






week30 CROSSFORMER
摘要
本文主要讨论Crossformer。首先本文简要介绍了self-attention的框架。其次本文展示了题为CrossFormer: A Versatile Vision Transformer Hinging on Cross-scale Attention的论文主要内容。该文提出了跨尺度嵌入层(CEL)和长短距离注意力(LSDA)。通过以上两种设计,该文实现了跨尺度的注意力。大量实验表明,CrossFormer 在图像分类、对象检测、实例分割和语义分割任务方面优于其他视觉Transformer。最后,本文简要介绍了污水处理流程。
Abstract
This article focuses on Crossformer. First, this article briefly introduces the framework of self-attention. Secondly, this paper presents the main content of the paper entitled CrossFormer: A Versatile Vision Transformer Hinging on Cross-scale Attention. This paper proposes cross-scale embedding layer (CEL) and long-distance attention (LSDA). Through the above two designs, this paper achieves cross-scale attention. A large number of experiments show that CrossFormer is superior to other vision transformers in image classification, object detection, instance segmentation and semantic segmentation tasks. Finally, this article provides a brief introduction to the wastewater treatment process.
一、framework of self-attention
在网络中使用dot-product计算相关性的流程如下,假设要查询 a 1 a^1 a1与其他向量的相关性
- 首先,计算 q u e r y query query向量 q 1 = W q a 1 q^1=W^qa^1 q1=Wqa1,之后计算 k e y key key向量 k i = W k a i k^i=W^ka^i ki=Wkai, a i a^i ai为输入序列中的所有向量。
- 其次,计算
a
t
t
e
n
t
i
o
n
s
c
o
r
e
attention\ score
attention score,若查询向量对应
a
1
a^1
a1、关键词向量对应
a
2
a^2
a2,则有
α
1
,
2
=
q
1
⋅
k
2
\alpha_{1,2}=q^1\cdot k^2
α1,2=q1⋅k2
- 以此类推计算所有向量的attention score
- 之后,将所有的 a t t e n t i o n s c o r e attention score attentionscore输入soft-max中,将其映射为一个分布, α 1 , 2 \alpha_{1,2} α1,2对应的输出为 α 1 , 2 ′ \alpha'_{1,2} α1,2′
- 最后,将 a i a^i ai乘上矩阵 W v W^v Wv,得到 v i v^i vi,用 α 1 , i ′ \alpha'_{1,i} α1,i′乘上 v i v^i vi,将所有的按照该流程的得到的结果累加 b 1 = ∑ i α 1 , i ′ v i b^1=\sum_i{\alpha'_{1,i}v^i} b1=∑iα1,i′vi, a i a^i ai为输入序列中的所有向量。若其他向量 b i b^i bi与 b 1 b^1 b1越相近,则 a i a^i ai与 a 1 a^1 a1越相近
二、文献阅读
1. 题目
题目:CrossFormer: A Versatile Vision Transformer Hinging on Cross-scale Attention
作者:Wenxiao Wang1,2, Lu Yao1, Long Chen3, Binbin Lin4, Deng Cai1, Xiaofei He1 &Wei Liu2
链接:https://arxiv.org/abs/2108.00154
发布:ICLR2022
2. abstract
Transformers尚不具备在不同尺度的特征之间建立交互的能力。为此,该文提出了跨尺度嵌入层(CEL)和长短距离注意力(LSDA)。通过以上两种设计,该文实现了跨尺度的注意力。大量实验表明,CrossFormer 在图像分类、对象检测、实例分割和语义分割任务方面优于其他视觉Transformer。
Existing vision transformers do not yet possess the ability of building the interactions among features of different scales, which is perceptually important to visual inputs. To this end, this article propose Cross-scale Embedding Layer (CEL) and Long Short Distance Attention (LSDA). Through the above two designs, this article achieve cross-scale attention. Extensive experiments show that CrossFormer outperforms the other vision transformers on image classification, object detection,
instance segmentation, and semantic segmentation tasks.
