






文章目录
前言
本文内容是B站up主“技术喵”的《神经网络十四’对比学习’》课程的学习笔记。up主乃湾区大厂程序员,值得关注。
课程链接:https://www.bilibili.com/video/BV19F41187hK?spm_id_from=333.1007.top_right_bar_window_default_collection.content.click&vd_source=0c402abd3bb251e4d8e531418743215a
对比学习,利用事物间的相关性来学习事物的本质。
对比学习已经成为一整套框架。
一、主体思想
通过对比来了解事物的本质,灵感来源于人类本身。
二、对比学习框架
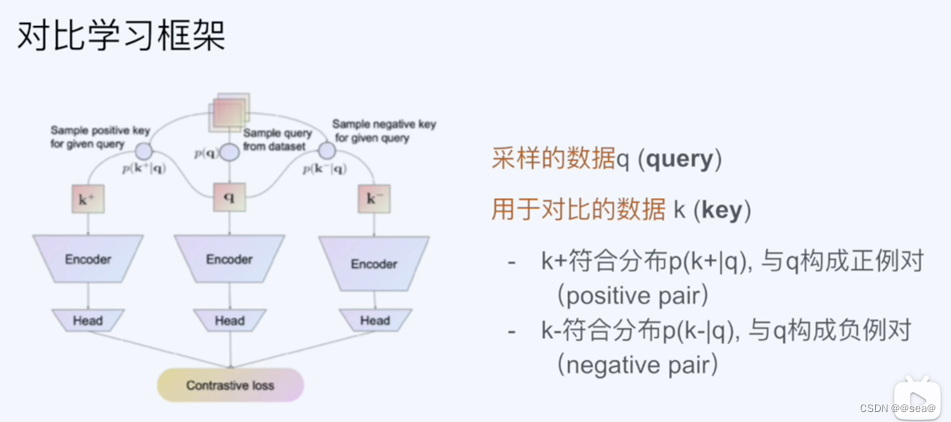
训练数据成为query,用于对比的数据成为key。如果q与k相似,则q与k则构成正例对,反之,为负例对。
三.正负例生成方法
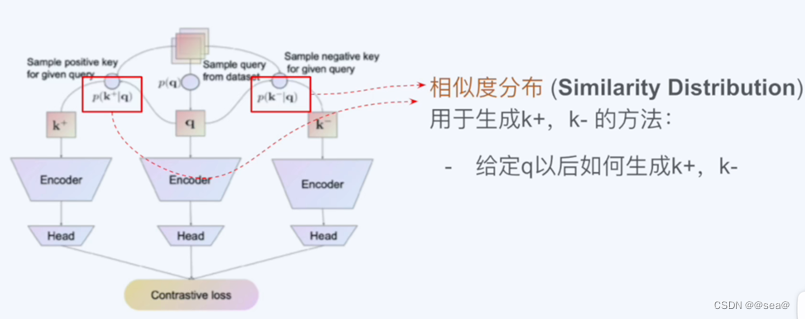
实际生活中,拿到一堆数据,数据本身天然不是成对的,有以下几个方法:
(1) 对于同一个事物用不同的角度去看。
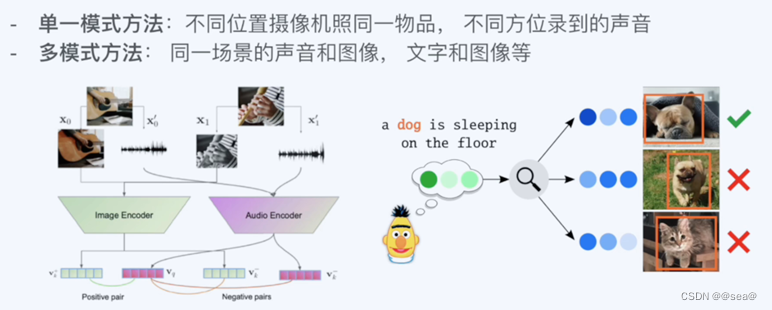
(2) 制造新的数据

(3) 拆分原数据
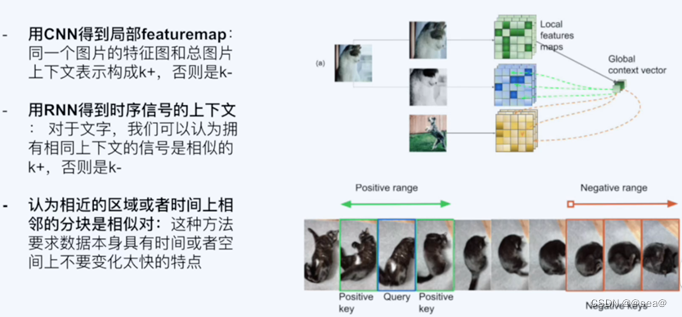
(4)利用其他的已有的feature的clustering
四.模型
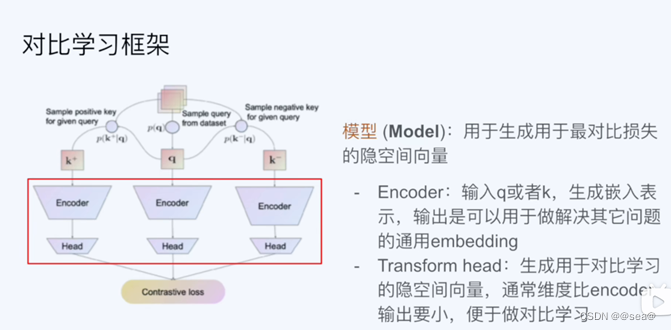
Head:把样本的表示变成一个度量的表示。Transform head 理论上也不是必须的,但在实际应用中通常还是会加上,理由如下:
(1) encoder生成的表示涵盖的信息太多了,我们可以再进行压缩,从而让对比学习更有效率。
(2) 如果直接encoder输出的话,可能就会把嵌入过分地拟合到我们想要对比的这个概念上。从而使得encoder输出的信息量太单一,从而没有办法很好的应用于其他任务中。
Encoder和head本质上和其他神经网络并没有什么区别。对于q和k,如果是单一模式(例如都是图片或者语音),那可以使用同一个Encoder。但如果不是单一模式(一个是图片一个是语音),那最好用不同的Encoder.

