







文章目录
前言
这学期刚开始的时候买了一本《MySQL是怎样运行的——从根儿上理解MySQL》,看完之后得知MIT有一门用Java编写的简单数据库lab,遂决定试试手,中间做课题组的实验整理数据花了挺多时间,但还是断断续续的抽空完成了MIT6.830。在这个过程中网上一些先辈的实验报告对我起了很大的帮助,我也准备将其整理出来,也当自己再了解一遍。
一、关于MIT6.830?
SimpleDB consists of:
Classes that represent fields, tuples, and tuple schemas; Classes that
apply predicates and conditions to tuples; One or more access methods
(e.g., heap files) that store relations on disk and provide a way to
iterate through tuples of those relations; A collection of operator
classes (e.g., select, join, insert, delete, etc.) that process
tuples; A buffer pool that caches active tuples and pages in memory
and handles concurrency control and transactions (neither of which you
need to worry about for this lab); and, A catalog that stores
information about available tables and their schemas. SimpleDB does
not include many things that you may think of as being a part of a
“database.”
In particular, SimpleDB does not have:
(In this lab), a SQL front end or parser that allows you to type
queries directly into SimpleDB. Instead, queries are built up by
chaining a set of operators together into a hand-built query plan (see
Section 2.7). We will provide a simple parser for use in later labs.
Views. Data types except integers and fixed length strings. (In this
lab) Query optimizer. (In this lab) Indices.
二、lab1
1.Exercise 1
Exercise 1主要是让我们去实现数据库的Tuples和TupleDesc,其中Tuples由一组 Field 对象组成,Field 是不同数据类型(例如,整数、字符串)实现的接口。Tuple 对象由底层访问方法(例如,堆文件或 B 树)创建。关于本节的概念可以用如下表格描述
| id(int) | name(string) |
|---|---|
| 1 | xxx |
| 2 | yyy |
那么(1, xxx)就是一个Tuples,其中的值就是Field,然后TupleDesc是(id(int) , name(string))。
2.Exercise 2
Exercise 2是去实现数据库里的Catalog,顾名思义就是为数据库添加一个目录,可以去访问所有表的集合。Catalog全局目录是为整个 SimpleDB 进程分配的单个实例。全局目录可以通过方法Database.getCatalog()检索
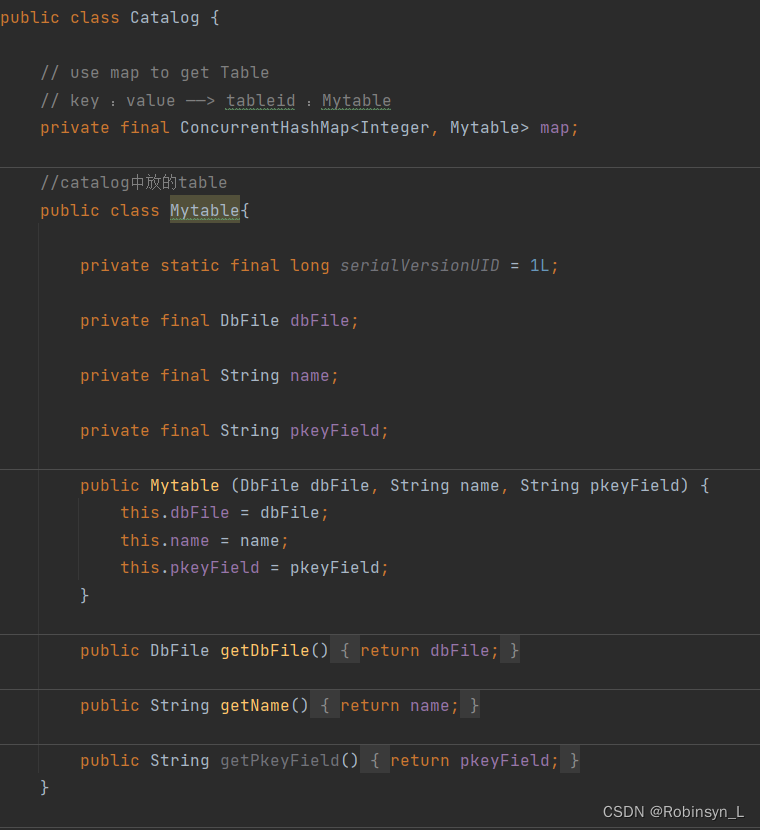
我们可以看到,在Catalog类中持有一个线程安全的Map,其键为存的表ID、值为对应表
3.Exercise 3
Exercise 2是去实现数据库里的BufferPool,BufferPool (缓冲池)负责在内存中缓存最近从磁盘读取的页面,lab1中不需要考虑驱逐脏页。
public Page getPage(TransactionId tid, PageId pid, Permissions perm)
throws TransactionAbortedException, DbException {
// some code goes here
// Page page = map.get(pid);
// if (page == null) {
// page = Database.getCatalog().getDatabaseFile(pid.getTableId()).readPage(pid);
// addToBufferPool(pid, page);
// }
//
// return page;
long st = System.currentTimeMillis();
while (true) {
//获取锁,如果获取不到会阻塞
if (lockManager.acquireLock(tid, pid, perm)) {
break;
}
long now = System.currentTimeMillis();
if (now - st > 500) throw new TransactionAbortedException();
}
if (lruCache.get(pid) == null) {
DbFile databaseFile = Database.getCatalog().getDatabaseFile(pid.getTableId());
Page page = databaseFile.readPage(pid);
addToBufferPool(pid, page);
return page;
} else {
return lruCache.get(pid);
}
}
在刚开始做这个lab的时候我是使用了一个ConcurrentHashMap<PageId, Page>来保存页ID及其对应的页,后来要实现驱逐策略,改用了用一个LRU缓存来保存。两种方法的基本思路都是先看BufferPool中是否有目标页,如果没有则调用Catalog找到对应的表文件,使用readPage得到目标页。
4.Exercise 4
Exercise 4需要实现以下三个类:
src/java/simpledb/storage/HeapPageId.java
src/java/simpledb/storage/RecordId.java
src/java/simpledb/storage/HeapPage.java
我们的表是以HeapFile的文件形式存在我们的硬盘上,而HeapFile由多个HeapPage组成,每一个HeapPage拥有唯一的标识HeapPageID,表征其是哪个表(tableID)的第几页(pagNo),这里的tableID由f.getAbsoluteFile().hashCode()给出。在HeapPage中,存放的是我们的记录,在HeapPage中的数据由由header和tuples两个数组组成,其中tuples表示插入的每一条记录,每一条记录对应一个slot,而header以bitmap的形式来表示第i个slot是否被占用,最低位表示第一个slot是否被占用。

