







目录
分割文件 - 指定分割成n个文件,不拆分行,保留整行,输出第k次到标准输出
分割文件 - 指定分割成n个文件,不拆分行,保留整行,一行一个文件循环
分割文件 - 指定分割成n个文件,不拆分行,保留整行,一行一个文件循环,输出第k次到标准输出
内容来源:
GUN : Coreutils - GNU core utilities
busybox v1.36.1 : 【busybox记录】【shell指令】基于的Busybox的版本和下载方式-CSDN博客
【GUN】【split】指令介绍
split:将文件分割为多个部分。
split 创建包含连续或交错输入部分的输出文件(如果没有给出标准输入或输入为' - ')。
简介:
split [option] [input [prefix]]
默认情况下,split将1000行输入(或者上一节剩下的内容)放入每个输出文件中。
输出文件的名称由前缀(默认为`x`)和一组字符(`aa`,`ab`,…默认情况下),这样按照文件名的传统排序顺序连接输出文件就会生成原始输入文件(-nr/n除外)。
默认情况下,split会创建两个后缀字符的文件,当下一个重要位置到达最后一个字符时,会将宽度增加2。(`yz`,`zaaa`,`zaab`,…)
这种方式支持任意数量的输出文件,如上所述排序,即使存在一个 --additional-suffix 选项。
如果指定了-a选项,并且输出文件名耗尽,split将报告错误,但不会删除它创建的输出文件。
该程序接受以下选项。参见第2章[常见选项],第2页。
‘-l lines’
‘--lines=lines’
将每行输入放入每个输出文件。如果指定 --separator,则行数决定记录的数量。为了兼容性,split还支持过时的选项语法-lines。新的脚本应该使用 -l。
‘-b size’
‘--bytes=size’
将大小字节的输入放入每个输出文件。size可以是一个整数,后面可以有下列乘性后缀:
'b' => 512 ("blocks")
'KB' => 1000 (KB)
'K' => 1024 (KibiBytes)
'MB' => 1000*1000 (MB)
'M' => 1024*1024 (mb)
'GB' => 1000*1000*1000 (GB)
'G' => 1024*1024*1024 (GibiBytes)
等等'T', 'P', 'E', 'Z', 'Y','R','Q'。也可以使用二进制前缀:'KiB' = 'K', 'MiB' = 'M',等等。
‘-C size’
‘--line-bytes=size’
在每个输出文件中放入尽可能多的完整输入行,但不超过大小字节。超过size字节的单行或记录被分成多个文件。Size的格式与--bytes选项相同。如果指定--separator,则行数决定记录的数量。
‘--filter=command’
使用此选项,不是简单地写入每个输出文件,而是通过管道写入每个输出文件的指定shell命令。命令应该使用$FILE环境变量,该变量为每次调用命令设置不同的输出文件名。
例如,假设您有一个1TiB的压缩文件,如果不进行压缩,它将太大而无法驻留在辅助存储中,而您必须将它分割为单独压缩的片段,使其具有更易于管理的大小。
为此,可以运行以下命令:
xz -dc BIG.xz | split -b200G --filter='xz > $FILE.xz' - big-
假设压缩比为10:1,这将创建大约50个大小为20GiB的big-aa.xz big-ab.xz big-ac.xz文件,等等。
‘-n chunks’
‘--number=chunks’
将输入分割成块输出文件,其中块可以是:
n 根据当前输入大小生成n个文件
k/n 只输出第k次到标准输出
l/n 生成n个文件,不拆分行或记录
l/k/n同样,但只输出第k次到stdout
r/n 类似于'l',但使用轮询分布
r/k/n同样,但只输出第k个到stdout
如果输入文件的大小不是n的倍数,则早期的输出文件比之后的输出文件长1字节,以弥补差异。任何出现在初始计算之后的多余字节都会被丢弃(除非使用`r`模式)。
即使少于n行,也会创建所有n个文件,否则输入将被截断。
对于'l'模式,块近似为输入大小/n。尽管输入仍然像以前一样划分为n个大小近似相等的区域,但如果一行从一个分区中开始,它将完全写入相应的文件。
因为即使行或记录重叠在一个分区上,它们也不会被分割,所以写入的文件可以比分区大小大或小,如果一行或记录很长,完全重叠在分区上,甚至可以是空的。
