







文章目录
前言:20天吃掉pytorch——学习解读
- 本人将依据《20天吃掉那只pytorch》这个优秀的项目回顾一遍pytorch的基本知识,总结成十个章节
项目地址:https://github.com/lyhue1991/eat_pytorch_in_20_days
思维导图
- 假设转化成tensor数据类型前的数据是data
- 假设转化成tensor数据类型后的数据是tensor_data
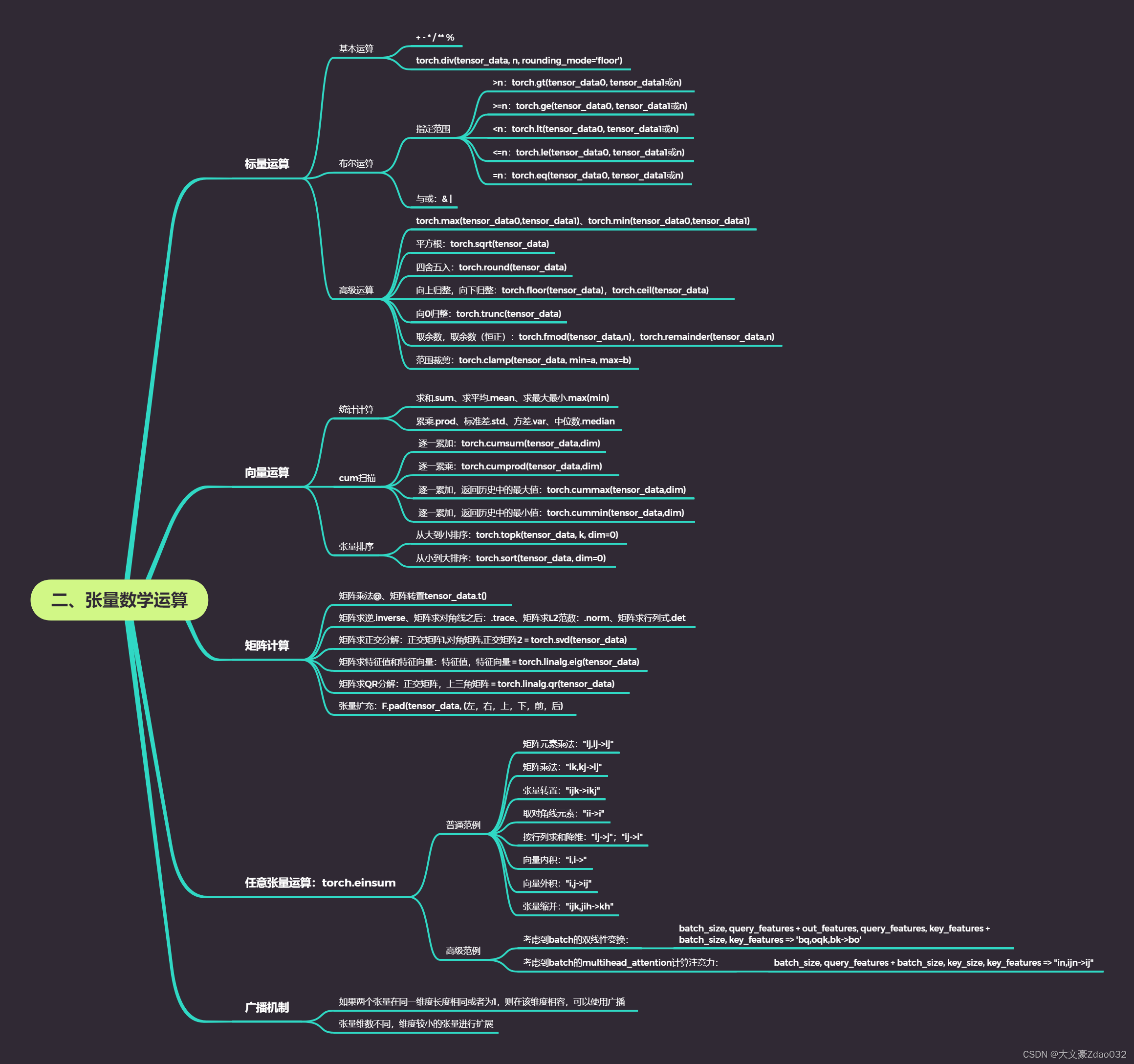
一、标量运算
import torch
import numpy as np
a = torch.tensor([[1.0, 2], [-3, 4.0]])
b = torch.tensor([[5.0, 6], [7.0, 4.0]])
print(a)
print(b)
