








Enhanced Target Detection:Fusion of SPD and CoTC3 Within YOLOv5 Framework
增强目标检测:YOLOv5框架下SPD与CoTC3的融合
0.论文摘要
摘要
摘要—高分辨率遥感图像识别具有重要意义,可广泛应用于城市规划、土地利用等领域。现有模型在训练过程中过度关注图像的纹理和细粒度特征,忽略了特征图中更广泛的上下文信息,这降低了模型识别目标的能力。为提高检测精度与鲁棒性,我们提出一种改进版YOLOv5框架,专门针对具有小目标和低分辨率特点的遥感图像分析。通过引入空间到深度(SPD)组件,并采用空洞卷积和深度可分离卷积,增强了模型感知目标属性的能力。此外,我们提出上下文Transformer聚焦综合卷积(CoTC3)模块,将其无缝集成至YOLOv5核心架构。该创新模块使模型能够利用相邻键之间的丰富上下文信息,从而获得更优的特征表示,进而提升检测精度。模型在损失函数等方面也进行了优化以进一步增强性能。通过在包含34类目标、总计382,221个对象的三个不同数据集上评估,改进后的模型在目标检测精度与鲁棒性方面均表现出显著提升。值得注意的是,车辆和桥梁的识别精度分别提高了10.1%和11.3%,整体准确率较基线模型提升至93.5%(提升2.3%)、88.1%(提升2.9%)和71.2%(提升6.3%)。
关键词—注意力机制,高分辨率遥感图像,图像识别,神经网络,YOLOv5。
1.引言
高分辨率遥感技术的进步极大地提升了高分辨率影像在从高空获取地表信息中的作用。此类影像在无人机检测[1]、城市规划[2]、环境监测[3]和资源管理等多个领域日益重要。随着遥感技术的发展和高分辨率影像应用范围的扩大,准确检测这些影像中目标的重要性也随之提升。该能力通过提供对决策至关重要的洞察性数据,成为解决众多实际问题的关键。
目标检测算法在高清遥感影像中展现出广阔的应用前景,能够精准识别特定目标物体。这类方法主要分为传统算法和基于深度学习的两大体系。传统技术依赖人工设计特征与机器学习算法实现目标分类与定位,典型代表包括Haar特征级联检测器[4]、方向梯度直方图(HOG)[5],以及AdaBoost[6]与支持向量机(SVM)[7]等分类器。而近年来蓬勃发展的深度学习方法则通过区域提案与单次检测两大技术路线实现了变革性突破:以R-CNN[8]和Fast R-CNN[9]为代表的区域提案方法擅长在大尺度场景中精确定位特定目标;YOLO[10]和SSD[11]等单次检测方法则注重检测效率,其中YOLOv5因其卓越性能尤为突出。这些计算机视觉技术的进步为高清遥感图像目标检测带来重大突破,YOLOv5更是表现抢眼。Zhu等[12]基于YOLOv5提出了巨型岩石检测算法;Zhang等[13]的研究则展示了该模型在小行星图像中检测大型岩石的多功能性与高性能表现。
