







1.含义
当有多个纯数字特征或因素参与分析,而有的因素之间很有关联,就可以采用主成分分析法来降维处理,将高维数据转换为低维数据,降低分析的复杂度,有效解决冗余特征带来的多重共线性问题。如下面这种表:
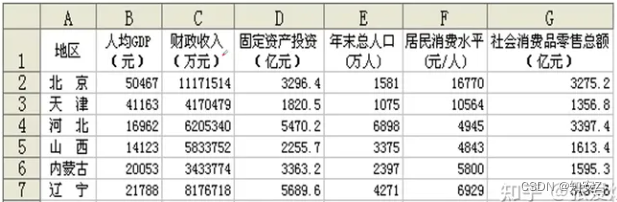 、
、
数学建模中经常给个表里面有很多列,几十列,这样不好分析,需要将其降维降成几列。
2.输入输出:
- 输入:多个数值型的数据
- 输出:降维后的数据,具体还剩几维都是,看累计贡献度什么时候>80%,具体百分之几看情况而定。它的输出不再是输入的那些变量了,而是综合这些变量产生的新变量。
-
-
3.适用范围:
- 可以计算权重,给每一行一个综合的得分
- 样本量必须大!
-
4.代码
相关数据表及python代码:
链接:https://pan.baidu.com/s/1qjbnYCoOEMXoutX9nmv0fg
提取码:uk53
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
# 设置中文字体
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
# 读取数据read_excel,read_csv
df = pd.read_excel(r'C:\Users\zhanyu\Desktop\data\豆瓣电影数据clean.xlsx')
df = df[:][['投票人数','时长','年代','评分']]
df.head()
# 设置可以展示多少数据,不加数据看不完整
pd.set_option('display.max_columns',100)
pd.set_option('display.max_rows',500)
# 标准化数据
scaler = StandardScaler()
df = scaler.fit_transform(df)
pca=PCA(n_components=4, svd_solver='full') # n_components指定保留的主成分个数,mle会自动选择最合适的个数
# 主成分分析
pca.fit(df)
# 获得主成分及主成分个数
components = pca.components_
n_components = pca.n_components_
# 降维后的数据
transformed_data = pca.transform(df)
# 打印结果
print("主成分个数:",pca.n_components_)
print("主成分:")
print(pca.components_)
print('各主成份贡献率(可以作为权重)',pca.explained_variance_ratio_)
print('累计贡献率',np.cumsum(pca.explained_variance_ratio_)[-1])
print("降维后的数据:")
print(transformed_data)
# 获得降维后的数据
reduced_df = pd.DataFrame(data=transformed_data, columns=['主成分1', '主成分2','主成分3','主成分4'])[['主成分1', '主成分2','主成分3']]
reduced_df.to_excel(r'C:\Users\zhanyu\Desktop\data\主成分分分析.xlsx')
相关图表的绘制:
# 可视化-碎石图
plt.figure(figsize=(8, 6))
plt.plot(range(1, len(pca.explained_variance_ratio_) + 1), pca.explained_variance_, marker='o', linestyle='--')
plt.xlabel('主成分数量')
plt.ylabel('特征值')
plt.title('PCA 碎石图')
plt.grid()
plt.show()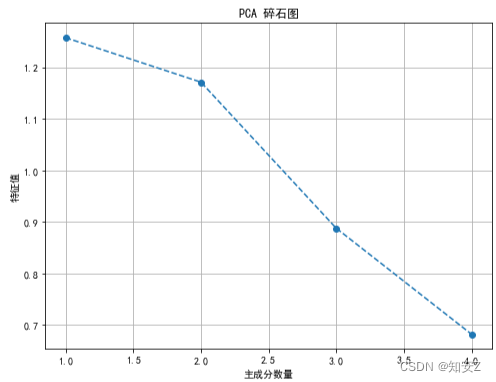
# 因子得分系数矩阵(载荷矩阵与各主成分贡献率相乘):可以作为后续每个元素的权重
weighted_loadings = loadings_df * pca.explained_variance_ratio_[:, np.newaxis]
weighted_loadings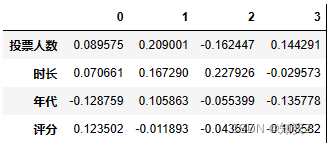
注:这里仅有一个主成分分析模型,也可以多个评分模型,总分=权重x值+权重x值...















 296
296











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









