







6.830是麻省理工学院(简称 MIT)的一门计算机科学课程,全名为"6.830: Database Systems"。该课程是关于数据库系统的高级课程,旨在教授学生关于数据库的设计、实现和优化的知识和技能。
课程附带了6个Lab以供练习,最终目的是使学生能够用Java写出一个简易数据库系统,这6个Lab由浅入深,覆盖了数据库的核心知识点。
Lab1 总共有 6 个 exercise,主要是练习的是数据库的数据存储部分。
Exercise 1
src/java/simpledb/storage/TupleDesc.javasrc/java/simpledb/storage/Tuple.java
在 SimpleDB 中,逻辑上的存储单元由大到小分别是 Database -> Table -> Tuple -> Field。一个表中的每一条记录就是一个 Tuple 元组对象,元组中的每一列是一个 Field 字段值,目前只实现了 Int 和 String(固定长度)类型。
每个元组需要一个 TupleDesc 对象来描述该元组包含的所有字段,包括每个字段类型 fieldType 和字段名 fieldName,在 SimpleDB 中由 TDItem 对象存储。
在实现 TupleDesc 的 toString() 方法时,发现了一个显而易见但之前没注意到的问题:集合每次在调用 iterator() 方法时都会生成一个新的 Iterator,所以不能反复调用此方法。另外
for-each语句不能用于 Iterator,只能用于数组或实现了 Iterable 接口的对象。
Exercise 2
src/java/simpledb/common/Catalog.java
Catalog 是管理数据库所有表的单例对象,比较简单。
- 主要实现了供外界调用的 addTable、getTableName 等方法
- 在 SimpleDB 中,一个 Table 对应一个 DbFile,并且共享同一个 ID(DbFile 绝对路径的 hashcode)
- 这里的 HashMap 用并发安全的比较好
Exercise 3
src/java/simpledb/storage/BufferPool.java- 实现
getPage()方法
- 实现
BufferPool 也是一个全局单例对象,它负责维护访问页面 Page 的缓存。
关于页面,有三个容易混淆的概念:
- 硬盘中的页面(也可以叫块 block)
- 操作系统中的页面
- 数据库中的页面
Page 是数据库向硬盘中读取和写入一次数据的最小单位,一般来说数据库的页面比底层的页面要大一些,所以需要我们自己写一些逻辑来保证操作的原子性(暂时不需要)。
每次通过 PageId(存储 tableId 和 pageNo)来获取页面。首先查找缓存,没有的话就通过 Catalog 获取 DbFile 读取页面并加入缓存。如果缓存占满,就要进行页面置换(暂时不需要)。
public Page getPage(TransactionId tid, PageId pid, Permissions perm)
throws TransactionAbortedException, DbException {
Page res = idToPage.get(pid);
if(res == null) {
Catalog catalog = Database.getCatalog();
DbFile f = catalog.getDatabaseFile(pid.getTableId());
res = f.readPage(pid);
idToPage.put(pid, res);
}
return res;
}
Exercise 4
src/java/simpledb/storage/HeapPageId.java(继承自 PageId)src/java/simpledb/storage/RecordId.javasrc/java/simpledb/storage/HeapPage.java(继承自 Page)
前两个 Id 对象主要就是 hashcode() 和 equals() 方法的编写,注意:
在重写一个类的
equals方法的时候,必须同时重写hashCode方法。否则的话,在使用需要判断 hash 值的数据结构(如 HashMap)进行存储时就会出现问题。要求: equals 为 true 时 hashCode 一定为 true;hashCode 为 true 时,equals 不一定为 true。
HeapPage 是实际存储在缓存中的页面(从硬盘读取到内存),它主要包含头部 header 标志位和一个固定长度的 tuple 数组(slots),结构示意图如下:
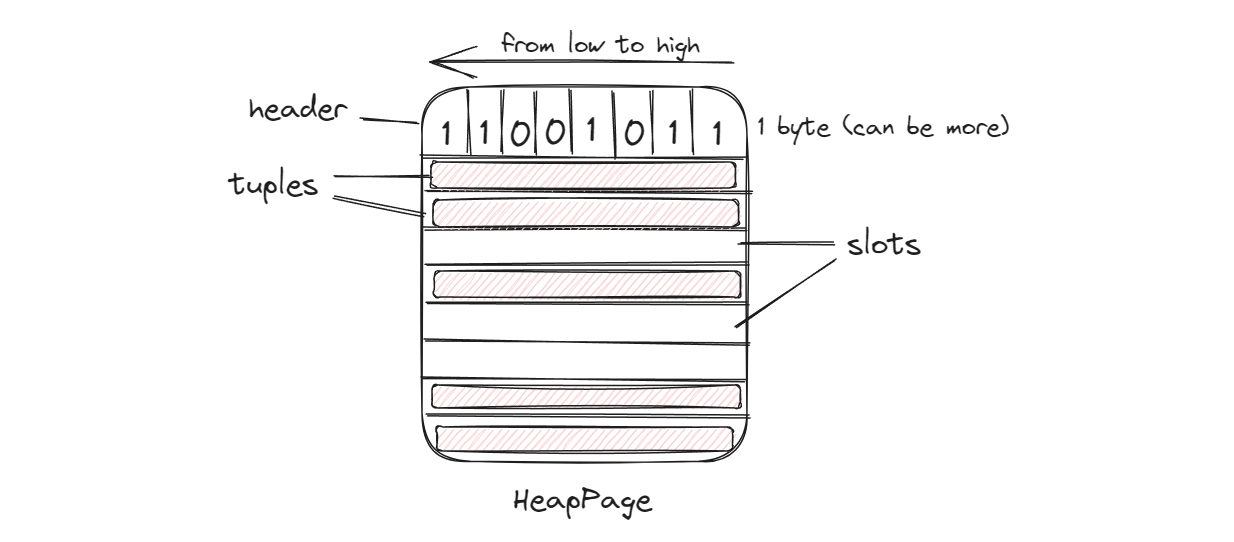
