







Perceptron 感知机
1. Reference
刘建平 Pinard
Hsuan-Tien Lin ,National Taiwan University
统计学习方法 李航
2. Concept
参考台湾大学林轩田老师 机器学习基石课程。
2.1 Basic Notations
-
H \ H H: the set of candidate formulas.
-
D \ D D: data ⇒ \Rightarrow ⇒ training examples.
-
f \it f f: X → Y \ X \rightarrow Y X→Y , which is the unknown pattern to be learned ⇔ \Leftrightarrow ⇔ target function.
-
g \ g g: X → Y \ X \rightarrow Y X→Y , which is ‘learned’ formula to be used)
-
A \ A A: learning algorithm
We want
A \ A A takes D \ D D (given) and H \ H H (suitable) to get g ( b e s t ) \ g \,(best) g(best).
Learning Model = A \ A A and H \ H H.==
2.2 Learning Model

3. Perceptron
3.1 What is Perceptron?
在机器学习中,perceptron是一种二元分类的线性分类模型,它可以决定输入是属于一个类(+1,记为正类)还是另一个类(-1,记为负类)。
以恋爱为例,你自己本身就是一个perceptron,根据自己的择偶准则,异性在你的眼里就自动被划分为鱼塘内和鱼塘外两种类型(太魔鬼…)。
我们用数学的语言来进行更为准确的表达,用threshold表示择偶的门槛分数,也叫做阈值,
x
\bf x
x
=
(
x
1
,
x
2
,
.
.
.
,
x
d
)
=(x_1,x_2,...,x_d)
=(x1,x2,...,xd)表示boy or girl 的features,
w
\bf w
w
=
(
w
1
,
w
2
,
.
.
.
,
w
d
)
=(w_1,w_2,...,w_d)
=(w1,w2,...,wd)表示每一个feature的权重。
approve
\quad
∑
i
=
1
d
w
i
x
i
>
t
h
r
e
s
h
o
l
d
\sum_{i=1}^d {w_ix_i} > threshold
∑i=1dwixi>threshold
deny
\qquad
∑
i
=
1
d
w
i
x
i
<
t
h
r
e
s
h
o
l
d
\sum_{i=1}^d {w_ix_i} <threshold\\[2ex]
∑i=1dwixi<threshold
此处,为了简化起见,记
h
(
x
h(\bf x
h(x
)
=
s
i
g
n
(
(
∑
i
=
1
d
w
i
x
i
)
−
t
h
r
e
s
h
o
l
d
)
=
s
i
g
n
(
∑
i
=
0
d
w
i
x
i
)
=
s
i
g
n
(
w
T
x
)
)=sign((\sum_{i=1}^d {w_ix_i} )-threshold)=sign(\sum_{i=0}^d {w_ix_i} )=sign(\bf w^Tx)
)=sign((∑i=1dwixi)−threshold)=sign(∑i=0dwixi)=sign(wTx),where
x
0
=
+
1
,
w
0
=
−
t
h
r
e
s
h
o
l
d
x_0=+1,\,w_0=-threshold
x0=+1,w0=−threshold
其中,
s
i
g
n
sign
sign是示性函数,
若
w
T
x
\bf w^Tx
wTx大于0,即
∑
i
=
1
d
w
i
x
i
−
t
h
r
e
s
h
o
l
d
>
0
\sum_{i=1}^d {w_ix_i} -threshold>0
∑i=1dwixi−threshold>0, 也就是boy or girl 的得分大于阈值的时候,
s
i
g
n
=
+
1
sign=+1
sign=+1,那他/她就被划进鱼塘;在小于零的时候,
s
i
g
n
=
−
1
sign=-1
sign=−1,那就放生。
所以,我们的目标是,寻找一张合适的网,进行最佳的渔场管理。
3.2 Why Perceptron?
简单地解决分类问题
从两个角度来解释“简单”,一方面是训练数据应该是线性可分的,另一方面,我们的解决办法也很简单,就是找到一个超平面完全将其分割开来。

3.3 How Perceptron?
3.31 Sketch
Rule: improve it based on mistakes.
