






💡 包含键值对的无序散列表。value 只能是字符串,不能嵌套其他类型。
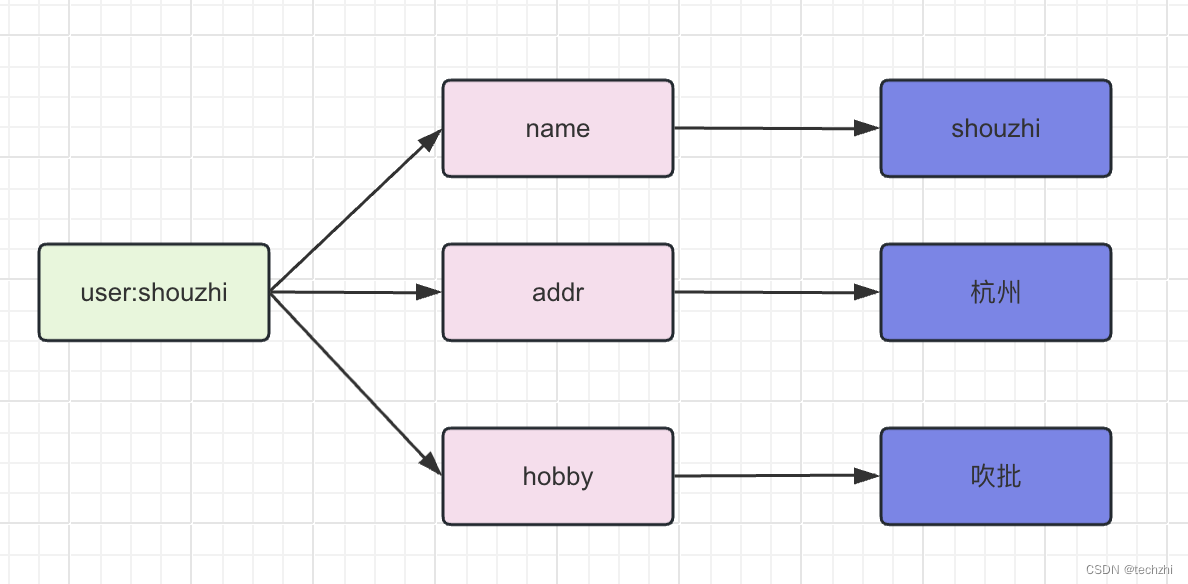
同样是存储字符串,Hash 与 String 的主要区别?
1、把所有相关的值聚集到一个 key 中,节省内存空间
2、只使用一个 key,减少 key 冲突
3、当需要批量获取值的时候,只需要使用一个命令,减少内存/IO/CPU 的消耗
Hash 不适合的场景:
1、Field 不能单独设置过期时间
2、没有 bit 操作
3、需要考虑数据量分布的问题(value 值非常大的时候,无法分布到多个节点)
版本信息
- redis_version:7.2.3
存储类型
- String
操作命令
- hset
- hmget
- hkeys
- hval
- hgetall
- more commands
底层编码
- listpack
redis6版本之前是ziplist,现在变成了listpack适用小数据,数据存储空间过大就会变成hashtable
> hset user:shouzhi name shouzhi
(integer) 1
> OBJECT ENCODING user:shouzhi
"listpack"
- hashtable
# 这里故意把value的值设置长一点,这样就会转变成hashtable来存储了。
> hset user:shouzhi name shouzhi111111111111111111111111111111111111111111111111111111111111111111111111
(integer) 0
> OBJECT ENCODING user:shouzhi
"hashtable"
下面存储原理会做相应的解释分析,查看key对应的存储编码命令:OBJECT ENCODING <YOUR_KEY>
存储原理
Redis 的 Hash 本身也是一个 KV 的结构,类似于 Java 中的 HashMap。外层的哈希(Redis KV 的实现)只用到了 hashtable。当存储 hash 数据类型时,我们把它叫做内层的哈希。内层的哈希底层可以使用两种数据结构实现:
ziplist:OBJ_ENCODING_ZIPLIST(压缩列表,ziplist被redis6版本优化掉了,变成下面的listpack)
listpack:OBJ_ENCODING_LISTPACK(列表包)
hashtable:OBJ_ENCODING_HT(哈希表)
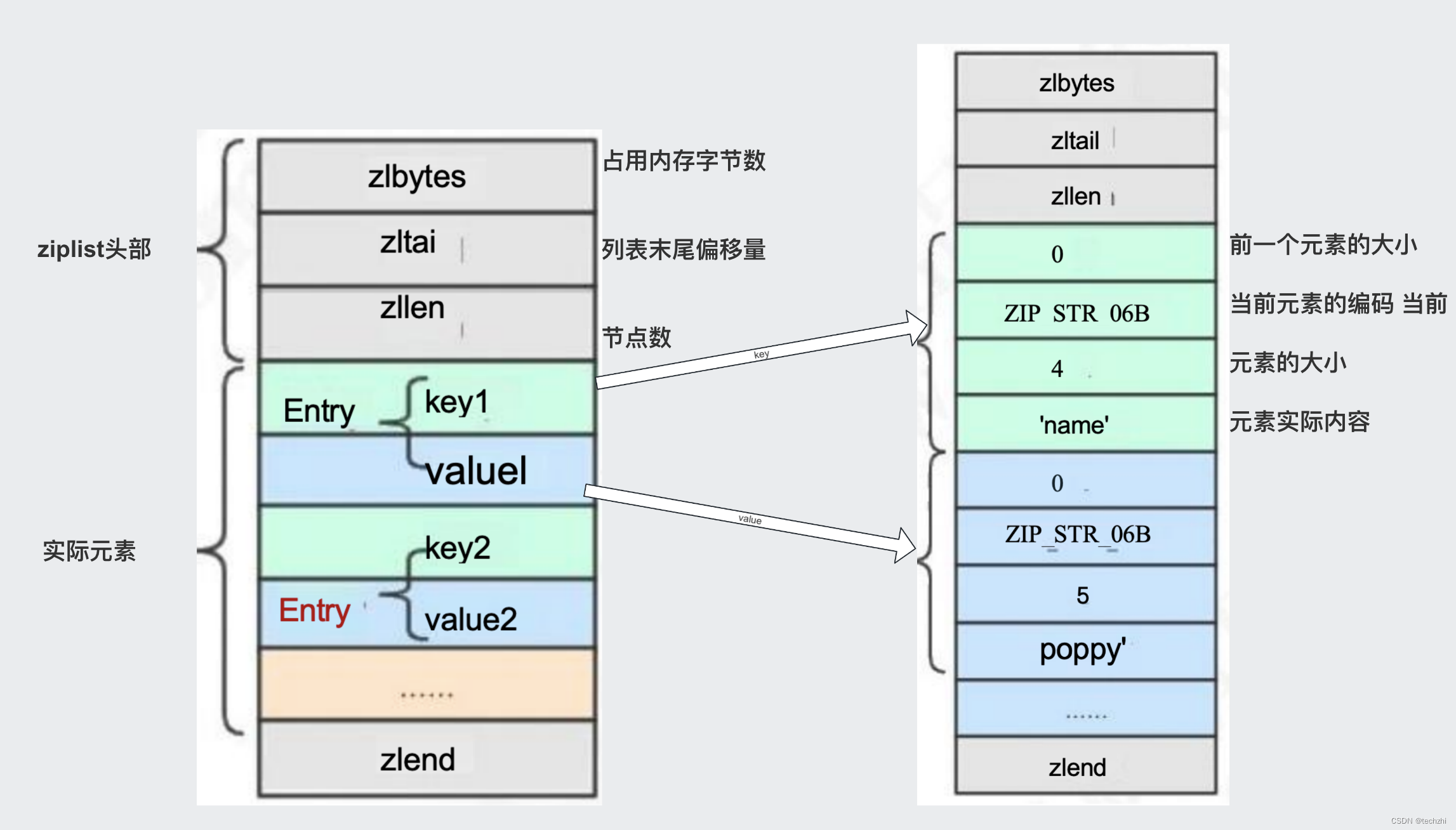
ziplist 压缩列表
(注意:ziplist是redis6版本之前的实现,现在改成了listpack。但是这里还是给大家分析下。)

ziplist 是一个经过特殊编码的双向链表,它不存储指向上一个链表节点和指向下一
个链表节点的指针,而是存储上一个节点长度和当前节点长度,通过牺牲部分读写性能,
来换取高效的内存空间利用率,是一种时间换空间的思想。只用在字段个数少,字段值
小的场景里面。
typedef struct zlentry {
unsigned int prevrawlensize; /* 上一个链表节点占用的长度 */
unsigned int prevrawlen; /* 存储上一个链表节点的长度数值所需要的字节数 */
unsigned int lensize; /* 存储当前链表节点长度数值所需要的字节数 */
unsigned int len; /* 当前链表节点占用的长度 */
unsigned int headersize; /* 当前链表节点的头部大小(prevrawlensize + lensize),即非数据域的大小 */
unsigned char encoding; /* 编码方式 */
unsigned char *p; /* 压缩链表以字符串的形式保存,该指针指向当前节点起始位置 */
} zlentry;
编码 encoding(ziplist.c 源码第 204 行)
- define ZIP_STR_06B (0 << 6) //长度小于等于 63 字节
- define ZIP_STR_14B (1 << 6) //长度小于等于 16383 字节
- define ZIP_STR_32B (2 << 6) //长度小于等于 4294967295 字节
什么时候使用ziplist 存 储 ?