3. CROSSFORMER
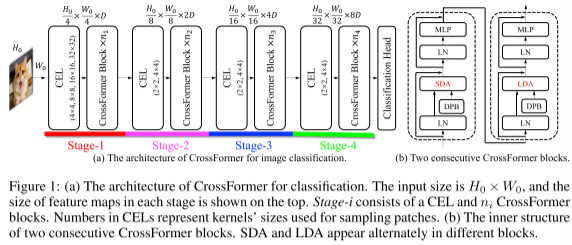
CrossFormer 的整体架构如上图所示。CrossFormer 采用了金字塔结构,自然地将 Transformer 模型分为四个阶段。每个阶段由一个跨尺度嵌入层(CEL,第 3.1 节)和几个 CrossFormer 块(第 3.2 节)组成。 CEL 接收最后阶段的输出(或输入图像)作为输入并生成跨尺度嵌入。在此过程中,CEL(第一阶段除外)将嵌入数量减少到四分之一,同时将金字塔结构的尺寸加倍。然后,在 CEL 之后设置几个 CrossFormer 块,每个块都涉及长短距离注意力(LSDA)和动态位置偏差(DPB)。在负责特定任务的最后阶段之后有一个专门的头(例如上图中的分类头)。
3.1 跨尺度嵌入层

上图展示了CEL层的结构,在该层输入图像由四个不同的内核以相同步长进行采样。每个嵌入都是通过投影和链接四个patch来构造,其中 D t D_t Dt表示嵌入的总尺寸
利用跨尺度嵌入层(CEL)为每个阶段生成输入嵌入。如上图,以网络Stage-1的第一个CEL为例。它接收图像作为输入,然后使用四个不同大小的内核对patch进行采样。四个内核的步幅保持相同,以便它们生成相同数量的嵌入。如上图每四个对应的 patch 具有相同的中心但不同的尺度,并且所有这四个 patch 都将被投影并连接为一个嵌入。实际上,采样和投影的过程可以通过四个卷积层来完成。
为了控制 CEL 的总预算,该文对大内核使用较低的维度,而对小内核使用较高的维度。上图给出了其子表中的具体分配规则,并给出了128维的例子。与平均分配维度相比,该方案节省了大量的计算成本,但没有显着影响模型的性能。其他阶段的跨尺度嵌入层以类似的方式工作。
3.2 CROSSFORMER块
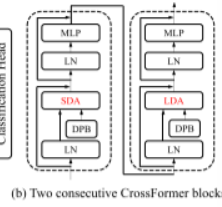
每个 CrossFormer 块由一个长短距离注意力模块(即 LSDA)和多层感知器(MLP)组成。如上图,,SDA和LDA交替出现在不同的块中,动态位置偏差(DPB)模块在SDA和LDA中工作,以获得嵌入式的位置表示。
3.2.1 长短距离注意力(LSDA)
将自注意力模块分为两部分:短距离注意力(SDA)和长距离注意力(LDA)。
对于SDA,每个 G × G G×G G×G相邻的嵌入被分组在一起。如下图a,其中G=3。对于输入大小为 S × S S × S S×S 的 LDA,嵌入以固定间隔 I 进行采样。如下图b (I = 3) 中,所有带有红色边框的嵌入都属于一组,带有黄色边框的组成另一组。 LDA 组的高度或宽度计算公式为 G = S / I G = S/I G=S/I(即本例中 G = 3 G = 3 G=3)。对嵌入进行分组后,SDA 和 LDA 在每组中都使用普通的自注意力机制。结果,自注意力模块的内存/计算成本从 O ( S 4 ) O(S^4) O(S4) 降低到 O ( S 2 G 2 ) O(S^2G^2) O(S2G2),并且在大多数情况下 G ≪ S G \ll S G≪S。LDA 的有效性还受益于跨尺度嵌入。
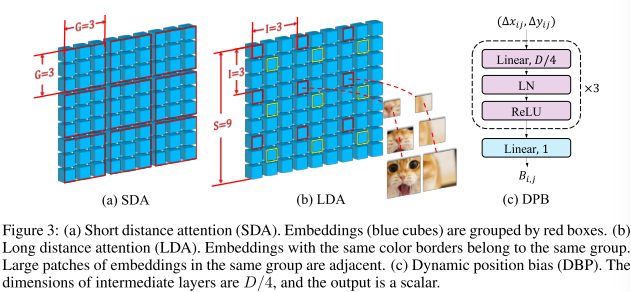
如下图为LSDA伪代码

