






文章目录
一.一些建议
逻辑主要还是重在练习,平时交流的时候就要注意
画图常用工具:visio
排版:用word,排的时候可以找一个模板文章。

画图的话,建议先完成大框架,再细化。
| 1.摘要第一句话:点明问题+本文技术(解决的问题) |
|---|
| 2.讲论文中的公式时,先解释变量所代表的含义。(也更偏向于公式) |
| 3.要明白公式所代表的深层含义。 |
二.深度学习
深度学习的概念源于人工神经网络的研究,含多个隐藏层的多层感知器就是一种深度学习结构。深度学习通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示。研究深度学习的动机在于建立模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像,声音和文本等。
1.神经网络
人工神经网络(Artificial Neural Networks,简写为ANNs)也简称为神经网络(NNs)或称作连接模型(Connection Model),它是一种模仿动物神经网络行为特征,进行分布式并行信息处理的算法数学模型。这种网络依靠系统的复杂程度,通过调整内部大量节点之间相互连接的关系,从而达到处理信息的目的。
1.1举例理解
如下示例:
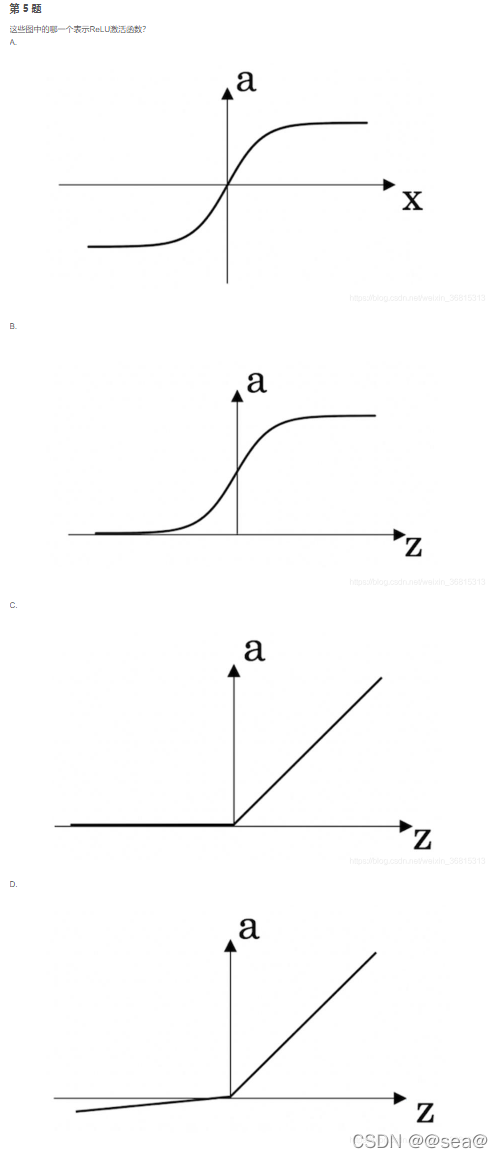
LeRU:线性整流函数(Linear rectification function),又称修正线性单元,是一种人工神经网络中常用的激活函数(activation function),通常指代以斜坡函数及其变种为代表的非线性函数。
修正(rectify):指的是取不小于0的指
更大的神经网络就是把这些单个神经元堆叠起来的(可以将单个神经元想像成乐高的积木,可以通过搭积木来构建一个更大饿神经网络),举例如下:
输入层 -------------------------------中间层-------------------输出层
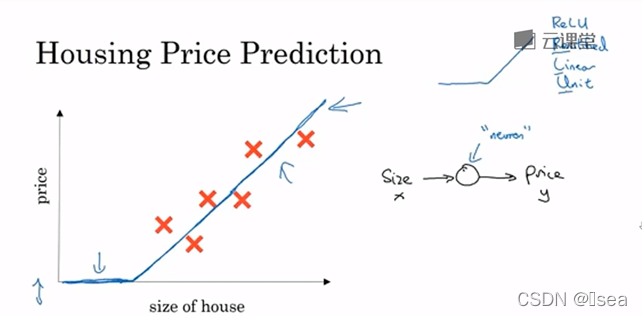
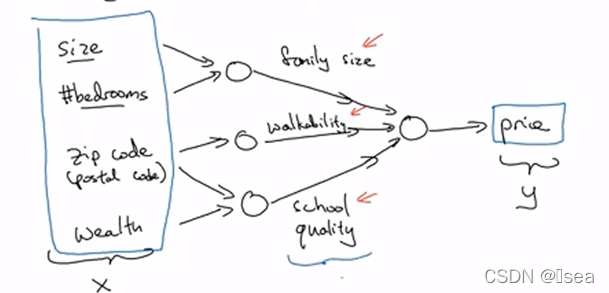
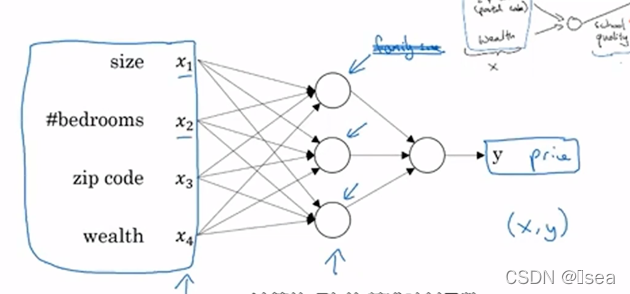
