






前言
个人出于兴趣关于IM的一些学习总结,欢迎各位大佬指点,我会从客户端发送端,服务器,客户端接收端三个层次,然后描述各个层次作用以及注意点。此篇文章要求有一定的netty和IM基础,不懂得地方可以评论我会尽力解答。
文章中一些概念的解释
消息风暴扩散系数:是指一个消息发出时,变成N个消息的扩散系数,这个系数与业务及数据相关,一定程度上它的大小决定了技术采用推送还是拉取。如果对业务实时性要求较高,可以采用推送的方式同步;如果实时性要求不高,可以采用轮询拉取的方式同步。
举例:
- 好友状态,如果对实时性要求较高,可以采用推送的方式同步;如果实时性要求不高,可以采用轮询拉取的方式同步;
- 群友的状态,由于消息风暴扩散系数过大,可以采用按需拉取,延时拉取的方式同步;
- 系统消息/开屏广告等对实时性要求不高的业务,可以采用拉取的方式获取消息;
IM通信数据格式参考:
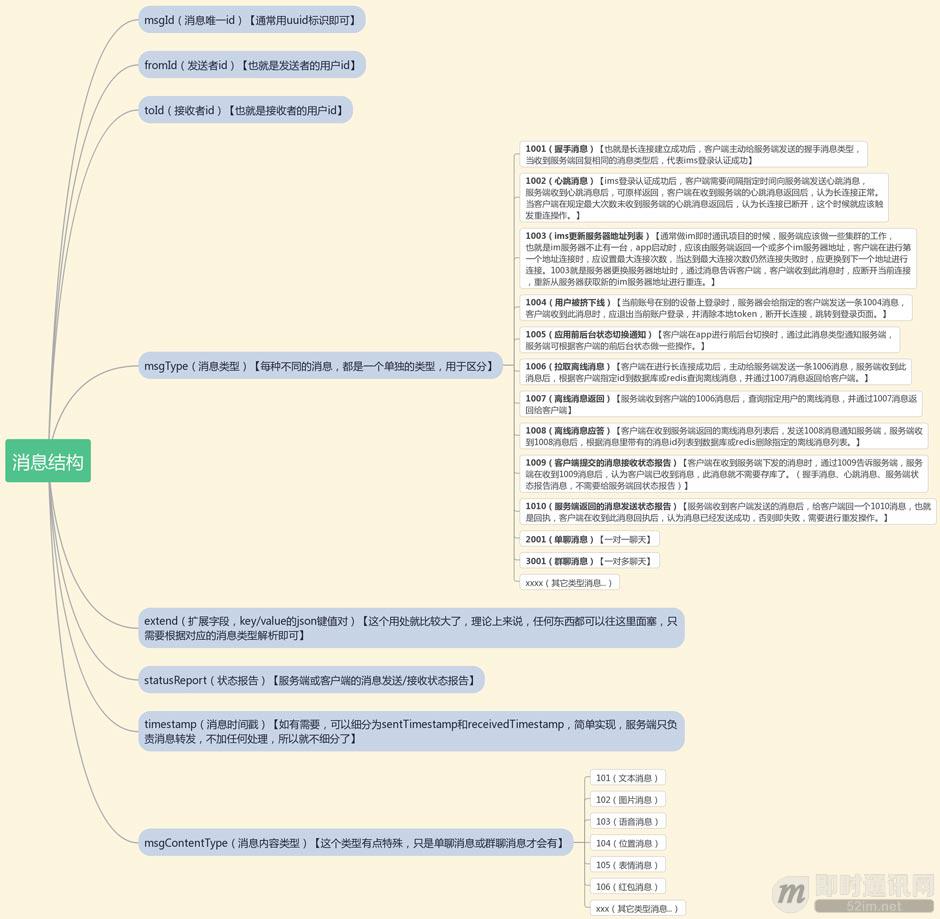
在此基础上还可以定义一种回执数据格式ACK,MsgType有三种,分别是sent(已发送),delivered(已送达), read(已读),以及加密相关的。
举例:
消息回执表:用来记录消息的已读回执
msg_acks(sender_uid, msgid, recv_uid, gid,if_ack);
各字段的含义为:发送方UID,消息ID,回执方UID,群ID,回执标记。
消息通信注意TCP出现拆包/粘包的原因,那么,如何解决呢?