3.2.2 动态位置偏差(DYB)
相对位置误差(RPB)通过向嵌入的注意力添加误差来指示嵌入的相对位置。形式上,带有RPB的LSDA的注意力图变为:
Attention
=
Softmax
(
Q
K
T
/
d
+
B
)
V
(1)
\text{Attention}=\text{Softmax}(QK^T/\sqrt{d}+B)V \tag{1}
Attention=Softmax(QKT/d+B)V(1)
其中
Q
,
K
,
V
∈
R
G
2
×
D
Q,K,V ∈ \mathbb R^{G^2×D}
Q,K,V∈RG2×D 分别表示自注意力模块中的查询、键、值。
d
\sqrt d
d 是常数归一化器,
B
∈
R
G
2
×
G
2
B ∈ \mathbb R^{G^2×G^2}
B∈RG2×G2 是 RPB 矩阵。在之前的工作中,
B
i
,
j
=
B
^
Δ
x
i
j
,
Δ
y
i
j
B_{i,j} = \hat B_{Δxij,Δyij}
Bi,j=B^Δxij,Δyij ,其中
B
^
\hat B
B^ 是固定大小的矩阵,
(
Δ
x
i
j
,
Δ
y
i
j
)
(Δxij,Δyij)
(Δxij,Δyij) 是第 i 个和第 j 个嵌入之间的坐标距离。很明显,如果
(
Δ
x
i
j
,
Δ
y
i
j
)
(Δxij,Δyij)
(Δxij,Δyij) 超过
B
^
\hat B
B^ 的大小,则图像/组的大小受到限制。相比之下,提出了一个名为 DPB 的基于 MLP 的模块来动态生成相对位置偏差,即
B
i
,
j
=
D
P
B
(
Δ
x
i
j
,
Δ
y
i
j
)
(2)
B_{i,j}=DPB(\Delta x_{ij},\Delta y_{ij}) \tag{2}
Bi,j=DPB(Δxij,Δyij)(2)

如上图为DPB结构。器线性变换由三个全连接层组成,具有层归一化和ReLU。DPB的输入维度为2,即 ( Δ x i j , Δ y i j ) (Δxij,Δyij) (Δxij,Δyij),中间层的维度设置为 D / 4 D/4 D/4,其中D式嵌入维度。输出 B i j B_{ij} Bij式一个标量,对第i个和第j个嵌入之间的相对位置特征进行编码。DPB是一个与整个Transformer一起优化的可训练模块。其可处理任何图像/组大小,而无需担心 ( Δ x i j , Δ y i j ) (Δxij,Δyij) (Δxij,Δyij)的边界。当图像/组大小固定时,其等价于RPB。当图像/组大小为动态时,提供了DPB的高效 O ( G 2 ) O(G^2) O(G2)实现。
3.3 Crossformer 的变体
四种Crossformer的图像分类变体的详细配置,如下图。
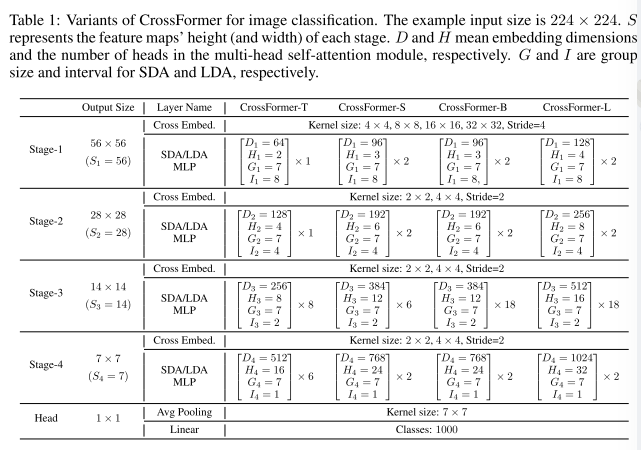
为了重用训练的权重,其他任务的模型采用与分类相同的主干,只是可能使用不同的 G , I G,I G,I。具体来说,除了与分类相同的配置外,还使用 G 1 = G 2 = 14 , I 1 = 16 , I 2 = 8 G_1=G_2=14,I_1=16,I_2=8 G1=G2=14,I1=16,I2=8用于检测模型的前两个阶段,以适应更大的图像。组大小或者间隔不会影响权重张量的形状,因此在ImageNet上预训练的主干网络可以轻松的在其他任务上进行微调,即使它们使用不同的G或者I。