当神经网络建立完成后,只需要输入x,则可以直接得到y,中间的所有过程都自己完成. 只要给予足够多的训练样本(这里就是(x, y),神经网络非常擅于计算从x到y的精准映射函数)
2.监督学习
监督学习是从标记的训练数据来推断一个功能的机器学习任务。训练数据包括一套训练示例。在监督学习中,每个实例都是由一个输入对象(通常为矢量)和一个期望的输出值(也称为监督信号)组成。监督学习算法是分析该训练数据,并产生一个推断的功能,其可以用于映射出新的实例。
3.神经网络的应用
- 按照应用场景分类
房地产推荐(根据地段、价格、步行率等因素进行推荐)、在线广告推荐、图片标记、语音识别、机器翻译、自动驾驶。
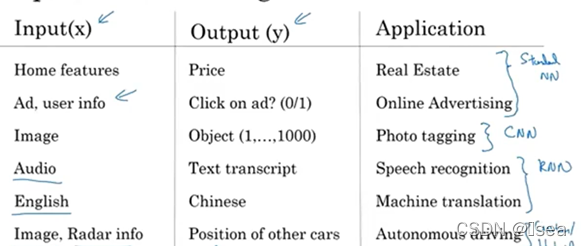
- 按照数据类型分类
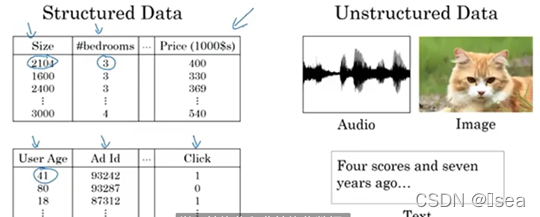
可以处理结构化数据以及非结构化数据。结构化数据,例如数据库中的table;非结构化数据,例如音频、视频、文本等等。
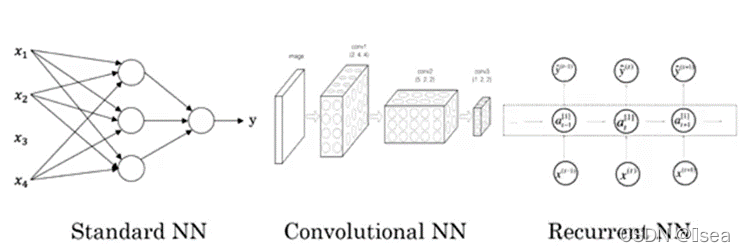
4.标准、卷积、循环神经网络
CNN:卷积神经网络
RNN:循环神经网络(适用于序列数据,例如音频)
三种神经网路的结构如下所示。
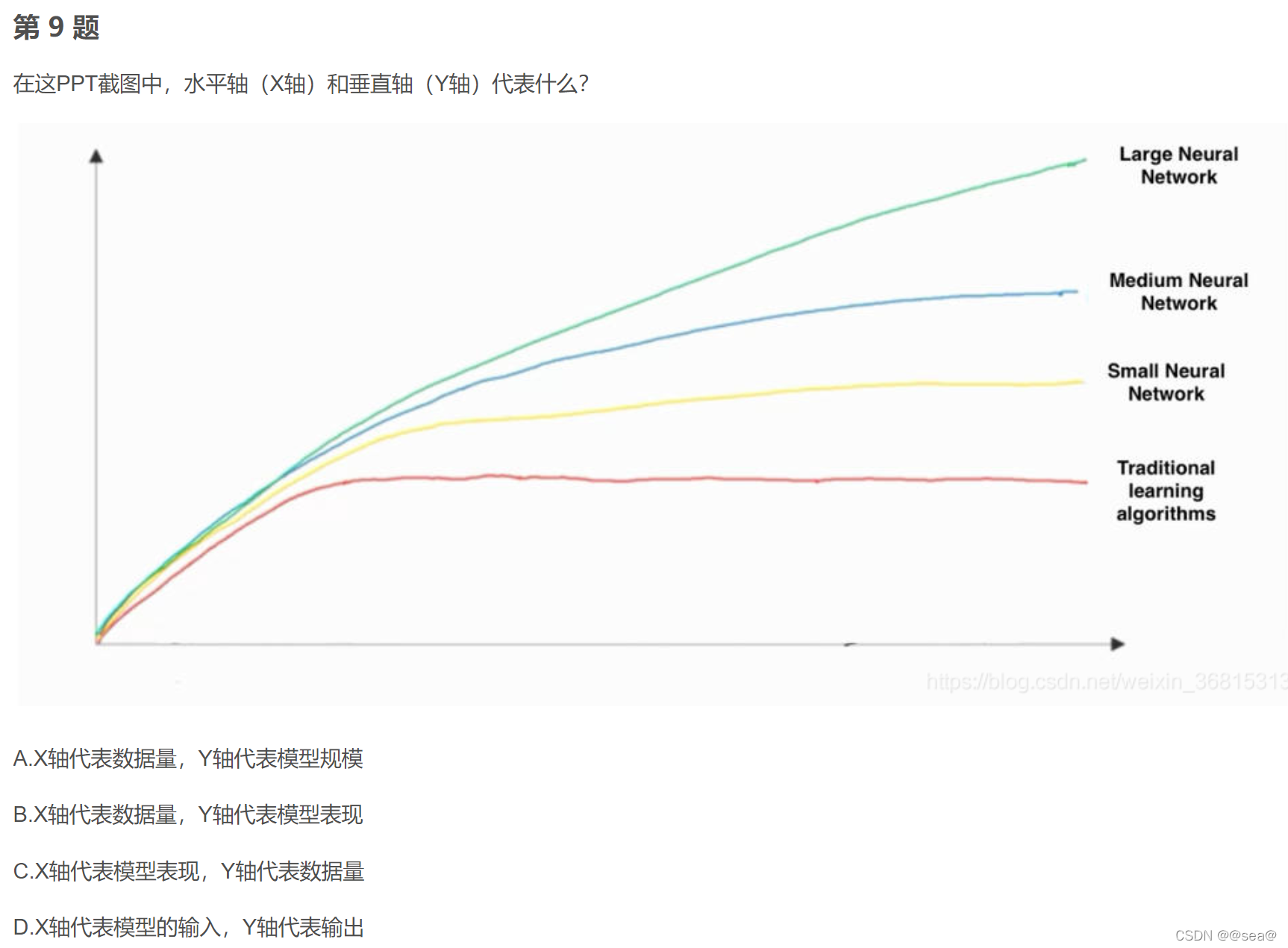
5.深度学习的兴起
规模一直在推动深度学习的进步。这里包括带标签数据的规模以及神经网络的规模(许多的隐藏单元、参数以及连接)。
不同的算法也能够提高速度或训练足够大的神经网络。
6.二分分类
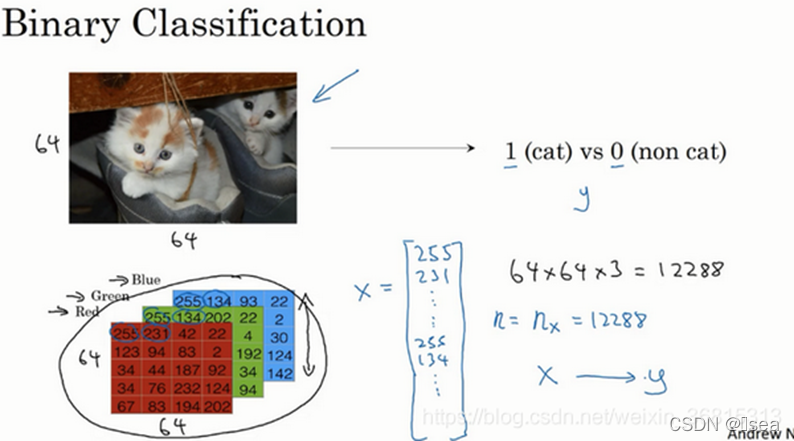
二分类问题中,我们的目标就是习得一个分类器,它以图片的特征向量作为输入,然后预测输出 y结果为1还是0。
6.1举例理解
如下示例::识别图片,输入一张图片,如果识别这张图片为猫则输出1,否则输出0.
计算机保存一张图片,需要保存三个矩阵,如上图中所示(假设每个矩阵是64*64)。为了把这些像素值放到一个特征向量中,我们需要把这些像素值提取出来,然后放入一个特征向量x。
7.Logisitc Regression(逻辑回归)
对于一个二分类的问题来说,给定一个输入X,例如图片。想要通过算法知道这张图片是猫的几率是多少。同时引入参数w以及b,其中w表示逻辑回归的参数,是一个n_x维的向量;而b是一个实数,表示偏差。
