







概述
YOLO11是YOLO系列实时目标检测器的最新迭代版本,在之前YOLO版本取得的显著进步基础上,YOLO11在架构和训练方法上进行了重大改进,使其成为各种计算机视觉任务中的通用选择。除了传统的目标检测外,YOLO11 还支持目标跟踪、实例分割、姿态估计、OBB定向物体检测(旋转目标检测)等视觉任务。
OBB定向物体检测在标准物体检测基础上,引入了一个额外的角度来更准确地定位图像中的物体,能够更准确的预测物体的形状、运动方向等特征。
预训练模型数据集DOTA
Ultralytics官方提供标准的预训练模型,该模型是基于DOTAv1数据集训练的。
DOTA数据集是用于航拍图像中的目标检测的大型图像数据集,它可用于发现和评估航拍图像中的物体。
DOTA数据集是武汉大学于 2017 年 11 月 28 日在 arXiv 上发布的论文《DOTA: A Large-scale Dataset for Object Detection in Aerial Images》中提出的,于 2018 年 6 月在 IEEE 计算机视觉 和模式识别会议(CVPR)上发布(论文地址:https://arxiv.org/pdf/1711.10398.pdf)。
DOTA 数据集是用于航拍图像中目标检测的图像数据集,被用于发现和评估航拍图像中的物体。这些图像来源包含不同传感器和平台,包括 Google Earth、JL–1 卫星拍摄,以及中国资源卫星数据和应用中心的 GF–2 卫星拍摄。
数据集共计 2806 幅航拍图,每张图像的像素尺寸在 800x800 到 4000x4000 的范围内,其中包含不同尺度、方向和形状的15类物体,包括:飞机,轮船,储罐,棒球场,网球场,篮球场,地面跑道,港口,桥梁,大型车辆,小型车辆,直升机,环形交叉路口,足球场和篮球场。完全注释的 DOTA 图像包含 188282 个实例,每个实例均由任意四边形进行标记。
DOTA-v1.5 使用与 DOTA-v1.0 相同的图像,但对极小的实例(小于 10 像素)也进行了标注。此外,还增加了一个新类别“集装箱起重机”。它总共包含 403,318 个实例。图像数量和数据集拆分与 DOTA-v1.0 相同。

停车场训练数据集准备
之前使用标准检测对停车场检测进行了一些模型训练和测试工作。由于停车场的形态各异,从各个角度看停车状况均不相同,要检测停车位的停车情况,标准检测对不同角度的停车的检测结果尚有欠缺。
本次的数据集选取了如下图所示的场景,相对规则排布的停车场,这种场景的预测难度更大。

