






作者简介:王春波,《高效使用Greenplum:入门、进阶和数据中台》作者,“数据中台研习社”号主,十年数据开发从业者,资深零售数仓项目实施专家。
以下内容摘自《高效使用Greenplum:入门、进阶和数据中台》第14章。
京东购买链接:https://search.jd.com/Search?keyword=%E9%AB%98%E6%95%88%E4%BD%BF%E7%94%A8Greenplum
要实现数据中台,一个最基本的要求就是同步交易系统接口数据。实现接口数据同步的方式主要有3种:全量同步、增量同步、流式数据同步,其中流式数据又分为业务流数据和日志流数据。
接口数据同步是数据中台的一项重要工作,是在搭建数据中台的过程中需要投入很多精力完成的。虽然单个表的数据同步任务难度不大,但是我们需要在数据中台实现标准化配置,这样才可以提高工作效率,为后续的数据中台运维和持续扩充接口打下良好的基础。
全量接口同步
一般而言,全量接口同步是数据中台必不可少的功能模块。不管是增量数据同步还是流式数据同步,都是在全量接口同步的基础上进行的。
全量接口同步一般针对T+1的业务进行,选择晚上业务低峰和网络空闲时期,全量抽取交易系统的某些业务数据。一般来说,虽然全量接口同步占用时间长,耗费网络宽带高,但是数据抽取过程简单、准确度高,数据可靠性好,因此比较容易进行平台标准化配置。
根据目前的开源生态,我们主要推荐了两种数据同步工具,一个是Kettle,一个是DolphinScheduler集成的DataX。
1.Kettle
对于Kettle,我们一般按照系统+业务模块来划分Kettle数据抽取任务。
第一步,把对应数据库的JDBC驱动都加入到data-integration\lib目录下,然后重新打开Spoon.bat。
第二步,在新创建的转换里面创建DB连接。