当 hash 对象同时满足以下两个条件的时候,使用ziplist 编码:
1)所有的键值对的健和值的字符串长度都小于等于64byte (一个英文字母
一 个字节);
2)哈希对象保存的键值对数量小于512个。

/*源码位置:t_hash.c ,当达字段个数超过阈值,使用HT 作为编码*/
if(hashTypeLength(o)> server.hash_max_ziplist_entries)
hashTypeConvert(o,OBJ_ENCODING_HT);
/*源码位置:t_hash.c, 当字段值长度过大,转为HT*/
for(i=start,i<=end,i++){
if(sdsEncodedObject(argv[i])&&
sdslen(argv[i]->ptr)>server.hash_max_ziplist_value)
{
hashTypeConvert(o,OBJ_ENCODING_HT);
break
}
}
一个哈希对象超过配置的阈值(键和值的长度有>64byte ,键值对个数>512 个)时 ,
会转换成哈希表(hashtable )。
listpack
-
Listpack 简介
Listpack是Redis 6.0引入的一种紧凑型存储格式,设计用于高效地存储多个小元素。它是一种连续的内存块,存储了一系列的元素,每个元素的长度和内容紧挨着存储。 -
Listpack的结构
Header: 包含整个Listpack的总长度以及元素的数量。
Entry: 每个元素的前面有一个字节或多个字节来表示该元素的长度,接着是元素本身的数据。
End: 一个特殊的字节(0xFF)标识Listpack的结束。 -
Listpack 在 Hash 中的使用
在Redis中,如果一个Hash比较小(元素数量少且每个元素的大小也比较小),Redis会选择使用Listpack来存储这些数据。具体的阈值可以通过配置项hash-max-ziplist-entries和hash-max-ziplist-value来设置。 -
Listpack 的优点
紧凑存储: Listpack使用连续的内存块,减少了内存碎片,并且由于存储元素的长度是可变的,可以高效地利用内存。
低开销: 对于小数据集,Listpack的内存开销非常低,特别是与普通的Hash表相比,可以显著减少内存使用。
快速访问: 由于Listpack是连续存储的,CPU缓存命中率较高,访问速度较快。
节省内存: Listpack在存储小元素时具有显著的内存节省效果,因为它避免了额外的指针和元数据开销。 -
Listpack 的设计原理
连续内存块: Listpack通过将所有数据紧密地存储在一个连续的内存块中,减少了内存碎片,并且提高了数据访问的局部性。
变长编码: 使用变长编码来存储每个元素的长度,使得Listpack能够高效地存储大小不同的元素。
自描述结构: 每个元素的长度信息与数据紧密结合,使得Listpack可以轻松解析和遍历。