前文提到过,我们的目标是找到最佳的分类器,可以将训练集中的两类数据分开。
观察之前的数学式子,
s
i
g
n
(
w
T
x
)
sign(\bf w^Tx)
sign(wTx)的结果关乎判断对错,其中,用于训练的样本
x
\bf x
x是给定的,无法改变,可以进行改动的就只有
w
\bf w
w。所以,我们用
w
\bf w
w来代表分类器。

为了更形象地进行说明,依旧以二维平面为例:上图中的黑色直线代表分类器,
w
\bf w
w是其法向量。当选取了最优的
w
\bf w
w时,分割线也就可以被唯一地表达出来,就是我们要找的分类器。所以,寻找最佳分类器的任务就是寻找最佳
w
\bf w
w啦~~~
然而,在一般情况下,我们不可能一次就得到这样的分类器,可以完美地将两类数据分开。一开始,分类器可能会出现误分类的现象,基于它犯的这些错误,我们可以来一步步改进我们的分类器。
如下流程图所示,每当遇到分类错误的情况,我们就更新一次参数
w
\bf w
w。

步骤:
- 随机选取一个 w t = 0 \bf w_{t=0} wt=0。(实际上,并没有那么“随便”。如果一开始选的分类器就不会“犯错”,那么后面的优化迭代也就无法进行。)
- 随机选择样本点,如果样本点在该分类器下是正确分类的,则继续sample,直到发生第一次错误。(这里应该不是从全局的误分类点中随机抽样,点到即止可以提高运算效率)。
- 修正 w \bf w w。
- 重复步骤2-3,如果某个分类器遍历所有样本都没有发生误分类的错误,则停止。
3.32 Details
3.321 Correction
可以看出,根据“误分类的样本点”来修正我们的分类器是关键所在。那么,具体又是如何进行修正的呢?