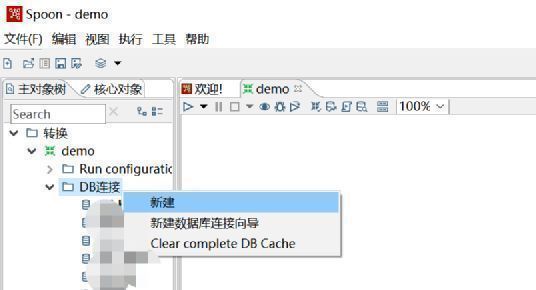
在弹出的页面选择对应的数据库,填写相关信息并保存。
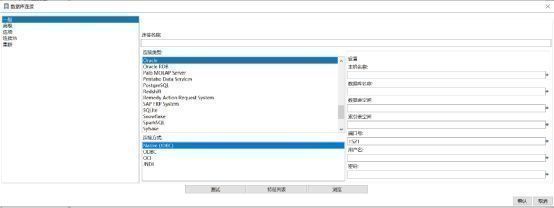
针对DB连接设置“共享”,可以在多个Kettle中共享相同的数据库链接信息。
第三步,在Kettle开发视图中拖入一个表输入组件和一个表输出组件。
在表输入组件和表输出组件中分别选择不同的数据库连接,表输入支持选择一张表自动生成SQL语句,也支持手写SQL语句。
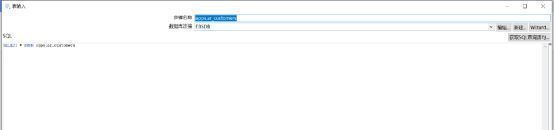
表输出组件则支持自动获取表结构和自动生成目标表。通过点击获取字段,即可直接获取表输入查询到的字段信息。
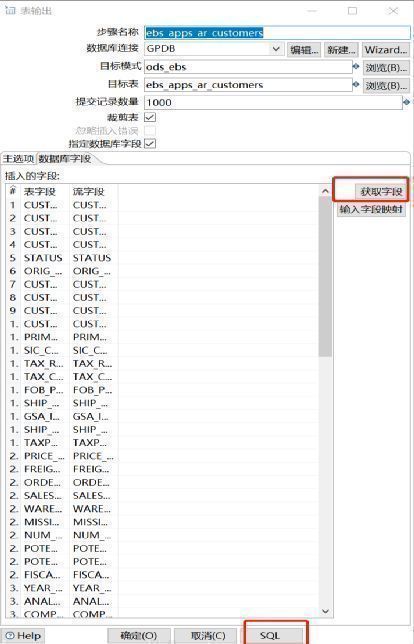
图14-4 Kettle表输出界面
点击SQL,即可在弹出的窗口中看到工具自动生产的建表语句,再点击“执行”,Kettle会自动完成目标表的创建。当然,这个建表语句是比较粗糙的,我们一般需要按照指定的规范来手工创建,需要指定分布键。
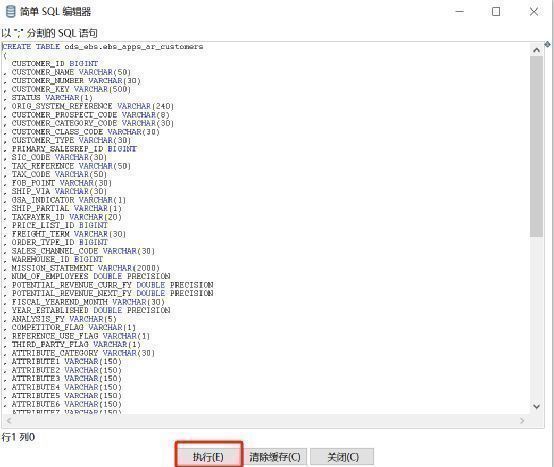
第四步,将输入组件和输出组件用线连起来,就组成了一个数据同步任务。
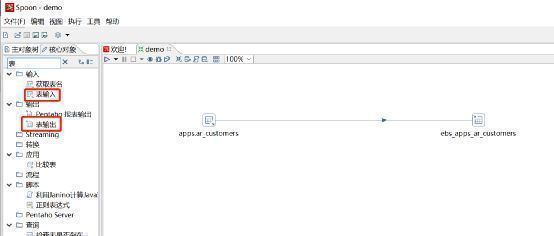
第五步,将上述组件一起复制多份,修改来源表、目标表、刷新字段,即可完成大量的数据同步任务。

第六步,直接点“开始”图标运行数据同步任务或者通过Kettle的左右来调度数据同步任务。
2.DataX
由于DataX数据同步工具本身是没有界面化配置的,因此我们一般会配套安装DataX-web或者DolphinScheduler调度工具。DolphinScheduler集成DataX的配置也很简单,只需要在DolphinScheduler的配置文件中指定DATAX_HOME即可。
