






文章目录
前言
Spark 2.0开始,应用程序入口为SparkSession,加载不同数据源的数据,封装到DataFrame集合数据结构中,使得编程更加简单,程序运行更加快速高效。并且开始提供spark sql和spark dsl形式的编程,更便于理解。
一、SparkSession
1、SparkSession介绍
spark session模式提供了sql和dsl api形式的编程,其操作的数据形式,区别于RDD,被称为dataframe,可以理解成加入schema约束的RDD,即DataFrame = RDD[Row] + Schema。简单理解成为数据添加了行列名称、限制。
2、SparkSession构建
# 1. 获取会话实例对象-session
spark = SparkSession.builder\
.appName('SparkSession Test')\
.master('local[2]')\
.getOrCreate()
print(spark)
# 2. 加载数据源-source
dataframe = spark.read.text('../datas/words.txt')
# 3. 数据转换处理-transformation
# 4. 处理结果输出-sink
dataframe.show(n=10, truncate=False)
# 5. 关闭会话实例对象-close
spark.stop()
3、sql与dsl实现词频统计
sql:
# 1. 获取会话实例对象-session
spark = SparkSession.builder \
.appName('SparkSession Test') \
.master('local[2]') \
.getOrCreate()
# 2. 加载数据源-source
input_df = spark.read.text('../datas/words.txt')
# input_df.printSchema()
# input_df.show(n=10, truncate=False)
"""
root
|-- value: string (nullable = true)
+----------------------------------------+
|value |
+----------------------------------------+
|spark python spark hive spark hive |
|python spark hive spark python |
|mapreduce spark hadoop hdfs hadoop spark|
|hive mapreduce |
+----------------------------------------+
"""
# 3. 数据转换处理-transformation
"""
当使用SQL方式分析数据时,如下2个步骤:
step1、注册DataFrame为临时视图view
step2、编写SQL语句并执行
"""
# step1、注册DataFrame为临时视图view
input_df.createOrReplaceTempView('view_tmp_lines')
# step2、编写SQL语句并执行
output_df = spark.sql("""
WITH tmp AS (
select explode(split(value, ' ')) AS word from view_tmp_lines
)
SELECT word, COUNT(1) AS total FROM tmp GROUP BY word ORDER BY total DESC LIMIT 10
""")
# 4. 处理结果输出-sink
output_df.printSchema()
output_df.show(n=10, truncate=False)
# 5. 关闭会话实例对象-close
spark.stop()
dsl:
# 1. 获取会话实例对象-session
spark = SparkSession.builder \
.appName('SparkSession Test') \
.master('local[2]') \
.getOrCreate()
# 2. 加载数据源-source
input_df = spark.read.text('../datas/words.txt')
"""
root
|-- value: string (nullable = true)
+----------------------------------------+