4. 文献解读
4.1 Introduction
受益于其 self-attention 模块,Transformer从根源上具备构建长距离依赖的关键能力。Transformer需要一系列嵌入作为输入。为了使这一要求适应典型的任务,大多数现有的视觉Transformer采用将输入图像分割为大小相等块的方法。在某个Transformer内部,自注意力机制用于构建任意两个嵌入之间的交互。因此,自注意力模块的计算或内存成本为 O(N2),其中 N 是嵌入序列的长度。这样的成本对于输入来说太大了。因此,最近提出的Transformer开发了多种替代品,以较低的成本近似普通的自注意力模块。
然而,当前的Transformer无法建立不同尺度特征之间的交互。为了构建跨尺度交互,该文设计了一个新颖的嵌入层和自注意力模块,如下所示。
- 1)跨尺度嵌入层(CEL)——采用了金字塔结构,它自然地将Transformer分为多个阶段。 CEL 出现在每个阶段的开始,它接收最后阶段的输出(或输入图像)作为输入,并使用不同尺度的多个内核对补丁进行采样。然后,每个嵌入都是通过投影和连接这些补丁来构建的,而不是仅仅使用一个单尺度补丁,这赋予每个嵌入跨尺度的特征。
- 2)长短距离注意力(LSDA)——提出了普通自注意力的替代品,但为了保留小规模特征,嵌入不会被合并。相比之下,将自注意力模块分为短距离注意力(SDA)和长距离注意力(LDA)。 SDA 建立相邻嵌入之间的依赖关系,而 LDA 负责彼此远离的嵌入之间的依赖关系。该文所提出的 LSDA 也可以像之前的研究一样降低自注意力模块的成本,但与它们不同的是,LSDA 不会破坏小规模或大规模特征。因此,可以实现跨尺度交互的注意力。
此外,对嵌入的位置表示采用相对位置偏差。相对位置偏差(RPB)仅支持固定图像/组大小。为了使得RPB更加灵活,进一步引入了一个成为动态位置偏差(DPB)的可训练模块,该模块接受两个嵌入的相对距离作为输入并输出它们的位置偏差。DPB模块在训练阶段进行端到端优化,使得成本可以被忽略,同时使得RPB能够失用于可变图像/组大小。
基于该文中的模型,构建了四个不同尺寸的多功能视觉变换器,称为 CrossFormers。所提出的 CrossFormer 可以处理具有可变大小输入的各种任务。对四个代表性视觉任务(即图像分类、对象检测、实例分割和语义分割)的实验表明,CrossFormer 在所有任务上都优于其他最先进的视觉Transformer。值得注意的是,CrossFormer 带来的性能提升在密集预测任务(例如对象检测和实例/语义分割)上非常显着。
4.2 创新点
- 提出跨尺度嵌入层(CEL)和长短距离注意力(LSDA),它们共同弥补了现有 Transformer 无法构建跨尺度注意力的问题。
- 进一步提出动态位置偏差模块(DPB)以使相对位置偏差更加灵活,即适应可变的图像尺寸或组尺寸。
- 构建了多个不同尺寸的 CrossFormers,通过对四个代表性视觉任务的充分实验证实了它们的有效性。
4.3 实验过程