这里用知乎@少年弈画的图表示上述关系。
每个HeapPage能放多少条记录,其中slot又占用多少字节在实验讲义里都写得很清楚,这里就不在赘述。
5.Exercise 5
这部分就是去实现HeapFile类了,前面有提到在缓冲池中如果没有目标页面,则需要调用全局目录得到对应的表,调用readPage得到目标页,具体实现如下:
public Page readPage(PageId pid) {
// some code goes here
long offset = pid.getPageNumber() * BufferPool.getPageSize();
byte[] data = new byte[BufferPool.getPageSize()];
try {
RandomAccessFile rFile = new RandomAccessFile(file, "r");
rFile.seek(offset);
for (int i = 0; i < BufferPool.getPageSize(); i++) {
data[i] = (byte) rFile.read();
}
int tableID = pid.getTableId();
int pageNumber = pid.getPageNumber();
HeapPageId hpid = new HeapPageId(tableID, pageNumber);
HeapPage page = new HeapPage(hpid, data);
rFile.close();
return page;
} catch (Exception e) {
return null;
}
}
首先计算出目标页在HeapFile中的偏移量,新建一个data数组准备存数据,这里提一下由于RandomAccessFile可以自由访问文件的任意位置,所以如果需要访问文件的部分内容,而不是把文件从头读到尾,使用RandomAccessFile将是更好的选择。将读取到的数据封装到HeapPage返回。
除此之外还要实现 HeapFile.iterator() 方法,该方法应该遍历 HeapFile 中每个页面的记录。迭代器必须使用 BufferPool.getPage() 方法来访问 HeapFile 中的页面。这里的实现是先从BufferPool 中读取数据,读取不到再从磁盘中读,不要在 open() 调用时将整个表加载到内存中——这将导致非常大的表出现内存不足错误。也就是说,所有页面的调用,都是首先经过缓冲池,没有的话再去HeapFile中找。
6.Exercise 6
实现一个顺序扫描,前面都没问题的话,这里就是一个简单的封装。
总结
这是我在CSDN注册后的第一篇文章,整理写文档是一个很痛苦的事,说不定后面的实验报告就不想写啦哈哈哈。整个lab还是挺有质量的,马克思主义说理论联系实际,将书上看的东西自己做一个简单实现还是挺不错的,并且对于数据库的理解也加深了,另外在写文档的过程可能也会写一些其他随笔,复习一下Java基础,希望明年的就业形势稍微好一点,能找个好工作吧。















 25
25











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