通常来说,有以下四种解决方式:
- 1)消息定长;
- 2)用回车换行符作为消息结束标志;
- 3)用特殊分隔符作为消息结束标志,如\t、\n等,回车换行符其实就是特殊分隔符的一种;
- 4)将消息分为消息头和消息体,在消息头中用字段标识消息总长度。
- netty针对以上四种场景,给我们封装了以下四种对应的解码器:
- 1)FixedLengthFrameDecoder,定长消息解码器;
- 2)LineBasedFrameDecoder,回车换行符消息解码器;
- 3)DelimiterBasedFrameDecoder,特殊分隔符消息解码器;
- 4)LengthFieldBasedFrameDecoder,自定义长度消息解码器。
一、客户端发送端
功能点:
1.启动netty的IdleStateHandler进行心跳检测,检测不到了就关闭channel
2.单独开辟线程在channel记录时间实现重连逻辑,进行最大重试次数进行重试连接。
3.发送方每次发送一个消息,就必须要等待对方的ack回应,并且在ack确认消息中应该带有收到的id以便发送方识别。
4.发送方需要维护一个等待ack的队列。 每次发送一个消息之后,就将消息和一个计时器入队,另外存在一个线程一直轮询队列,如果有超时未收到ack的,就取出消息重发。
5.客户端登录时,先去数据库拉取自己的好友列表,再去缓存获取所有好友的在线状态,如果接收方下线要对自己的好友进行推送自己的下线状态。
注意点:
1.已读回执过多怎么办?
答:轮询拉取,比如群里发送方每发一条消息,会收到40个已读回执,采用轮询拉取(例如1分钟一次,一个小时也就60个请求),可以大大降低请求量。
2.发送方不在线怎么办?
答:在线实时推送,不在则考虑下次在线再拉取。
3.接收方下线要对自己的好友进行推送自己的下线状态,如果是群那怎么办,所有好友都互相推送系统可以承受住吗?
答:客户端发送方主动拉取,考虑到加的群一般很多所以只有进入的那个群才会开始拉取。
4.为什么需要单独开辟线程在channel记录时间进行重连逻辑?
在调用 ctx.writeAndFlush() 发送消息获取回调时。
其中是 isSuccess 并不能作为消息发送成功与否的标准:这是因为这里的 success 只是告知我们消息写入了 TCP 缓冲区成功了而已。
所以我们不能依据此来关闭客户端的连接,而是要判断 Channel 上绑定的时间与当前时间只差是否超过了阈值。超过了这个时间没收到ack则认为断线需要重连,指定时间收到ack则认为连接正常。
一个单独的线程来判断是否需要重连,不依赖于 IdleStateHandler。不然会因为IdleStateHandler 作为一个 ChannelInbound 也重写了 channelInactive() 方法,导致你自己写的重连代码逻辑被忽略
5.消息已读同步如何保证?
1)同步状态维护,为用户的每一个Session,维护一个时间戳,保存最后的读消息时间;
2)同一个人发出的消息,排序按消息附带的本地时间来排。不同人的消息,按照服务器时间排序。
6.为什么不能用keepalive做心跳?
考虑一种情况,某台服务器因为某些原因导致负载超高或者说掉线了无法及时响应,TCP探测周期太长。对客户端而言,这时的最好选择就是断线后重新连接其他服务器,而不是一直认为当前服务器是可用状态,一直向当前服务器发送些必然会失败的请求。
KeepAlive 并不适用于检测双方存活的场景,这种场景还得依赖于应用层的心跳。应用层心跳有着更大的灵活性,可以控制检测时机,间隔和处理流程,甚至可以在心跳包上附带额外信息。从这个角度而言,应用层的心跳的确是最佳实践。netty种pipeline 中加入了一个 10秒没有收到写消息的 IdleStateHandler,到时他会回调 ChannelInboundHandler 中的 userEventTriggered 方法。
7.超时未收到ack的消息有两种处理方式:
- 1)和tcp一样不断发送直到收到ack为止。
- 2)设定一个最大重试次数,超过这个次数还没收到ack,就使用失败机制处理,节约资源。可以主动断开和客户端接收方的连接,剩下未发送的消息就作为离线消息入库,客户端断连后尝试重连服务器即可。
二、服务器
功能点:
1.离线消息:
如果用户当前不在线,就必须把消息持久化下来,等待用户下次上线再推送,可以考虑使用mysql存储离线消息。为了方便地水平扩展,我们使用消息队列进行解耦。
- 1)服务器接收到消息后如果发现接受方不在线,就发送给消息队列入库;
- 2)接收方登录时,服务器从库里拉取离线消息进行推送。
注意点:
如何保证离线消息可靠传输?
