







目录
流式数据的定义
流式数据是一种新的数据类型,它是一个有序的数据序列项,具有大量、连续、快速和不可再现的性质。例如,运营商数据管理(通话记录)、金融信用数据(证券交易)、网络应用程序(浏览记录)、银行系统数据(客户交易)等。由此可以概括出流式数据的一般定义:流式数据 S 是形如 {
(x0,y0),(x1,y1),(x2,y2),(xt,yt)}的且随时间推移而不断地变化增长的数据序列,其中 (xt,yt) 表示序列中的每一条数据样本。
大数据处理系统可分为批式(batch)大数据和流式(streaming)大数据两类。其中,批式大数据又被称为历史大数据,流式大数据又被称为实时大数据。
复杂的批量数据处理(batch data processing),通常的时间跨度在数十分钟到数小时之间。
基于历史数据的交互式查询(interactive query),通常的时间跨度在数十秒到数分钟之间。
基于实时数据流的数据处理(streaming data processing),通常的时间跨度在数百毫秒到数秒之间。
实时计算,强调的是实时。
计算机要在人能够忍耐的时间范围内得出结果
离线计算,离线计算是人无法忍耐的时间进行计算,因此人不需要等待,把任务丢给计算机后,自己该干嘛就去干嘛。
流式计算,比实时计算要稍微迟钝些,但比离线计算又实时的多,而且主要强调的是计算方法。
流式数据,特点就是,像流水一样,不是一次过来而是一点一点“流”过来。而你处理流式数据也是一点一点处理。如果是全部收到数据以后再处理,那么延迟会很大,而且在很多场合会消耗大量内存。
流式数据被封装成了byte流(其实也是二进制的)
比如,服务器端,有一个值,是记录小明订单数量。当小明每买一件东西后,服务端立即发出一个交易成功的事件,该值接收到这个事件后就立即加1。如果用离线计算的方式来做,估计是在查询时,才慢腾腾的从低速存储中,把小明的所有订单取出来,统计数量。流式计算有点像数据库领域的触发器,又有些像事件总线、中间件之类的计算模式。
流式数据的特征
静态数据是指那些固定的、一成不变的数据。比如最常见的数据集,它就是人为搜集后处理加工而成的,一经形成不可更改。当然,静态数据也有它的好处。静态数据集可以让研究者更快的建立与数据特征相关的数学模型,从而研究数据的行为规律。但是,它仅能代表数据当前的行为特征,并不能反映数据的实时行为。这也是为什么当下学者们要研究流式数据的原因之一。简言之,流式数据就是一系列不断变化的数据。它往往具有以下一些特征:
(1) 实时性。数据的到达都是连续不断的,随着时间的推移而无限增长。
(2) 时序性。流式数据中的数据元都是随着时间的顺序出现,具有时间序列相关性。
(3) 高速性。流式数据的速度在一般情况下都会保持一个较高的到达速度,在任何时刻都可能会有大量的数据元实例产生。
(4) 无限性。数据的量非常大,在某些情况下可能会无限增长。通常不可能将产生的庞大数据全部存储下来,只能在内存中存储一部分数据块以供检测。
(5) 不可再现性。通常建立的流式数据异常检测模型只能对高速到达的数据流扫描一次,如果处理的数据块不可以留存就会被模型直接丢弃,不会进行循环处理。
(6) 高纬性。流式数据中的数据元实例通常会有很高的维度,它代表了数据的不同特征,进而处理过程中会首先考虑对其执行降维操作。
(7) 概念漂移。数据流一直是高速增长和动态变化的,数据元实例会随着时间的变化而发生某些改变,这就产生了概念飘移。可以看到,流式数据是一种复杂的数据形式,这将会给流式数据的异常检测研究带来一定的困难。首先面临的问题就是流式数据的处理问题,只有高效的完成流式数据的处理才能实现对它的高性能检测。下面将围绕流式数据的处理技术展开讨论。
流式数据处理技术
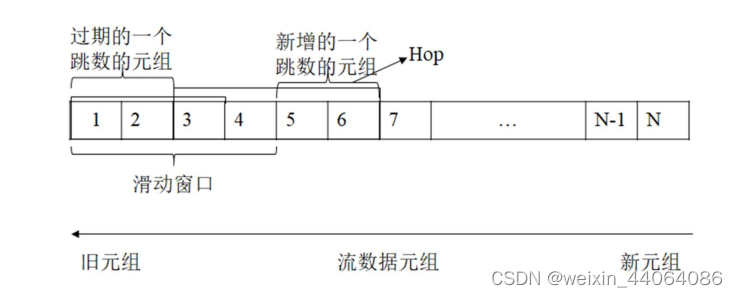
窗口技术
窗口技术在流式数据上具有很重要的地位。窗口技术是将对流上的数据处理作区域性限制,即针对流动数据处理的无限增长特性而作的处理方式,将所有流动数据处理操作全部限制在窗口的左右边缘范围。对于大部分应用来说,最近一段时间所产生的数据可以挖掘出更有价值的信息,之前的比较久的数据产生的价值相对来说就会少很多。它们大都比较强调时效性,因此只需要更多的关注最近的数据流,过多的在之前的数据流上进行挖掘信息反而起不了关键作用。因此,窗口技术得到了广泛的应用。
抽样技术
在统计学中,抽样技术(Sampling Techniques)是数学界研究颇多的一个分支。它主要由概率抽样和非概率抽样构成,见下表 。抽样,即从原始数据(总体)中按照一定规则抽取部分数据(样本),通过对样本进行计算(求均值、方差等)从而获取总体的相关信息。有了总体和样本,就可以计算出总体的均值和方差