根据以上两个参数,很容易想到构建一个线性方程,即:
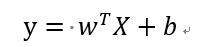
但是这显然是不合理的,因为最后得到的结果应该在0~1之间,而该方程最后得到的结果有可能是大于1或小于0。所以要为其加上一个sigmoid函数:
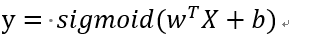
sigmoid函数为:
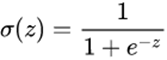
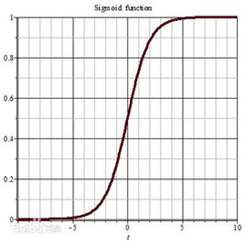
sigmoid函数的图像如下:
7.1损失函数与成本函数
它们可以用来衡量算法的运行情况,衡量预测值与实际值的接近程度。
7.1.1损失函数
一种loss函数是如下图中蓝色部分所示。当y=1时,如果想要损失函数的值尽量小,那-logy ̂就需要尽量小,logy ̂则需要尽量大,又因为y ̂的取值范围是0~1,所以y ̂的值就要接近1。当y = 0时同理。
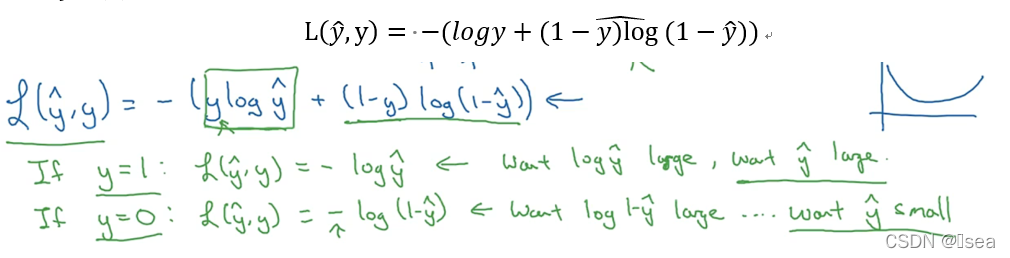
7.1.1成本函数
衡量的是在全体训练样本上的表现,具体适用于单个训练样本。具体如下:
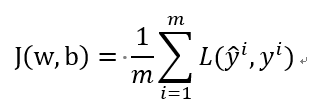
所以在训练logisitc回归模型时,需要找到合适的参数w以及b,让cost函数的值J尽量的小。
8.梯度下降法
训练或学习训练集上的参数w以及b 。需要找到合适的参数 以及 ,以使cost函数尽可能的小。
为了便于理解,此处使 以及 都是实数,则根据以下两个公式,则可以得到下图。
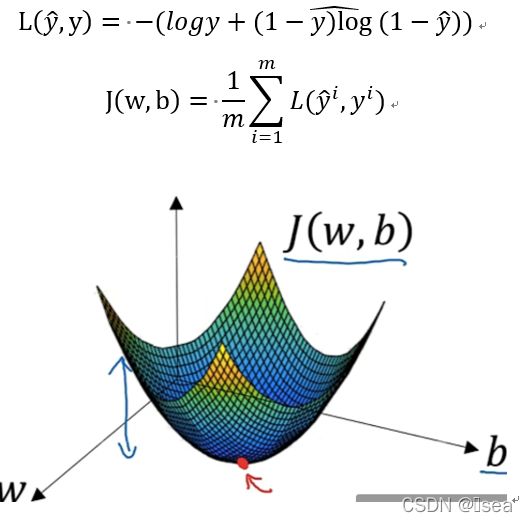
下降过程(简易理解)
1.可以用如图那个小红点来初始化参数 以及 ,也可以采用随机初始化的方法,对于逻辑回归几乎所有的初始化方法都有效,因为函数是凸函数,无论在哪里初始化,应该达到同一点或大致相同的点。
2.朝最陡的下坡方向下降一步并迭代。
3.走到全局最优解或者接近全局最优解的地方。
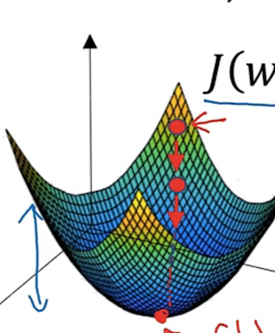
8.1举例理解
为了方便理解,这里有一个参数,为一维曲线。
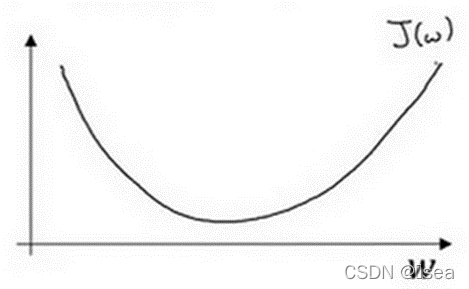