实验针对四个具有挑战性的任务进行:图像分类、对象检测、实例分割和语义分割。为了进行公平的比较,尽可能保持与其他Transformer相同的数据增强和训练设置。参赛者均为Transformer,包括 DeiT、PVT、T2T-ViT、TNT 、CViT、Twins、Swin、NesT、CvT 、ViL、CAT、ResT、TransCNN、Shuffle、 BoTNet和 RegionViT。
4.3.1 图像分类
实验设置:图像分类实验使用 ImageNet数据集完成的。这些模型在 128 万张训练图像上进行训练,并在 5 万张验证图像上进行测试。采用与其他视觉Transformer相同的训练设置。网络使用 AdamW优化器训练 300 轮、余弦衰减学习率调度器、20 轮线性预热。在 8 个 V100 GPU 上,批量大小为 1,024 个分割。使用 0.001 的初始学习率和 0.05 的权重衰减。此外,对 CrossFormer-T、CrossFormer-S、CrossFormer-B、CrossFormer-L 分别使用 0.1、0.2、0.3、0.5 的下降路径率。此外,类似于Swin、RandAugment、Mixup、Cutmix、random erasing和stochasitc depth用于数据增强
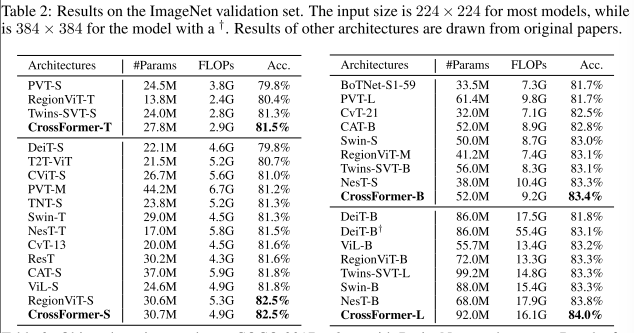
结果:结果如下表所示。CrossFormer 实现了最高的精度,其参数和 FLOP 与其他最先进的视觉Transformer结构相当。具体来说,与强大的对比模型DeiT、PVT 和 Swin 相比,CrossFormer 在小型模型上的准确度至少比它们高出 1.2%。此外,尽管 RegionViT 在小模型上达到了与实验模型相同的准确率 (82.5%),但它在大模型上的准确率绝对低于实验模型的 0.7%(84.0% vs. 83.3%)。
4.3.2 对象探测和实例分割
实验设置:对象检测和实例分割的实验都是在 COCO 2017 数据集上完成的,该数据集包含 118K 训练图像和 5K 验证图像。分别使用基于 MMDetection的 RetinaNet和 Mask R-CNN作为对象检测和实例分割头。对于这两个任务,主干网均使用在 ImageNet 上预训练的权重进行初始化。然后整个模型在 8 个 V100 GPU 上以批量大小 16 进行训练,并使用初始学习率为 1 × 10−4 的 AdamW 优化器。继之前的工作之后,在以 RetinaNets 作为检测器时采用 1× 训练计划(即模型训练 12 个 epoch),并将图像的短边尺寸调整为 800 像素。而对于 Mask R-CNN,同时使用 1× 和 3× 训练计划。值得注意的是,在采用 3× 训练计划时也采用多尺度训练。
结果:RetinaNet和Mask R-CNN的结果分别如下表所示。第二名的架构随着实验而变化,也就是说,这些架构可能在一项任务上表现良好,但在另一项任务上表现不佳。相比之下,CrossFormer 在两种模型大小(小和基本)的任务(检测和分割)上都优于所有其他模型。此外,当模型放大时,CrossFormer相对于其他架构的性能提升更加明显,这表明CrossFormer具有更大的潜力。
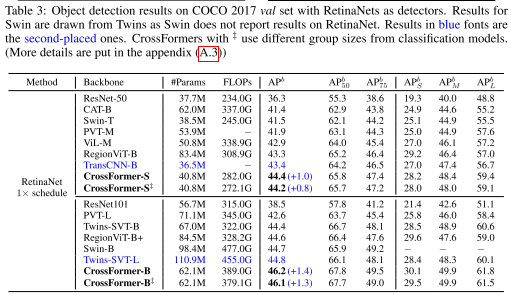
上表为RetainNets的结果