# 输出
# tensor([[ 1., 2.],
# [-3., 4.]])
# tensor([[5., 6.],
# [7., 4.]])
1.基本运算
print(a + b) # 加
print(a - b) # 减
print(a * b) # 乘
print(a / b) # 除
print(a ** 2) # 幂运算
print(a ** 0.5)
print(a % 3) # 求模
print(torch.div(a, 3, rounding_mode='floor')) # 地板除法
# 输出
# tensor([[6., 8.],
# [4., 8.]])
# tensor([[ -4., -4.],
# [-10., 0.]])
# tensor([[ 5., 12.],
# [-21., 16.]])
# tensor([[ 0.2000, 0.3333],
# [-0.4286, 1.0000]])
# tensor([[ 1., 4.],
# [ 9., 16.]])
# tensor([[1.0000, 1.4142],
# [ nan, 2.0000]])
# tensor([[1., 2.],
# [-0., 1.]])
# tensor([[ 0., 0.],
# [-1., 1.]])
2.布尔运算
print(torch.gt(a, 2)) # >2的元素返回True
print(torch.ge(a, 2)) # >=2的元素返回True
print(torch.lt(a, 2)) # <2的元素返回True
print(torch.le(a, 2)) # <=2的元素返回True
print('-------------------------------')
# 相同元素返回True
print(torch.eq(a, 2)) # print(a==2)
print(torch.eq(a,b)) # 比较ab是否逐元素相同
print('-------------------------------')
print((a>=2)&(a<=3)) # 与
print((a>=2)|(a<=3)) # 或
# 输出
# tensor([[False, False],
# [False, True]])
# tensor([[False, True],
# [False, True]])
# tensor([[ True, False],
# [ True, False]])
# tensor([[ True, True],
# [ True, False]])
# -------------------------------
# tensor([[False, True],
# [False, False]])
# tensor([[False, False],
# [False, True]])
# -------------------------------
# tensor([[False, True],
# [False, False]])
# tensor([[True, True],
# [True, True]])
3.高级运算
print(torch.max(a,b))
print(torch.min(a,b))
print(torch.sqrt(a)) # 平方根
print(torch.round(a)) # 保留整数部分,四舍五入
print(torch.floor(a)) # 保留整数部分,向下归整
print(torch.ceil(a)) # 保留整数部分,向上归整
print(torch.trunc(a)) # 保留整数部分,向0归整
print(torch.fmod(a,2)) # 作除法取余数
print(torch.remainder(a,2)) # 作除法取剩余的部分,结果恒正
print(torch.clamp(a, min=-1, max=1)) # 范围裁剪
# 输出
# tensor([[5., 6.],
# [7., 4.]])
# tensor([[ 1., 2.],
# [-3., 4.]])
# tensor([[1.0000, 1.4142],
# [ nan, 2.0000]])
# tensor([[ 1., 2.],
# [-3., 4.]])
# tensor([[ 1., 2.],
# [-3., 4.]])
# tensor([[ 1., 2.],
# [-3., 4.]])
# tensor([[ 1., 2.],
# [-3., 4.]])
# tensor([[ 1., 0.],
# [-1., 0.]])
# tensor([[1., 0.],
# [1., 0.]])
# tensor([[ 1., 1.],
# [-1., 1.]])
二、向量运算
- 只在一个特征维度上的运算,将一个向量映射到一个标量或者另一个向量
a = torch.tensor([[ 1., 2.], [-3., 4.]])
b = torch.tensor([[5., 6.], [7., 4.]])
1.统计计算
print(torch.sum(a))
print(torch.mean(a))
print(torch.max(a, dim=0)) # "["从外到内,这里的第0个dim为最外围的"["
print(torch.min(a, dim=1))