迭代过程就是重复的进行下面公式中的操作,反应在图中就是向下走(从左到右,从右到左都是这样)
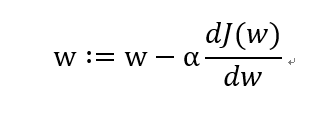
:=: 更新参数
其中α是学习率,用来控制步长,即向下走一步的长度(dJ(w))/dw就是J(w)对w求导,用dw来表示这个结果。
如果含有两个参数w以及b,则公式如下所示:
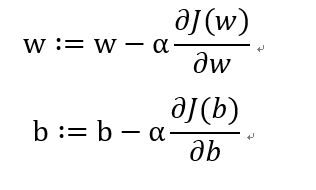
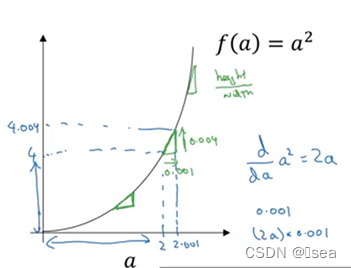
9.导数的简单介绍
举例所涉及的都是中学知识,不再赘述。
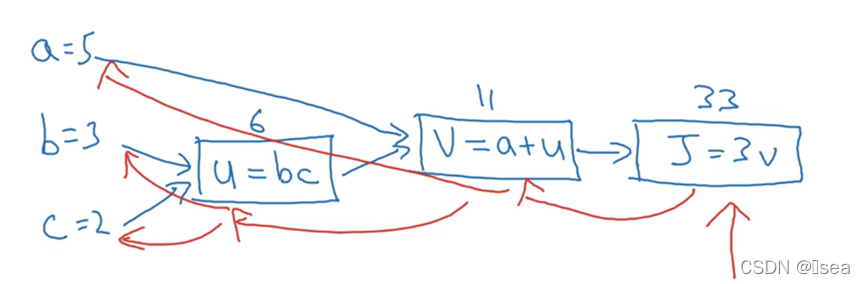
10.计算图
神经网络的计算,就是按照前向传播或者后向传播的。前向过程计算除一个输出,后向传播计算相应的梯度或导数。计算图就是形象化的表示这一过程。例如要计算 J(a, b,c) = 3(a+bc)
这里令u = bc, v = a+u。所以整个计算过程就是先计算u v J,如下图所示(后向传播为红线)。
11.使用计算图求导
用到的数学知识:链式求导法则。
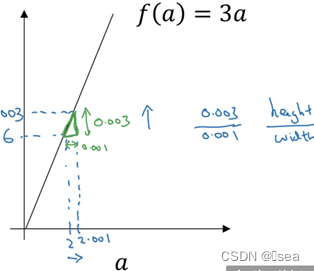
举个例子:变量 a = 5 ,我们让它增加到5.001,那么对 v 的影响就是 a + u ,之前 v = 11 ,现在变成11.001,我们从上面看到现在 J 就变成33.003了,所以我们看到的是,如果你让a 增加0.001, J增加0.003。那么增加 a ,我是说如果你把这个5换成某个新值,那么a的改变量就会传播到流程图的最右,所以J最后是33.003。所以J的增量是3乘以a的增量,意味着这个导数是3。
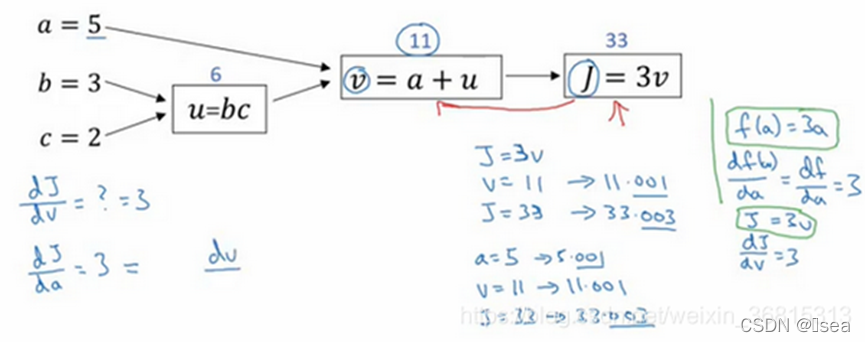
如果你想计算最后输出变量的导数(使用你最关心的变量),这里是对v的导数,那么我们就做完了一步方向传播,在这个流程图中是一个反向步。
dJ/du = dJ/dv* dv/du
当你编程实现反向传播的时候,通常会有一个最终输出值是你要关心的,即最终的输出变量
12.logistic回归中的梯度下降法
回想一下logistic回归的公式(目前只考虑单个样本)