然而,基于深度学习的高分辨率复杂遥感影像目标检测方法仍面临重大挑战。这类影像具有目标种类繁多、分布场景复杂的特点,且目标本身存在多尺度、多形态、多外观特性,加之遮挡、光照变化和视觉噪声等问题,严重影响了现有检测技术的精度与可靠性。当前主流模型尚未能有效解决遥感影像中普遍存在的目标尺寸微小、分辨率低下等特殊难题。因此,亟需开发更先进、更强大的方法体系来提升高分辨率遥感目标检测效能。例如,Biswas和Tesic[14]提出基于对比学习的卫星图像识别算法,有效提升了卫星影像中小目标物体的识别精度;Konstantinidis等人[15]设计了基于卷积神经网络(CNN)的新型架构,旨在增强遥感数据中建筑物的检测能力;Biswas和Tesic[16]开发了基于偏差的去偏对比学习数据集标注方法,可有效降低偏差提升准确率;Bai等[17]改进了Faster R-CNN模型以提升地标建筑的识别效率;Lang团队[18]则构建了基于YOLO的检测系统,用于实现遥感影像中目标的快速精准识别。尽管取得进展,这些方法在高清遥感模型训练过程中可能忽略特征图的关键细节信息,从而削弱模型的精准识别能力。空间到深度(SPD)[19]组件能有效保持特征图的细粒度特征,但目前极少应用于遥感图像识别领域。我们创新性地将SPD组件引入高清遥感图像识别任务,以更好地保留细粒度特征并提升识别精度。
自Bahdanau等人[20]于2015年首次提出这一概念以来,注意力机制已成为深度学习方法中的关键组成部分。这种创新方法增强了模型对输入数据不同部分进行差异化优先级排序和加权的能力,尤其在序列数据分析中表现突出,由此催生了大量探索其潜力的研究和多样化应用。例如,Li等人[21]提出了一种完全基于Transformer的架构,用于实现端到端视频目标分割,重点关注物体层面的精细空间上下文;Gao等人[22]则利用多轴视觉Transformer微型架构(MaxViT-T)构建了多标签分类矿物识别模型,显著提升了关联矿物的识别准确率;Zhao等人[23]开发了名为增强句间注意力(EIA)的新型自注意力框架,可无缝集成Transformer模型以加强跨句信息的提取与应用;Ren等人[24]设计了一种基于协同注意力的多模态融合网络用于评论有用性预测,该方法不仅关注文本与视觉线索的协同作用,还将传统手工特征与深度学习特征相融合,通过利用不同数据模态间的关联动态优化性能。CoT模块[25]作为一种新型注意力机制,能更好地捕捉图像语义信息并减少对纹理细节的过度依赖,其通过聚焦上下文信息提取,在遥感图像识别中展现出更优性能。然而现有研究对特征提取过程中上下文信息提取与特征融合的交互关系关注有限,且先进注意力机制在提升上下文提取与语义捕获能力方面的潜力尚未得到充分探索。此外,当前模型难以缓解对纹理细节的过度依赖,制约了高分辨率遥感图像的高精度识别效果。