结束标识: 通过特殊的结束字节来标识Listpack的结束,简化了解析逻辑。 -
优势对比
Listpack 优势
更简洁的设计,减少了不必要的指针开销。
更高的内存利用率,适合存储大量小元素。
插入和删除操作更高效,因为不需要更新前向指针。
Ziplist 优势
支持双向遍历,在某些应用场景中可能更加灵活。
hashtable(dict)
在 Redis 中 ,hashtable 被称为字典(dictionary ),它是一个数组+链表的结构。 源码位置:dict.h。前面我们知道了 ,Redis 的 KV 结构是通过一个 dictEntry 来实现的。Redis 又对 dictEntry 进行了多层的封装。
typedef struct dictEntry {
void *key; /* key 关键字定义 */
union {
void *val; uint64_t u64; /* value 定义 */
int64_t s64; double d;
} v;
struct dictEntry *next; /* 指向下一个键值对节点 */
} dictEntry;
dictEntry 放到了 dictht(hashtable 里面)
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
typedef struct dictht {
dictEntry **table; /* 哈希表数组 */
unsigned long size; /* 哈希表大小 */
unsigned long sizemask; /* 掩码大小,用于计算索引值。总是等于 size- 1 */
unsigned long used; /* 已有节点数 */
} dictht;
ht 放到了 dict 里面
typedef struct dict {
dictType*type;
void *privdata;/* 私有数据 */
dictht ht[2];/* 一个字典有两个哈希表*/
long rehashidx;/*rehash 索 引 */
unsigned long iterators;/* 当前正在使用的迭代器数量*/
} dict;
从最底层到最高层 dictEntry——dictht——dict——OBJ_ENCODING_HT
总结hash存储结构
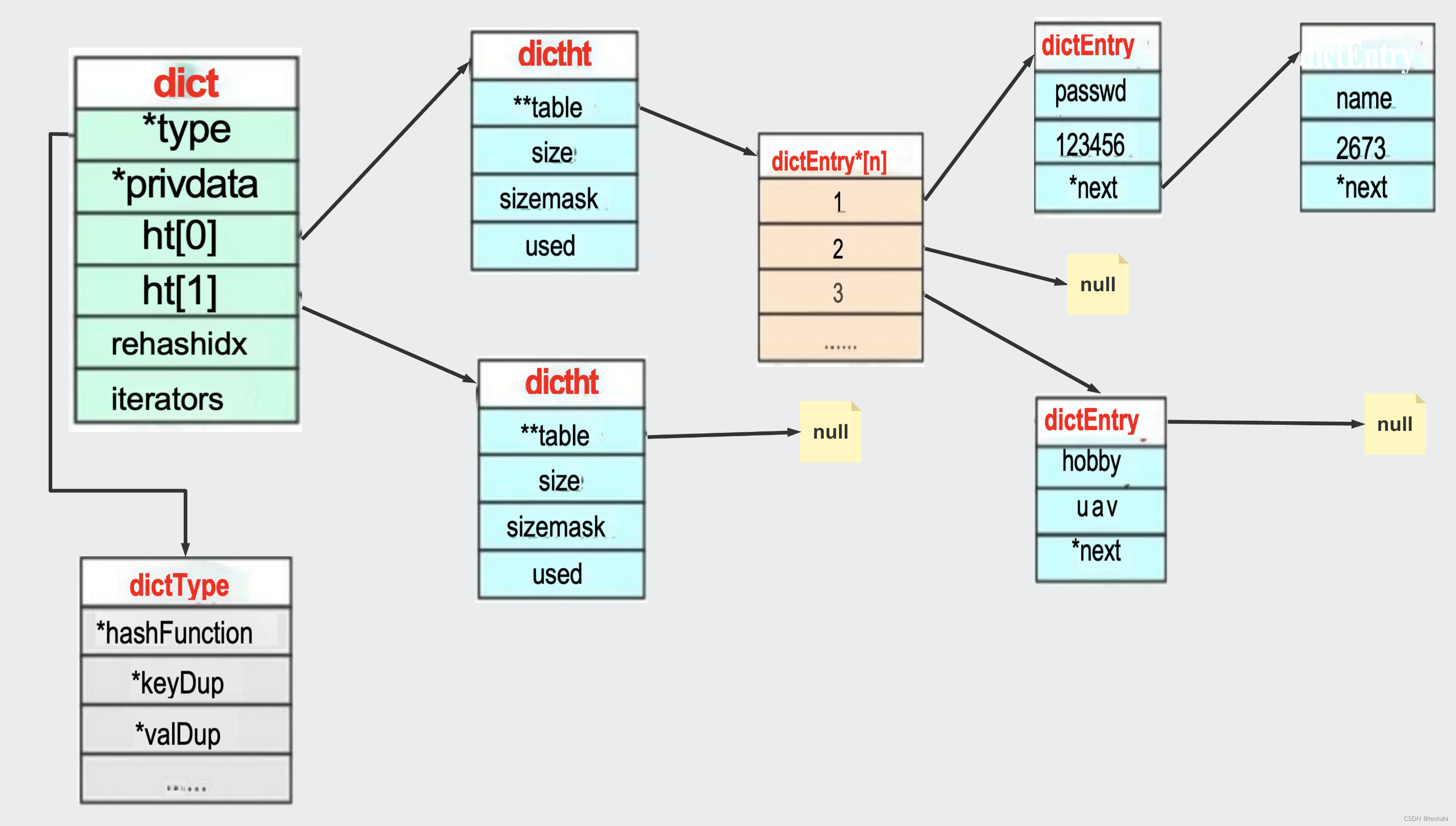
如上图:
- dict
dict就是上面所说的外层hash。 - dictht
dictht就是上文所说的内层hash。
注意:dictht后 面 是NUL 说明第二个ht还没用到。dictEntry*后面是NULL 说明没有hash 到这个地址。dictEntry后面是 NULL说明没有发生哈希冲突。
为什么要定义两个哈希表呢?ht[2]
redis 的 hash 默认使用的是ht[0],ht[1] 不会初始化和分配空间。