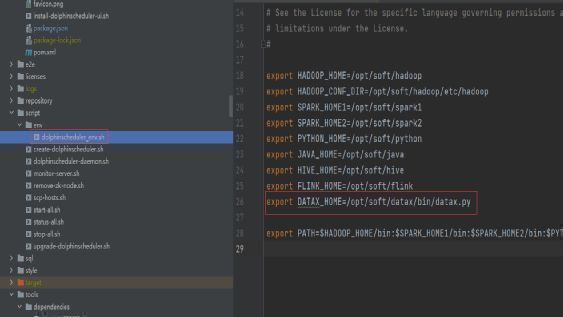
在DolphinScheduler后台配置datax任务,这里以MySQL数据源为例,数据流配置如下。
首先在数据源中心配置MySQL数据源。
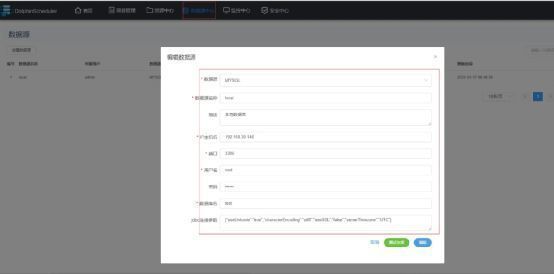
然后在项目管理里面创建数据流任务,在画布上拉去DataX类型配置第一个任务,选择刚才配置的MySQL数据源。
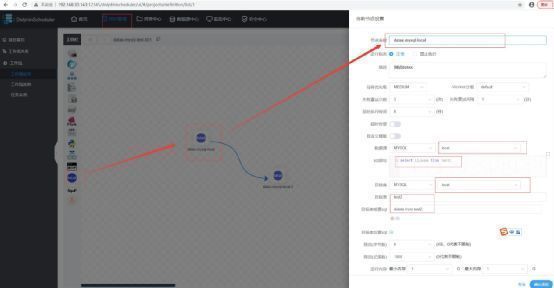
保存以后,系统就会自动生成数据同步的工作量,将数据流上线,并配置定时调度策略,即可完成数据的定时同步。
增量接口同步
一般来说,数据仓库的接口都符合二八规律,即20%的表存储了80%的数据,因此这20%的表数据抽取特别耗费时间。此时,对于批处理来说,最好的方法是,对于80%数据量较小的表,采用流水线作业的方式,快速生成接口表、接口程序、接口任务,通过全量接口快速抽取、先清空后插入目标表;针对20%数据量较大的表,则需要精耕细作,确定一个具体可行的增量方案。
我认为一般满足以下条件之一就是较大的表:①抽取时间超过10分钟;②单表记录数超过或者接近100万;③接口数据超过1GB。之所以如此定义,是从数据接口的实际情况出发。第一,抽取时间超过10分钟,会影响整体调度任务的执行时间;第二,单表记录数超过100万,则插入数据占用数据库大量的资源,会影响其他任务的插入,降低系统的并发能力;第三,数据传输超过1GB,则需要耗费大量的网络宽带,每天重复一次会增加网络负担。
对于需要做增量的接口表,主要推荐以下两种批处理方案。
方案一:根据数据创建或者修改时间来实现增量