当输入是一个管道或其他大小无法轻易确定的特殊文件时,使用`r`模式没有问题,因为输入的大小是不相关的。对于其他模式,这样的输入首先被复制到一个临时变量以确定其大小。
‘-a length’
‘--suffix-length=length’
使用length长度后缀。如果指定长度为0,这与未指定-a的情况相同,因此启用默认行为,即后缀长度从2开始,除非指定-n或--numeric-suffixes=from,否则将根据需要自动将长度增加2。
‘-d’
‘--numeric-suffixes[=from]’
使用数字后缀,而不是小写字母。如果指定,则数字后缀从开始计数,否则为0。
long form选项支持From,用于为单个运行设置初始后缀,或为独立分割的输入设置后缀偏移量,因此上述自动后缀长度扩展是禁用的。
因此,你可能还想使用option -a来允许后缀超过`99`。
如果指定了--number,并且文件数量小于from,则假定一次运行,并自动确定所需的最小后缀长度。
‘-x’
‘--hex-suffixes[=from]’
类似--numeric-suffixes,但使用十六进制数字(小写)。
‘--additional-suffix=suffix’
为输出文件名追加一个额外的后缀。后缀不能包含斜杠。
‘-e’
‘--elide-empty-files’
禁止生成零长度输出文件。
如果文件(截断后)比请求的数字短,或者一行长到可以跨越一个块,则可以使用--number选项。输出文件序列号,即使指定了这个选项,也总是连续运行。
‘-t separator’
‘--separator=separator’
使用字符分隔符作为记录分隔符,而不是默认的换行符(ASCII LF)。要指定ASCII中的NUL作为分隔符,可以使用两个字符的字符串'\0',例如 "split -t '\0'"。
‘-u’
‘--unbuffered’
立即将输入复制到输出中--number r/…模式,这是一种慢得多的操作模式。
‘--verbose’
在打开每个输出文件之前编写诊断。
退出状态为零表示成功,非零值表示失败。
下面是几个例子来说明--number (-n)选项的工作原理:
请注意,默认情况下,一行代码可能会被分割成两行或多行:
$ seq -w 6 10 > k; split -n3 k; head xa?
==> xaa <==
06
07
==> xab <==
08
0
==> xac <==
9
10
Use the "l/" modifier to suppress that:
$ seq -w 6 10 > k; split -nl/3 k; head xa?
==> xaa <==
06
07
==> xab <==
08
09
==> xac <==
10
Use the "r/" modifier to distribute lines in a round-robin fashion:
$ seq -w 6 10 > k; split -nr/3 k; head xa?
==> xaa <==
06
09
==> xab <==
07
10
==> xac <==
08
You can also extract just the Kth chunk. This extracts and prints just the 7th "chunk" of 33:
$ seq 100 > k; split -nl/7/33 k
20
21
22【busybox】【split】指令介绍
NA
【linux】【split】指令介绍
[root@localhost bin]# split --help
Usage: split [OPTION]... [FILE [PREFIX]]
Output pieces of FILE to PREFIXaa, PREFIXab, ...;
default size is 1000 lines, and default PREFIX is 'x'.
如果没有指定文件,或者文件为"-",则从标准输入读取。
必选参数对长短选项同时适用。
-a, --suffix-length=N generate suffixes of length N (default 2)
--additional-suffix=SUFFIX append an additional SUFFIX to file names
-b, --bytes=SIZE put SIZE bytes per output file
