









Andrew Ng’s Coursera Machine Leaning(ML) Notes Week2
Author: Yu-Shih Chen
December 20, 2018 1:10AM
Intro:
本人目前是在加州上大学的大二生,对人工智能和数据科学有浓厚的兴趣所以在上学校的课的同时也喜欢上一些网课。主要目的是希望能够通过在这个平台上分享自己的笔记来达到自己更好的学习/复习效果所以notes可能会有点乱,有些我认为我自己不需要再复习的内容我也不会重复。当然,如果你也在上这门网课,然后刚好看到了我的notes,又刚好觉得我的notes可能对你有点用,那我也会很开心哈哈!有任何问题或建议OR单纯的想交流OR单纯想做朋友的话可以加我的微信:y802088
Week2
大纲:
- Multiple Feature hypothesis h(x)(预测公式)
- Gradient Descent for multiple variables
- Feature Scaling and Mean Normalization
- Alpha (learning rate)
- Features and Polynomial Regression
- Normal Equation
Multiple Feature Hypothesis h(x)(预测公式):
week1讲的主要是1个feature的model,也就是只有一个’x’的model。举个栗子:h(x) = 3 + 5x, 也就是很简单的一条线(这里3是theta0,5是theta1)。但其实多加一点feature也不会改变公式太多。
先来注释一下各种notation吧:

如果用matrix来解释,x(i)j就是i排的第j个元素。 其他的都比较straight forward没什么好讲的。
Multivariate Linear Hypothesis h(x)(预测)的公式如下:

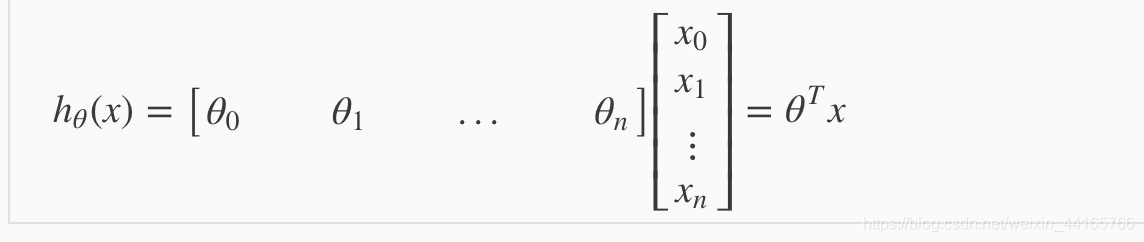
上面两张图是一样的。第二张图只是用matrix(矩阵)来表示出来而已。
Gradient Descent for Multiple Features
week1讲到gradient descent是用来寻找最好的theta/parameters 搭配来达到最低的cost(误差)。如果有多个’x’,gradient descent的公式如下:

是不是跟week1的没什么区别,因为的确没什么区别,只是从1个feature变成多个n个feature了而已。 思路还是一样的,通过寻找根据theta的partial derivative找slope,然后慢慢地找到误差最低点的theta。
Feature Scaling and Mean Normalization
这不是一个必须要做的,这是一个可以让你的gradient descent更有效率的小技巧。 有些时候如果你的featurer的值很大,比如说你的feature 1是关于某个城市每天出入的人数什么但是feature 2是关于平均每个人拥有的手机数量,那这两个feature的数值差就很大吧?可想而知,如果你很多feature而且都差得很多,那虽然gradient descent能跑是能跑,但是越大的range就越慢找到理想的theta。
大概的想法就是我们想要让每组的feature都在某个较小的数值的区间里(如: -1<= x <= 1)有两种做法:
- Feature Scaling - 把每个x都除以它dataset的range(最大减最小)
举个栗子:feature 1是某个城市每天出入人数然后我们有5组数据(1000,1500,1200,2000,1700)那这个的range就是2000-1000 = 1000 然后如果feature 2是平均每个人拥有的手机(1,2,2,3,1)range就是3-1 =2。也就是说把每一个x都除以它对应的range就行 - Mean Normalization - 在feature scaling的基础上,让x减去最小值(mu(i))
公式为: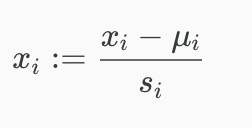
这里的s(i)可以是standard deviation也可以是我们刚刚讲的range,结果会不一样,但是达到目的是一样的。
再次声明:这个小技巧不是必须的,但是可以提高gradient descent的运行速度。
Alpha (Learning Rate)
这个week1的时候好像就写过了但我再写一遍吧
对于alpha要注意的有几点:
- alpha不能太大。 如果太大,会导致像蜘蛛侠一样在graph上弹来弹去,而且是越弹越高,离我们的cost(误差)的最小值越来越远,这样就本末倒置了。
- alpha不能太小。 如果太小,那运行的时间就需要更久,导致没有效率。但是比起alpha太大,它还是能达到我们想要的目的的。
解决方法:
- 如果发现implement gradient descent之后误差反而越来越大,就降低我们的alpha值。
- 相反,如果发现误差在减小,但是速度太慢了,那就适当的提升一点alpha的值。
Features and Polynomial Regression
我们可以通过加入higher degree feature (比如:x^2)或者是其他feature的改动来更好的贴合我们的数据。