很多业务系统一般都会在表结构上增加创建和修改时间字段,并且存在主键或者唯一键(可以是一个字段,也可以是多个字段组合),同时确保数据不会被物理删除,这种表适合方案一。实际情况是,各大OLTP系统的数据库都可以满足记录创建和修改时间信息的,因此这种方式应用最广泛。
对于创建或者修改时间,MySQL数据库可以在建表时指定字段默认值的方式来生成。
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间'
也可以在建表以后通过增加字段的方式来补充。
-- 修改create_time 设置默认时间
CURRENT_TIMESTAMP ALTER TABLE `tb_course`MODIFY COLUMN `create_time` datetime NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间' ;
-- 添加update_time 设置 默认时间 CURRENT_TIMESTAMP 设置更新时间为 ON UPDATE CURRENT_TIMESTAMP
ALTER TABLE `tb_course`ADD COLUMN `update_time` datetime NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间'
Oracle数据库默认情况下只能记录创建时间,不能记录修改时间。
--先添加一个date类型的字段
alter table tb_course add create_time date; --将该字段默认为系统时间
alter table tb_course modify create_time default sysdate;
如果需要记录修改时间,则需要通过触发器或者修改更新语句来实现。触发器的脚本如下。

有了创建或者修改时间以后,每次抽取最近几天(一般建议3天)的数据,则直接在where条件后面加上下面的过滤条件。
--取最近3天插入或者更新的记录
where create_time >= cast(date_add(CURRENT_DATE,interval -3 day) as datetime)
or update_time >= cast(date_add(CURRENT_DATE,interval -3 day) as datetime)
DataX或者Kettle在抽取数据时直接在SQL语句上加上上述条件即可,数据写入临时表,笔者一般以_incr作为临时表后缀。
抽取到变化的数据以后,将前后数据进行合并即可完成增量数据更新。一般情况下我们可能会采用MERGE INTO的方式进行数据合并,这里推荐先删除后插入的方式。首先,MERGE只有少数数据库支持,虽然Greenplum也支持,但是功能不够完善,语法比较复杂。其次对于大多数数据库而言,删除比更新更快,因此推荐先删除后插入的方式。如果变化的数据不大,可以直接采用删除再插入的方式;如果变化的数据太大,删除的效率太低,则需要借助第三张表来完成数据的合并。先删除后插入的语句示例如下,假设DRP系统的item_info表是一张商品主数据,数据量大,但是变化频率不高,则我们可以通过下面的语句来合并增量数据。

方案二:增加触发器记录创建或者修改时间来实现增量
对于SAP之类的业务系统,我们经常遇到有些表要么没有创建、修改时间,要么存在记录物理删除的情况,因此无法通过方案一实现增量。结合HANA数据库的特点,我们最后采用了创建触发器来记录业务数据创建、修改时间的方案。
