







Grounding of Textual Phrases in Images by Reconstruction
(看看 image grounding 论文,给 moment 任务找找灵感)
注:ECCV 2016, paper arXiv 传送门
motivation:
-
Many prior efforts in this area have focused on rather constrained settings with a small number of nouns to ground . On the contrary, we want to tackle the problem of grounding arbitrary natural language phrases in images. (之前工作主要针对少量名词做image grounding → \to → 本文针对任意自然语言 phrase)
-
Most parallel corpora of sentence/visual data do not provide localization annotations (e.g. bounding boxes) and the annotation process is costly. We propose an approach which can learn to localize phrases relying only on phrases associated with images without bounding box annotations but which is also able to incorporate phrases with bounding box supervision when available. (标注成本过高 → \to → 适用于弱监督下的grounding,即训练集只有 image 的标注 phrase 而没有 image 内对应区域的标注)
Target:
弱监督条件,即给定phrase p p p 和相应的 image I I I,得到 I I I 中与 p p p 相关的 region r i r_i ri(segment 或者bounding box)
Main Idea:
既然有 phrase p p p , image I I I与 region r i r_{i} ri 的对应关系,即 f : p , I → r i f:p,I \to r_i f:p,I→ri ;那么理想情况下, 也可以通过 image I I I与 region r i r_{i} ri , 重构出 phrase p p p (类似于 autoencoder 的思路)
Contribution:
-
提出的 model 在 grounding 阶段使用 attention 机制
-
加入重构 phrase p p p 的模块,引入重构损失,使得提出的 model 可以用于各种监督条件:监督、半监督、非监督
-
good performance
Model:
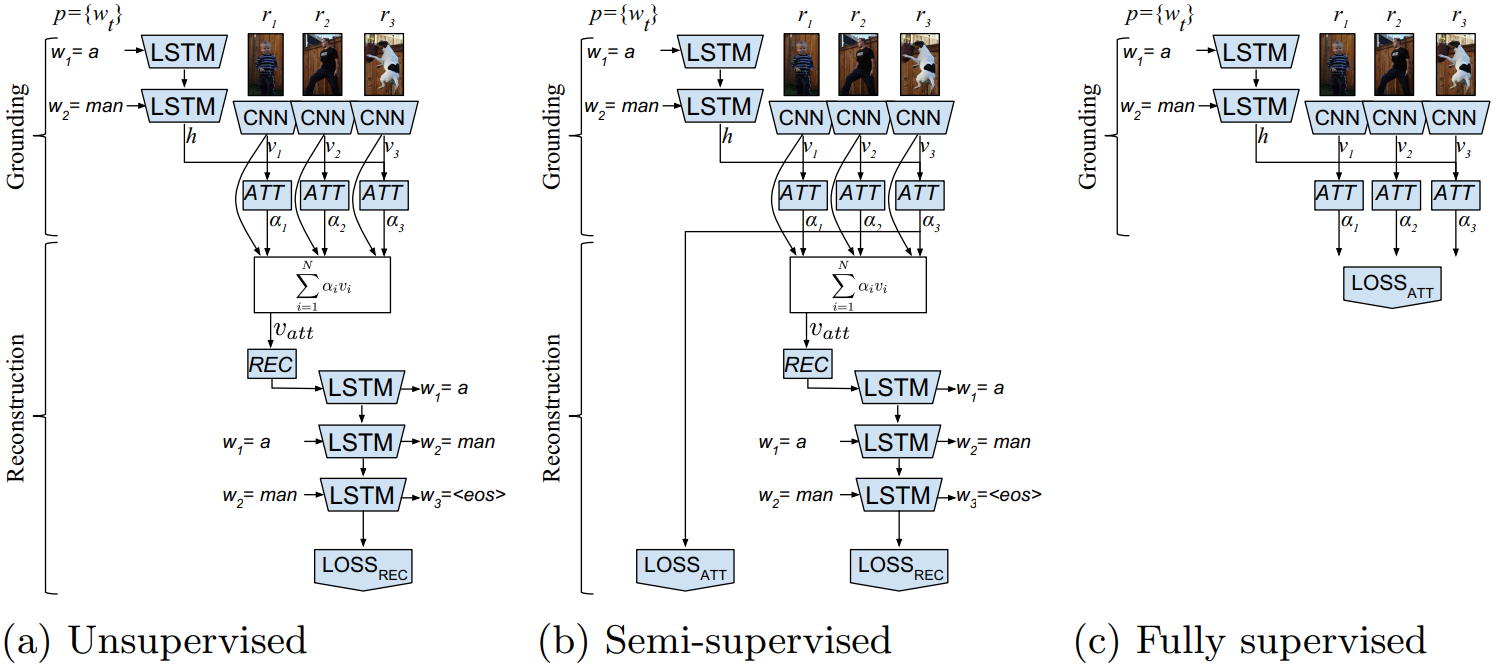
1)Grounding
To select the correct bounding box from region proposal { r i } i = 1 , . . . , N {\{r_i\}_{i=1,...,N}} { ri}i=1,...,N, we define an attention function f A T T f_{ATT} fATT and select the box j j
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 491
491











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