比如说如果我们的数据呈现的是个弧形,那我们可能可以考虑到平方(比如:y = theta0 + theta1*x + theta2 * x^2)能够更好的贴合我们的数据。week2只是提到了有这么一个idea而已,但是关于如何去选择最好的模型要等到后面才会详细讲解。
需要注意的点是:如果说给feature加进了更高的degree或者是一些其他的mathematical adjustment
比如:
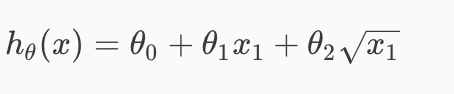
或者: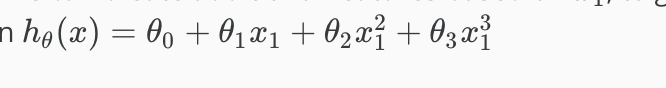 那上面说的feature scaling就会变得非常重要。因为你的数据的范围可能会因此变得非常的大,也就导致你的gradient descent非常的没有慢且没有效率。
那上面说的feature scaling就会变得非常重要。因为你的数据的范围可能会因此变得非常的大,也就导致你的gradient descent非常的没有慢且没有效率。
Normal Equation
除了通过gradient descent来找到理想的theta以外,我们还有个比较简单粗暴的公式可以准确的直接手动计算找到我们想要的theta。
用matrix表示公式如下:
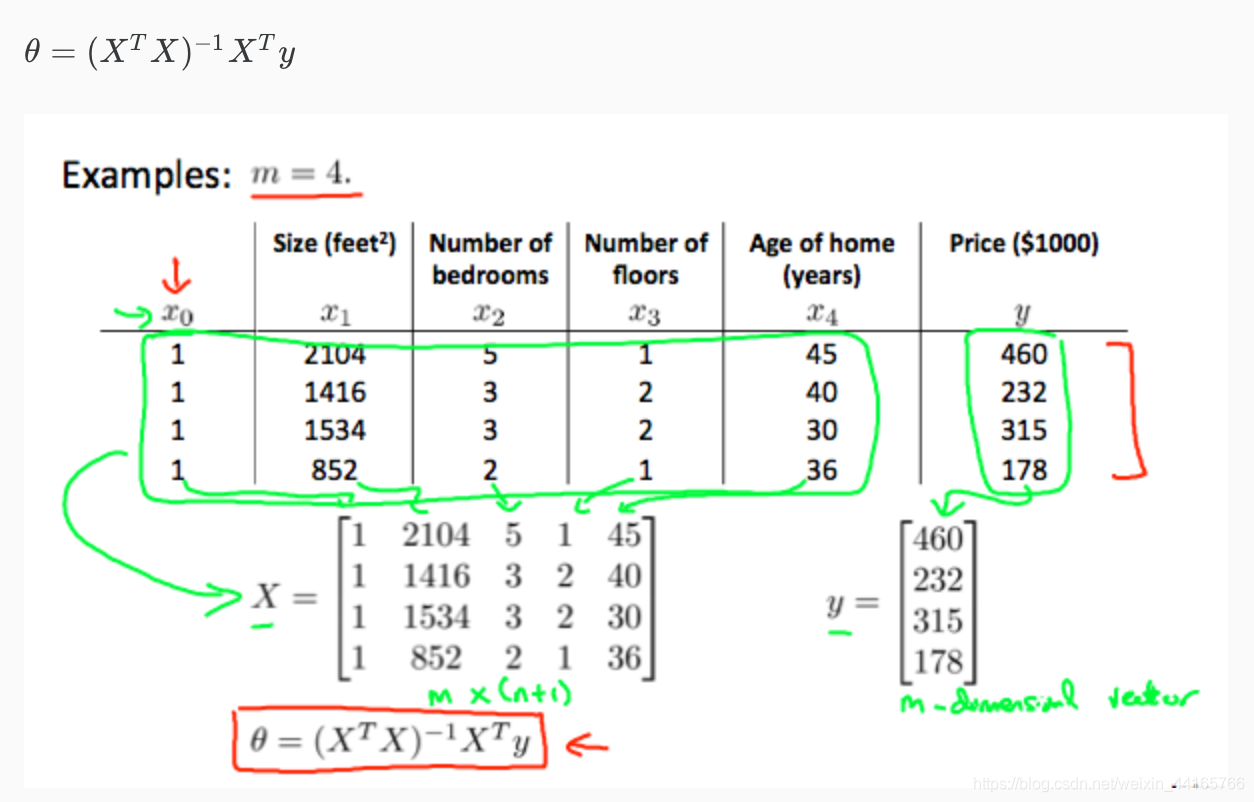
如图中所示,用这个公式就可以直接找到我们最理想的theta,而且效率非常高。如果用这个公式,feature scaling是不必要的。
问题:那我们为什么不直接用这个,多简单多方便?因为如果我们的feature的数量很多的话,那用这个公式计算将会很“贵”。 什么叫“贵”呢?就是说会非常非常没有效率,计算机会需要做庞大的计算。在这个追求效率的社会,这是不好的。那到多少个n(feature的数量)可以允许我们使用这个“作弊捷径”呢? Andrew Ng给的答案是在n=10000以下的时候可以用,但是如果超过这个数字了,最好还是通过gradient descent或是其他的algorithm来寻找theta。
以下的图表为Gradient Descent跟Normal Equation的性质差:
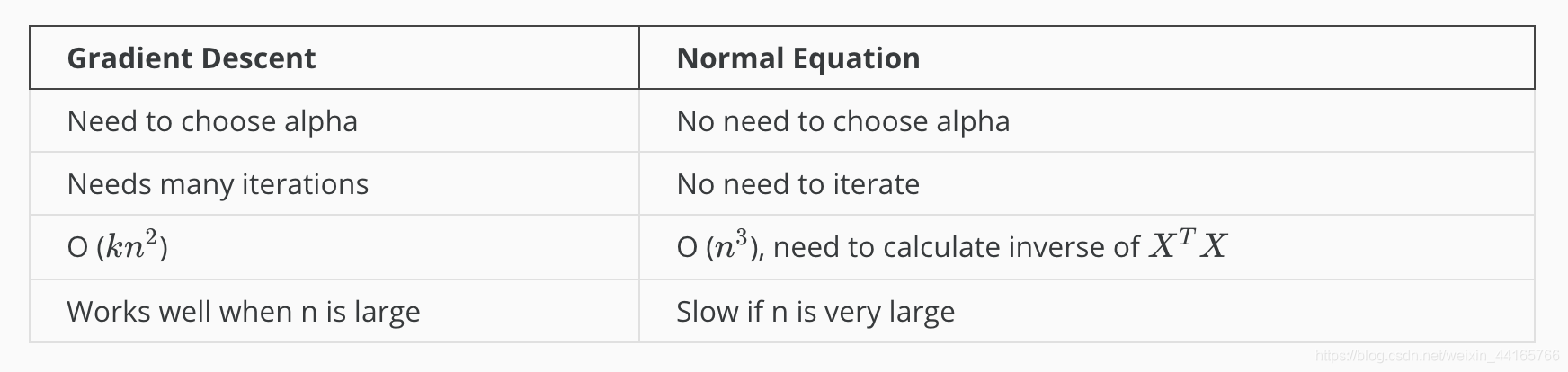
简单的说就是:
Gradient Descent
- 需要选择alpha(learning rate)
- 需要很多次的运算
- O(kn^2)的计算复杂度
- n(feature数量)庞大的时候好用(当然不庞大的时候也好用只是Normal Equation可能是个更好的选择)
Normal Equation
- 不需要选择alpha
- 不需要多次运算(一次就算好)
- O(n^3)的计算复杂度,因为要计算X’ * X
- 如果n很庞大,会非常的慢而且“贵”
Week 2的编程作业我会分开在另外一个笔记里写。
Thanks for reading!














 131
131











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









