







论文笔记–GCC: Graph Contrastive Coding for Graph Neural Network Pre-Training
简介:KDD 2020发表的一篇关于预训练应用在图神经网络的论文,目前引用量120+。目标是学习一个初始化的GNN encoder,但是实验效果不佳, GCC 表现逼进甚至不如目前的GIN。论文链接🔗
摘要
图表征学习(Graph representation learning)已经成为解决现实问题的一种强有力的技术。各种下游图学习任务如 node classification, similarity search and graph classification,都得益于其最新发展。然而,现有的图表征学习技术方法主要关注于特定问题,并为每个图数据集训练一个专用模型,该模型通常在其他领域数据上不work。
受NLP和CV的最新进展的影响,我们设计了 GCC —— 一种自监督图神经网络预训练框架 —— 以捕获跨多个网络的通用网络拓扑结构特性。我们将GCC的预训练任务设计为 网络内和跨网络的 subgraph instance discrimination ,并利用对比学习(Contrastice learning)使图形神经网络能够学习 内在的和可转移的结构表示。
本文在三个图学习任务和十个图数据集上进行了广泛的实验。结果表明,在一组不同的数据集上预先训练的GCC,对于特定任务, 可以获得与baseline 相似的或更好的性能。这表明pre-training和fine-tuning范式为图形表表征学习提供了巨大的潜力。
1 引言
Hypothesis. Representative graph structural patterns are universal and transferable across networks.
在过去二十年中, network science research的主要焦点一直是discover和abstracting不同网络背后的普遍结构特性。然而,在过去几年中,Graph learning的范式已经从结构模式发现转变为Graph representation learning ,这是由深度学习的最新进展推动的。具体的说,Graph representation learning将图的顶点、边或子图转换为低维嵌入,从而保留图的重要结构信息。然后可以将学习到的嵌入输入到下游任务的机器学习模型中。
然而到目前为止,大多数图表示学习的工作都集中于学习a signal graph 或 a fixed set of graphs的表示,在跨任务的研究上很少。本质上,这些representation learning models旨在针对每个数据集学习特定的网络结构模式。例如,在Facebook社交图网络上学习到的 DeepWalk embedding model不能应用于其他图上面。这里自然而然就引出了一个问题: can we universally learn transferable representative graph embeddings from networks?
在NLP、CV和其他领域也提出了类似的问题。迄今为止,最好的解决方案是在self-supervised的环境下,在 a large dataset 上 预训练 a representation learning model。预训练的核心是使用预训练的模型作为一个良好的初始化,以便对没有见过的数据集上的任务进行微调。例如,BERT设计了语言模型预训练任务,以从大型语料库中学习Transformer编码器然后通过微调,使预先训练的Transformer编码器适应各种NLP任务。
受这一点和通用图结构模式的启发,我们研究了预训练representation learning model,特别是GNN方向上的。理想情况下,给定一组(多样化的)输入图,如Facebook社交图和DBLP co-atuhor图,我们的目标是使用self - supervised 任务对GNN进行预训练,然后针对不同的图学习任务对其进行微调。在GNN上预训练的关键问题是:如何设计预训练任务,以捕获 网络中 和 跨网络 的通用结构特征?
本文我们提出了Graph Contrastive Coding(GCC)框架来学习跨图形的结构表示。相反,我们利用对比学习的思想设计了图预训练任务作为实例识别。它的基本思想是从输入图中抽取instance,将它们视为自己的一个不同类,并学习对这些实例进行编码和区分。GCC需要回答三个问题,以便它能够学习 the transferable structural patterns:(1) what are the instances? (2) what are the discrimination rules? (3) how to encode the instances?
在GCC中,我们将预训练任务设计为subgraph instance discrimination。其目标是根据顶点的局部结构来区分顶点(参见图1)。对于每个顶点,我们从 multi-hop ego network采样子图作为instance。GCC旨在区分从某个顶点采样的子图和从其他顶点采样的子图。最后对于每个子图,使用一个图形神经网络(ex GIN模型)作为图形编码器,将底层结构模式映射到潜在表示。由于GCC不假设顶点和子图来自同一个图,因此graph encoder 必须捕获不同输入子图的通用结构信息。给定预先训练好的GCC模型,我们将其应用于新的图数据上处理下游任务。