print(torch.prod(a)) # 累乘
print(torch.std(a)) # 标准差
print(torch.var(a)) # 方差
print(torch.median(a)) # 中位数
# 输出
# tensor(4.)
# tensor(1.)
# torch.return_types.max(values=tensor([1., 4.]), indices=tensor([0, 1]))
# torch.return_types.min(values=tensor([ 1., -3.]), indices=tensor([0, 0]))
# tensor(-24.)
# tensor(2.9439)
# tensor(8.6667)
# tensor(1.)
2.cum扫描
a = torch.tensor([1,2,3,4,5,6,-1,-2,7,8,9])
print(torch.cumsum(a,dim=0)) # 累加
print(torch.cumprod(a,dim=0)) # 累乘
# torch.cummax(input, dim):返回(values, indices)
# values是累加过程中的最大值(与历史比较)
# indices为每个最大值的索引位置
print(torch.cummax(a,0).values)
print(torch.cummax(a,0).indices)
print(torch.cummin(a,0))
# 输出
# tensor([ 1, 3, 6, 10, 15, 21, 20, 18, 25, 33, 42])
# tensor([1, 2, 6, 24, 120, 720, -720, 1440, 10080, 80640, 725760])
# tensor([1, 2, 3, 4, 5, 6, 6, 6, 7, 8, 9])
# tensor([0, 1, 2, 3, 4, 5, 5, 5, 8, 9, 10])
# torch.return_types.cummin(values=tensor([ 1, 1, 1, 1, 1, 1, -1, -2, -2, -2, -2]), indices=tensor([0, 0, 0, 0, 0, 0, 6, 7, 7, 7, 7]))
3.张量排序
a = torch.tensor([[9,7,8],[1,3,2],[5,6,4]]).float()
# 从大到小排序
print(torch.topk(a, k=3, dim=0).values) # k: 对前k个排序
print(torch.topk(a, k=3, dim=0).indices)
# 从小到大排序
print(torch.sort(a, dim=0).values)
print(torch.sort(a, dim=0).indices)
# 输出
# tensor([[9., 7., 8.],
# [5., 6., 4.],
# [1., 3., 2.]])
# tensor([[0, 0, 0],
# [2, 2, 2],
# [1, 1, 1]])
# tensor([[1., 3., 2.],
# [5., 6., 4.],
# [9., 7., 8.]])
# tensor([[1, 1, 1],
# [2, 2, 2],
# [0, 0, 0]])
三、矩阵运算
a = torch.tensor([[1,2],[3,4]])
b = torch.tensor([[2,0],[0,2]])
c = torch.tensor([[1.0,2], [3,4]])
print(a@b) # 矩阵乘法,等价于torch.mm(a,b)
print(a.t()) # 矩阵转置
print(torch.inverse(c)) # 矩阵求逆,必须有浮点类型元素
print(torch.trace(c)) # 矩阵求trace,即对角线之和
print(torch.norm(c)) # 矩阵求L2范数,即元素的平方和再开平方根,必须有浮点数
print(torch.det(c)) # 矩阵求行列式,即ad-bc(二阶)
# 输出
# tensor([[2, 4],
# [6, 8]])
# tensor([[1, 3],
# [2, 4]])
# tensor([[-2.0000, 1.0000],
# [ 1.5000, -0.5000]])
# tensor(5.)
# tensor(5.4772)
# tensor(-2.0000)
d = torch.tensor([[4,2,-5], [6,4,-9], [5,3,-7]], dtype = torch.float)
e = torch.tensor([[1.0, 2.0], [3.0, 4.0]])
u,s,v = torch.svd(e) # 矩阵U(正交矩阵1)S(对角阵)V(正交矩阵2)分解
print(torch.linalg.eig(d)) # 矩阵求特征值和特征向量
print(torch.linalg.qr(e)) # 矩阵Q(正交矩阵,矩阵*矩阵_T=E)R(上三角矩阵)分解
import torch.nn.functional as F
# 张量扩充:F.pad(左填充,右填充,上填充,下填充,前填充,后填充)
print(u@F.pad(torch.diag(s),(0,0,0,0))@v.t())
# 输出
# torch.return_types.linalg_eig(
# eigenvalues=tensor([1.0000e+00+0.0000j, 2.5273e-07+0.0007j, 2.5273e-07-0.0007j]),
# eigenvectors=tensor([[-0.5774+0.0000j, 0.2673-0.0002j, 0.2673+0.0002j],
# [-0.5773+0.0000j, 0.8018+0.0000j, 0.8018-0.0000j],
# [-0.5774+0.0000j, 0.5345-0.0002j, 0.5345+0.0002j]]))
# torch.return_types.linalg_qr(
# Q=tensor([[-0.3162, -0.9487], [-0.9487, 0.3162]]),
# R=tensor([[-3.1623, -4.4272], [ 0.0000, -0.6325]]))
# tensor([[1.0000, 2.0000], [3.0000, 4.0000]])
四、任意张量运算:torch.einsum