|value |
+----------------------------------------+
|spark python spark hive spark hive |
|python spark hive spark python |
|mapreduce spark hadoop hdfs hadoop spark|
|hive mapreduce |
+----------------------------------------+
"""
# 3. 数据转换处理-transformation
"""
a. 分割单词,进行扁平化(使用explode)
b. 按照单词分组,使用count函数统计个数
c. 按照词频降序排序,获取前10个
"""
output_df = input_df\
.select(
explode(split(col('value'), ' ')).alias('word')
)\
.groupBy(col('word'))\
.agg(
count(col('word')).alias('total')
)\
.orderBy(col('total').desc())\
.limit(10)
# 4. 处理结果输出-sink
output_df.printSchema()
output_df.show(n=10, truncate=False)
# 5. 关闭会话实例对象-close
spark.stop()
4、spark开发形式发展
1、Spark 1.0之前
- Shark = Hive + Spark
- 将Hive框架源码,修改其中转换SQL为MapReduce,变为转换RDD操作,称为Shark
- 问题:维护成本太高,没有更多精力在于框架性能提升
2、Spark 1.0开始提出SparkSQL模块
- 重新编写引擎Catalyst,将SQL解析为优化逻辑计划Logical Plan
- 此时数据结构:SchemaRDD
3、Spark 1.3版本,SparkSQL成为Release版本
- 数据结构:DataFrame,借鉴于Python和R中dataframe,DataFrame = RDD[Row] + Schema
- 提供外部数据源接口:方便可以从任意外部数据源加载load和保存save数据
4、Spark 1.6版本,SparkSQL数据结构Dataset
- 坊间流传,参考Flink中DataSet数据结构而来,Dataset = RDD + schema
5、Spark 2.0版本,DataFrame和Dataset何为一体
- Dataset = RDD + schema,DataFrame = Dataset[Row]
二、DataFrame
1、dataframe概述
- DataFrame = RDD[Row] + Schema
- DataFrame是特殊RDD分布式集合
- DataFrame是分布式表,类似MySQL数据库中表table、Pandas库中dataframe
在SparkSQL中,DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格。
[DataFrame与RDD的主要区别在于,前者带有schema元信息,即DataFrame所表示的二维表数据集的每一列都带有名称和类型。
Schema封装类:StructType结构化类型,里存储的每个字段封装的类型:StructField结构化字段。
- 其一、StructType 定义,属性为StructField的数组
- 其二、StructField定义,有四个属性,其中字段名称和类型为必填

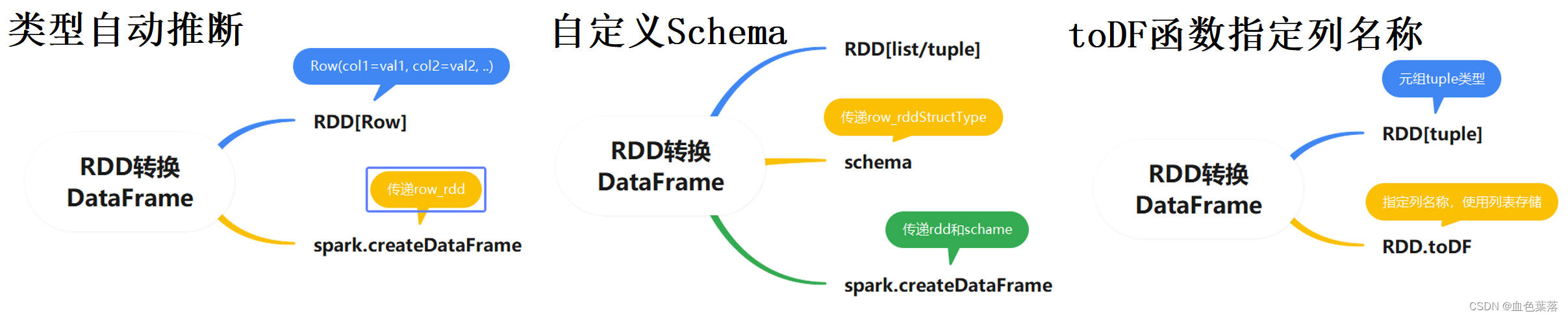
2、dataframe编程
- 通过将读取数据RDD转换成Row()对象构建Dataframe
# 1. 获取会话实例对象-session
spark = SparkSession.builder \
.appName('SparkSession Test') \
.master('local[2]') \
.getOrCreate()
# 2. 加载数据源-source RDD
rating_rdd = spark.sparkContext.textFile('../datas/ml-100k/u.data')
"""
每条数据:196 242 3 881250949
"""
# 3. 数据转换处理-transformation
"""
3-1. 将RDD中每条数据string,封装转换为Row对象
3-2. 直接将Row RDD 转换为DataFrame
"""
row_rdd = rating_rdd\