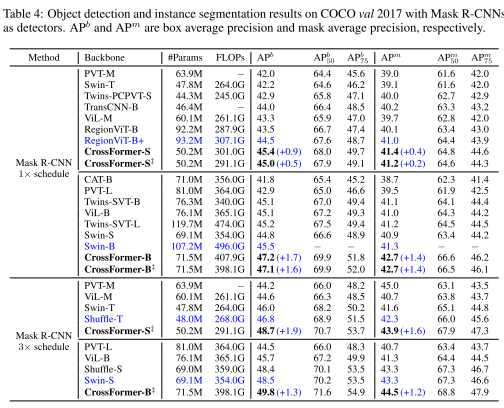
上表为Mask R-CNN
4.3.3 语义分割
实验设置:ADE20K被用作语义分割的基准模型。它涵盖了 150 个语义类别,包括 20K 个用于训练的图像和 2K 个用于验证的图像。与检测模型类似,我们使用在 ImageNet 上预训练的权重来初始化主干,并将基于 MMSegmentation的语义 FPN 和 UPerNet作为分割头。对于 FPN,使用学习率和权重精度为 1 × 10−4的 AdamW 优化器。模型经过 80K 次迭代训练,批量大小为 16。对于 UPerNet,使用初始学习率为 6 × 10−5 且权重衰减为 0.01 的 AdamW 优化器,模型经过 160K 次迭代训练。
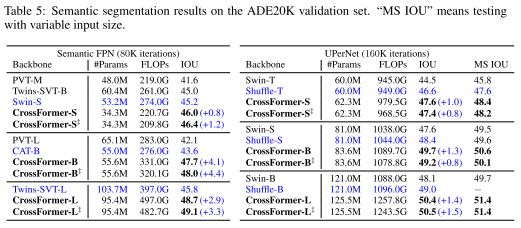
结果:所有结果如下表所示。与目标检测类似,CrossFormer 在放大模型时表现出比其他模型更大的性能增益。例如,CrossFormer-T 的 IOU 绝对比 Twins-SVT-B 高 1.4%,但 CrossFormer-B 的 IOU 绝对比 Twins-SVT-L 高 3.1%。总的来说,CrossFormer 在密集预测任务(例如检测和分割)上比在分类上显示出比其他任务更显着的优势,这意味着注意模块中的跨尺度交互对于密集预测任务比分类更重要
4.4.4 消融研究
跨尺度嵌入与单尺度嵌入:通过用单尺度嵌入层替换跨尺度嵌入层来进行实验。如下表中,当使用单尺度嵌入时,与 4×4 内核相比,Stage-1 中的 8 × 8 内核带来了 0.4%(81.9% vs. 81.5%)的绝对改进。因此重叠的感受野有助于提高模型的性能。此外,所有具有跨尺度嵌入的模型都比具有单尺度嵌入的模型表现更好。特别是,与在所有阶段使用单尺度嵌入相比,CrossFormer 实现了 1%(82.5% vs. 81.5%)的绝对性能增益。对于跨尺度嵌入,还尝试了几种不同的内核大小组合,它们都表现出相似的性能(82.3%∼82.5%)。总之,跨尺度嵌入可以带来很大的性能增益,而且该模型对于不同的内核大小选择相对稳健。
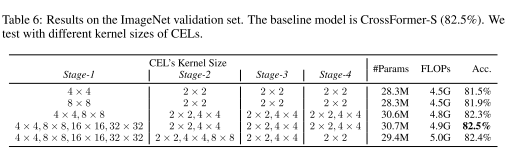
LSDA 与其他自注意力机制:比较了 PVT 和 Swin 中使用的两种自注意力模块。具体来说,PVT在计算self-attention时牺牲了小尺度特征,而Swin则将self-attention限制在局部区域,放弃了远距离的attention。如下表a中所观察到的,与类似 PVT 和类似 Swin 的自注意力机制相比,CrossFormer 的绝对准确率至少优于它们 0.6%(82.5% 与 81.9%)。结果表明,以长短距离的方式进行self-attention最有利于模型性能的提升。
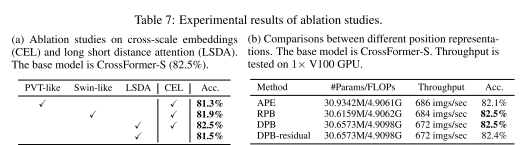
DPB 与其他位置表示:比较了绝对位置嵌入(APE)、相对位置偏差(RPB)和 DPB 模型的参数、FLOP、吞吐量和精度。结果如下表b所示。 DPB-residual 表示具有剩余连接的 DPB。 DPB 和 RPB 的绝对精度都优于 APE,达到 0.4%,这表明相对位置表示比绝对位置表示更有利。此外,DPB 实现了与 RPB 相同的精度(82.5%),而额外成本可以忽略不计;同时它比 RPB 更灵活,并且适用于可变图像大小或组大小。结果还表明,DPB 中的残差连接无助于提高甚至降低模型的性能。
