






1.Motivation
现有方法忽略了数据经过逐层特征提取和空间变换操作后会丢失大量信息,即信息瓶问题。
解释
所谓的信息瓶颈问题,作者用一个公式进行了解答,公式如下式1所示:
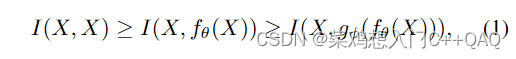
其中I是相似性(或者共有信息吧),X表示输入的数据,f,g表示转换函数,
Θ
\Theta
Θ和
ϕ
\phi
ϕ表示f和g的参数。
随着网络的加深,信息丢失问题回原来越严重,导致题刻不可靠,收敛差。
解决上述问题的一种方法就是增加模型大小,当使用大量参数构建模型时,它能够对数据进行更完整的转换,减少信息丢失问题。这也就是问什么现有模型宽度比深度更重要。
顺带一题作者讲述了可逆函数,当网络的变换函数由可逆函数组成时,可以获得更可靠的梯度信息来更新模型
2.方法
提出可编程梯度信息(programmable gradient information,PIG)和广义高效聚合网络(Generalized Efficient Layer Aggregation Network,GELAN)。
PIG
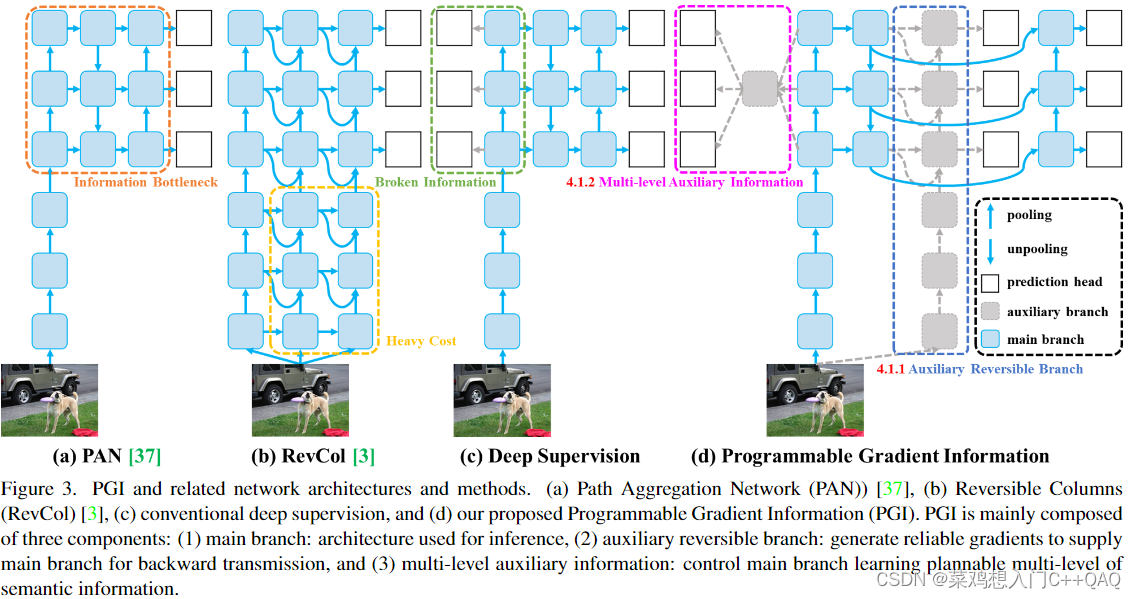
PIG主要由上图三个部分组成:主分支、辅助可逆分支(auxiliary reversible branch)和多级辅助信息(multi-level auxiliary information)。
由于主分支会因为信息瓶颈问题而丢失重要信息,通过辅助可逆分支(有点类似于CBNet的双backbone)使得主分支能够接收可靠的梯度信息,这些梯度信息将驱动参数学习来辅助提取正确和重要的信息。值得注意的是辅助可逆分支只在训练中存在(这个操作使得网络训练速度变得很慢,比v5、v7、v8都慢,训练速度应该是v5>v8>v7>v9),在推理过程中没有复制可逆分支。
多级辅助信息(训练阶段存在,推理中没有)聚合包含所有目标对象的梯度信息,并将其传递给主分支,然后更新参数。此时,主分支特征金字塔层次结构的特征不会由某些特定对象的信息主导。因此,可以缓解深度监督中的破碎信息问题。此外,任何集成网络都可以用于多级辅助信息。因此,可以规划所需的语义级别来指导不同大小的网络架构的学习。(简单来说就是多层特征相加吧)
GELAN

结合了CSPNet和ELAN。
实验结果
对比训练和推理实际耗时(实测)
测试环境 Tesla T4 cuda10.1,三千多张图片训练,训练batchsize统一设置为8,输入图像尺寸640*640。
YOLOv9训练YOLOv9-c时使用train_dual.py进行训练(作者github issue中回复说的YOLOv9训练就需要使用train_dual.py),测试时使用detect_dual.py进行测试。
测试环境 Tesla T4 cuda10.2
| 模型 | 参数量(M) | 运算量(FLOPs) | 训练时间(s) | GPU推理速度(ms) | CPU推理速度(ms) |
|---|---|---|---|---|---|
| YOLOv5-L | 46.1 | 107.7 | 162 | 28.7 | 249.3 |
| YOLOv7 | 36.9 | 104.5 | 196 | 16.4 | 396.4 |
| YOLOv8-L | 43.6 | 165.4 | 181 | 26.6 | 262.4 |
| YOLOv9-c | 50.7 | 236.7 | 405 | 48.9 | 537.1 |
实测有可能我测试有误。
才疏学浅,如有错误欢迎指出!














 350
350











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