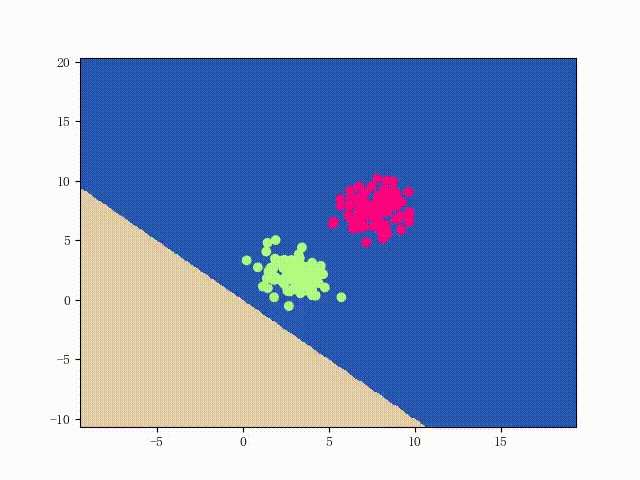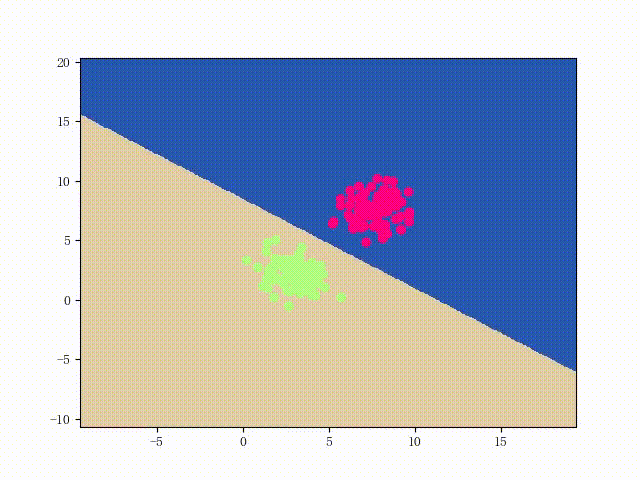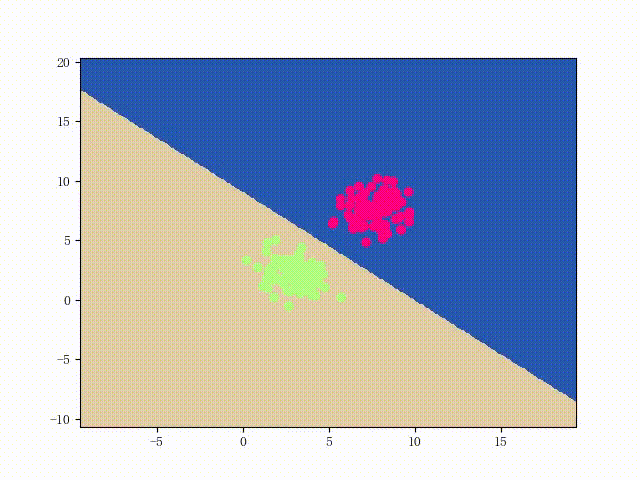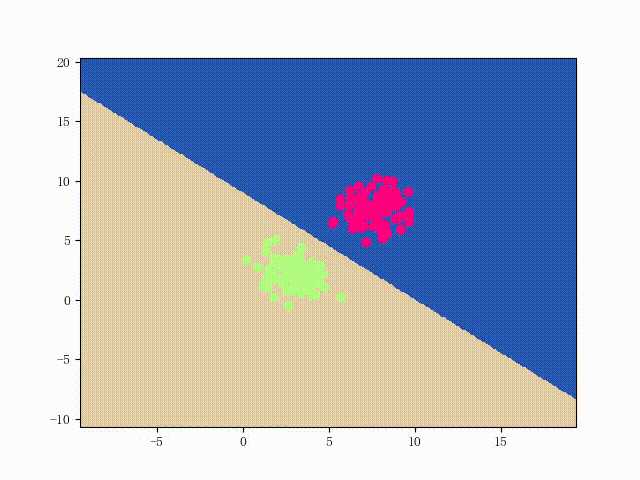
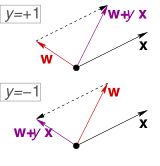
如下图所示,我们用具体的例子进行说明。其中,
O
O
O表示原点,
蓝色的点表示正类样本(+1),
红色的叉叉表示负类样本(-1);
紫色的向量是法向量,与法向量垂直的灰色直线代表对应的分隔线。
我们可以清楚地观察到,样本点B和样本点C被分类错误了。
用数学形式表达如下:
s
i
g
n
(
w
T
x
B
sign(\bf w^Tx_B
sign(wTxB)=
−
1
-1
−1,
y
B
=
+
1
y_{B}=+1
yB=+1,
s
i
g
n
(
w
T
x
C
sign(\bf w^Tx_C
sign(wTxC)=
+
1
+1
+1,
y
C
=
−
1
y_C=-1
yC=−1.

对于正类样本点B来说,超平面的法向量
w
w
w与其(
x
\bf x
x) 夹角却大于90°,所以产生误分类。那我们很自然的一个想法就是,根据这个“犯错点”来修正法向量,考虑
w
t
+
1
←
w
t
\bf w_{t+1}\leftarrow w_t
wt+1←wt+
y
n
(
t
)
y_{n(t)}
yn(t)
x
n
(
t
)
\bf x_{n(t)}
xn(t),即
w
t
+
1
=
w
t
+
x
B
\bf w_{t+1}= w_t+\bf x_B
wt+1=wt+xB.