标注(Annotation)
选取合适的图片后,需要对图片进行标注(Annotation)。在停车检测任务中,只需要考虑两个class:车辆和空位,使用标注工具软件(例如labelme、anylabeling)进行任意画框标注,各软件有其特定的标注格式,可以编写python代码对其转换成YOLO TXT文件。
YOLO OBB TXT文件的标注格式为:
<class-index> x1 y1 x2 y2 x3 y3 x4 y4
这里我们定义:0 car, 1 free
以下是上面图片的标注:
1 0.562500 0.762500 0.628906 0.923611 0.558594 0.969444 0.503125 0.808333
0 0.600781 0.626389 0.663281 0.741667 0.616406 0.813889 0.547656 0.679167
1 0.629687 0.554167 0.686719 0.647222 0.642969 0.693056 0.583594 0.590278
0 0.647656 0.448611 0.703125 0.531944 0.673438 0.597222 0.602344 0.494444
1 0.664062 0.391667 0.717187 0.447222 0.696094 0.511111 0.632812 0.431944
0 0.674219 0.320833 0.732812 0.376389 0.710156 0.429167 0.650000 0.363889
1 0.690625 0.269444 0.746875 0.320833 0.725000 0.368056 0.664844 0.306944
1 0.706250 0.230556 0.764062 0.277778 0.742969 0.313889 0.682813 0.262500
0 0.718750 0.190278 0.767188 0.225000 0.757812 0.262500 0.700781 0.220833
0 0.482812 0.781944 0.506250 0.875000 0.378906 0.951389 0.367188 0.837500
0 0.606250 0.390278 0.622656 0.440278 0.545312 0.483333 0.529687 0.430556
1 0.631250 0.336111 0.646094 0.379167 0.566406 0.415278 0.555469 0.363889
0 0.651563 0.275000 0.666406 0.323611 0.586719 0.352778 0.575000 0.297222
0 0.662500 0.233333 0.678125 0.279167 0.602344 0.295833 0.593750 0.258333
0 0.684375 0.197222 0.691406 0.241667 0.629687 0.248611 0.623437 0.208333
1 0.314844 0.347222 0.342187 0.416667 0.301563 0.454167 0.282031 0.370833
0 0.356250 0.295833 0.379688 0.363889 0.342187 0.388889 0.318750 0.320833
0 0.391406 0.248611 0.417187 0.306944 0.384375 0.341667 0.357812 0.279167
0 0.418750 0.208333 0.444531 0.258333 0.413281 0.283333 0.386719 0.237500
1 0.445312 0.166667 0.473438 0.212500 0.442188 0.244444 0.414062 0.201389
0 0.468750 0.137500 0.496094 0.181944 0.469531 0.208333 0.439844 0.166667
0 0.189062 0.381944 0.212500 0.484722 0.159375 0.505556 0.147656 0.412500
0 0.239063 0.334722 0.260937 0.412500 0.217188 0.436111 0.196875 0.352778
0 0.285156 0.281944 0.305469 0.356944 0.264844 0.377778 0.246875 0.315278