主要贡献:
- 我们将 跨多个图的 GNN 预训练 问题公式化,并确定其存在主要挑战(难点)。
- 我们将预训练任务设计为Graph representation learning ,以从多个输入图中捕获通用和可转移的结构特征。
- 我们提出GCC框架来学习 structural graph representations,该框架是利用 contrastive learning 来指导训练。
- 我们进行了大量实验,以证明对于跨领域的任务,GCC可以提供与 特定任务领域的模型 近似或更高的性能。
2 相关工作
节点相似性;对比学习;图pre- training;(由于对此部分背景知识不熟悉,所以就不展开啦,以防误导大家😄)
3 GRAPH CONTRASTIVE CODING (GCC)
在本节中,我们将图形神经网络 预训练问题形式化。为了解决这个问题,我们提出了GCC框架。图2概述了GCC的与预训练和微调两阶段。
3.1 The GNN Pre-Training Problem
从概念上讲,给定一组来自不同领域的图,我们的目标是预训练GNN模型,以self-supervised的方式捕获这些图中的结构特征。该模型应该能够使不同数据集上的下游任务受益。基本假设是,不同的graph之间存在着 common and transferable structural patterns,例如主题,这在网络科学文献中是显而易见的。一个易于理解的场景,我们在Facebook、IMDB和DBLP图上预先训练一个GNN模型,并进行self-supervised学习,然后将其应用于 US-Airport network图的节点分类任务,如图2所示。

形式上,GNN预训练问题是学习将顶点映射到低维特征向量的函数f,且f具有以下两个特性:
- structural similarity:它的映射需满足,在向量空间中,具有相似局部网络拓扑的顶点距离较近
- transferability:它是与预训练时没有见过的顶点和图是兼容的
因此,满足以上两点的函数f可用于各种图学习任务中,如社会角色预测、节点分类和图分类。
特别注意⚠️,本文工作的重点是在没有节点属性和节点标签的情况下进行structural representation learning,与普通图形神经网络研究中的常见问题设置不同。此外,我们的是预训练一个structural representation 模型,并将其应用于新的图数据集,这与传统GNN网络不同。
3.2 GCC Pre-Training
给定一组图,我们的目标是预先训练一个通用图神经网络编码器,以捕获这些图背后隐藏的结构特征。为了实现这一点,我们需要为图结构数据设计适当的自监督任务和学习目标。受对比学习在NLP和CV领域应用的影响,我们使用 subgraph instance discrimination 作为我们的预训练任务,使用InfoNCE作为我们的学习目标。预训练任务将每个子图instance视为其自身的一个不同类,并学习区分这些实例。预训练后它可以输出 子图实例之间相似性的表示。
从字典查找的角度来看,给定一个encode query *q *和一个 有 K+1个encode keys {k_0,···,k_K}的字典,对比学习在字典中查找与query q匹配的一个 key(由K+表示)。我们采用InfoNCE作为目标函数:

(InfoNCE 主要用在自监督学习中作为一个对比损失函数, 核心思想 就是通过学习数据分布样本和噪声分布样本之间的区别,从而发现数据中的一些特性;)
直观的理解:query * key 有的地方称互信息,这篇文章在后面直接定义q*k为相似度。目标是Loss最小化,即log 取对数的部分值越大越好,通过学习使querk q 和 K+(字典中与q匹配的key)相似度最大。
为了实现上述目标,我们需要解决三个问题:
-
Q1: How to define subgraph instances in graphs?
-
Q2: How to define (dis) similar instance pairs in and across graphs,
i.e., for a query xq , which key xk is the matched one?
-
Q3: What are the proper graph encoders fq and fk ?
值得注意的是,在我们的问题设置中,xq 和 xk 不一定来自同一个图
Q1: Design (subgraph) instances in graphs.
CV and NLP tasks 中的 instance 可以直接定义成 an image or a sentence,但是在GNN中不能直接定义实例的。此外我们的预训练的重点仅仅是纯粹的structural representation,没有额外的节点特征属性输入,所以选择单个顶点作为instance是不可行的,因为它不适用于区分两个顶点。
为了解决这个问题,我们建议通过将每个顶点扩展到其局部结构,使用子图作为对比instance。具体讲,对于某个顶点v,我们将一个instance定义为它的 r-ego network:


图3左显示了2-ego network 的两个instane。GCC将每个r-ego网络视为其自身的一个不同类,并对模型进行改进,以区分相似的instance和不同的instance。