-C, --line-bytes=SIZE put at most SIZE bytes of records per output file
-d use numeric suffixes starting at 0, not alphabetic
--numeric-suffixes[=FROM] same as -d, but allow setting the start value
-x use hex suffixes starting at 0, not alphabetic
--hex-suffixes[=FROM] same as -x, but allow setting the start value
-e, --elide-empty-files do not generate empty output files with '-n'
--filter=COMMAND write to shell COMMAND; file name is $FILE
-l, --lines=NUMBER put NUMBER lines/records per output file
-n, --number=CHUNKS generate CHUNKS output files; see explanation below
-t, --separator=SEP use SEP instead of newline as the record separator;
'\0' (zero) specifies the NUL character
-u, --unbuffered immediately copy input to output with '-n r/...'
--verbose 在每个输出文件打开前输出文件特征
--help 显示此帮助信息并退出
--version 显示版本信息并退出
The SIZE argument is an integer and optional unit (example: 10K is 10*1024).
Units are K,M,G,T,P,E,Z,Y (powers of 1024) or KB,MB,... (powers of 1000).
CHUNKS may be:
N split into N files based on size of input
K/N output Kth of N to stdout
l/N split into N files without splitting lines/records
l/K/N output Kth of N to stdout without splitting lines/records
r/N like 'l' but use round robin distribution
r/K/N likewise but only output Kth of N to stdout
GNU coreutils 在线帮助:<https://www.gnu.org/software/coreutils/>
请向 <http://translationproject.org/team/zh_CN.html> 报告 split 的翻译错误
完整文档请见:<https://www.gnu.org/software/coreutils/split>
或者在本地使用:info '(coreutils) split invocation'使用示例:
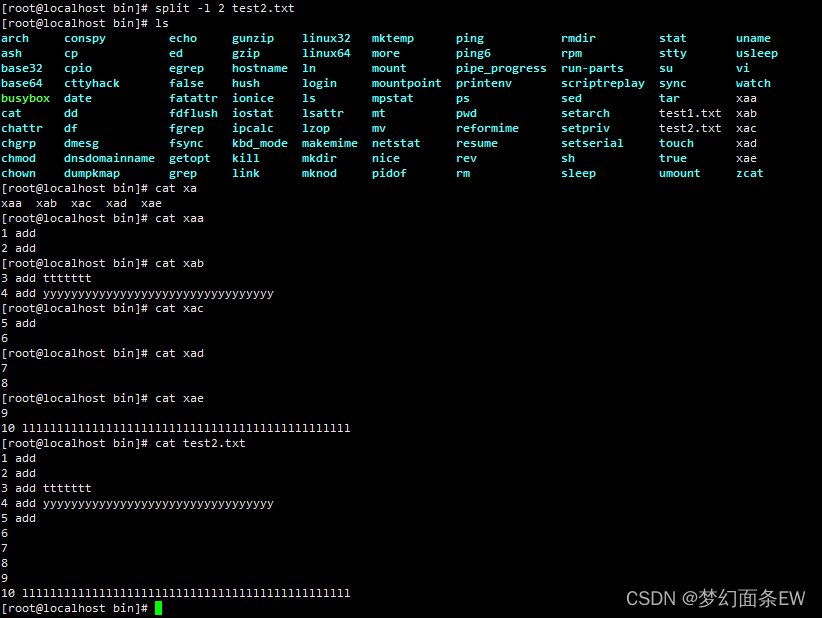
分割文件 - 以行数为单位进行切割
将源文件以2行的大小来分割
指令: split -l 2 test2.txt
默认生成了 ./xaa ./xab ./xac ./xad ./xae 五个文件,因为源文件只有10行
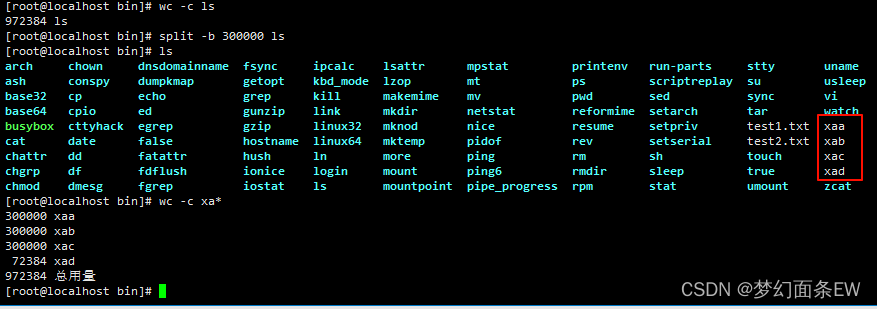
分割文件 - 以字节为单位进行切割
将ls文件以300000字节的大小来分割
ls文件总大小为972384字节,用300000字节来分割可以分成4个文件,下面分割后查了下总大小和源文件能对上
指令: split -b 300000 ls
分割文件 - 在每个文件中尽可能多得放入完整的行
指令: split -C 12 test2.txt
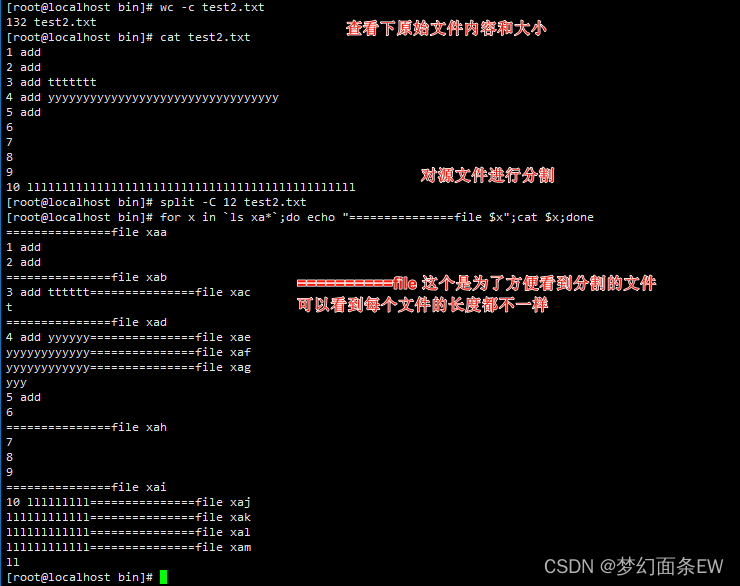
可以看到这个选项会导致文件大小不一致