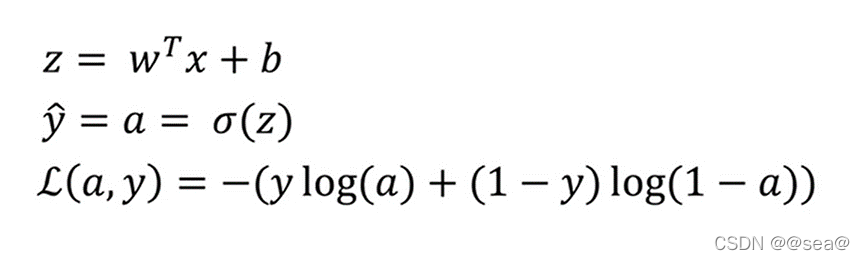
a:是logistic回归的输出,
y: 是样本的ground-truth label (ground truth就是参考标准,一般用来做误差量化。比方说要根据历史数据预测某一时间的温度,ground truth就是那个时间的真实温度。在全监督学习中,数据是有标签(label)的的,以(x, t)的形式出现,其中x是输入数据,t是label。正确的t标签是ground truth,错误的标签则不是。)
假设样本只有两个特征x1和x2,为了计算z,我们需要输入参数w1、w2和b,还有样本特征值x1, x2。
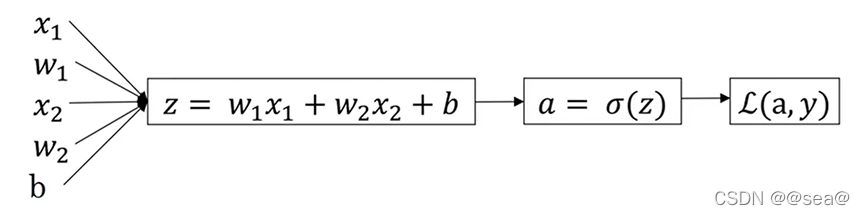
因此在logistic回归中 我们需要做的就是变换参数w和b的值,来最小化损失函数。现在就来讨论如何向后计算偏导数。
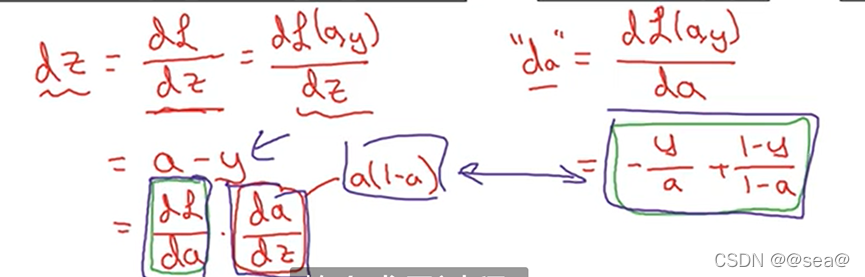
dz=dl / dz = (dl/da) *(da/dz)= a-y

最后,运用上图中的结果,就可以更新w1,w2,b,具体更新原理如下,学习率。
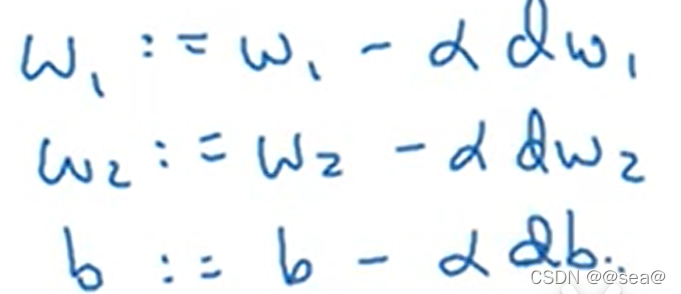
以上就是单个样本实例的,一次梯度更新步骤。但是这里只是一个样本,但实际情况往往包含一个样本集,下一节就讨论这个问题。
13.m个样本的梯度下降
上一节已经讨论了单个样本的梯度下降,现在我们想要把它应用到m个训练样本上。成本函数J(w,b)的定义如下:
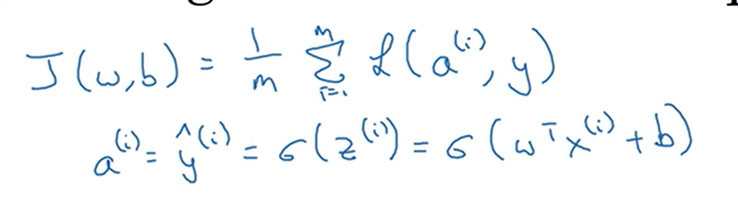
a^i是训练样本的预测值,σ代表sigmod函数。
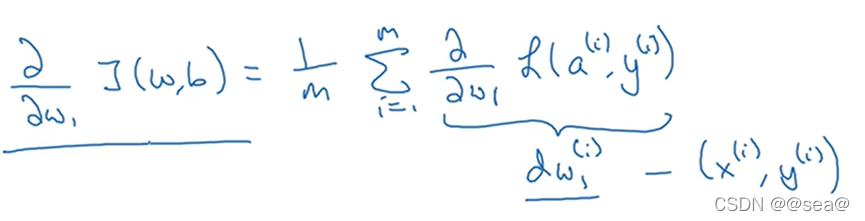
可以把上图中的所有公式直接用于一个具体的算法,用于计算损失函数J对参数w1,w2,b的导数。然后再去更新w1,w2,b,更新方法如下:

14.向量化
在深度学习安全领域、深度学习实践中,你会经常发现自己训练大数据集。数据量越大则训练的时间就会越长。而向量化是非常基础的去除code中for循环的技巧。

但是在python中,可以直接使用,这种方式非常快。
z = np.dot(w,x) + b
参考代码如下:
import numpy as np
import time
