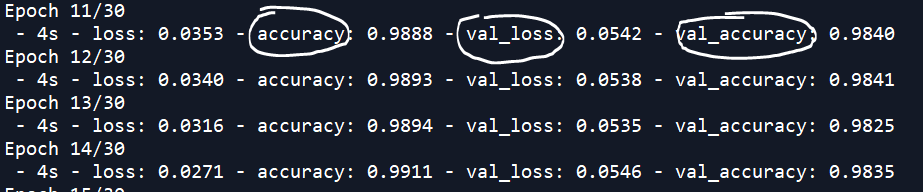
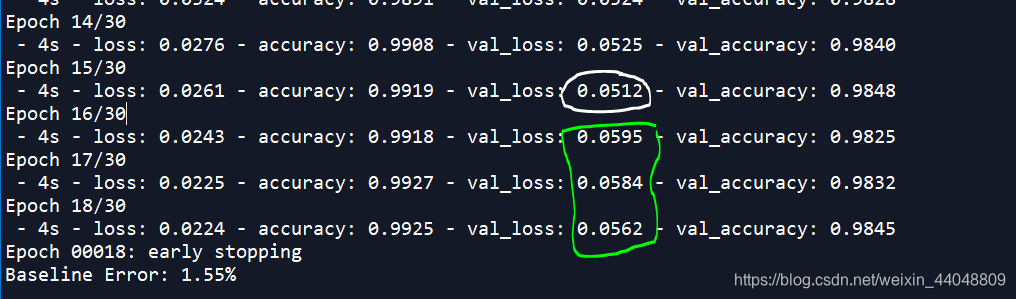
patience:中文意思忍耐,很形象。需要填写 int 值。是指能够允许后续训练的几个epoch比当前的大或者小。当monitor=‘val_loss’,patience=3。如下图,16,17,18 (共3个epoch就是指patience=3)比15的val_loss要大。就触发早停,停止训练。
verbose:信息展示模式
mode:‘auto’,‘min’,‘m
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6594
6594

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