尽管近年来的研究极大推进了遥感图像识别技术的发展,但仍存在明显局限性。例如,现有大多数遥感目标检测深度学习模型难以精准识别小型低分辨率目标,且在复杂高分辨率数据集中往往无法保持此类目标的完整性;传统深度学习方法有时无法有效捕捉或保留遥感图像分类识别所需的细粒度特征;部分模型对上下文信息的利用也欠佳。如图1所示,传统方法通常难以准确识别遥感影像中的小目标,导致检测精度和鲁棒性较低。图1(b)左上角的船舶未被检测到,这表明现有方法过度依赖图像中的纹理和细节信息,而忽视了更广泛的上下文信息。这导致在检测船舶等小型遥感目标时性能较差,尤其当图像背景纹理复杂时。本文正是针对这些问题展开研究。


图1. 现有方法缺陷示例(以YOLOv8为例)。(a) 船舶原始图像。(b) 船舶热力图(YOLOv8生成)。© 飞机原始图像。(d) 飞机热力图(YOLOv8生成)。(e) 车辆原始图像。(f) 车辆热力图(YOLOv8生成)。
因此,本研究利用注意力机制独特的识别与关键数据优先级处理能力,将其与YOLOv5相结合,提出了一种针对上述挑战优化的改进模型。该研究旨在显著提升高分辨率遥感场景下的目标检测效能。本文的核心贡献与创新点可概括如下:
- 提出了一种改进的YOLOv5架构,专门针对遥感图像中小目标和低分辨率目标的检测需求进行优化。该改进通过在原始YOLOv5的特征融合功能中引入SPD组件,增强了感知层保留细节特征的能力,并强化了图像表征学习。
- 创新性地构建了上下文 Transformer 聚焦的综合卷积模块(CoTC3),该模块将CoT与C3块协同融合,应用于YOLOv5的主干网络和颈部网络。这一设计显著提升了模型利用相邻关键点间广泛上下文数据的能力,从而优化了特征表征并提高了检测精度。
- 我们替换了YOLOv5的传统损失函数,并在NWPU VHR-10数据集上通过消融实验验证其效果。具体而言,车辆和桥梁的检测精度分别提升了10.1%和11.3%,其他分类数据类型也取得了显著进步。
- 我们分别在DOTA、DIOR和NWPU VHR-10数据集上进行实验,结果表明相较于传统YOLOv5模型,所提模型的准确率有显著提升。我们的模型在三个数据集上的平均准确率分别达到71.2%(DOTA)、88.1%(DIOR)和93.5%(NWPU VHR-10)。