同时,对于C点来说,超平面的法向量
w
w
w与其(
x
\bf x
x) 夹角小于90°,所以产生误分类,那我们把
w
\bf w
w朝着
x
\bf x
x的反方向调节移动, 即
w
t
+
1
=
w
t
−
x
C
\bf w_{t+1}= w_t-\bf x_C
wt+1=wt−xC.
w
t
+
1
=
w
t
+
x
B
\bf w_{t+1}= w_t+\bf x_B
wt+1=wt+xB 和
w
t
+
1
=
w
t
−
x
C
\bf w_{t+1}= w_t-\bf x_C
wt+1=wt−xC可以被合并表示为
w
t
+
1
=
w
t
\bf w_{t+1}= w_t
wt+1=wt
+
y
n
(
t
)
+y_{n(t)}
+yn(t)
x
n
(
t
)
\bf x_{n(t)}
xn(t)
我们以更严谨的形式描述PLA算法:
For t = 0 , 1 , . . . t=0,1,... t=0,1,...
- find a mistake of
w
t
\bf w_t
wt called
(
x
n
(
t
)
\bf (x_{n(t)}
(xn(t),
y
n
(
t
)
)
y_{n(t)})
yn(t))
s i g n ( w T x n ( t ) ) ̸ sign(\bf w^Tx_{n(t)})\not sign(wTxn(t)) = y n ( t ) = y_{n(t)} =yn(t) - ( try to ) correct the mistake by
w t + 1 ← w t \bf w_{t+1}\leftarrow w_t wt+1←wt+ y n ( t ) y_{n(t)} yn(t) x n ( t ) \bf x_{n(t)} xn(t)
Until no more mistakes,
return last
w
\bf w
w (called
w
P
L
A
\bf w_{PLA}
wPLA ) as
g
g
g
这里,我们需要特别注意,PLA存在许多解集,也就是说,不只存在一个超平面可以将两类数据完全分开。在进行PLA的过程中,我们可能每次会得到不同的结果,这些结果不仅依赖于我们对于
w
0
\bf w_0
w0的选择,而且也依赖于迭代过程中对于误分类点的选择顺序。
让我们再回顾一下这张图,记紫色向量为
w
t
\bf w_t
wt,当我们选择点B对
w
t
\bf w_t
wt进行更新时,新的法向量为
w
(
t
+
1
)
g
r
e
e
n
\bf w_{(t+1)green}
w(t+1)green;然而,若我们选择了点C时,更新后的法向量为
w
(
t
+
1
)
y
e
l
l
o
w
\bf w_{(t+1)yellow}
w(t+1)yellow.
3.322 Break Point
因为数据是线性可分的,我们知道一定可以找到一个线性分类器将两类数据分开,也就是说,迭代一定是会停止的。那么问题在于,迭代的次数一定是有限的吗?
我们可以证明迭代次数一定是有限的。
MATH WARNING (T-T)
-
w t + 1 = w t \bf w_{t+1}= w_t wt+1=wt + y n ( t ) +y_{n(t)} +yn(t) x n ( t ) \bf x_{n(t)}\\[2ex] xn(t) (Correction)
-
y n ( t + 1 ) w f T x n ≥ \bf y_{n(t+1)}w^T_fx_{n}\geq yn(t+1)wfTxn≥ m i n n y n ( t ) w f T x n \mathop{min}\limits_{n} \bf y_{n(t)}w^T_fx_{n}\\[2ex] nminyn(t)wfTxn (图中任意点在法向量上的投影长度都大于点T在其上的投影长度。)

-
w f T w t + 1 ≥ w f T w t + m i n n y n ( t ) w f T x n \bf w^T_fw_{t+1}\geq w^T_fw_{t}+\mathop{min}\limits_{n}\bf y_{n(t)}w^T_fx_{n} wfTwt+1≥wfTwt+nminyn(t)wfTxn
-
∥ w t + 1 ∥ 2 ≤ ∥ w t ∥ 2 + m a x n ∥ y n x n ∥ 2 \bf \|w_{t+1}\|^2 \leq \bf \|w_{t}\|^2+\mathop{max}\limits_{n} \bf \|y_{n}x_{n}\|^2 ∥wt+1∥2≤∥wt∥2+nmax∥ynxn∥2
-
w f T w t + 1 ≥ w f T w 0 + ( t + 1 ) m i n n y n ( t ) w f T x n \bf w^T_fw_{t+1}\geq w^T_fw_{0}+(t+1)\mathop{min}\limits_{n}\bf y_{n(t)}w^T_fx_{n}\\[2ex] wfTwt+1≥wfTw0+(t+1)nminyn(t)wfTxn (由3可得)