- 利用元素计算公式来表达张量运算
- 只出现在元素计算公式一边(左边)的指标为哑指标,省略元素计算公式中对哑指标的求和
- 出现在元素计算公式两边的指标为自由指标
1.普通范例
a = torch.tensor([[1,2],[3,4.0]])
b = torch.tensor([[5,6],[7,8.0]])
c = torch.randn(3,4,5)
d = torch.tensor([1,2,3])
e = torch.tensor([3,2,1])
f = torch.randn(4,3,6)
print(torch.einsum("ij,ij->ij", a,b)) # 矩阵元素乘法,a*b
print(torch.einsum("ik,kj->ij", a,b)) # 矩阵乘法,a@b
print(torch.einsum("ijk->ikj", c).shape) # 张量转置,torch.permute(c,[0,2,1])
print(torch.einsum("ii->i", a)) # 取对角线元素, torch.diagonal(a)
print(torch.einsum("ij->i", a)) # 按列求和降维,torch.sum(a, dim=1)
print(torch.einsum("ij->j", a)) # 按行求和降维,torch.sum(a, dim=0)
print(torch.einsum("i,i->", d,e)) # 向量内积,torch.dot(d,e)
print(torch.einsum("i,j->ij", d,e)) # 向量外积,torch.outer(d,e)
print(torch.einsum("ijk,jih->kh", c,f).shape) # 张量缩并,torch.tensordot(c,f,dims=[(0,1),(1,0)])
# 输出
# tensor([[ 5., 12.],
# [21., 32.]])
# tensor([[19., 22.],
# [43., 50.]])
# torch.Size([3, 5, 4])
# tensor([1., 4.])
# tensor([3., 7.])
# tensor([4., 6.])
# tensor(10)
# tensor([[3, 2, 1],
# [6, 4, 2],
# [9, 6, 3]])
# torch.Size([5, 6])
2.高级范例
2.1考虑到batch的双线性变换
# 双线性变换: A = q @ W @ k_t + b
q = torch.randn(10) # query_features
k = torch.randn(10) # key_features
W = torch.randn(5,10,10) # out_features, query_features, key_features
b = torch.randn(5) # out_features
print(torch.bilinear(q,k,W,b).shape) # # out_features
# 考虑到batch
q_batch = torch.randn(5, 10) # batch_size, query_features
k_batch = torch.randn(5, 10) # batch_size, key_features
print((torch.einsum('bq,oqk,bk->bo', q_batch, W, k_batch) + b).shape) # batch_size, query_features
# 输出
# torch.Size([5])
# torch.Size([5, 5])
2.2考虑到batch的multihead_attention计算注意力
# multihead_attention计算注意力: softmax((a@k_t)/d_k)
q = torch.randn(10) # query_features
k = torch.randn(6,10) # key_size, key_features
d_k = k.shape[-1]
print(torch.softmax(q@k.t()/d_k, -1).shape)
# 考虑到batch
q_batch = torch.randn(5, 10) # batch_size, query_features
k_batch = torch.randn(5, 6, 10) # batch_size, key_size, key_features
d_k_batch = k_batch.shape[-1]
print(torch.softmax(torch.einsum("in,ijn->ij", q_batch, k_batch)/d_k_batch,-1).shape)
# 输出
# torch.Size([6])
# torch.Size([5, 6])
五、广播机制
- 如果两个张量在同一维度长度相同或者为1,则在该维度相容,可以使用广播
- 张量维数不同,维度较小的张量进行扩展
# 广播运算过程
a = torch.tensor([1,2,3])
b = torch.tensor([[0,0,0],[1,1,1],[2,2,2]])
a_broad,b_broad = torch.broadcast_tensors(a,b)
print(a_broad,"\n")
print(b_broad,"\n")
print(a_broad + b_broad)
# 输出
# tensor([[1, 2, 3],
# [1, 2, 3],
# [1, 2, 3]])
# tensor([[0, 0, 0],
# [1, 1, 1],
# [2, 2, 2]])
# tensor([[1, 2, 3],
# [2, 3, 4],
# [3, 4, 5]])
总结
如有错误或不足的地方,请评论区指出,本人认真修改,谢谢~!















 1339
1339











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