本文档按以下方式组织。首先,我们探讨了多种成熟的图像识别方法,并深入研究了注意力机制的概念。随后,我们概述了YOLOv5技术以及注意力机制的具体应用。接着,详细阐述了本研究中构建的算法框架,并阐明其基本原理。此后,我们描述了为验证所提模型有效性而开展的实验过程,最终对研究结果进行了全面讨论。文章结尾总结了关键发现,并对未来潜在研究方向提出了见解。相关代码可参阅文献[26]。
2.相关工作
本文档这一部分深入探讨了遥感领域中图像识别的基础性内容,既涵盖传统方法,也着重分析了注意力机制增强的技术路径。需要特别说明的是,相关讨论主要针对高分辨率遥感影像展开。本节还简要介绍了YOLOv5算法,并就该场景下注意力机制的融合应用进行了探讨。
A. 基于遥感图像的识别
遥感图像识别涉及对获取的遥感影像进行分析与处理,以实现自动化识别与分类任务。这类图像通常通过无人机、卫星等设备进行航拍获取。特征提取是该过程中的关键步骤,它将原始图像转化为分类器可用的特征向量。该领域的传统方法包括局部二值模式(LBP)[27]、方向梯度直方图(HOG)[5]以及尺度不变特征变换(SIFT)[28],这些方法主要侧重于从图像中提取纹理、形状和颜色等特征属性。
基于深度学习的方法能提供更精准高效的特征提取能力。卷积神经网络(CNN)[29]、循环神经网络(RNN)[30]以及YOLO[31]等模型可自动学习特征,显著提升识别精度与效率。YOLOv5作为当前流行的单阶段目标检测算法,在保持优异性能的同时兼具轻量化与高效特性。该算法基于单阶段目标检测框架,其具体结构如图2所示,支持多种变体以适应不同应用场景,并能处理各种尺寸的输入图像。本文采用的YOLOv5版本使用C3模块[32]替代了原有的瓶颈CSP结构,在保持功能相似的前提下调整了组件选择。C3模块包含三个标准卷积层和多个瓶颈结构,有效提升了目标检测任务的性能。图3展示了该模块的结构示意图。
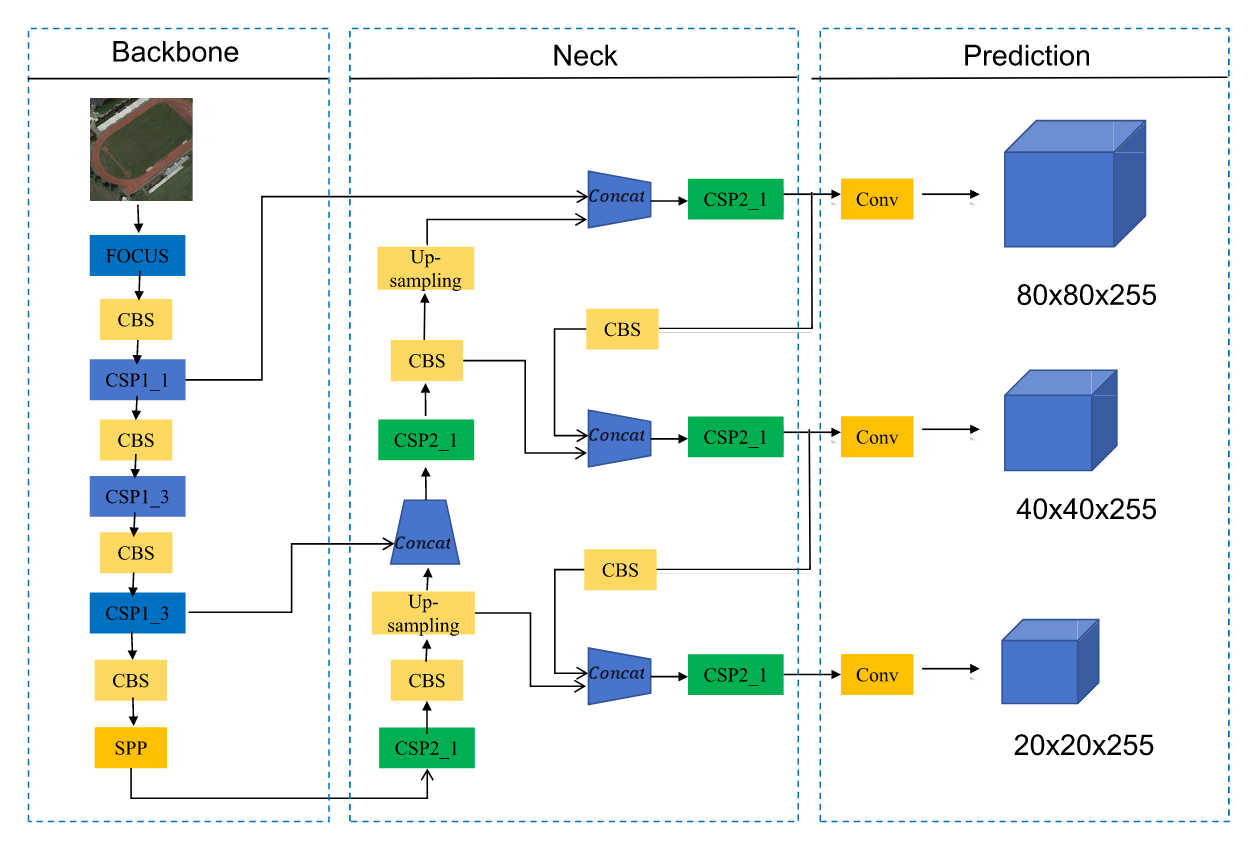
图2. YOLOv5模型结构。
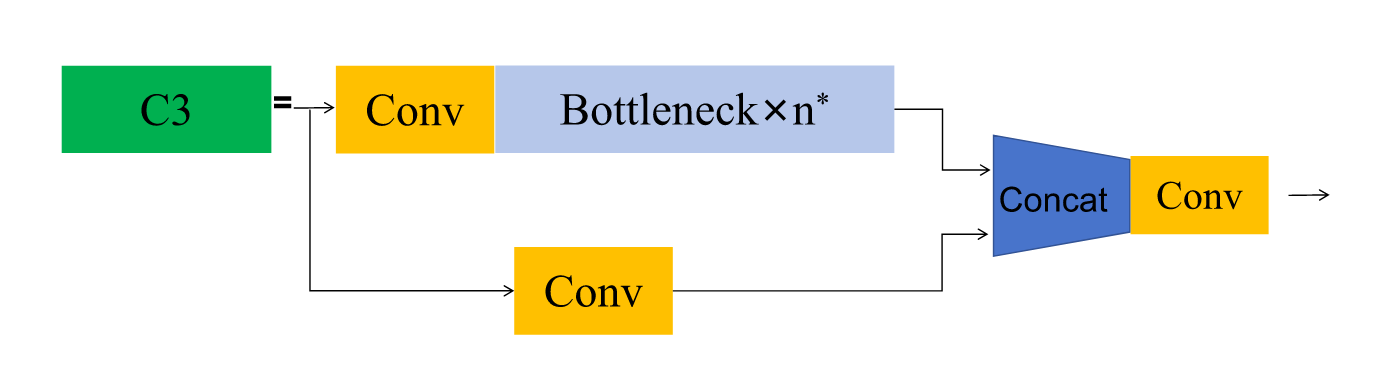
图3. C3模块结构。
B. 基于注意力机制的遥感图像识别