.map(lambda line: re.split('\\s+', line))\
.map(lambda list: Row(user_id=list[0], movie_id=list[1], rating=float(list[2]), timestamp=int(list[3])))
rating_df = spark.createDataFrame(row_rdd)
# 4. 处理结果输出-sink
rating_df.printSchema()
rating_df.show(n=10, truncate=False)
# 5. 关闭会话实例对象-close
spark.stop()
- 通过处理将RDD数据处理成数据列表,自定义StructFiled集合,传参构建
# 1. 获取会话实例对象-session
spark = SparkSession.builder \
.appName('SparkSession Test') \
.master('local[2]') \
.getOrCreate()
# 2. 加载数据源-source
rating_rdd = spark.sparkContext.textFile('../datas/ml-100k/u.data')
# 3. 数据转换处理-transformation
"""
3-1. RDD[list]
3-2. schema: StructType
3-3. createDataFrame
"""
# 3-1. RDD[list]
list_rdd = rating_rdd\
.map(lambda line: re.split('\\s+', line))\
.map(lambda list: [list[0], list[1], float(list[2]), int(list[3])])
# 3-2. schema: StructType
list_schema = StructType(
[
StructField("user_id", StringType(), True),
StructField("movie_id", StringType(), True),
StructField("rating", DoubleType(), True),
StructField("timestamp", LongType(), True)
]
)
# 3-3. createDataFrame
rating_df = spark.createDataFrame(list_rdd, schema=list_schema)
# 4. 处理结果输出-sink
rating_df.printSchema()
rating_df.show(n=10, truncate=False)
# 5. 关闭会话实例对象-close
spark.stop()
- SparkSQL中提供一个函数:toDF,通过指定列名称,将数据类型为元组的RDD转换为DataFrame
# 1. 获取会话实例对象-session
spark = SparkSession.builder \
.appName('SparkSession Test') \
.master('local[2]') \
.getOrCreate()
# 2. 加载数据源-source
rating_rdd = spark.sparkContext.textFile('../datas/ml-100k/u.data')
# 3. 数据转换处理-transformation
"""
3-1. RDD[tuple]
3-2. toDF()
"""
# 3-1. RDD[tuple]
tuple_rdd = rating_rdd\
.map(lambda line: re.split('\\s+', line))\
.map(lambda list: (list[0], list[1], float(list[2]), int(list[3])))
# 3-2. toDF()
rating_df = tuple_rdd.toDF(['user_id', 'movie_id', 'rating', 'timestamp'])
# 4. 处理结果输出-sink
rating_df.printSchema()
rating_df.show(n=10, truncate=False)
# 5. 关闭会话实例对象-close
spark.stop()
3、dataframe函数
# 1. 获取会话实例对象-session
spark = SparkSession.builder \
.appName('SparkSession Test') \