-
∥ w t + 1 ∥ 2 ≤ ∥ w 0 ∥ 2 + ( t + 1 ) m a x n ∥ y n x n ∥ 2 \bf \|w_{t+1}\|^2 \leq \bf \|w_{0}\|^2+(t+1)\mathop{max}\limits_{n} \bf \|y_{n}x_{n}\|^2\\[2ex] ∥wt+1∥2≤∥w0∥2+(t+1)nmax∥ynxn∥2 (由4可得)
-
w f ′ ∥ w f ∥ w T ∥ w T ∥ = c o s θ ≤ 1 \bf \frac{w_f^{'}}{\|w_f\|} \frac{w_T}{\|w_T\|}=cos\theta \leq1\\[2ex] ∥wf∥wf′∥wT∥wT=cosθ≤1
-
R 2 = m a x n ∥ x n ∥ 2 R^2=\mathop{max}\limits_{n}\bf \|x_{n}\|^2\\[2ex] R2=nmax∥xn∥2
-
ρ = m i n n y n w f T x n ∥ w f ∥ \rho=\mathop{min}\limits_{n}\bf y_{n}\frac{w^T_fx_{n}}{\|w_f\|}\\[2ex] ρ=nminyn∥wf∥wfTxn
Finally, we get
w
f
′
∥
w
f
∥
w
T
∥
w
T
∥
=
1
∥
w
f
′
∥
T
m
i
n
n
y
n
w
f
T
x
n
T
∗
m
a
x
n
∥
x
n
∥
2
=
T
ρ
R
\bf \frac{w_f^{'}}{\|w_f\|} \frac{w_T}{\|w_T\|}= \frac{1}{\|w_f^{'}\|} \frac{T\mathop{min}\limits_{n}\bf y_{n}w^T_fx_{n}}{\sqrt{T*\mathop{max}\limits_{n}\bf \|x_{n}\|^2} } =\sqrt{T} \frac{\bf \rho}{R}\\[2ex]
∥wf∥wf′∥wT∥wT=∥wf′∥1T∗nmax∥xn∥2TnminynwfTxn=TRρ
⟹ T ≤ R 2 ρ 2 \implies T\leq \frac{R^2}{\rho^2}\\[2ex] ⟹T≤ρ2R2
Oooooops!!!
3.4 统计学习角度
根据李航老师的统计计算一书,将统计学习方法解构为模型,策略和算法三个要素。
模型: 示性(符号)函数
f
(
x
)
=
s
i
g
n
(
w
x
+
b
)
f(x)=sign(wx+b)
f(x)=sign(wx+b)
s
i
g
n
(
w
T
x
+
b
)
=
{
+
1
w
T
x
+
b
≥
0
−
1
w
T
x
+
b
<
0
sign(w^Tx+b)=\left\{ \begin{array}{rcl} +1 & & {w^Tx+b\geq 0}\\ -1 & & {w^Tx+b< 0}\\ \end{array} \right.
sign(wTx+b)={+1−1wTx+b≥0wTx+b<0
策略:最小化误分类点到超平面的距离
m
i
n
−
1
∣
∣
w
∣
∣
∑
x
i
∈
误
分
类
y
i
(
w
T
x
i
+
b
)
min \;-\frac{1}{ ||w||}\sum\limits_{x_i\in误分类}y_i(w^Tx_i+b)
min−∣∣w∣∣1xi∈误分类∑yi(wTxi+b)
算法: 随机梯度下降
对损失函数求偏导得到其梯度,从而对 w , b w,b w,b进行更新:
▽
w
L
(
w
,
b
)
=
−
∑
x
i
∈
误
分
类
y
i
x
i
\bigtriangledown_w L(w,b)=-\sum\limits_{x_i\in 误分类}y_ix_i
▽wL(w,b)=−xi∈误分类∑yixi
▽
b
L
(
w
,
b
)
=
−
∑
x
i
∈
误
分
类
y
i
\bigtriangledown_b L(w,b)=-\sum\limits_{x_i\in 误分类}y_i\\[2ex]
▽bL(w,b)=−xi∈误分类∑yi
随机选择误分类点
(
x
i
,
y
i
)
(x_i,y_i)
(xi,yi),对
w
,
b
w,b
w,b进行更新:
w
n
e
w
←
w
o
l
d
+
y
i
x
i
w_{new} \leftarrow w_{old}+y_ix_i
wnew←wold+yixi
b n e w ← b o l d + y i b_{new}\leftarrow b_{old}+y_i bnew←bold+yi
3.5 To Be Continued…
3.51 Pocket
If noise in the data?