1.服务器返回客户端“发送成功”ACK确认包(对于消息发送方而言,消息一旦落地存储至DB就认为是发送成功了)。离线消息删除也是同样的,要确保收到接收方ACK以后才进行消息删除。
2.防止离线消息重复推送:
我们思考一下多端登录的情况,Alice有两台设备同时登陆,在这种并发的情况下,我们就需要某种机制来保证离线消息只被读取一次。
这里利用CAS机制来实现:
- 1)首先取出所有has_read=false的字段;
- 2)检查每条消息的has_read值是否为false,如果是,则改为true。这是原子操作,修改成功则推送,失败则不推送。
3.服务器推送离线消息过多要考虑分页拉取,这样可以保证显示的实时性
4.服务端自动剔除离线客户端
5.IM的群聊消息,究竟存1份(即扩散读方式)还是存多份(即扩散写方式)?
任何架构方案都不是灵光一现,而是逐步迭代优化产生的:
- 方案1:群聊消息存多份,只存在线,消息容易丢;
- 方案2:群聊消息存多份,所有群友都存储,消息冗余多;
- 方案3:群聊消息存多份,只存ID,未利用偏序;
- 终极方案:群聊消息存一份,只存last_ack_msgid。
客户端接收方
注意点:
不重复
有的时候因为网络原因可能导致ack收到较慢,发送方就会重复发送,那么接收方必须有一个去重机制。
去重的方式是给每个消息增加一个唯一id。这个唯一id并不一定是全局的,只需要在一个会话中唯一即可。例如某两个人的会话,或者某一个群。如果网络断连了,重新连接后,就是新的会话了,id会重新从0开始。
不乱序
接收方需要在当前会话中维护收到的最后一个消息的id,叫做lastId。
每次收到一个新消息, 就将id与lastId作比较看是否连续,如果不连续,就放入一个暂存队列 queue中稍后处理。如果是重复的就直接发送ACK
1)当前会话的lastId=1,接着服务器收到了消息msg(id=2),可以判断收到的消息是连续的,就处理消息,将lastId修改为2;
2)但是如果服务器收到消息msg(id=3),就说明消息乱序到达了,那么就将这个消息入队,等待lastId变为2后,(即服务器收到消息msg(id=2)并处理完了),再取出这个消息处理。
降低离线拉取ACK带来的额外与服务器的交互次数
不用每一页消息都ACK,在拉取第二页消息时相当于第一页消息的ACK,此时服务器再删除第一页的离线消息即可,最后一页消息再ACK一次(实际上:最后一页拉取的肯定是空返回,这样可以极大地简化这个分页过程
否则客户端得知道当前离线消息的总页数,而由于消息读取延迟的存在,这个总页数理论上并非绝对不变,从而加大了数据读取不一致的可能性)
这样的效果是,不管拉取多少页离线消息,只会多一个ACK请求,与服务器多一次交互。
接收方累计收到N条群消息再批量ack,避免一次性ack带来的性能影响
IM登录相关:
可以看看这个
http://www.52im.net/thread-2863-1-1.html