.master('local[2]') \
.getOrCreate()
# 2. 加载数据源-source
emp_df = spark.read.json('hdfs://node1.itcast.cn:8020/datas/resources/employees.json')
emp_df.printSchema()
emp_df.show(n=10, truncate=False)
# 3. 数据转换处理-transformation
# TODO:count/collect/take/first/head/tail/
emp_df.count()
emp_df.collect()
emp_df.take(2)
emp_df.head()
emp_df.first()
emp_df.tail(2)
# TODO: foreach/foreachPartition
emp_df.foreach(lambda row: print(row))
# TODO:coalesce/repartition
emp_df.rdd.getNumPartitions()
emp_df.coalesce(1).rdd.getNumPartitions()
emp_df.repartition(3).rdd.getNumPartitions()
# TODO:cache/persist
emp_df.cache()
emp_df.unpersist()
emp_df.persist(storageLevel=StorageLevel.MEMORY_AND_DISK)
# TODO: columns/schema/rdd/printSchema
emp_df.columns
emp_df.schema
emp_df.printSchema()
# 5. 关闭会话实例对象-close
spark.stop()
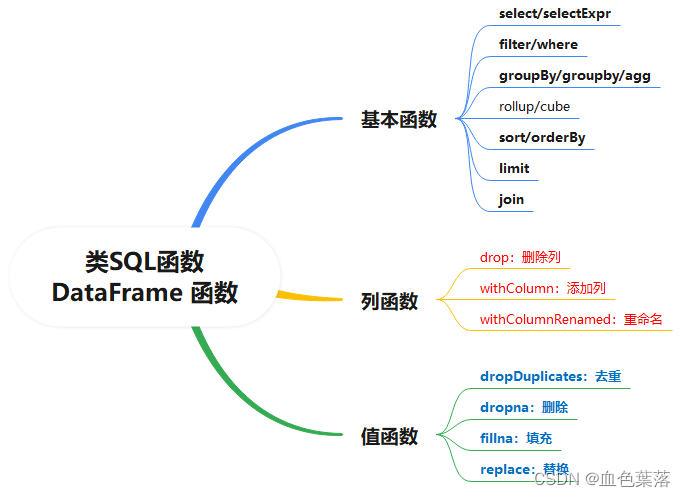
- 类sql函数算子
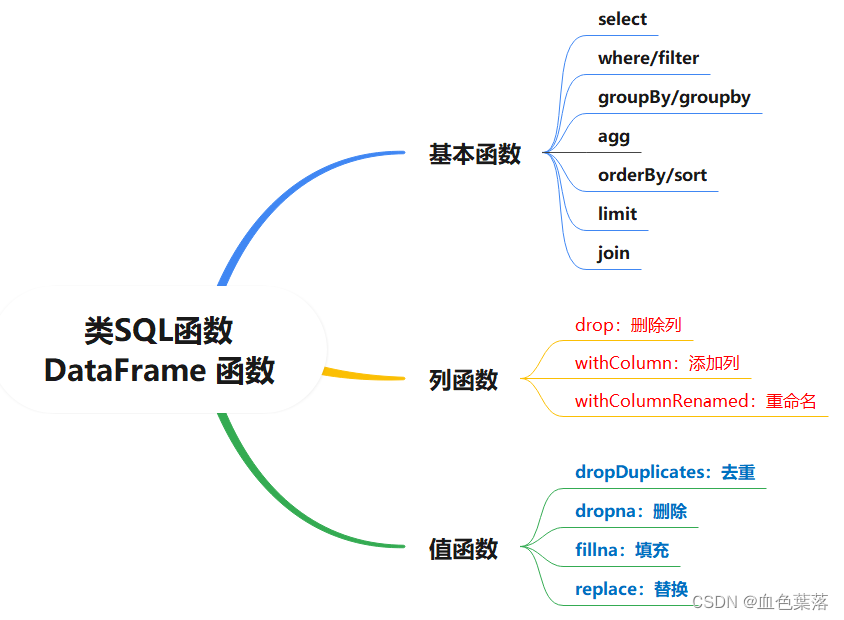
# 1、选择函数select:选取某些列的值
def select(self, *cols: Union[Column, str]) -> DataFrame
# 2、过滤函数filter/where:设置过滤条件,类似SQL中WHERE语句
def filter(self, condition: Union[Column, str]) -> DataFrame
# 3、分组函数groupBy/rollup/cube:对某些字段分组,在进行聚合统计
def groupBy(self, *cols: Union[Column, str]) -> GroupedData
# 4、聚合函数agg:通常与分组函数连用,使用一些count、max、sum等聚合函数操作
def agg(self, *exprs: Union[Column, Dict[str, str]]) -> DataFrame
# 5、排序函数sort/orderBy:按照某写列的值进行排序(升序ASC或者降序DESC)
def sort(self,
*cols: Union[str, Column, List[Union[str, Column]]],
ascending: Union[bool, List[bool]] = ...) -> DataFrame
# 6、限制函数limit:获取前几条数据,类似RDD中take函数
def limit(self, num: int) -> DataFrame
# 7、重命名函数withColumnRenamed:将某列的名称重新命名
def withColumnRenamed(self, existing: str, new: str) -> DataFrame
# 8、删除函数drop:删除某些列
def drop(self, cols: Union[Column, str]) -> DataFrame
# 9、增加列函数withColumn:当某列存在时替换值,不存在时添加此列
def withColumn(self, colName: str, col: Column) -> DataFrame
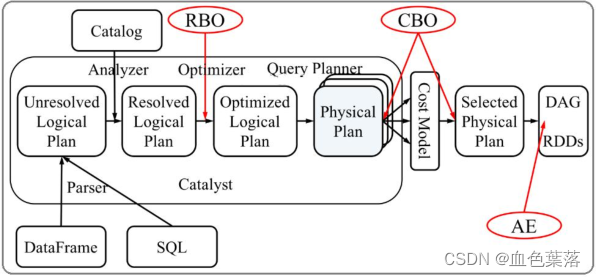
4、Catalyst 优化器
Spark SQL核心是Catalyst优化器,对SQL 或者DSL 代码解析生成逻辑计划,对逻辑计划进行优化的查询优化器。
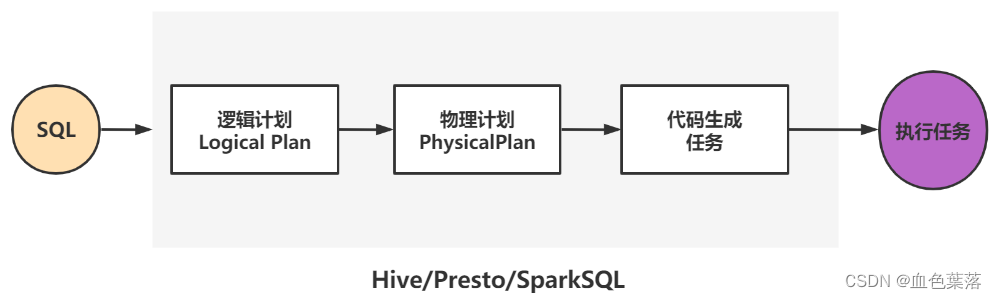