哈 希 表dictht 是用链地址法来解决碰撞问题的。在这种情况下,哈希表的性能取决
于它的大小(size 属性)和它所保存的节点的数量(used 属 性 ) 之 间 的 比 率 :
● 比率在1:1时( 一 个哈希表 ht 只存储一个节点entry), 哈希表的性能最好;
● 如果节点数量比哈希表的大小要大很多的话(这个比例用ratio 表示,5表示平均一个 ht 存储 5 个entry ),那么哈希表就会退化成多个链表 ,哈希表本身的性能
优势就不再存在。
在这种情况下需要扩容。 Redis 里面的这种操作叫做 rehash。
rehash 的步骤 :
1、为字符 ht[1]哈希表分配空间 ,这个哈希表的空间大小取决于要执行的操作 ,以
及 ht[0]当前包含的键值对的数量。
扩展 :ht[1]的大小为第一个大于等于 ht[0].used*2。
2、将所有的 ht[0]上的节点 rehash 到 ht[1]上 ,重新计算 hash 值和索引 ,然后放
入指定的位置。
3、 当 ht[0]全部迁移到了 ht[1]之后 ,释放 ht[0]的空间 ,将 ht[1]设置为 ht[0]表 ,
并创建新的 ht[1] ,为下次 rehash 做准备。
什么时候触发扩容?
负载因子( 源码位置:dict.c ):
static int dict_can_resize = 1;
static unsigned int dict_force_resize_ratio = 5;
dict_can_resize 为 1 并且 dict_force_resize_ratio 已使用节点数和字典大小之间的比率超过 1:5 ,触发扩容。
扩容判断 _dictExpandIf Needed(源码 dict.c )
if (d->ht[0].used >= d->ht[0].size &&
(dict_can_resize ||d->ht[0].used/d->ht[0].size > dict_force_resize_ratio))
{
return dictExpand(d, d->ht[0].used*2);
}
return DICT_OK;
扩容方法 dictExpand(源码 dict.c )
static int dictExpand(dict *ht, unsigned long size) {
dict n; /* the new hashtable */
unsigned long realsize = _dictNextPower(size), i;
/* the size is invalid if it is smaller than the number of
* elements already inside the hashtable */
if (ht->used > size)
return DICT_ERR;
_dictInit(&n, ht->type, ht->privdata);
n.size = realsize;