分割文件 - 同时对每个文件执行shell指令
ls的输出为例:
将ls的输出分割以20行进行分割,同时没分割一次,执行一次打印指令
PS<不会生成分割后的文件>
指令: ls | split -l 20 --filter='echo log'

也可以使用分号同时执行多条shell指令,
PS<同样的只有打印,没有生成分割后的文件>
指令:ls | split -l 20 --filter='echo log;echo log2'

那么有没有既有打印,也生成文件的方法,我没找到方法,如果有人知道,麻烦留言。
分割文件 - 指定分割成n个文件
-n 选项 指定分割的文件个数
指令: split -n 3 --verbose test2.txt mytest

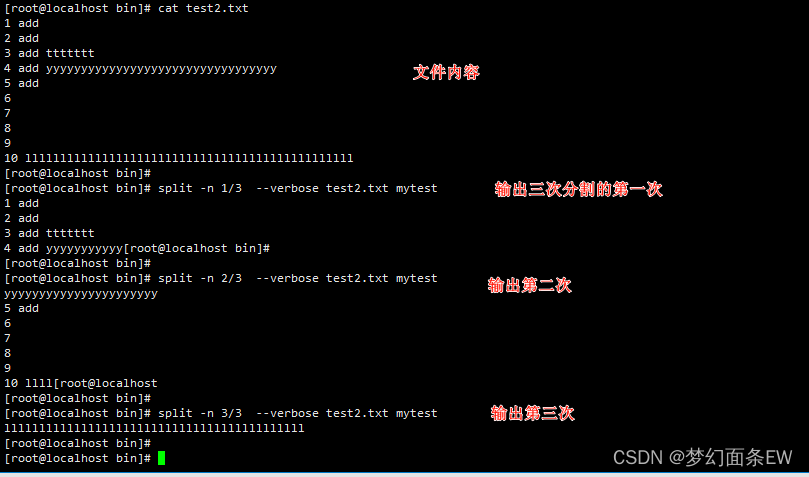
分割文件 - 指定分割成n个文件,输出第k次到标准输出
分别输出第一次,第二次,第三次的拆分结果到标准输出,PS<不生成文件>
指令:split -n 1/3 --verbose test2.txt mytest
指令:split -n 2/3 --verbose test2.txt mytest
指令:split -n 3/3 --verbose test2.txt mytest
分割文件 - 指定分割成n个文件,不拆分行,保留整行
注意:前面那个是字母的l,不是数字的1
指令: split -n l/3 --verbose test2.txt mytest