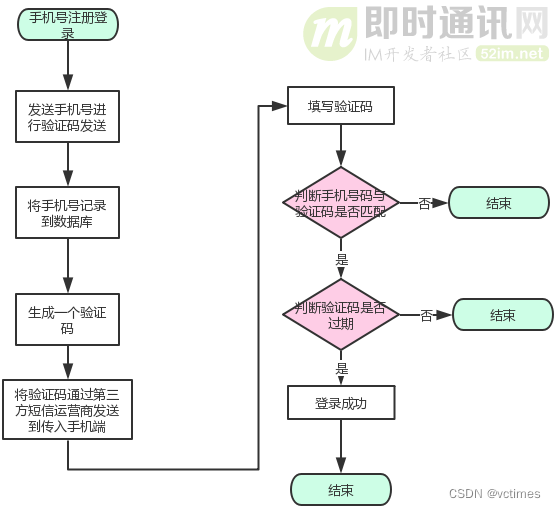
常见登录方式:
第三方登录:
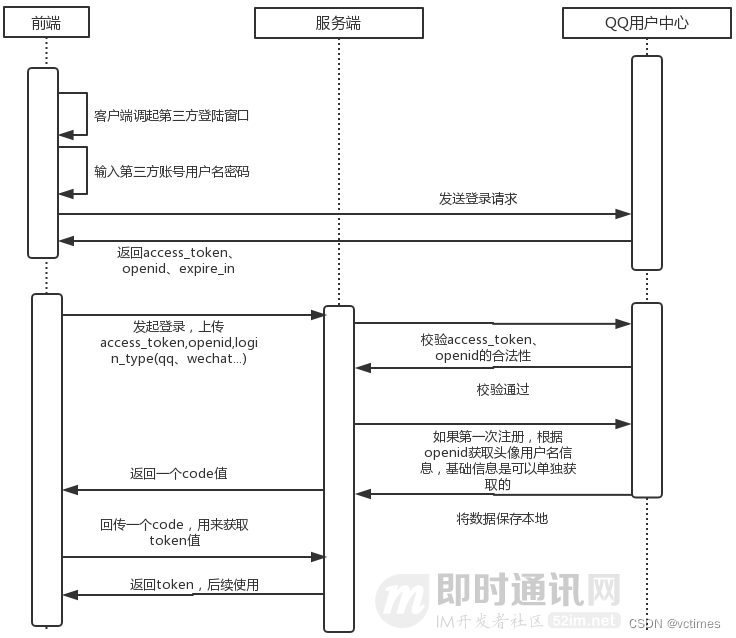
、
群消息处理策略
群消息怎么存?
“不管是否在线,都冗余一份群消息”带来的问题是:同一条消息存储了很多次,对磁盘和带宽造成了很大的浪费。
很容易想到的优化是:群消息实体存储一份,用户只冗余消息ID。
- 方案1:群聊消息存多份,只存在线,消息容易丢;
- 方案2:群聊消息存多份,所有群友都存储,消息冗余多;
- 方案3:群聊消息存多份,只存ID,未利用偏序;
- 终极方案:群聊消息存一份,只存last_ack_msgid。
为了减少消息风暴,可以批量ACK;
如果收到重复消息,需要msg_id去重,让用户无感知;
对于群消息已读回执,怎么处理?
- 如果发送方在线,会实时被推送已读回执;
- 如果发送方不在线,会在下次在线时拉取已读回执。
如果要对进行优化,可以:
- 接收方累计收到N条群消息再批量ack;
- 会带来什么副作用?
- 批量消息再ack可能导致异常退出时候有些消息没有发送ack,然后客户端收到重复消息,这里要注意客户端去重
- 发送方轮询拉取已读回执。
- 还可能存在的问题:群离线消息过多:拉取过慢。
解决方案:分页拉取(按需拉取)
群消息一定要主动推送吗,能否改为接收方轮询拉取?
答:不能,消息接收,实时性是核心指标。服务器必须马上推送到另一个客户端,但是不一定要马上收获ack
群聊消息发送原理
群聊消息的分发通常有两种技术实现方式,我们一一来看看。
方式一:假设一个群有100人,如果Client1给一个群的所有人发消息,其实相当于Client1分别给其余99人分别发一条消息。我们可以直接在Client端,通过循环,分别给群里的99人发消息即可,相当于Client发送给NettyServer发送了99次相同的消息(除了to_uid不同)。
上述方案有很严重的性能问题:Client1通过循环99次,分别把消息发给NettyServer,NettyServer收到这99条消息后,分别将消息发给群内其余的用户。先抛开移动端的特殊性(比如循环还没完成手机就有可能退到后台被系统挂起),显然Client1到NettyServer的99次循环存在明显不合理地方。
方式二:上节的消息体中to_uid_list字段就是为了解决这个方式一的性能问题的。Client1把群内其余99个Client的uid保存在to_uid_list中,然后NettyServer只发一条消息,NettyServer收到这一条消息后,通过to_uid_list字段解析群内其余99的Client的uid,再通过循环把消息分别发送给群内其余的Client。















 873
873











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