页面中的 slot(插槽)有几个,header 就有几位,当一个元组插入 slot 后,header 对应位置设置为 1,删除元组则反之。在 SimpleDB 中,一个 table 的 TupleDesc 确定下来后,tuple 的长度就是固定的,因此可以计算出该页面可以有多少个 slot,用于初始化 header 和数组。
计算 slot 个数:
private int getNumTuples() {
// 每个页面可存储的元组数计算公式(大小单位是字节):
// 页面大小 * 8 / (元组大小 * 8 + 1),向下取整
int numTuples = BufferPool.getPageSize()*8 / (td.getSize()*8+1);
return numTuples;
}
+1 是因为每个元组要附带一个标志位。
计算 header 大小(字节),多余的 0 位不考虑:
private int getHeaderSize() {
// Header要存储numSlots个bit,计算所需的bytes
int headerSize = (int) Math.ceil(numSlots / 8.0); // 向上取整
return headerSize;
}
HeapPage 在初始化时接受一个 pageId 和从硬盘读入的序列化后的 byte 数组进行反序列化,相反,getPageData 方法将该页面序列化以存入硬盘。
需要实现 isSlotUsed() 方法,该方法返回某个 slot 是否插入了元组。检查 header 对应位置的标志位是否为 1 即可。
public boolean isSlotUsed(int i) {
// 注意规定了从每个byte从右到左(low to high)
byte slot = (byte) ((header[i/8] >> (i%8)) & 1);
return slot == (byte)1 ? true : false;
}
Exercise 5
src/java/simpledb/storage/HeapFile.java(继承自 DbFile)
HeapFile 对应一个表在硬盘中存储的文件,存储的单位是 HeapPage,所以主要是实现 readPage() 方法,它接受 pageId,需要找到对应 Page 在文件中的偏移量读取出来。一定要用文件随机读取,而不能一次性全部读到内存中,因为文件可能会很大。
public Page readPage(PageId pid) {
// 找到对应Page所在的偏移量,读取后生成HeapPage
int pageSize = BufferPool.getPageSize();
int offset = pid.getPageNumber() * pageSize;
byte[] data = new byte[pageSize];
Page heapPage = null;
try (RandomAccessFile f = new RandomAccessFile(file, "r")) {
f.seek(offset);
f.read(data);
heapPage = new HeapPage((HeapPageId)pid, data);
} catch (IOException e) {
e.printStackTrace();
}
return heapPage;
}
另外的一个难点是实现 iterator() 方法,它的功能是遍历该表(DbFile)中的所有元组。那么就需要我们遍历 HeapFile 的所有 HeapPage,过程中使用 HeapPage 的 Iterator 来遍历元组。
但是上面实现的 readPage() 方法是给 BufferPool 调用的,因为所有的页面读取都要经过缓存。所以我们需要调用 BufferPool 的 getPage() 方法来获取页面,从 pageNo = 0 开始累加,直到到达该文件所存储的页面数量的上限,是在 numPages() 里计算得到的(文件大小除以 PageSize)。
Exercise 6
src/java/simpledb/execution/SeqScan.java(实现 OpIterator)
Operator 是执行计划的基本单位,最简单、最底层的一个 Operator 就是 SeqScan,按照存储顺序扫描某一个表的全部元组。
这里主要添加了表的别名 alias的概念,我们需要生成一个 tableAlias.filedName 形式的 TupleDesc 以供后续使用。
实现 OpIterator 接口的全部方法,主要是调用 HeapFile 里的 Iterator 的相应方法。
详细的数据库查询模型在下一个 Lab 总结。
















 131
131











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