分割文件 - 指定分割成n个文件,不拆分行,保留整行,输出第k次到标准输出
PS<不生成文件>
注意:前面那个是字母的l,不是数字的1
指令: split -n l/1/3 --verbose test2.txt mytest
指令: split -n l/2/3 --verbose test2.txt mytest
指令: split -n l/3/3 --verbose test2.txt mytest

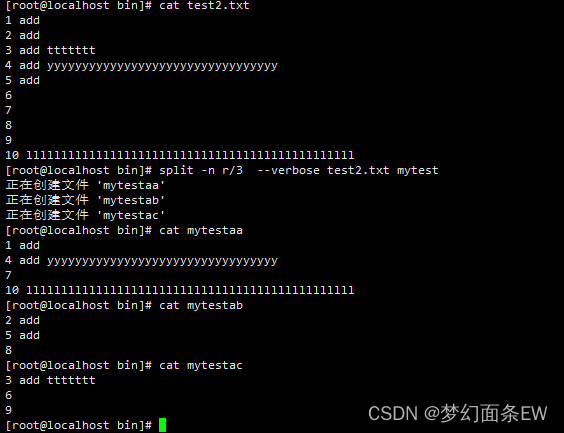
分割文件 - 指定分割成n个文件,不拆分行,保留整行,一行一个文件循环
举例:一共分割3个文件
第一个文件:第一行,第四行,第七行 ...
第二个文件:第二行,第五行,第八行 ...
第三个文件:第三行,第六行,第九行 ...
指令:split -n r/3 --verbose test2.txt mytest
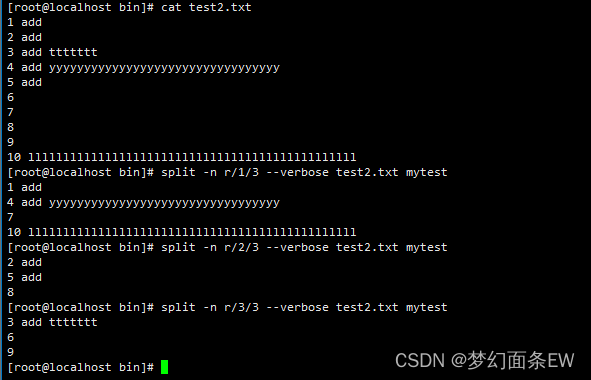
分割文件 - 指定分割成n个文件,不拆分行,保留整行,一行一个文件循环,输出第k次到标准输出
PS<不生成文件>
举例:一共分割3个文件
第一个文件:第一行,第四行,第七行 ...
第二个文件:第二行,第五行,第八行 ...
第三个文件:第三行,第六行,第九行 ...
指令:split -n r/1/3 --verbose test2.txt mytest
指令:split -n r/2/3 --verbose test2.txt mytest
指令:split -n r/3/3 --verbose test2.txt mytest
分割文件 - 指定分割后文件的文件名
最后一个参数为文件名
指令: split -l 5 --verbose test2.txt mytest

分割文件 - 指定分割后文件的文件名长度
指定文件长度为10 ,可以看到默认是3,新分割的文件文件名为10
指令: split -l 5 -a 10 test2.txt

分割文件 - 指定分割后文件的文件名为数字递增
指令:split -l 5 -d test2.txt

分割文件 - 指定分割后文件的文件名为16进制递增
指令: split -l 5 -x test2.txt

分割文件 - -a和-d组合可以使用更大范围的数字递增
指令: split -l 5 -d -a 10 test2.txt

分割文件 - 不产生空文件
常和分割成n个文件一起使用
示例中指定要拆分成3个文件,但是拆分成三个文件不加 -e 选项就会导致第三个文件为空文件,增加以后,只生成2个文件
指令:split -n l/3 -e --verbose test2.txt

分割文件 - 指定分割后文件的文件名后缀
指定后缀为.log
指令: split -l 5 --additional-suffix=".log" test2.txt

分割文件 - 打印分割时的详细信息
指令: split -l 5 --verbose test2.txt

常用组合指令:
NA














 250
250











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