1 0.318750 0.236111 0.339844 0.304167 0.301563 0.316667 0.285938 0.255556
0 0.350781 0.194444 0.375000 0.261111 0.343750 0.279167 0.320312 0.219444
1 0.376563 0.163889 0.407813 0.216667 0.374219 0.243056 0.351562 0.184722
0 0.412500 0.136111 0.432812 0.179167 0.410156 0.205556 0.383594 0.152778
数据集目录结构
path
└-- datasets
|-- train
| |-- images
| └-- labels
└-- val
|-- images
└-- labels
图片和labels
本次训练使用了284副图片用于训练集,57副图片用于验证集。图片分辨率为1280*720。
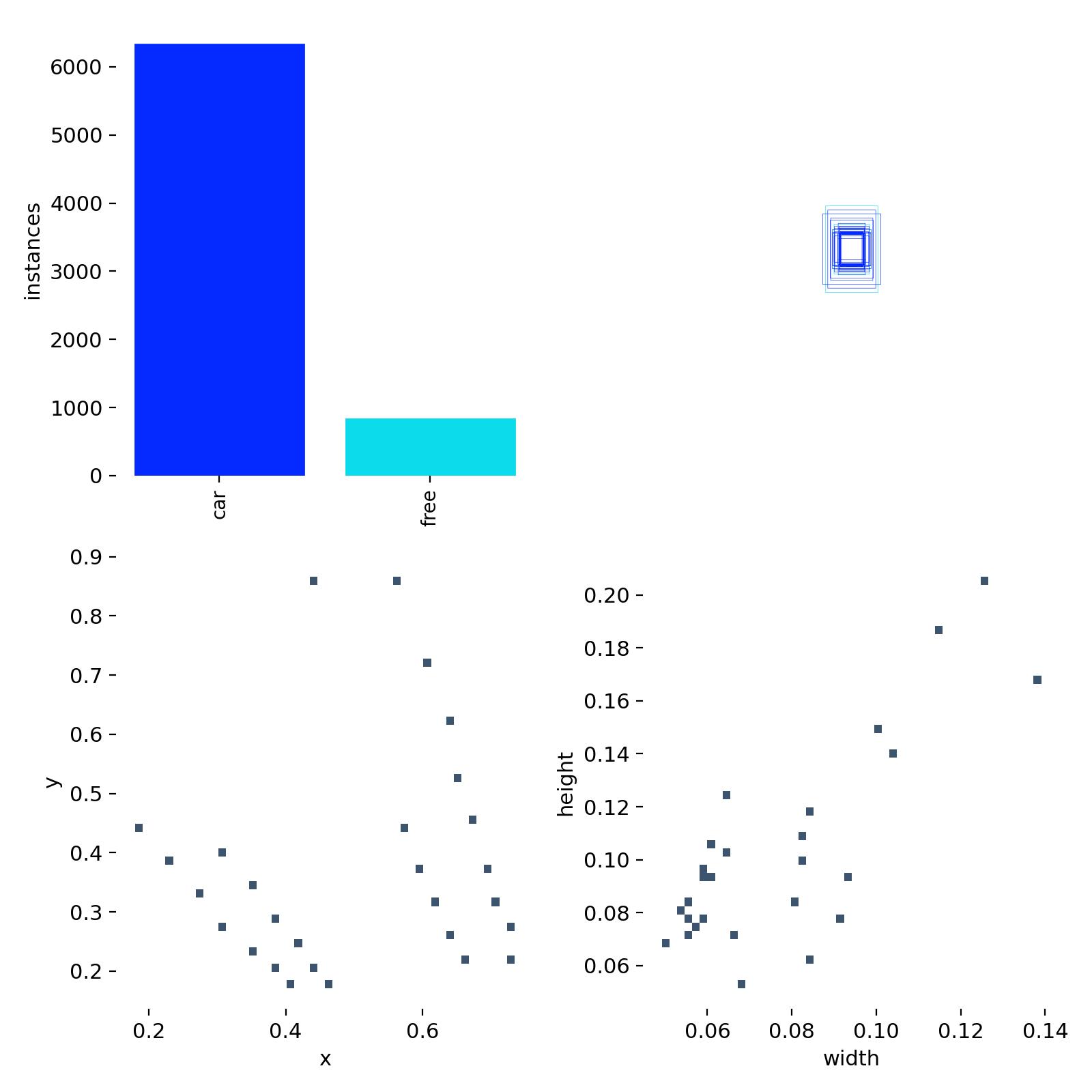
通过Labels分布图可以看到,在所有实例中,占用车位比空闲车位多。标注的车位集中在两个区域(左下图),车位大小(右下图)绝大部分是比较小的尺寸。
训练代码和参数
本次训练基本使用缺省参数,训练了100轮,imgsz设置为640。
训练模型使用yolo11n-obb.yaml
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import datetime
from ultralytics import YOLO
def yolo11obb_detect_train():
model = YOLO('yolo11n-obb.yaml')
model.info()
# data.yaml在当前目录,数据集在./datasets
data='yoloobb-park/data.yaml'
project= 'runs'
start_time = datetime.datetime.now()
print(f"开始训练 {start_time.strftime('%Y-%m-%d %H:%M:%S')}")
#imgsz 设置为640,兼顾训练速度和精度
model.train(data=data,
epochs=100,
imgsz=640,
batch=4,
workers=4,
half= True,
project=project)
end_time = datetime.datetime.now()
print(f"训练结束 {end_time.strftime('%Y-%m-%d %H:%M:%S')}")
if __name__ == '__main__':
'''
Park lot detection, only concerns car(occupied) and free spot
modify the data.yaml
modify nc: 2 in the yolo11.yaml file
copy training datasets to the datasets folder
'''
yolo11obb_detect_train()
这个batch是指一次训练多少张图片,训练结束后在runs文件下的图片会看到组合图片。
Batch参数的大小,需要根据你的计算机的配置确定,如果你用CPU进行训练,需要根据RAM大小确定。如果你用GPU训练,需要根据显卡显存确定。YOLO缺省的参数是16。当然,也可以设置成“-1”,让系统自动确定(但不一定是最好的选择)。batch大,显存/内存占用多,如果显存/内存不足,训练可能会失败或变得非常缓慢。如果batch设置的太小,那么利用率可能太低,会造成资源闲置。一般可以从一个较小的batch开始,如4、8或16,然后逐步增加,查看显存/内存占用到80%左右,就是比较合适的。
训练结果
损失函数曲线和精度曲线,如下图所示。
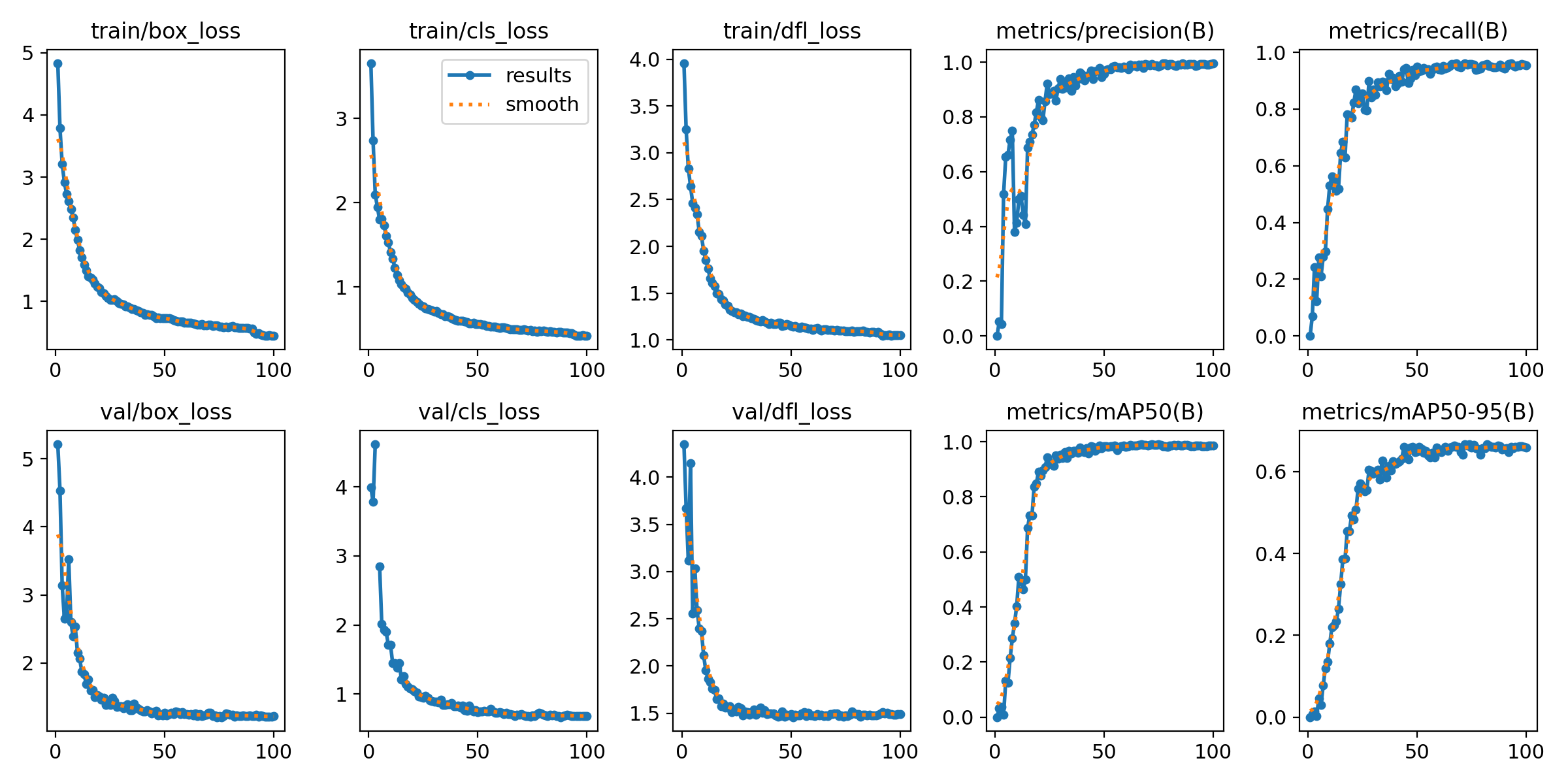
左边6幅图,上面的是训练过程中的损失函数曲线,下面是验证过程的损失函数曲线。在训练到100轮次的时候,都降到了比较低的水平,整个过程均呈下降趋势。
右上角2副图是bounding box的精度和召回率曲线。右下2副图是平均精度曲线(mAP,可以简单理解为预测框和真实框的重合度),mAP50是重合度50%的平均精度,mAP50-95则是重合度从50%到95%范围内的平均值,mAP50-95的值比mAP50低。
训练过程中的标注图和预测图