a = np.array([1,2,3,4])
print(a)
a = np.random.rand(1000000)
b = np.random.rand(1000000) #随机获取两个一百万维度的数组
tic = time.time() #获取当前时间
#1.向量化的部分
c = np.dot(a,b)
toc = time.time()
#向量化所需要时间
print("Vectorized version:" + str(1000*(toc-tic)) +"ms")
#2.非向量化的部分
c = 0
tic = time.time()
for i in range(1000000):
c += a[i]*b[i]
toc = time.time()
print(c)
#使用for循环需要时间
print("For loop:" + str(1000*(toc-tic)) + "ms")
结果如下所示

15.向量化的更多例子
经验告诉我们,如果能够避免使用for循环则一定要避免
- 例子一
下图中,左边是利用for循环,右边是利用向量化的方法
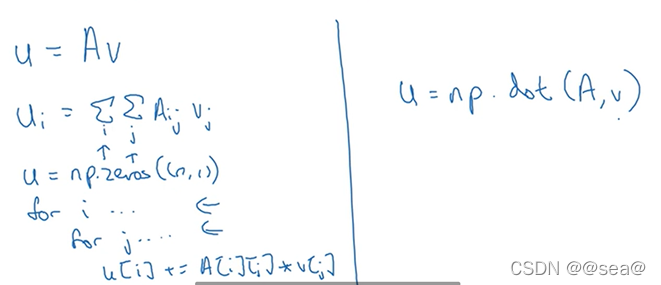
- 例子二
利用向量化,将下列两个地方for循环改变
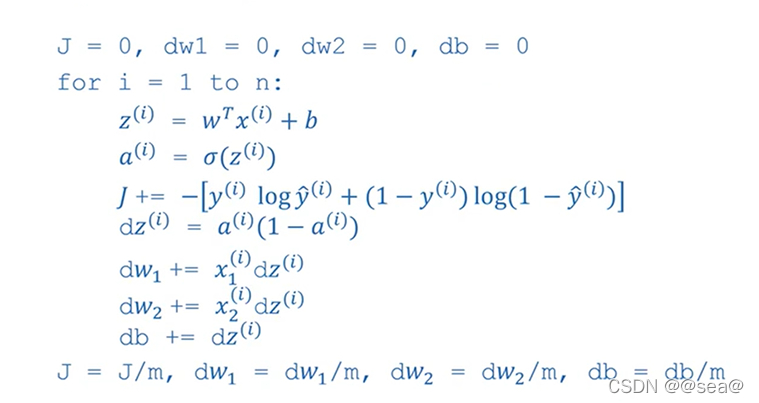

16.向量化的logistic回归
目的:同时处理整个数据集来实现梯度下降的一步迭代,这样就可以避免使用for循环
梯度下降中,需要z = wTx+b进行m次操作,具体如下。
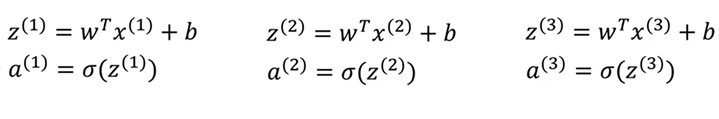
优化如下:

代码:
z = np.dot(w.T,x)+b
这里的b是一个实数,所以python会自动的将b转换为一个1xm维的向量----广播
17.向量化logistic回归的梯度输出
在此节,将会学会如何向量化计算m个训练数据的梯度(同时计算)
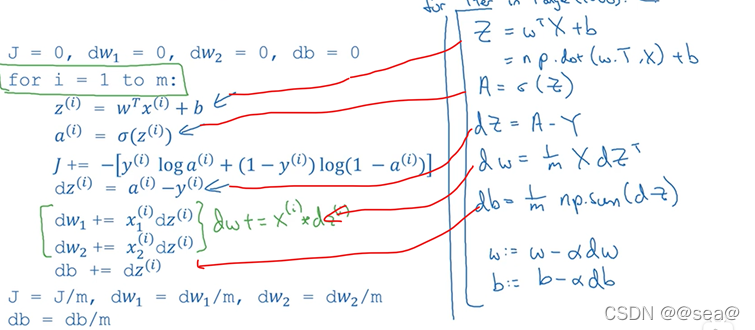
通过上图中的操作,就去掉了原本使用的for循环,从而完成了一次正向以及反向传播。
18.python中的广播
广播是一种手段,可以让你的python代码段执行得更快,本节主要目的就是探究这背后的具体原理。
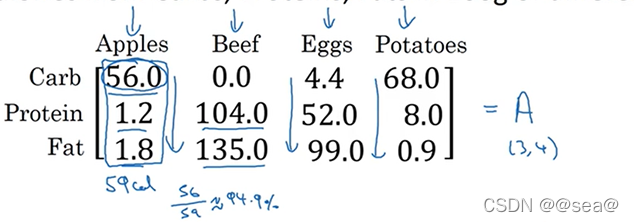
