







推荐阅读:通信的数学理论
数据编码
编码
在网络中进行信息传递,所有信息都是01010的二进制编码格式,例如这样一封信,信中只有狗,猫,鱼,鸟四个词

信的所有内容就是这4个词的组合。
第一封信写着"狗猫鱼鸟",第二封信写"鱼猫鸟狗"。
信件需要二进制编码,在互联网传递。两个二进制位就可以表示四个词汇。
狗 00
猫 01
鱼 10
鸟 11
所以,第一封信"狗猫鱼鸟"的编码是00011011,第二封信"鱼猫鸟狗"的编码是10011100。
压缩
考虑这样一封信
狗狗狗狗猫猫鱼鸟
上面这封信,用前一节的方法进行编码。
0000000001011011
一共需要16个二进制。互联网的流量费很贵,有没有可能找到一种更短编码方式?
很容易想到,"狗"的出现次数最多,给它分配更短的编码,就能减少总的长度。请看下面的编码方式。
狗 0
猫 10
鱼 110
鸟 111
注意不管如何编码,都需要保证任意编码不是其他编码的前缀(哈夫曼编码)。
使用新的编码方式,"狗狗狗狗猫猫鱼鸟"编码如下。
00001010110111
这时只需要14个二进制位,相当于把原来的编码压缩了12.5%。
根据新的编码,每个词只需要1.75个二进制位(14 / 8)。可以证明,这是最短的编码方式,不可能找到更短的编码。
信息熵
编码与概率
概率越大,所需要的二进制位越少。
狗的概率是50%,表示每两个词汇里面,就有一个是狗,因此单独分配给它1个二进制位。
猫的概率是25%,分配给它两个二进制位。
鱼和鸟的概率是12.5%,分配给它们三个二进制位。
香农给出了一个数学公式。
一般来说,在均匀分布的情况下,假定一个字符(或字符串)在文件中出现的概率是p,那么在这个位置上最多可能出现1/p种情况。需要log2(1/p)个二进制位表示替代符号。
这个结论可以推广到一般情况。
用L表示所需要的二进制位,p(x)表示发生的概率,它们的关系如下。

通过上面的公式,可以计算出某种概率的结果所需要的二进制位。举例来说,"鱼"的概率是0.125,它的倒数为8, 以 2 为底的对数就是3,表示需要3个二进制位。
知道了每种概率对应的编码长度,就可以计算出一种概率分布的平均编码长度(期望值)。