这种方案下,我们需要针对每一张增量接口表,创建一张日志表,包括接口表的主键字段、操作标志、操作时间。每次抽取数据需要用日志表关联业务数据,然后抽取一段时间内新增、修改、删除的记录到数据中台数据库,最后根据操作标志+操作时间对目标表数据进行更新。
本方案虽然看上去对交易系统的侵入性较高,很难被接受,但其实是一个非常好用的增量方案,适合任何场景。首先,触发器是Oracle、DB2、HANA等数据库系统标配的功能,在表上增加after触发器对业务交易影响微乎其微。其次,抽取数据的时间一般都在业务空闲时间,业务表和日志表的关联不会影响正常交易。第三,本方案可以捕捉数据的物理删除操作,可以保证数据同步100%的准确性。
下面,我们以SAP S/4 HANA的EKPO表为例进行方案解析。首先创建EKPO变更日志表。
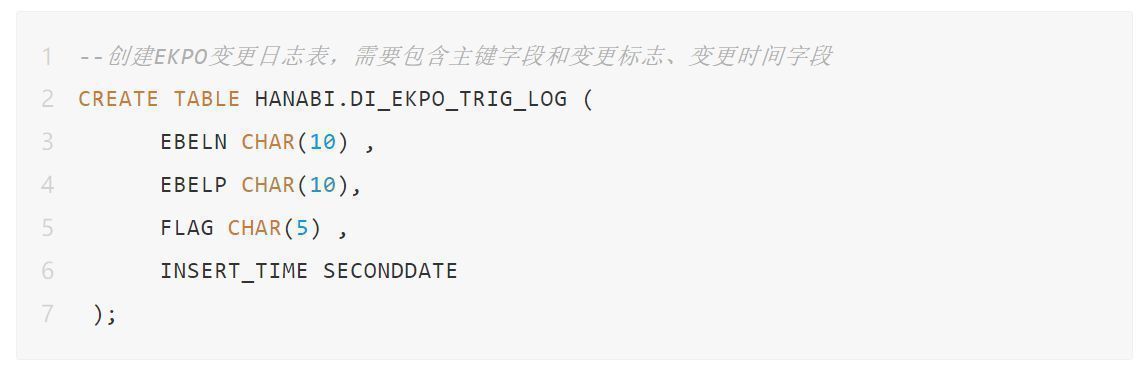
然后给EKPO表添加触发器。

有了变更日志表以后,用变更日志表关联源表,就可以得到源表新发生的所有增、删、改记录时间。

记录上次抽取时间的方案可以更加灵活地控制抽取数据的区间。为了抽取的数据不会遗漏,我们一般根据数据量预留10分钟的重叠区间。
首先,我们需要创建增量数据抽取的控制参数表ctl_ods_sync_incr。

然后,我们在抽取脚本中读取和更新抽取日志表。
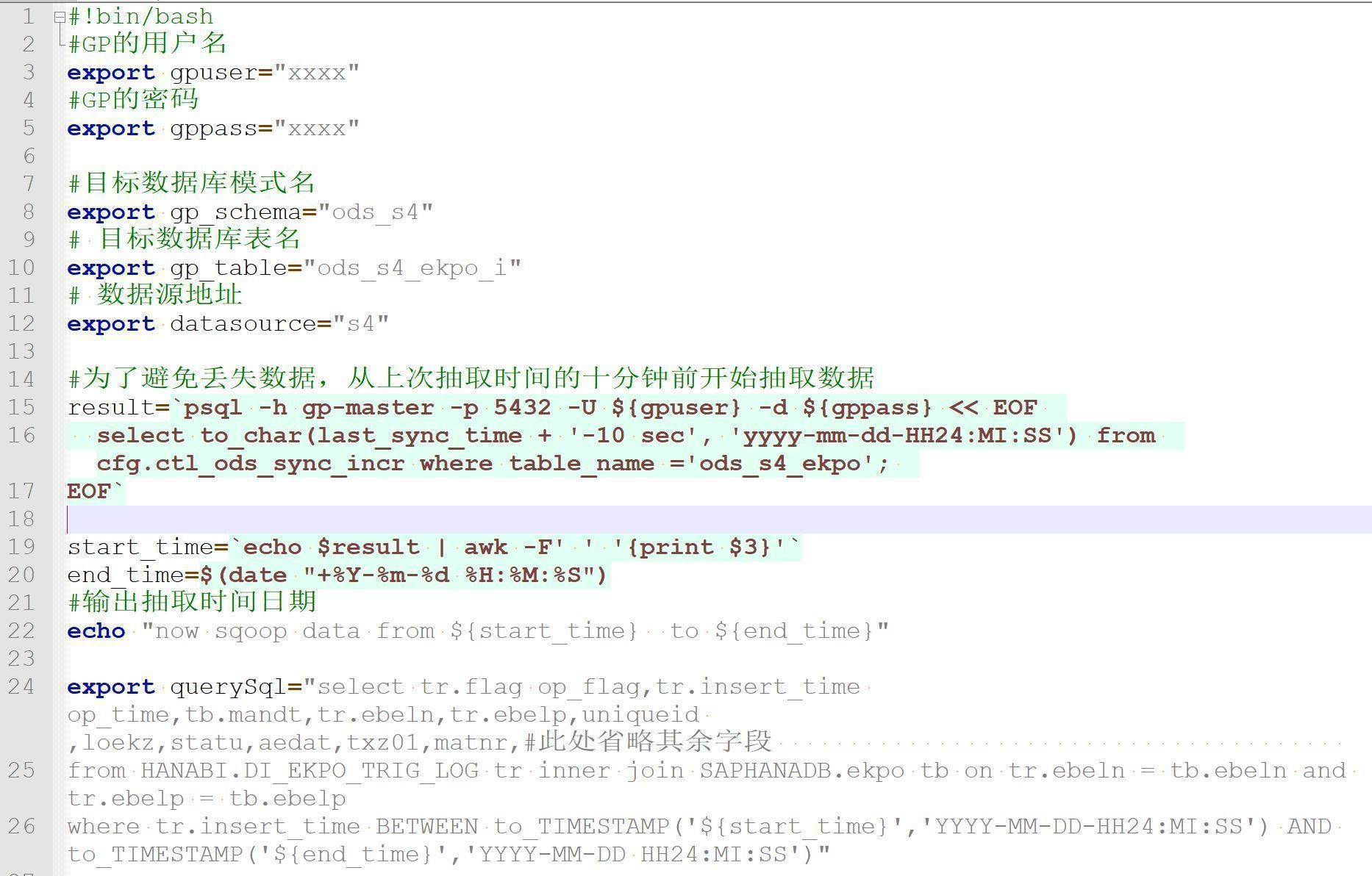
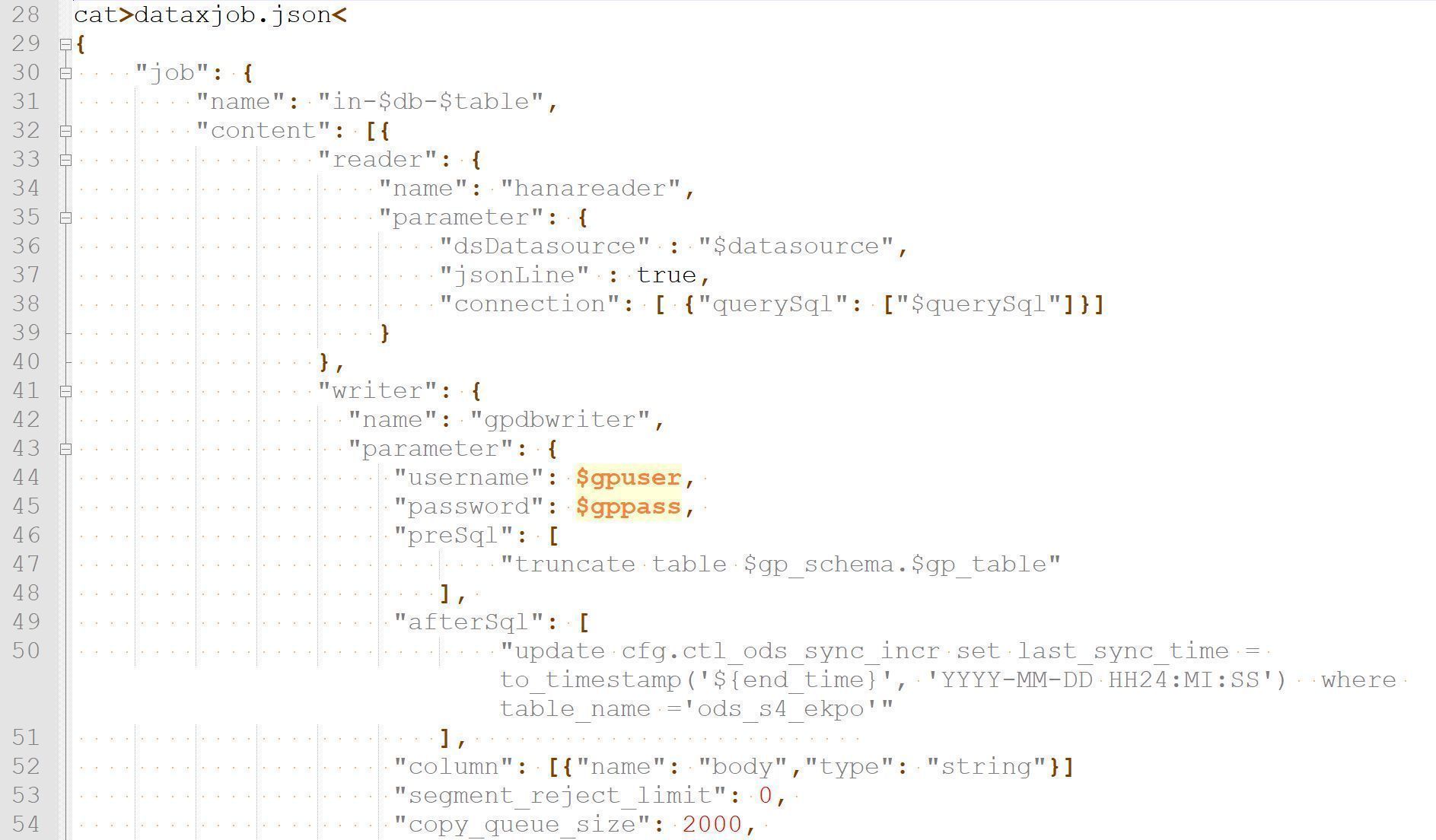
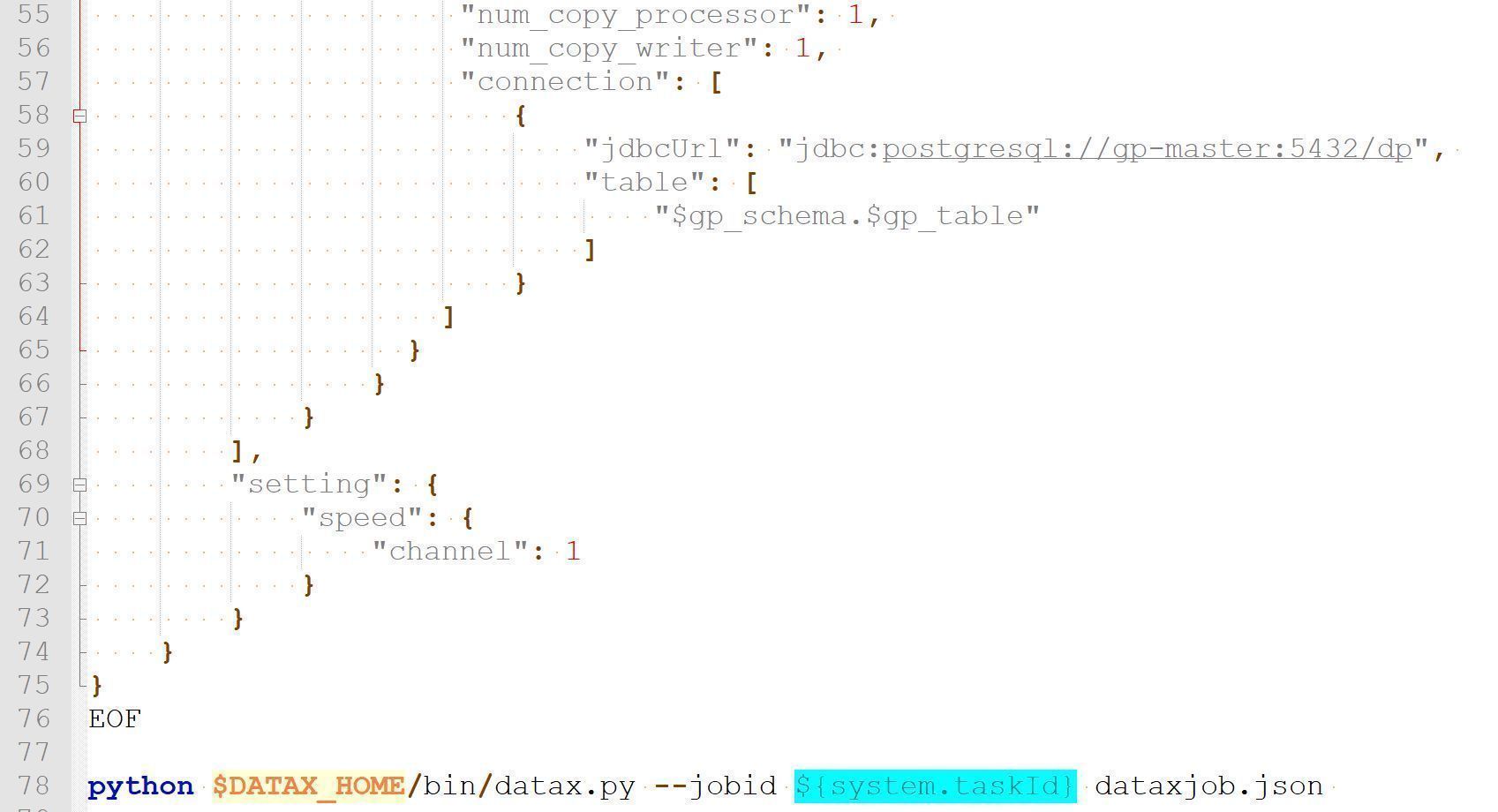
在保证数据抽取过程中不遗漏数据的前提下,我们需要对新抽取到的数据和历史数据进行合并。由于数据可能存在删除和多次修改的情况,我们的数据更新操作会比方案一更加复杂,需要在插入或者删除数据的过程中做一些开窗函数排序取最新的记录,操作语句如下。