遥感影像中目标物体的微小分辨率,以及尺度、形状和视觉特征的多样性,对传统图像识别技术的效能和精度提出了挑战。近年来,注意力机制在遥感图像分析领域已成为重要趋势,其通过提升图像清晰度来改善识别效果的作用已得到验证。多项研究证实了注意力机制整合方案的有效性:黄等学者[33]将自注意力网络与CNN结合,对江苏东台林场无人机拍摄图像中的林木种类进行分类,不仅证明了Transformer与CNN在树种分类中的协同优势,还解决了低空拍摄导致的图像质量下降问题;程等研究者[34]创新性地构建了以YOLOX为核心、融合注意力机制的多特征提取框架,通过重构主干网络将多分支卷积与注意力机制相结合,并优化损失函数,显著提升了对不同尺寸目标的特征提取能力,从而提高了遥感图像检测精度。
相反,一部分研究者提出在算法中集成精简的注意力机制,旨在降低计算开销的同时,解决遥感影像分辨率不足带来的挑战,从而提升模型的整体效率。例如,Tong等[35]采用极简注意力机制对多尺度RGB与多光谱影像进行优化处理。该方法应用于专门为遥感图像道路提取构建的数据集时,通过抑制此类数据中常见的多种噪声,获得了更优的结果。类似地,付洪建与洪阳[36]通过在YOLOv5框架中嵌入基于Swin Transformer的轻量级自注意力模块,显著提升了模型在密集区域的特征识别能力。Biswas等[37]则通过减少YOLOv5参数量,有效压缩了模型规模并降低了功耗。
3.方法
本部分深入探讨了YOLOv5框架所采用的核心改进措施,阐明这些优化如何显著提升模型的效能。
针对传统方法因遥感影像中目标尺寸微小、分辨率低而导致检测能力不足的问题,我们提出了一种改进的YOLOv5模型变体,专门针对遥感图像分析进行了优化。该模型基于YOLOv5 6.0版本架构构建。图4展示了这一增强型YOLOv5的设计方案。如图所示,SPD组件[19]被集成在主干网络中(以浅绿色标注),而CoT模块[25]则被置于颈网络上采样阶段的C3模块之前,由此形成了CoTC3复合模块(以浅蓝色标注)。此外,该CoTC3模块也被整合到主干网络的SPP模块[38]之后。SPD组件的引入旨在保留图像细微特征,从而提升模型对图像特征的学习与表征能力。与此同时,颈网络中CoT模块的加入引入了先进的注意力机制,增强了模型对相邻关键点间广泛上下文信息的利用与解析能力,进而优化了特征表征与检测精度。
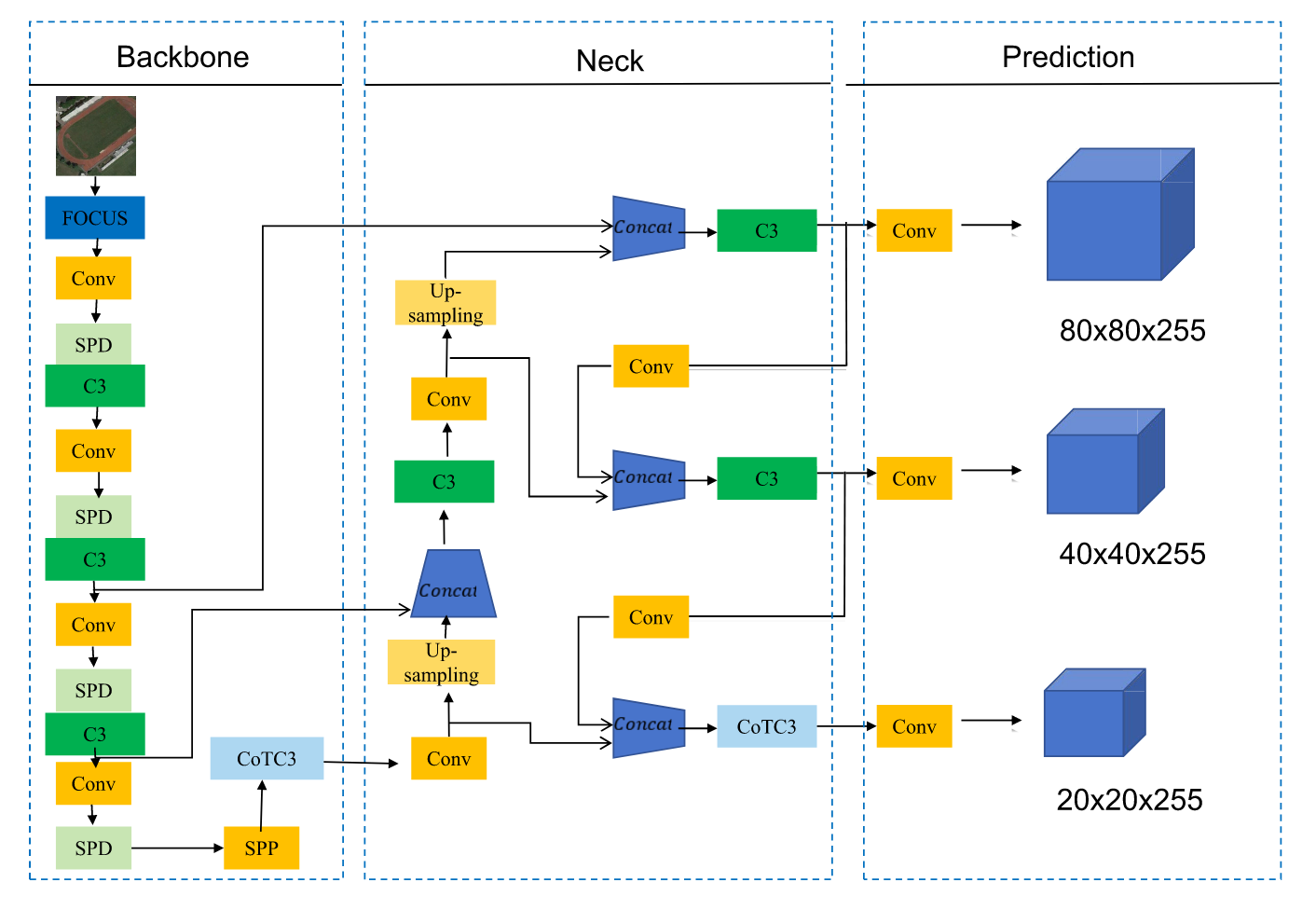
图4. 改进版YOLOv5模型结构。
A. 框架中SPD组件的改进
在YOLOv5框架中,我们对主干网络进行了增强,以解决遥感影像中小目标和低分辨率目标检测的相关问题——这些问题通常会降低卷积神经网络的性能。如图4所示,标为浅绿色的SPD组件被集成到主干网络中。该组件专门设计用于更有效地捕捉遥感图像中固有的球面细节特征。
