







分词
分词是指将一个中文词语拆成若干个词,提供搜索引擎进行查找,比如说:北京大学 是一个词那么进行拆分可以得到:北京与大学,甚至北京大学整个词也是一个语义
市面上常见的分词工具有 IKAnalyzer MMSeg4j Paoding等
这里我们使用IKAnalyzer分词器
首先解压文件
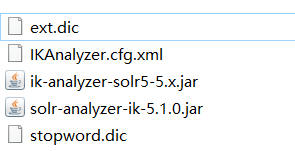
将ikanalyzer-solr5中的两个jar包复制到solr项目的lib中:Solr\apache-tomcat-8.0.39\webapps\solr\WEB-INF\lib
将剩下的三个文件复制到solr项目的WEB-INF\classes下
将solrHome\solr\conf\managed-schema文件中添加
<!-- 定义一个中文分词器类型 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
<!-- 定义字段,name为字段名,type为字段类型,
indexed=true可以使得一个field可以被搜索,如果你设置indexed=false,就算你有符合的数据也无法搜索出来,
stored=true表示是否保存到索引中,意味着你可以在结果中看到这个field,设置为false就表示不存储,结果中也看不到,
multiValued是否多值(配合copyField使用) -->
<field name="goods_name" type="text_ik" indexed="true" stored="true" />
<field name="goods_msg" type="String" indexed="true" stored="true" />
字段就是上边的配置文件里的
<field name="goods_name" type="text_ik" indexed="true" stored="true" />
启动tomcat打开浏览器


有些我们认为是词语的,但是中文分词器却不会以为他是词语,所以我们需要去想办法让他识别他就是词语。
打开apache-tomcat-8.0.39\webapps\solr\WEB-INF\classes
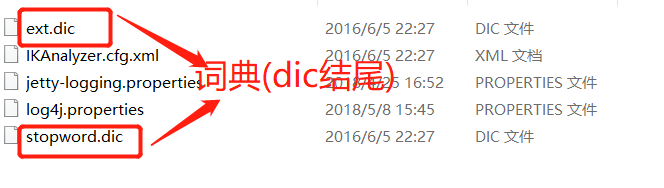
打开ext.dic

打开stopword.dic
 当你修改完你的词语后(自定义分词器) ,再去搜索查看效果。
当你修改完你的词语后(自定义分词器) ,再去搜索查看效果。















 1711
1711











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