为什么SAP接口会有这么复杂的逻辑,这是我们多次实践总结出来的经验。这个增量接口方式我们核对和修复了不少于5次漏洞才最终实现准确快速又稳定的增量接口方案。
流式数据同步
通过上节的增量数据接口可以看出,不管是方案一还是方案二,都需要业务系统数据库做出一定的调整(当然,如果某些业务系统数据库已经在设计的时候考虑到创建和更新时间,则不需要修改),一次性抽取大量的数据会对交易数据库产生压力。基于上述原因,对于类MySQL数据库,我们推荐CDC日志的同步方式。其他数据库如果可以满足CDC日志的要求,也可以采用这种方式。
基于CDC日志同步的方案,也称作流式数据同步方案,一个典型的数据采集流程如下图。
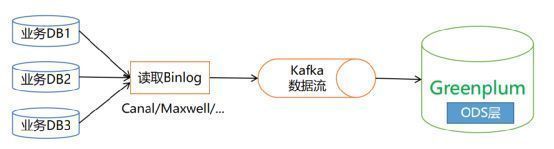
第一步,需要对业务数据库进行分析,分析数据库是否支持CDC日志。一般来说,业务数据通常保存在关系型数据库中,从数据库的发展来看,MySQL对CDC日志的支持是最好的。
第二步,需要有DBA权限的管理员开启数据库的CDC日志功能。其中MySQL数据库的CDC功能开启过程如下。


第三步,通过Canal、MaxWell、Debezium等开源组件读取数据库日志,将数据库转换成JSON对象写入Kafka队列。
第四步,通过Greenplum的GPSS读取Kafka消息或者通过Flink程序(Spark也可以)读取Kafka数据更新写入Greenplum数据库。
随着各个开源组件功能的完善,其中有些步骤已经可以省略了。例如Flink社区开发了flink-cdc-connectors组件,这是一个可以直接从MySQL、PostgreSQL等数据库直接读取全量数据和增量变更数据的source组件。
日志流数据同步
随着大数据技术的发展,日志数据的分析也成为数据中台必不可少的一个功能。一般来说,日志数据会以日志流的方式进入系统。