SparkSQL Catalyst 运作原理:对 SQL 或者DSL 代码解析生成逻辑计划,并对逻辑计划进行优化。
- 1)、SQL语句首先通过Parser模块被解析为语法树,此棵树称为Unresolved Logical Plan;
- 2)、Unresolved Logical Plan通过Analyzer模块借助于数据元数据解析为Logical Plan;
- 3)、此时再通过各种基于规则Rule的Optimizer进行深入优化,得到Optimized Logical Plan;
- 4)、优化后的逻辑执行计划依然是逻辑的,需要将逻辑计划转化为Physical Plan。
SparkSQL 内部底层核心,有2种优化:RBO 优化和CBO优化。
- 基于规则优化/Rule Based Optimizer/
RBO; - 基于代价优化/Cost Based Optimizer/
CBO;
5、spark读写外部数据源
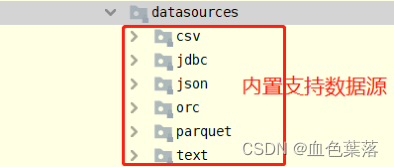
- load加载数据
在SparkSQL中读取数据使用SparkSession读取,并且封装到数据结构DataFrame中,基本格式如下:

SparkSQL模块本身自带支持读取外部数据源的数据:

- save 保存数据
SparkSQL模块中可以从某个外部数据源读取数据,就能向其保存数据,提供相应接口,基本格式如下:

SparkSQL模块内部支持保存数据源如下:

DataFrame数据保存时有一个mode方法,指定保存模式:
- 1、Append 追加模式,当数据存在时,继续追加;
- 2、Overwrite 覆写模式,当数据存在时,覆写以前数据,存储当前最新数据;
- 3、ErrorIfExists 存在及报错;
- 4、Ignore 忽略,数据存在时不做任何操作;
1、从本地文件系统加载JSON格式数据,保存为Parquet格式:
# 1. 获取会话实例对象-session
spark = SparkSession.builder \
.appName('SparkSession Test') \
.master('local[2]') \
.getOrCreate()
# 2. 加载数据源-source
# TODO: 第1、加载JSON格式数据
json_df = spark.read\
.format('json')\
.option('path', '../datas/resources/employees.json')\
.load()
# json_df.printSchema()
# json_df.show()
# 4. 处理结果输出-sink
# TODO: 第2、保存Parquet格式数据
json_df.write\
.mode('overwrite')\
.format('parquet')\
.option('path', '../datas/resources/emp-parquet')\
.save()
# 5. 关闭会话实例对象-close
spark.stop()
2、加载文本数据和保存数据到文本文件中:
# 1. 获取会话实例对象-session
spark = SparkSession.builder \
.appName('SparkSession Test') \
.master('local[2]') \
.getOrCreate()
# 2. 加载数据源-source
dataframe = spark.read.text('../datas/resources/people.txt')
dataframe.printSchema()
dataframe.show(truncate=False)
# 3. 数据转换处理-transformation
# 4. 处理结果输出-sink
dataframe.write.mode('overwrite').text('../datas/save-text')
# 5. 关闭会话实例对象-close
spark.stop()
3、加载文本JSON格式数据,并保存:
# 1. 获取会话实例对象-session
spark = SparkSession.builder \
.appName('SparkSession Test') \
.master('local[2]') \
.getOrCreate()
# 2. 加载数据源-source
json_df = spark.read.json('../datas/resources/people.json')
# json_df.printSchema()
# json_df.show()
# 3. 数据转换处理-transformation
# 4. 处理结果输出-sink
json_df.coalesce(1).write.mode('overwrite').json('../datas/save-json')
