






第二周优化算法
2.1Mini_batch梯度下降算法
①向量化可以让你相对较快的处理所有m个样本,但是如果m很大,处理速度仍然缓慢
②传统的梯度下降算法,需要先处理所有数据,然后进行下一步梯度下降算法
把训练集分割成小一点的子训练集,这些子集取名为Mini_batch(然后每处理一个子集,就把他传下去进行下一步梯度下降算法),同样也要拆分y训练集。
③我的理解:就是不再把所有数据向量化一个大向量,而是多个小向量
2.2理解mini_batch梯度下降算法

①需要决定mini_batch的参数值

选择合适的mini_batch值:一方面得到大量向量化,另一方面不需要等待整个训练集被处理完,就可以开始进行后续工作(但是他没有告诉我多大是合适,老师举的一个例子:5000000拆成1000(mini_batch)*5000)
2.3指数加权(移动)平均
主要讲述了怎么计算指数加权移动平均
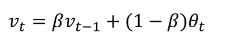

2.4理解指数加权平均
①
② 实质,就是在每一个位置的平均值,其他位置的值按照指数函数值加权平均
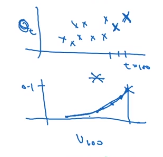
2.5指数加权平均的偏差修正
①
②计算方法:不用 v_t 而是用v_t除以(1-β**t),当t很大,分母几乎为1,偏差修正几乎没有作用,但是可以很好改善,在前期由于令V_t(0)= 0引起的问题
2.6动量梯度下降法(Momentum)梯度下降法
①定义:计算梯度的植树加权平均数并利用一度更新你的权值(我觉得:这大概是指数加权平均在深度学习的应用)
②举例理解
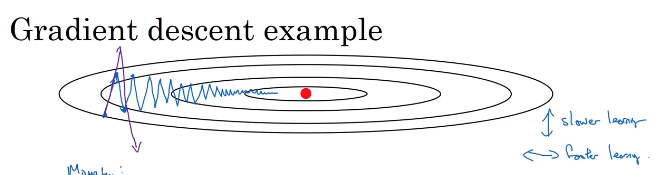
你希望在横轴上速度快一点(且平均数较大),但是希望在纵轴上的摇摆小一点(且平均数接近0),这样学习速率会变快
③计算方法
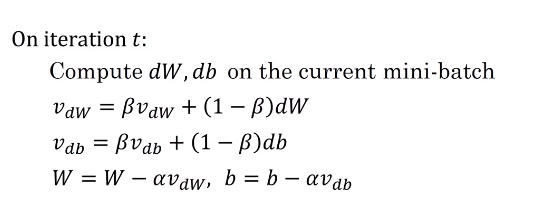
2.7RMSprop
①可以加速梯度下降
②计算过程其实我没怎么看懂(就是想让dw变大,db小一点)

2.8Adam优化算法
①作用:同样是用于加速算法,法则基本上就是将Momentum和RMSprop结合起来
②运行方法:首先初始化


③超参数
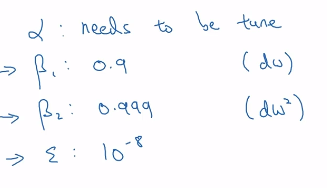
2.9学习率衰减
①加速学习算法的一个办法:随时间慢慢减少学习率

②计算方法


2.10局部最优问题
(没太懂)
局部最优解的问题不是问题
它的问题在于平滑阶段学习速率的问题
当维度十分的高
不同维度在一个位置的成本函数的大小很难统一
















 2657
2657











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