当在流式数据处理中引用抽样技术后,得到的流数据处理结果跟总体会有一定的偏差。为了解决这个问题,可以使用误差抽样区间或霍夫丁边界来确定抽样的范围。抽样误差的产生是因为个体中存在变异概率,此时就会产生样本统计量和总体参数之间的差异。
流式数据学习的研究现状
流式数据是由于现实世界的事件互相关联而产生的动态数据,常见的应用有网络营销、社交媒体等领域。对于流式数据的学习与研究是机器学习和数据挖掘的一个重要且具有挑战性的研究课题。流式数据模型与传统数据模型的主要区别是前者拥有庞大的数据量和不断动态变化的数据。由于内部存储量有限,这使得流式数据中的大多数实例在处理后必须丢弃。因此,在流式数据模型上使用传统的数据挖掘技术只能存储一定数量的实例以供分析,难以获取真正有效的用户数据。
《Mining Recurring Concept Drifts with Limited Labeled Streaming Data》提出一种基于决策树的半监督分类算法,该算法可以从有限标记数据的数据流中挖掘相同的数据。在决策树的构建过程中,采用 k-means 算法生成概念聚类。《Mining Streaming Emerging Patterns from Streaming Data》提出了一种在流式数据中挖掘频繁模式的方法,该方法引入一种新型AEP 决策树用于流数据的分类与项集的生成,从而有选择性地在流式数据中挖掘频率明显高于其他类别的项集 EPs。《 Finding tendencies in streaming data using Big Data frequent itemset mining-ScienceDirect》提出了一种新的流式数据挖掘方法,通过使用 MapReduce 框架和 Spark 平台从连续的数据流中提取有效信息。该方法可以在可变的窗口长度上执行,并且在算法执行期间通过更改阈值,使计算可以分布在多个数据集群数据上,从而提高运行速度。
对于流式数据的异常检测也广泛应用于环境监测、气象分析与网络异常检测等领域。传统的流式数据异常检测方法采用的是基于统计的分析方法,应用范围有一定的局限性。近年来,随着数据挖掘与机器学习的迅猛发展,流式数据的异常检测方法已经有了较高的实时性与准确性,可以处理空间异常、上下文异常或概念漂移等异常情况。














 1318
1318











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