4.4 结论
该文提出了一种新颖的基于 Transformer 的视觉架构,即 CrossFormer。其核心成分是跨尺度嵌入层(CEL)和长短距离注意力(LSDA),从而产生交叉注意力模块。进一步提出了动态位置偏差,使相对位置偏差适用于任何输入大小。大量实验表明,CrossFormer 在几个代表性视觉任务上比其他最先进的视觉转换器实现了卓越的性能。特别是,CrossFormer 被证明在对象检测和分割方面获得了巨大改进,这表明 CEL 和 LSDA 对于密集预测任务至关重要。
三、污水厂处理大致过程
1. 污染物
工业废水(工业的不叫污水)和生活污水主要污染物包括且不限于以下:
1、COD(化学需氧量)和BOD(生物需氧量):消耗水体氧气导致水中生物缺氧死亡。前者是利用化学氧化方式测定,后者利用微生物培养消耗的水中溶解氧测定,一般按5天计。
2、总氮和氨氮、总磷:导致水体富营养化,使水生植物和藻类大量生长,消耗水体中氧气。
3、Ph值:酸性碱性。
4、SS(悬浮物):导致水体浑浊和泥沙含量大。
5、色度:让水变颜色。
2. 大致处理过程
污水处理工艺流程由污水处理系统和污泥处理系统组成。污水处理系统包括一级处理系统、二级处理系统和深度处理系统。
污水一级处理是由格栅、沉砂池和初沉淀池组成,其作用是去除污水中的固体悬浮污染物质。并可去除BOD约20%~30%。
污水二级处理系统是污水处理系统的核心,主要作用是去除污水中呈胶体和溶解状态的[有机污染物。BOD可以降至20~30mg/L,经二级处理后,一般可满足污水综合排放标准。各种类型的污水生物处理技术有活性污泥法、生物膜法及生态处理技术等。
当为了保证受纳水体不受污染或是为了满足污水再生回用的要求,就需对二级处理出水作进一步处理,以降低悬浮物和有机物,并去除氮磷类营养物质,这就是污水的深度处理。
污泥是污水处理过程的必然产物。这些污泥应加以妥善处置,否则会造成二次污染。
选择污水处理工艺时,工程造价和运行费用也是工艺流程选择的重要因素。应以处理后水达到水质标准为约束条件,以处理系统的最低总造价和运行费用为目标函数,建立三者之间的相互关系。
小结
本周主要了解了Crossformer的大致结构,并复习了self-attention的框架(自注意力机制的大致计算流程)。本周阅读的论文提出了跨尺度嵌入层(CEL)和长短距离注意力(LSDA)。通过以上两种设计,该文实现了跨尺度的注意力。此外,其还在之前的研究基础上实现了DPB。最后通过上述两种新架构实现了Crossformer。
参考文献
[1] Wenxiao Wang, Lu Yao, Long Chen, Binbin Lin, Deng Cai, Xiaofei He &Wei Liu: CROSSFORMER: AVERSATILE VISION TRANSFORMER HINGING ON CROSS-SCALE ATTENTION.[J].arXiv:2108.00154v2
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









