






刚开始学怎么看论文,想记录一下,如果有大佬发现我的看论文思路有问题还请点明,欢迎一起交流
基于滑动窗口的分布式轨迹流聚类
摘要
问题
对于轨迹流数据的聚类问题,轨迹流数据增长速度快,现有的分布式数据聚类没有在轨迹数据上应用过。
现有分布式聚类将轨迹数据直接传输到总站再进行聚类,传输的开销比较大。
挑战
- 轨迹流数据是随着时间无限增长的,选择通过滑动窗口切割轨迹数据流让无限变有限。
- 轨迹数据是偏态分布的,如何在各局部节点对轨迹进行聚类?
- 节省通信开销。
本文工作(论文创新)
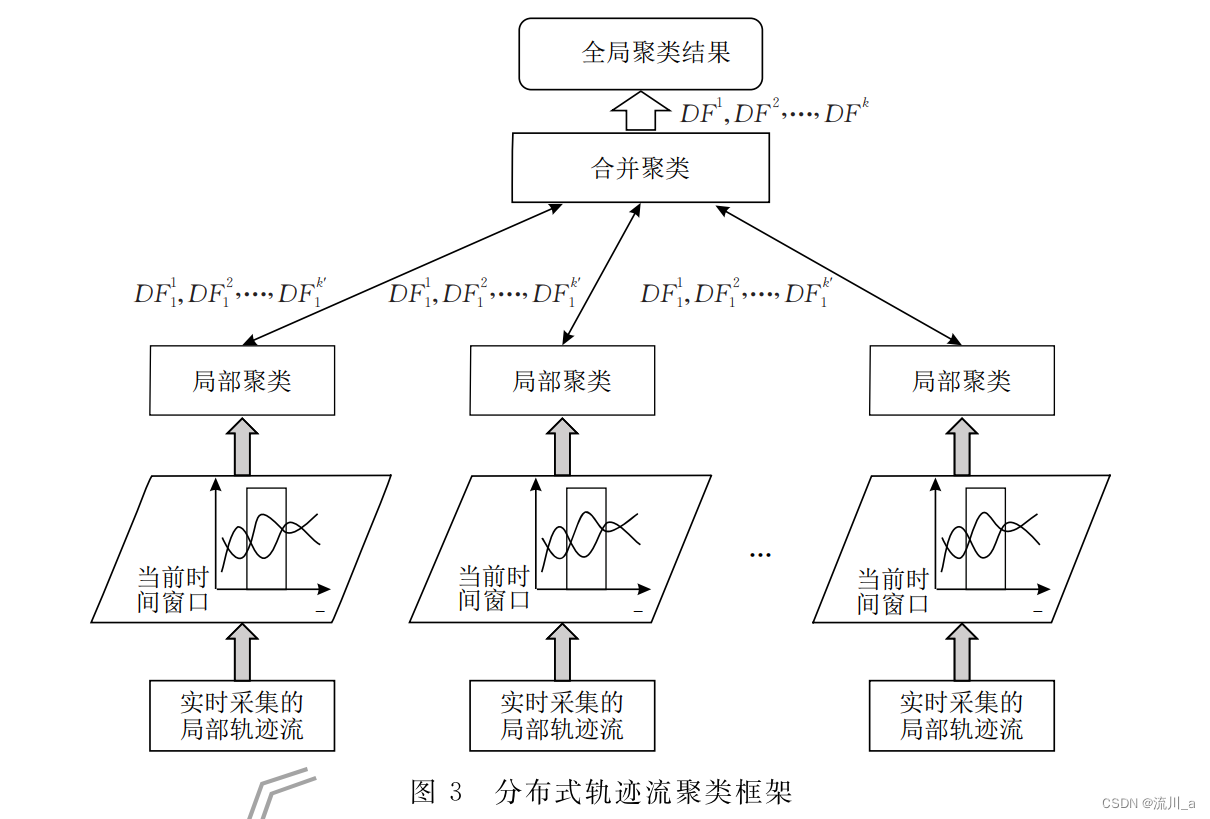
局部轨迹流聚类
- 定义远程节点一个和协调者节点M个
1.1远程节点
远程节点采用滑动窗口接收一段时间W内增加的局部轨迹流(Si),对到达同一窗口内的轨迹线段进行相似性度量并进行聚类。
 为降低远程节点和协调者之间的通信,降低局部聚类结果大小(或许可以理解为压缩了提取的特征)。
为降低远程节点和协调者之间的通信,降低局部聚类结果大小(或许可以理解为压缩了提取的特征)。
1.2. 协调者节点
协调者节点负责接受用户的聚类需求以及输出全局聚类结果
两节点需要统一输出的数据结构:DF用以描述聚类结果

模型架构
伪算法
没看懂,跳过了
在这里插入代码片
全局聚类
对可能拆开了原本属于同一类轨迹的局部聚类结果进行再次聚类
算法分析与优化
- 在协调节点合并的时候,面对k’个远程节点聚类结果两两比较开销较大,考虑到同一时刻不相邻的轨迹段必不属于同类,可以减少非相邻轨迹段的比较。
- 远程节点增加,传输通信消耗增加。考虑到轨迹数据具有偏态分布性质,则当前时刻聚类结果没有变化的远程节点不需要传输数据(采用averagessq判断聚类结果是否有变化)

评估
有效性评估
以作者本人的上一篇相关文章作为比较背景,Trajectory Stream Clustering over Sliding Window ,改变窗口大小(时间),比较两方法的ASSQ判断聚类的有效性
,改变窗口大小(时间),比较两方法的ASSQ判断聚类的有效性
性能评估
· 时间
两算法相比较(聚类时间+传送通信时间)
本算法改变:
- 随着轨迹数据流增加改变远程节点个数
- 随着轨迹数据流增加改变聚类数k值(验证算法对聚类数的敏感性,即算法的鲁棒性)
结论
本文基于Spark Streaming计算框架,以减少通信开销为目标,提出了OCluDTS算法。
远程节点聚类增量数据,协调节点合并聚类,保证分布式聚类的精度;此外对结果进行剪枝优化?














 1888
1888











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