我们将传统的常规小目标与大目标检测视为多尺度物体检测问题,通常采用图像金字塔方法[39]。该方法通过调整输入图像的多种尺寸并为每个尺寸训练专用检测器,导致所有模型都统一采用步进卷积和最大池化操作。然而研究发现,此类技术在处理低分辨率图像或小目标时效果欠佳,主要由于细节信息丢失。为应对这一问题并增强模型的特征表征能力,我们在方法中引入了SPD组件。该组件通过采用深度非跨越卷积层来保留细节特征,与传统跨越式卷积和池化操作形成显著差异,从而大幅提升了图像特征表征能力和学习效率。
对于特定的遥感图像特征图X(S, S, C1),其中"S"表示高度和宽度,"C1"表示特征维度,SPD组件的作用是在CNN中对这些特征图进行下采样。该过程将整个CNN的输出分割成一系列缩放后的子特征图,随后沿通道维度将这些分割后的特征图连接起来,形成中间特征图 X ′ ( ( S / s c a l e ) , ( S / s c a l e ) , s c a l e 2 C 1 ) X'((S/scale), (S/scale), scale²C1) X′((S/scale),(S/scale),scale2C1)。以 s c a l e = 2 scale=2 scale=2为例,在对X进行切片后,得到四个子特征图 X 1 ( ( S / 2 ) , ( S / 2 ) , C 1 ) X₁((S/2), (S/2), C1) X1((S/2),(S/2),C1)、 X 2 ( ( S / 2 ) , ( S / 2 ) , C 1 ) X₂((S/2), (S/2), C1) X2((S/2),(S/2),C1)、 X 3 ( ( S / 2 ) , ( S / 2 ) , C 1 ) X₃((S/2), (S/2), C1) X3((S/2),(S/2),C1)和 X 4 ( ( S / 2 ) , ( S / 2 ) , C 1 ) X₄((S/2), (S/2), C1) X4((S/2),(S/2),C1),连接这些子特征后得到中间特征图 X ′ ( ( S / 2 ) , ( S / 2 ) , 4 C 1 ) X'((S/2), (S/2), 4C1) X′((S/2),(S/2),4C1)。
B. CoTC3模块
- CoT模块:图5展示了CoT模块的网络结构。
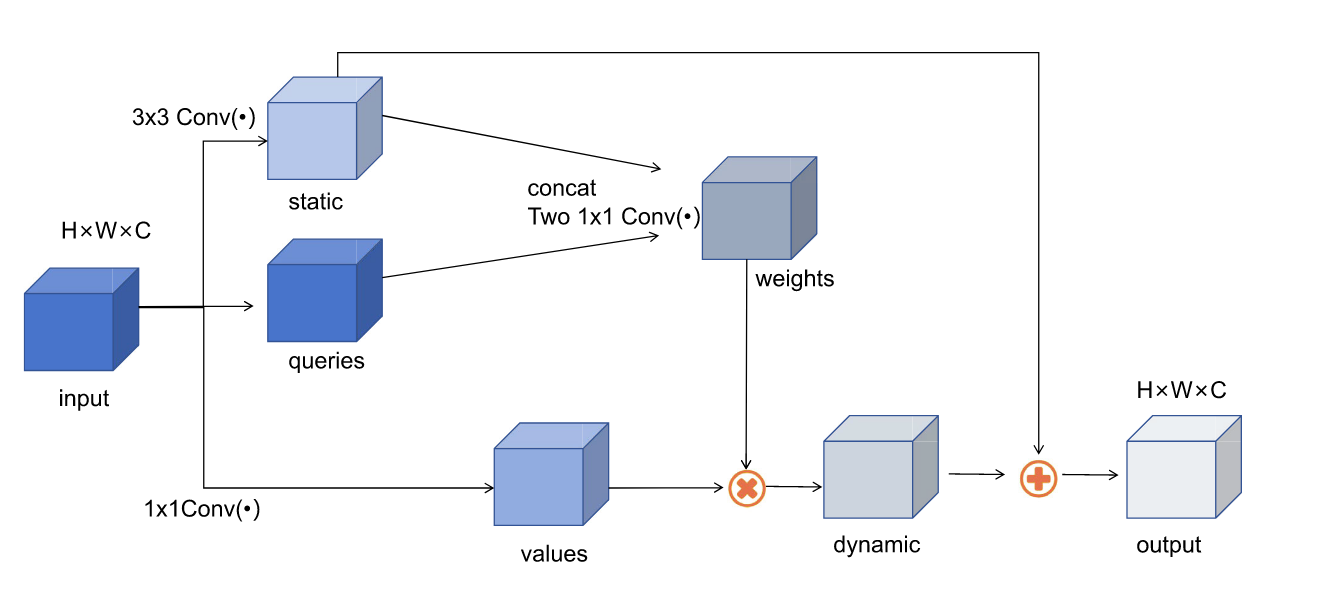
图5. CoT模块网络结构。 ⨁ \bigoplus ⨁和 ⨂ \bigotimes ⨂分别表示逐元素求和与局部矩阵乘法。