Q2: Define (dis)similar instances.
在CV中,同一图像的两个随机数据扩充data augmentation(例随机裁剪、随机调整大小、随机颜色抖动、随机翻转等)被视为相似的instance。在GCC中,我们考虑两个随机数据扩充,即相同的r-ego network作为一个相似的instance pair,并定义数据扩充作为graph sampling 。图采样是一种从原始图中提取 representative subgraph samples的技术。假设我们想扩充顶点v的r-ego网络,遵循以下三个步骤:
- **Random walk with restart:**我们从顶点v开始在G上随机游动。行走以与 边缘权重成比例的概率 迭代地移动到其相邻位置。此外,在每一步,以正概率行走返回起始顶点v。
- Subgraph induction:重新随机行走收集v周围顶点的子集,用 Sv '表示,然后将 由Sv '推出的子图Gv’视为r-ego network Gv的扩充版本。这一步也称为Induced Subgraph Random Walk Sampling (ISRW).
- Anonymization. 我们通过以任意顺序重新标记其顶点为 {1, 2, · · · , |Sv’|}, 将采样的图匿名化。因为我们需要学习的是一个结构特征,不包含节点时序性。这种设计避免了学习Subgraph instance discrimination的简单解决方案,即简单地只检查两个子图的顶点索引是否匹配。
我们重复上述过程两次以创建两个数据扩充,它们形成一个相似的instance pair( xq,x(k+) )。如果两个子图是从不同的r-ego network 扩充而来,我们将它们视为一个dissimilar instace pair(xq,xk)。特别注意的是上诉三个步骤都可以用DGL实现。
Q3: Define graph encoders.
给定两个采样子图 xq 和 xk ,GCC通过两个GNN encoder fq 和fk 对其进行编码.
从技术上讲,这里可以使用任何图形神经网络都可以作为作为编码器,GCC模型对不同的选择不敏感。在实践中,我们采用GIN,一种最先进的图神经网络模型,作为我们的图编码器。回想一下,我们专注于结构表示预训练,而大多数GNN模型需要顶点的特征/属性作为输入。为了弥补这一差距,我们建议利用每个采样子图的图结构来初始化顶点特征。具体而言,我们定义***generalized positional embedding*** 如下:

简单讲,利用拉普拉斯方程求特征向量,来表示位置编码。除了generalized positional embedding,我们还添加了顶点度的一个one-hot编码 和 the binary indicator of the ego vertex作为顶点特征。在通过图encoder编码后,最终的 d-dimensional output vectors 然后通过其L2范数进行归一化。
A running example.
图3中展示了GCC预训练的运行示例。为简单起见,我们将字典大小设置为3。GCC首先从图3左侧的2-ego网络中随机扩充两个子图xq和xk0。同时,另外两个子图xk1和xk2,是根据a noise distribution生成的–在本例中,它们是从图3左侧上的另一个2-ego网络随机扩充而来的。然后是两个图编码器,fq和fk,将query 和三个 key 映射到低维向量–q 和 {***k0,k1,k2***}。最后,公式1中的对比损失 鼓励模型将(xq,xk0)识别为similar pair 对,并将其与dissimilar instace (即{xk1,xk2})区分开来。

Learning.
在对比学习中,我们需要维护一个大小为K的字典和编码器。但要想计算上述损失函数,最理想的情况是把所有负例加入字典中进行计算,这样会导致K极大,难以维护。为了保证模型的效率,我们参考了MoCo (He et al., 2020)的方法加入动量对比学习(momentum contrast)。在MoCo的方法中,为了增大字典大小K,需要维护一个负样本的队列,队列中包含此前训练过的batch的样本作为负例。此外,只有q 的编码器fq的参数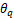 通过反向传递更新,而k的编码器fk的参数
通过反向传递更新,而k的编码器fk的参数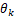 则通过以下方式更新
则通过以下方式更新

其中m指的是动量,通过超参数设定。对GCC而言,MoCo相较其他方法更为高效。
3.3 GCC Fine-Tuning
Downstream tasks.
图形学习中的下游任务一般分为图形级和节点级两类,其目标分别是预测图或节点的标签.对于 graph-level tasks, GCC可以对输入图本身进行编码以获得其 graph representation。通过编码其 r-ego networks (或从其r-egonetwork 扩充的子图)定义 node representation。在这两种情况下,编码的representations 输入下游任务以预测特定于任务的输出。
Freezing vs. full fine-tuning
两者区别:(下游任务的)分类器 和 (预训练的)encoder 是否一起训练。一起训练的是 full fine-tuning,Freezing 是先训练好 graph encoder fq.

4 Experiment
我们做了一系列的实验去验证GCC的效果,其中节点分类、图分类和相似性检索等等。实验结果分别如下:




从实验结果不难看出,GCC在多个任务多个数据集上都取得了比较突出的表现(看实验结果数据并没有多好),和现有最优模型相比能够取得更优或相近的表现。这也表现了GCC的有效性。
5 Conclusion
综上所述,本文提出的GCC的图神经网络预训练框架利用对比学习的方法,有效地学习了图结构的通用表征征,并且学习到图的结构化信息,可以迁移到各类下游任务和各类图中。实验表明了该方法的有效性。未来我们会在更多的任务和实验上进行实验,并探索GCC在其他领域的应用。















 388
388











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