# 5. 关闭会话实例对象-close
spark.stop()
4、加载Parquet格式数据包保存数据为Parquet存储:
# 1. 获取会话实例对象-session
spark = SparkSession.builder \
.appName('SparkSession Test') \
.master('local[2]') \
.getOrCreate()
# 2. 加载数据源-source
parquet_df = spark.read.parquet('../datas/resources/users.parquet')
# parquet_df.printSchema()
# parquet_df.show()
# TODO: 不指定数据格式,加载parquet 数据
df = spark.read.load('../datas/resources/users.parquet')
# df.printSchema()
# df.show()
# 3. 数据转换处理-transformation
# 4. 处理结果输出-sink
parquet_df.coalesce(1).write.mode('overwrite').parquet('../datas/save-parquet')
# 5. 关闭会话实例对象-close
spark.stop()
5、加载csv文本数据和保存数据为csv格式:
# 1. 获取会话实例对象-session
spark = SparkSession.builder \
.appName('SparkSession Test') \
.master('local[2]') \
.getOrCreate()
# 2. 加载数据源-source
csv_df = spark.read.csv(
'../datas/resources/people.csv', sep=';', header=True, inferSchema=True
)
csv_df.printSchema()
csv_df.show()
# 3. 数据转换处理-transformation
# 4. 处理结果输出-sink
csv_df.coalesce(1).write.mode('overwrite').csv('../datas/save-csv', sep=',', header=True)
# 5. 关闭会话实例对象-close
spark.stop()
6、加载数据库表数据,选择字段后,再次保存数据库表中:
# 1. 获取会话实例对象-session
spark = SparkSession.builder \
.appName('SparkSession Test') \
.master('local[2]') \
.getOrCreate()
# 2. 加载数据源-source
props = { 'user': 'root', 'password': '123456', 'driver': 'com.mysql.jdbc.Driver'}
jdbc_df = spark.read.jdbc(
'jdbc:mysql://127.0.0.1:3306/?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true',
'db_company.emp',
properties=props
)
jdbc_df.printSchema()
jdbc_df.show(n=20, truncate=False)
# 3. 数据转换处理-transformation
dataframe = jdbc_df.select('empno', 'ename', 'job', 'sal', 'deptno')
# 4. 处理结果输出-sink
dataframe.coalesce(1).write.mode('append').jdbc(
'jdbc:mysql://127.0.0.1:3306/?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true',
'db_company.emp_v2',
properties=props
)
# 5. 关闭会话实例对象-close
spark.stop()
7、从Hive表加载数据,并且将数据保存到Hive表:
# 1. 获取会话实例对象-session
spark = SparkSession.builder \