好了,至此PLA告一段落。
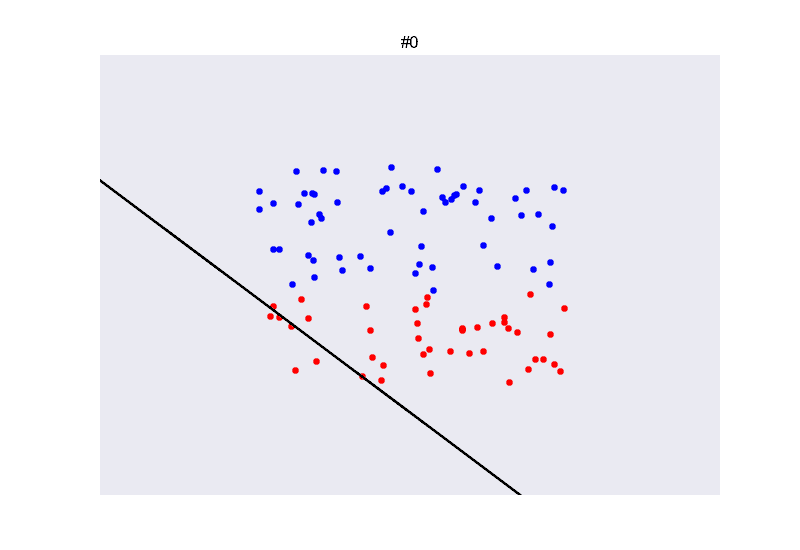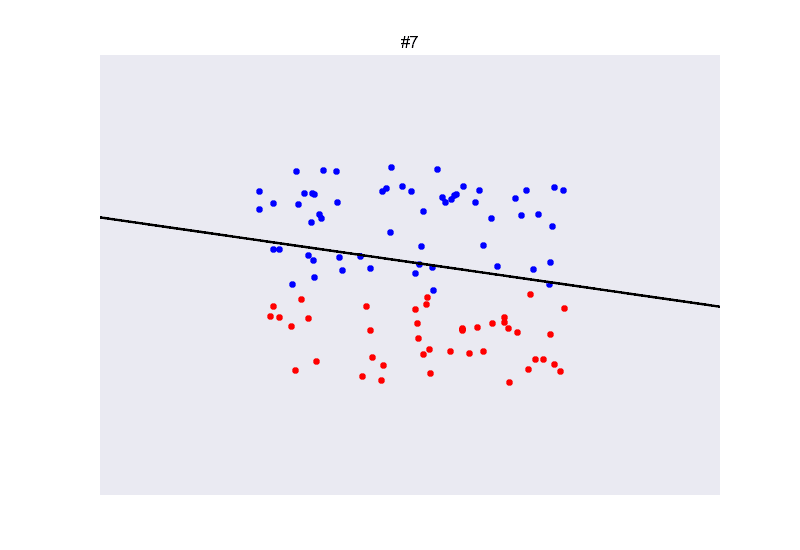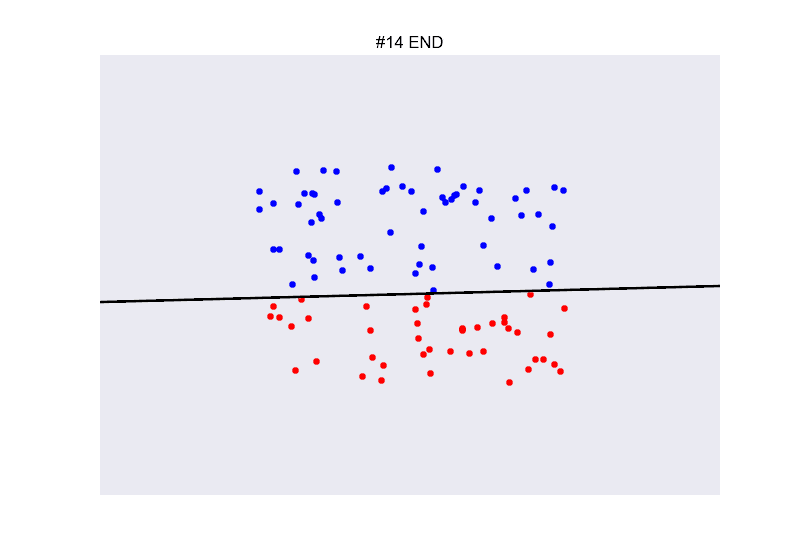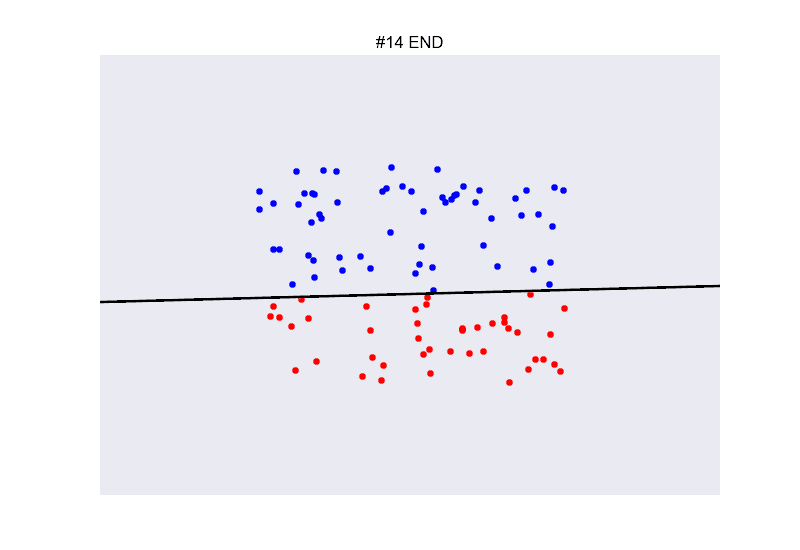
在现实生活中,两类数据完全线性可分的这种情况其实是比较少见的。如下图所示,两类数据并不能被直线完全分割开来。
我们考虑,那找一条犯错误最少的线好了!同时,因为数据线性不可分的原因,迭代不会停止,需要设置一个固定的迭代次数。
换句话说,我们每次更新参数的时候,都把之前的
w
t
\bf w_t
wt存储下来,当我们的口袋里装了足够多的分类器之后,最后从中选取一个犯错最少的分类器。
WARNING:
听起来,我们的算法好像变得更加实用了些。然而,每一次都要储存新的参数,也就意味着运算速度会降低。
如果数据的真实分布是线性可分的,口袋算法的效率可能还不如原始PLA高。
3.52 SVM
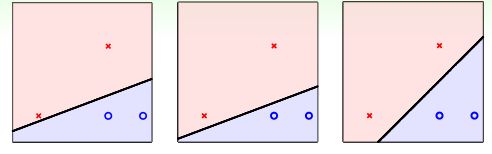
自始至终,我们的目标都是:找到一个超平面,将两类数据分开。可是,PLA的结果并不唯一。下图的三个超平面都可以将两类数据完美地分开,PLA 并不能帮助我们进行最优的选择。
直觉告诉我们,最右的分割线应该是最棒的。这就要提到SVM了,后面会详细介绍…















 267
267











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