具体而言,对于给定尺寸为 H × W × C H×W×C H×W×C(H:高度,W:宽度,C:通道数)的遥感图像特征图G,我们定义键 K = G K = G K=G、查询 Q = G Q = G Q=G、值 V = G W v V = GW_v V=GWv,其中 W v W_v Wv为嵌入矩阵。CoT模块首先对3×3网格内的所有相邻键进行空间上下文编码,从而获得上下文键 K 1 ∈ R H × W × C K^1 ∈ R^{H×W×C} K1∈RH×W×C(R为局部关系矩阵)。 K 1 K^1 K1反映了G中局部相邻键之间的静态上下文信息。
随后,将 K 1 K^1 K1与Q合并,并通过两次连续的 1 × 1 1×1 1×1卷积操作——第一次采用ReLU激活函数( W θ W_θ Wθ),第二次则不使用激活函数( W δ W_δ Wδ)——生成注意力矩阵( A A A),其计算方式如下:
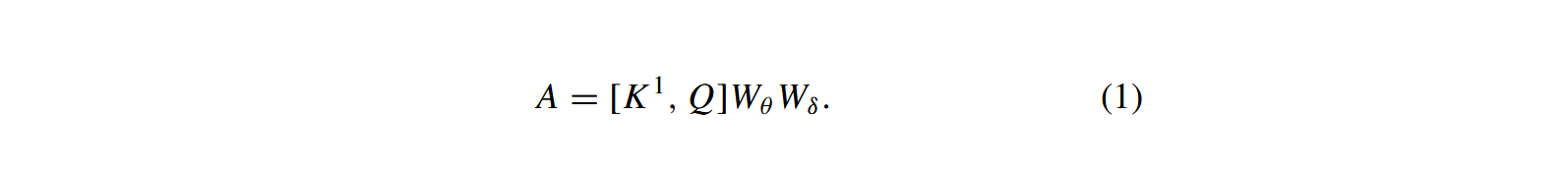
随后,矩阵 A A A在上下文中被用于融合 V V V,通过局部矩阵乘法( ⨂ \bigotimes ⨂)生成一个上下文加权的特征图( K 2 K^2 K2)。
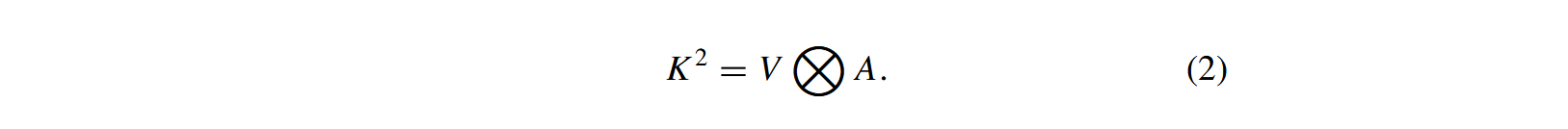
在最终阶段,CoT模块将静态上下文( K 1 K^1 K1)与动态上下文( K 2 K^2 K2)进行整合,通过这种复杂的上下文融合过程增强特征表示,最终输出优化后的结果。
- CoTC3模块:将CoT块集成到YOLOv5的C3组件中,形成了创新的CoTC3模块。传统C3块通过独立通道的双1×1卷积层处理输入特征图,生成两个不同的变换特征图。如图6所示,这些特征图在经CSP瓶颈块处理后,会与辅助分支输出沿通道轴进行合并。我们对原始设计进行了突破性改进,采用bottleneckCoT块替代了CoTC3模块中的传统瓶颈组件(具体结构见图7)。首先通过1×1卷积层精简输入特征,有效减少通道数以降低计算量并提升模型泛化能力。随后特征由CoT块处理,该模块融合静态与动态上下文信息,生成具有全局表征力的特征图。最后通过1×1卷积恢复原始通道数。通过堆叠多个颈部CoT块,CoTC3模块构建了深层网络架构,显著增强了网络的深度特征提取能力。

图6. CoTC3模块。
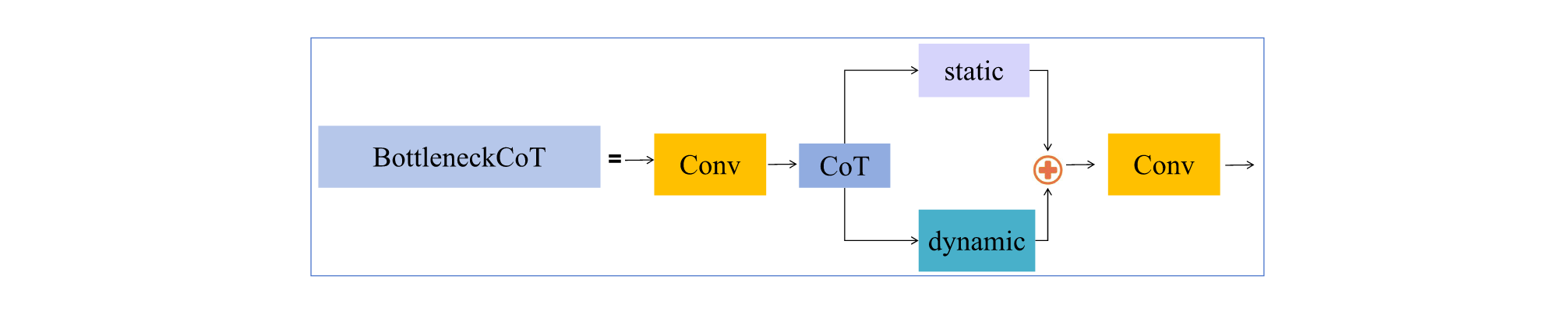
图7. Bottleneck CoT模块。
- CoTC3对框架的改进:在YOLOv5模型中,颈部网络对目标检测至关重要,其任务是通过上采样和特征图融合来提升检测精度。然而我们的实验发现,原始颈部网络的上采样方法存在一个关键问题,主要涉及信息丢失和分辨率质量下降。传统的上采样方法往往会模糊特征图中复杂的局部细节,而这些细节对于精细目标或密集排列物体的识别至关重要。这一问题在高分辨率遥感影像中尤为突出,因为此类影像中的目标具有复杂的纹理模式和细微特征,这些特征对准确识别至关重要。