.appName('SparkSession Test') \
.master('local[2]') \
.config("spark.sql.warehouse.dir", 'hdfs://127.0.0.1:8020/user/hive/warehouse') \
.config('hive.metastore.uris', 'thrift://127.0.0.1:9083') \
.enableHiveSupport()\
.getOrCreate()
# 2. 加载数据源-source
emp_df = spark.read.format('hive').table('db_hive.emp')
emp_df.printSchema()
emp_df.show(n=20, truncate=False)
# 3. 数据转换处理-transformation
# 4. 处理结果输出-sink
emp_df.coalesce(1)\
.write\
.format('hive')\
.mode('append')\
.saveAsTable('db_hive.emp_v2')
# 5. 关闭会话实例对象-close
spark.stop()
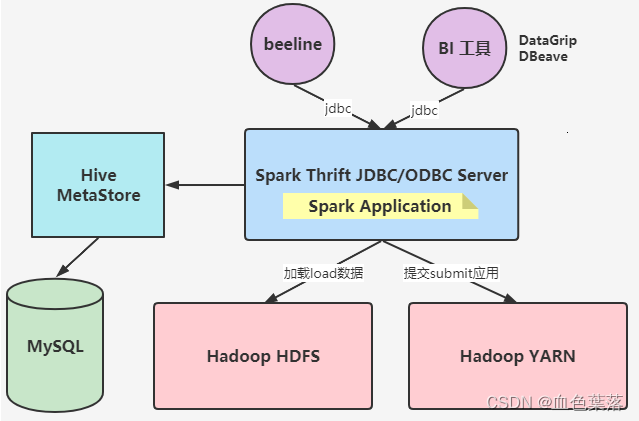
6、spark连接hive表的两种方式
通过类似于bin/hive形式连接
- /export/server/spark-local/bin/spark-sql --master local[2] --conf spark.sql.shuffle.partitions=2
利用Spark Thrift JDBC/ODBC Server服务,通过beeline连接
- /export/server/spark-local/sbin/start-thriftserver.sh
–hiveconf hive.server2.thrift.port=10000
–hiveconf hive.server2.thrift.bind.host=127.0.01
–master local[2]
–conf spark.sql.shuffle.partitions=2
7、自定义函数
-
第一类函数: 输入一条数据 -> 输出一条数据(1 -> 1)
split 分割函数
round 四舍五入函数 -
第二类函数: 输入多条数据 -> 输出一条数据 (N -> 1)
count 计数函数
sum 累加函数
max/min 最大最小函数
avg 平均值函数 -
第三类函数:输入一条数据 -> 输出多条数据 (1 -> N)
explode 爆炸函数
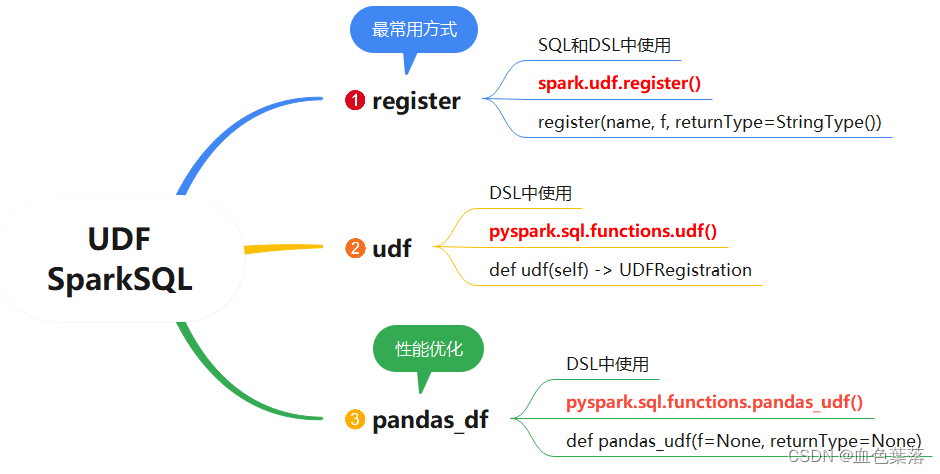
1、对于register注册的UDF函数,再spark sql使用时,通过函数自定义名称使用,在dsl使用时,通过变量名使用:
# 1. 获取会话实例对象-session
spark = SparkSession.builder \
.appName('SparkSession Test') \
.master('local[2]') \
.getOrCreate()
# 2. 加载数据源-source
people_df = spark.read.json('../datas/resources/people.json')
# people_df.printSchema()
# people_df.show(n=10, truncate=False)
# 3. 数据转换处理-transformation
"""
将DataFrame数据集中name字段值转换为大写UpperCase
"""
# TODO: 注册定义函数
upper_udf = spark.udf.register(
'to_upper',
lambda name: str(name).upper()
)
# TODO:在SQL中使用函数
people_df.createOrReplaceTempView("view_tmp_people")
spark\
.sql("""
SELECT name, to_upper(name) AS new_name FROM view_tmp_people
""")\
.show(n=10, truncate=False)
# TODO:在DSL中使用函数
people_df\
.select(
'name', upper_udf('name').alias('upper_name')
)\
.show(n=10, truncate=False)
# 4. 处理结果输出-sink
# 5. 关闭会话实例对象-close
spark.stop()