在Encoder模型确定下来之后,最直接的方法就是进行and to and的随机梯度下降算法去进行优化,但因为Encoder模型很大,k和q可能不是同步更新。
至于Transform head的部分,主要是在encoder之后进一步抽象和压缩,更需要具体问题具体分析。
五.对比损失
通常损失函数需要做到的就是在度量Z的嵌入空间上,把相似对的距离拉近,把不相似对的距离拉远。

对比学习的损失函数于其他损失函数的区别。

隐空间中的距离函数(scoring function),衡量向量间距离的方法有很多,比如一范数,二范数,点积,cosine相似性。

5.1基于能量模型的损失函数
要求给想要出现的数据对的结果一个比较高的能量。也就是说相似的对,我们希望它的距离越近越好,而不相似的我们让它的距离越大越好。
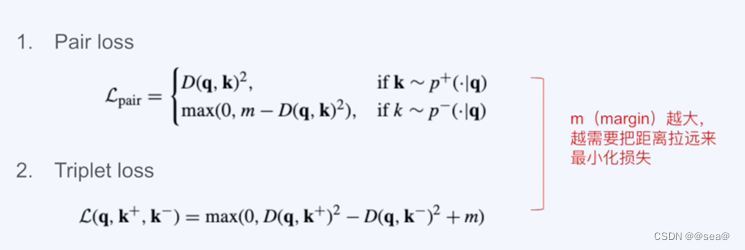
m: 用来给正例,负例保持距离用的。m越大,我们的损失越难是零,因为我们需要考虑越多的负例,事实上只有距离足够相似的点,才会出现在损失函数的考量中。
**Triplet loss:**就是在刚才说的pair loss的基础上同时考虑正例和负例。
这种损失函数虽然直观,但是收敛速度并不快。这主要是因为每一次更新随机梯度,可能很难挑到一组正好能够帮助模型的样本。(随便挑的一组样本,也许并不是现在的瓶颈,对模型的提高,没有太多的帮助)
5.2基于NCE的损失函数

基于NCE的损失函数的上层逻辑:对于对比学习,我们也可以假设是在设置一个分类器,目标就是让相似对的输出为1,不相似对的输出为0。
并不需要单独计算p(k-│q),因为p(k-│q)=1-p(k^+│q)。
损失函数所存在的问题:就是考虑所有复利对的这个z(q)函数,运算复杂度太高。
NCE主要的思想就是想办法不去用softmax,直接去参数化我估计出来的结果。


5.3互信息损失
除了NCE和能量模型,其实还有一种常见的损失函数叫做互信息损失。

6.经典的论文例子
6.1 CPC

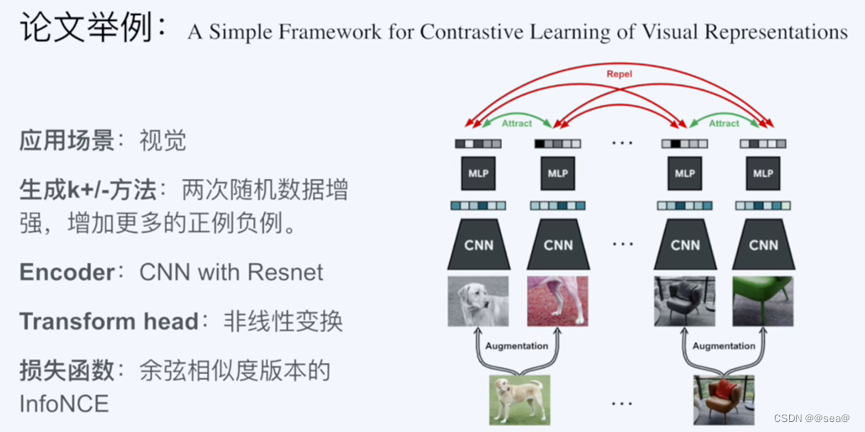
6.2 simCLR
6.3 moco
Moco生成正样本和负样本的方法是使用了两个不同的神经网络进行编码,分别叫做encoder和momentum encoder除了对query的这个x进行编码之外呢,也对其他的负例进行编码。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