我们这里所说的日志数据,一般是指Web应用或者手机程序的埋点日志,一般包括用户点击、浏览、鼠标停留、收藏、加购、分享等操作信息。这些操作虽然未产生真正的业务价值,但是可以用来进行用户行为分析和业务促销活动。
典型的用户行为数据采集流程:
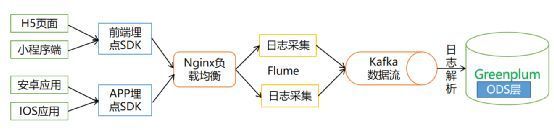
第一步,需要前端工程师或者App开发者在Web或者APP应用页面添加埋点信息,搜集用户的操作,并通过异步Post的方式发生给Ngnix服务器。
第二步,Ngnix服务器接收到用户的数据后,以文本格式记录请求参数等信息至access.log。
第三步,Flume实时监控Nginx日志变化,收集并过滤有用日志,之后发送至Kafka。
第四步,埋点数据到达Kafka后,通过Spark程序或者Flink程序完成日志解析,解析完成的数据格式化保存到Greenplum数据库的ODS层。
至此,日志数据采集和解析的工作完成了。
正如文章的章节分布一样,在数据中台实现过程中,最难做也是最费时间的就是增量数据接口。想要实现精准的增量数据快照,不仅有很多前置要求,也有很多数据合并的特殊处理。本文分析的内容适合绝大多数需要做增量接口的场景。而全量接口、实时接口、日志接口大多数情况下主要搭好平台做好配置即可。
更多书中内容,请关“数据中台研习社”公众号或者移步京东购买(链接:https://search.jd.com/Search?keyword=%E9%AB%98%E6%95%88%E4%BD%BF%E7%94%A8Greenplum)。

















 1708
1708

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