2、通过pyspark.sql.functions.udf注册,仅在dsl中使用:
# 1. 获取会话实例对象-session
spark = SparkSession.builder \
.appName('SparkSession Test') \
.master('local[2]') \
.getOrCreate()
# 2. 加载数据源-source
people_df = spark.read.json('../datas/resources/people.json')
# people_df.printSchema()
# people_df.show(n=10, truncate=False)
# 3. 数据转换处理-transformation
"""
将DataFrame数据集中name字段值转换为大写UpperCase
"""
# TODO: 注册定义函数,采用编程:封装函数
upper_udf = F.udf(
f=lambda name: str(name).upper(),
returnType=StringType()
)
# 在DSL中使用
people_df\
.select(
'name', upper_udf('name').alias('name_new')
)\
.show()
# 4. 处理结果输出-sink
# 5. 关闭会话实例对象-close
spark.stop()
3、pandas_udf(),用于定义和注册UDF函数,底层使用列存储和零复制技术提高数据传输效率,在PySpark SQL中建议使用:
# 1. 获取会话实例对象-session
spark = SparkSession.builder \
.appName('SparkSession Test') \
.master('local[2]') \
.config('spark.sql.execution.arrow.pyspark.enabled', 'true')\
.getOrCreate()
# 2. 加载数据源-source
people_df = spark.read.json('../datas/resources/people.json')
# people_df.printSchema()
people_df.show(n=10, truncate=False)
# 3. 数据转换处理-transformation
"""
将DataFrame数据集中name字段值转换为大写UpperCase
"""
# TODO: 注册定义函数,装饰器方式
@F.pandas_udf(StringType())
def func_upper(name: pd.Series) -> pd.Series:
return name.str.upper()
# 在DSL中使用
people_df\
.select(
'name', func_upper('name').alias('upper_name')
)\
.show()
# 4. 处理结果输出-sink
# 5. 关闭会话实例对象-close
spark.stop()
8、与pandas相互转换
# 1. 获取会话实例对象-session
spark = SparkSession.builder \
.appName('SparkSession Test') \
.master('local[2]') \
.getOrCreate()
# step1、使用pandas加载JSON数据
pandas_df = pd.read_csv('../datas/resources/people.csv', sep=';')
print(pandas_df)
print('*' * 40)
# TODO: step2、转换pandas DataFrame为 SparkSQL DataFrame
spark_df = spark.createDataFrame(pandas_df)
spark_df.printSchema()
spark_df.show()
print('*' * 40)
# TODO: step3、转换SparkSQL DataFrame为 pandas DataFrame
data_frame = spark_df.toPandas()
print(data_frame)
# 5. 关闭会话实例对象-close
spark.stop()
总结
spark sql与dsl时2.0完善的新特性,极大方便了spark数据分析流程。
时光如水,人生逆旅矣。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