n.sizemask = realsize- 1;
n.table = calloc(realsize,sizeof(dictEntry*));
/* Copy all the elements from the old to the new table:
* note that ifthe old hash table is empty ht->size is zero,
* so dictExpand just creates an hash table. */
n.used = ht->used;
for (i = 0; i < ht->size && ht->used > 0; i++) {
dictEntry *he, *nextHe;
if (ht->table[i] == NULL) continue;
/* For each hash entry on this slot... */
he = ht->table[i];
while(he) {
unsigned int h;
nextHe = he->next;
/* Get the new element index */
h = dictHashKey(ht, he->key) & n.sizemask;
he->next = n.table[h];
n.table[h] = he;
ht->used--;
/* Pass to the next element */
he = nextHe;
}
}
assert(ht->used == 0);
free(ht->table);
/* Remap the new hashtable in the old */
*ht = n;
return DICT_OK;
}
缩容 :server.c
int htNeedsResize(dict *dict) {
long long size, used;
size = dictSlots(dict);
used = dictSize(dict);
return (size > DICT_HT_INITIAL_SIZE &&
(used* 100/size < HASHTABLE_MIN_FILL));
}
应用场景
String
String 可以做的事情 ,Hash 都可以做。
存储对象类型的数据
比如对象或者一张表的数据 ,比 String 节省了更多 key 的空间 ,也更加便于集中管
理。
例如电商平台中的购物车列表数据:
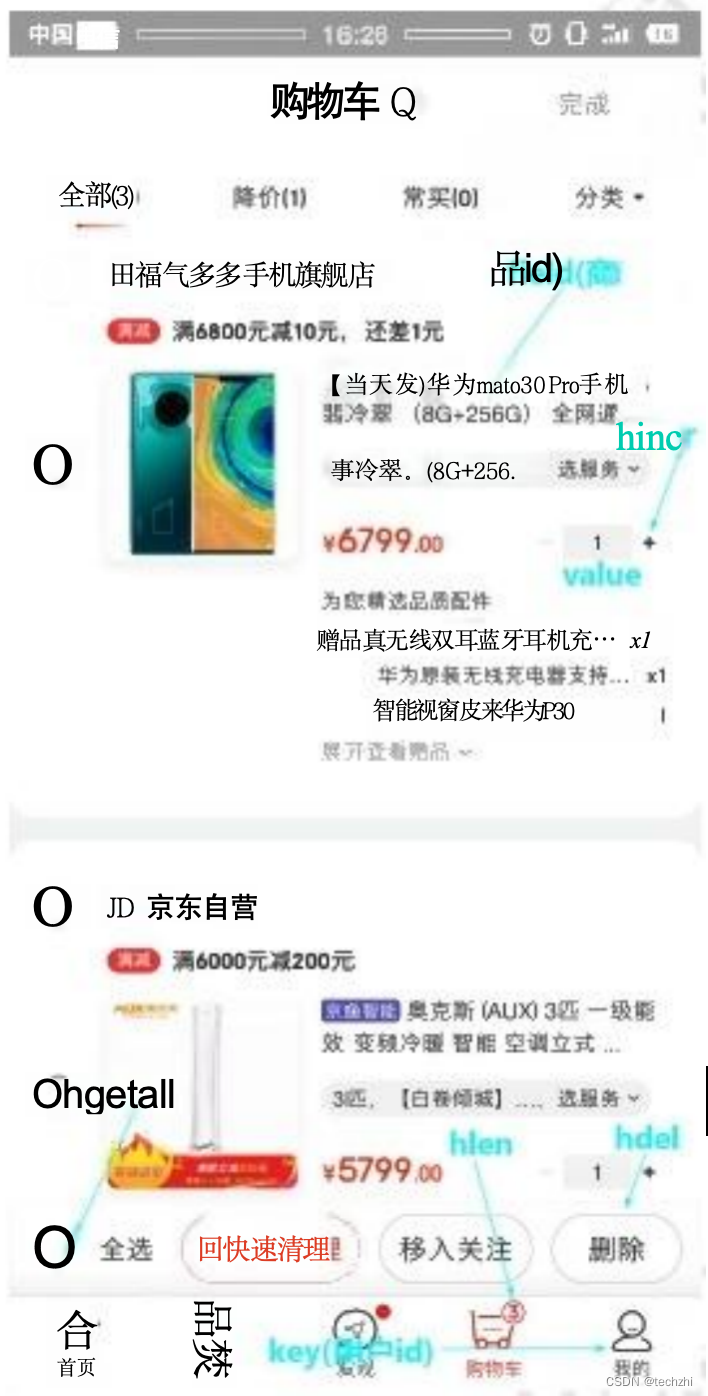
key: 用户id;field: 商品id;value: 商品数量。
+1:hincr 。-1:hdecr 。 删除:hdel。全 选 :hgetall 。商品数:hlen。















 1227
1227











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