使用真实停车场图片测试
模型训练出来, 表现怎么样,除了上述的指标分析,还需要找实际的场景运行看看。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import os
import shutil
from ultralytics import YOLO
from functions import process_images
def yolo11_detect_predict(repo_path, model, conf, iou):
modelname = os.path.basename(model)
# Remove folder if it exists
if os.path.exists(os.path.join(repo_path, f'results/{modelname[:-3]}/')):
shutil.rmtree(os.path.join(repo_path, f'results/{modelname[:-3]}/'))
dest_path=modelname[:-3]
model = YOLO(model)
source=os.path.join(repo_path, 'data/images')
project=os.path.join(repo_path, 'results/')
name=dest_path+"/yoloobb_images"
print(f"开始预测 {name}")
result = model.predict(source=source,
save_txt=True,
save=True,
exist_ok=True,
imgsz=640,
conf=conf,
iou=iou,
project=project,
name=name)
print("运行预测完成")
if __name__ == '__main__':
repo_path = os.getcwd()
model = "./models/last.pt"
# Execute the yolo11 predict
yolo11_detect_predict(repo_path, model, conf=0.4, iou=0.45)
以下是一些检测结果图片,可以看出,模型对这种不规则排布的停车场,具有较好的准确度。车辆的检测结果较好,置信度一般也比较高,大部分在0.8以上。


在光线合适的情况下,对这种空车位的检测准确度也比较好。



















 2450
2450

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