目标:计算四种食物中 卡路里有多少百分比来自碳水化合物,蛋白质和脂肪。且不使用for循环。代码如下:
mport numpy as np
A = np.array([[56.0,0.0,4.4,68.0],
[1.2,104.0,52.0,8.0],
[1.8,135.0,99.0,0.9]])
print(A)
cal = A.sum(axis=0) #纵向对每一列求和
print(cal)
percentage = 100*A/cal.reshape(1,4) #这里就调用了python中的广播机制
print(percentage)
结果如下:

其实cal已经是一个1X4的矩阵,所以技术上其实并不需要调用reshape。但在实际编写python代码时,如果不完全确定使用什么矩阵,不确定矩阵的维度,那就需要调用reshape命令,确保它的行列维度是正确的。而且该操作的时间复杂度是O(1)的。
下面再来看一些广播机制的例子。
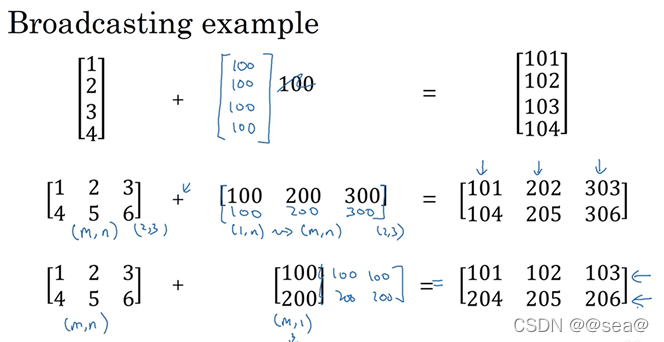
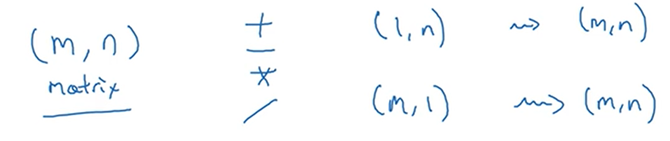
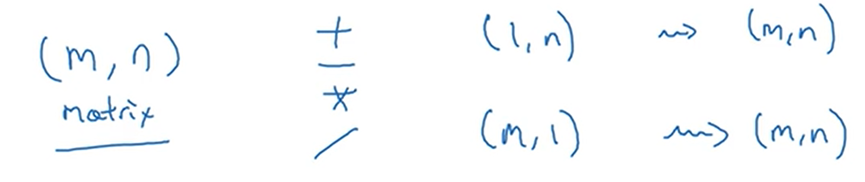
19.关于python_numpy向量的说明
本节主要讲Python中的numpy一维数组的特性,以及与行向量或列向量的区别。并介绍了老师在实际应用中的一些小技巧,去避免在coding中由于这些特性而导致的bug。所以我在这里想做的就是分享给你们一些技巧,这些技巧对我非常有用,它们能消除或者简化我的代码中所有看起来很奇怪的bug。同时我也希望通过这些技巧,你也能更容易地写没有bug的Python代码。
1.通过在原先的代码里清除一维数组,代码变得更加简洁。总是使用n∗1维矩阵(基本上是列向量),或者1∗n维矩阵(基本上是行向量),这样你可以减少很多assert语句来节省该矩阵和数组的维数的时间。
2.为了确保你的矩阵或向量所需要的维数时,不要羞于reshape操作。
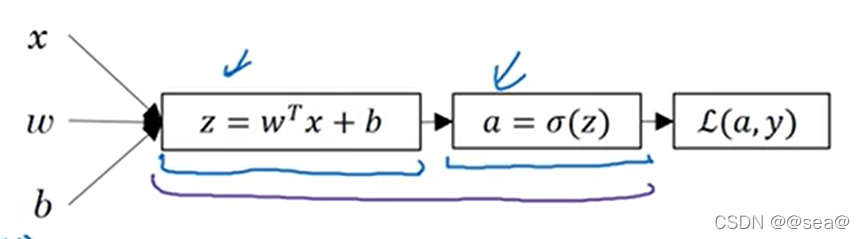
20.神经网络概况
以正向传播为例。
通常,在计算下面的式子时,只需要计算一次。但因为神经网络中含有很多层,这里假设有两层,则计算过程就应该如图2.