上面公式的H,就是该种概率分布的平均编码长度。理论上,这也是最优编码长度,不可能获得比它更短的编码了。
接着上面的例子,看看这个公式怎么用。小张养狗之前,"狗猫鱼鸟"是均匀分布,每个词平均需要2个二进制位。
H = 0.25 x 2 + 0.25 x 2 + 0.25 x 2 + 0.25 x 2
= 2
养狗之后,"狗猫鱼鸟"不是均匀分布,每个词平均需要1.75个二进制位。
H = 0.5 x 1 + 0.25 x 2 + 0.125 x 3 + 0.125 x 3
= 1.75
既然每个词是 1.75 个二进制位,"狗狗狗狗猫猫鱼鸟"这8个词的句子,总共需要14个二进制位(8 x 1.75)。
信息与压缩
很显然,不均匀分布时,某个词出现的概率越高,编码长度就会越短。
从信息的角度看,如果信息内容存在大量冗余,重复内容越多,可以压缩的余地就越大。日常生活的经验也是如此,一篇文章翻来覆去都是讲同样的内容,摘要就会很短。反倒是,每句话意思都不一样的文章,很难提炼出摘要。
图片也是如此,单调的图片有好的压缩效果,细节丰富的图片很难压缩。
由于信息量的多少与概率分布相关,所以在信息论里面,信息量被定义成不确定性的相关概念:概率分布越分散,不确定性越高,信息量越大;反之,信息量越小。
定义上文中的L为信息量,H为信息熵
即对于一个集合D(在上文中这个集合是一整封信),共有n种可能的值x1 ~ xn,每种取值出现的概率为p1 ~ pn ,则信息熵为
H
(
D
)
=
−
∑
n
i
=
1
p
x
i
l
o
g
2
p
x
i
H(D) = - \sum_{n}^{i=1} p_{x_{i}} log_{2}p_{x_{i}}
H(D)=−n∑i=1pxilog2pxi
抛硬币的信息熵如图:
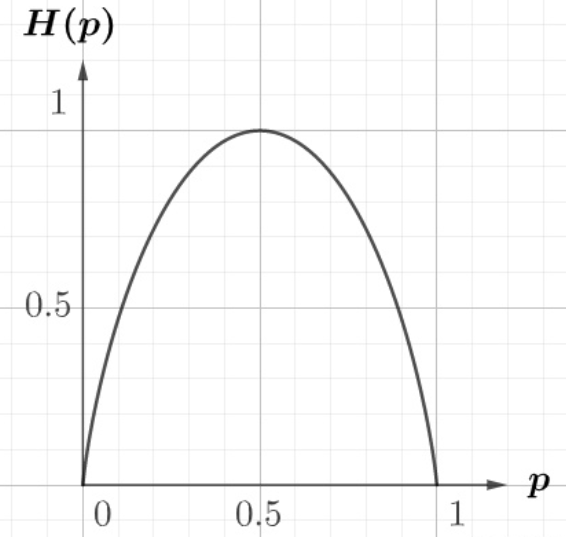
从该函数图像可以看出,p=0.5 时,熵最大,此时确定性最低;而p=1熵最小,此时确定性最高。
信息熵满足这样的性质:
【性质1】H关于pi是连续的。
【性质2】如果事件发生的概率相等,即pi = 1/n。那么事件越多不确定越大,即熵越大。因此, H是关于n的递增函数。
【性质3】如果事件发生可被分解为连续两个事件的发生,则原来事件的 H 应当是这两个事件的 H 的加权和。
例
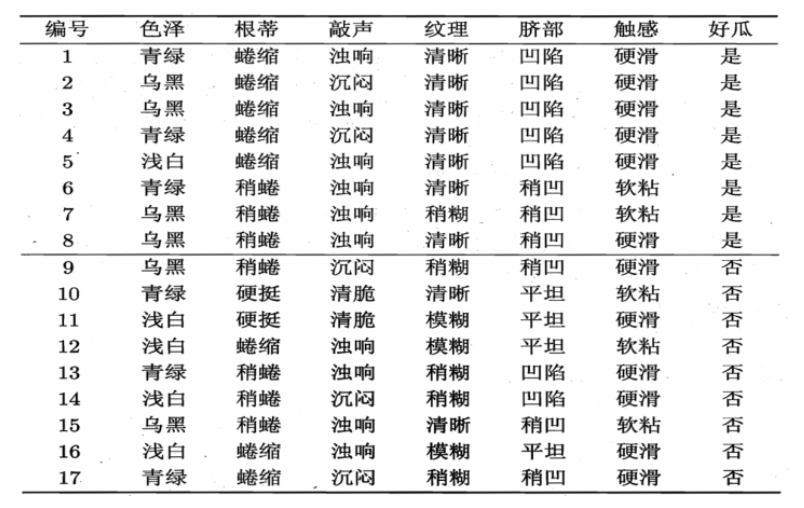
以瓜好坏作为标签,在这个瓜的集合中,好瓜占8/17,坏瓜占9/17,该集合的信息熵为:

决策树
基本思想
决策树就是不断选择特征值划分集合的过程,结构如下
根节点我们拥有整个训练集,每层选择一个特征作为划分特征,大集合划分为一个个小集合,直到集合中只有一种值为止(只有好瓜/只有坏瓜)。
那么根据什么选择分割特征最优呢,贪心地想,我们当然希望划分之后子树的“纯度”越高越好,即更多地属于同一类。
依据每层根据什么度量选择哪个特征值,分为ID3算法:信息增益,C4.5算法:信息增益率,CART算法:基尼系数
ID3算法:信息增益
信息增益通俗理解就是,对于特征X,在该维度数据有n种取值xi~xn,我们按照特征X的取值对于大集合进行划分成n个小集合之后,
信息增益 = 大集合的信息熵 - 小集合的信息熵之和
信息增益反应了当前特征对于不确定性减小的贡献,即信息增益越大,熵减小越大,不确定性减小越大,纯度越高,即更多的属于同一类。
对于上节的例子,对于“色泽”,计算他的信息增益的过程如下
D1(色泽=青绿) = {1, 4, 6, 10, 13, 17},正例 3/6,反例 3/6
D2(色泽=乌黑) = {2, 3, 7, 8, 9, 15},正例 4/6,反例 2/6
D3(色泽=浅白) = {5, 11, 12, 14, 16},正例 1/5,反例 4/5
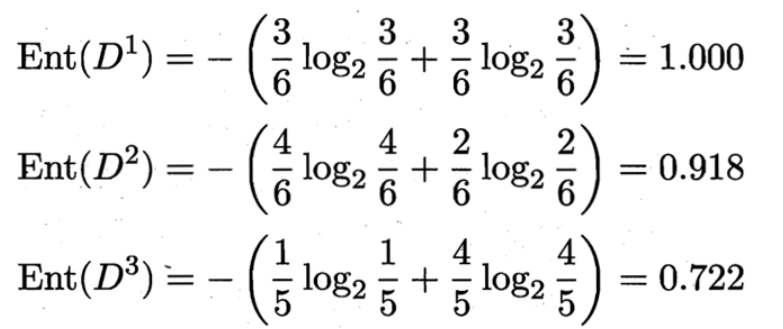
那么我们可以知道属性色泽的信息增益是:
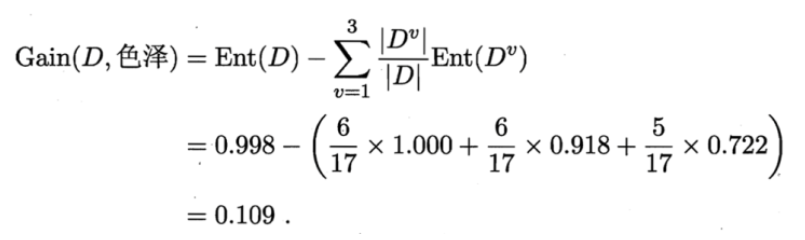
同理,我们可以求出其它属性的信息增益,分别如下:

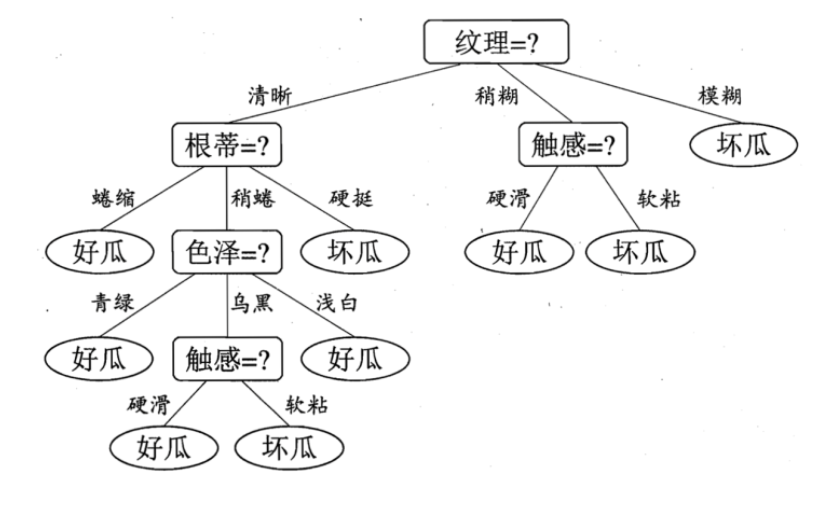
于是我们找到了信息增益最大的属性纹理,它的Gain(D,纹理) = 0.381最大。
于是我们选择的划分属性为“纹理”
如下:
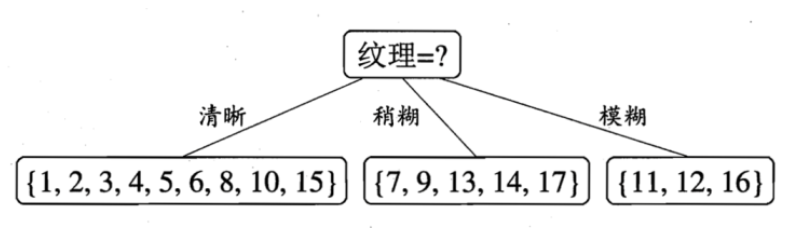
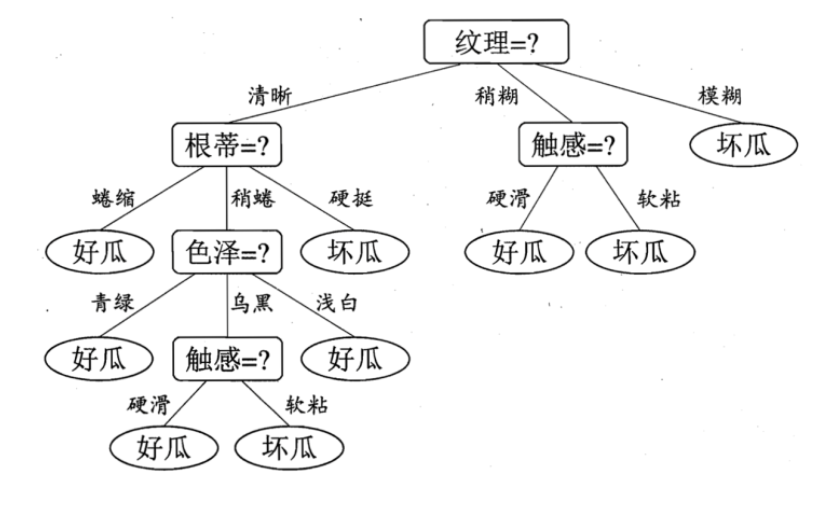
于是,我们可以得到了三个子结点,对于这三个子节点,我们可以递归的使用刚刚找信息增益最大的方法进行选择特征属性,我们最终的决策树如下:
C4.5算法:信息增益率
还没写
还有个剪枝也没写














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