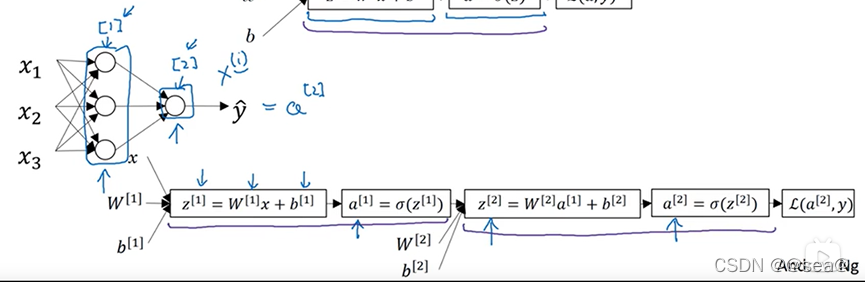
21.神经网络的表示
本节探讨我们画的这些神经网络到底代表了什么。先举例一个单层的神经网络。
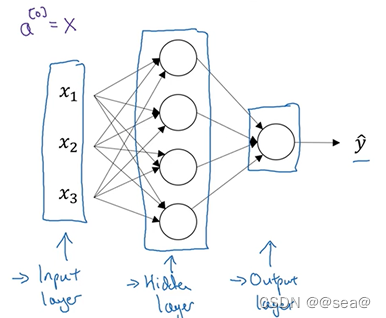
输入层:x1,x2,x3被竖直地堆叠起来,这叫做神经网络的输入层(Input Layer)
输出层:本例中最后一层只由一个结点构成,而这个只有一个结点的层被称为输出层(Output Layer),它负责产生预测值.
隐藏层:在训练集中,这些中间结点的准确值我们是不知道到的,也就是说你看不见它们在训练集中应具有的值。
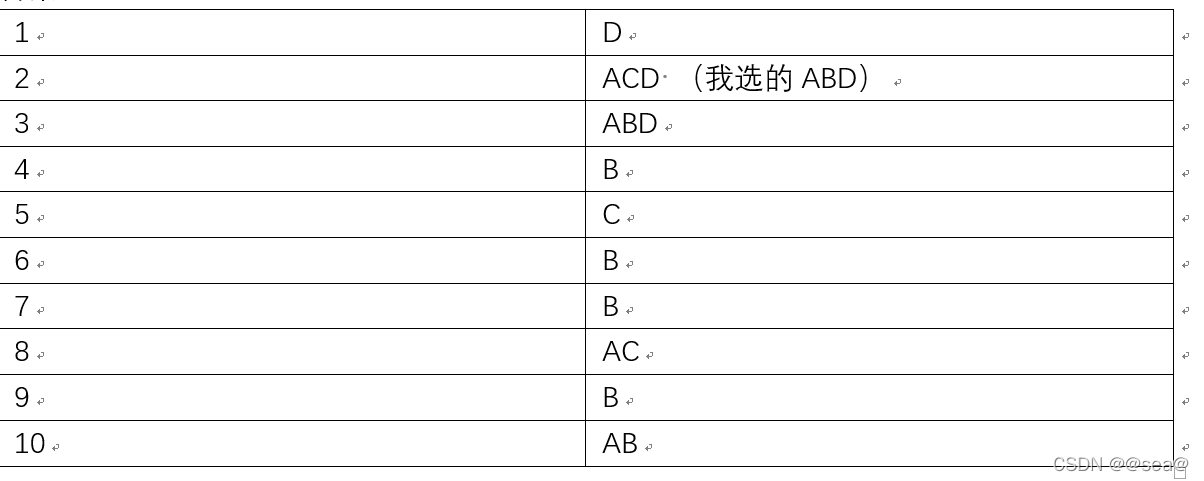
三.练习题
第一部分
答案
























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