为应对这些挑战,我们的创新方案将CoTC3模块整合到YOLOv5的颈部网络中,取代传统的上采样模块。CoTC3模块引入了一种新颖的上采样方法,不仅能更有效地提升特征图分辨率,还能保持其特征一致性。该模块的策略性应用解决了原颈部网络在处理高分辨率图像时的局限性,显著提升了模型精准检测较小且密集分布目标的能力。
原始YOLOv5网络在将信息传递至颈部网络前,会在骨干网络中使用空间金字塔池化(SPP)模块。然而这一特征提取过程耗时较长,且可能导致部分信息丢失。为解决该问题,我们在SPP模块后引入了CoTC3模块,通过其内嵌的自注意力机制增强特征提取能力。该改进旨在利用CoTC3中的自注意力机制强化特征提取,从而提升遥感图像中目标的检测与定位精度。
4.实验
在本部分中,对所提出的模型进行了全面比较,重点分析了关键性能指标。评估采用了一系列量化模型效能的指标,其中最重要的是平均精度均值(mAP)、平均精度(AP)、召回率(R)和精确率(P),这些指标分别从不同维度揭示了模型的性能表现。
这些指标共同构成了对目标检测模型性能的全面评估,有助于我们理解模型在不同方面的表现,从而指导后续的改进与优化。
A. 数据集与环境条件
- 数据集:在数据集选择方面,我们选取了DOTA[40](https://captain-whu.github.io/DOTA/index.html)、DIOR[41](http://www.escience.cn/people/gongcheng/DIOR.html)和NWPU VHR-10[42](https://github.com/Gaoshuaikun/NWPU-VHR-10)这三个开源卫星图像数据集作为实验数据源。
NWPU VHR-10数据集被广泛认可并用于遥感影像目标检测与识别算法的评估与改进。该数据集由中国西北工业大学的一个遥感研究团队开发,在遥感图像分析领域获得了高度关注。NWPU VHR-10数据集包含10类不同地理环境下的3651幅遥感图像,涵盖飞机(AR)、船舶(SP)、储油罐(ST)、棒球场(BD)、网球场(TC)、篮球场(BC)、田径场(GT)、港口(HB)、桥梁(BE)和车辆(VE)等场景,为算法测试与验证提供了多样化的场景。这些图像具有极高的分辨率,能捕捉精细的细节和丰富的特征信息,同时呈现不同的光照条件和观测角度,增强了数据集的多样性和代表性。图8展示了DOTA数据集与NWPU VHR-10数据集的部分示例图像,其中图8(a)为运动场样本图,图8(b)为帆船样本图。

图8. 数据集中的样本图像。(a) 真实场样本。(b) 船舶样本。
为增强模型对图像中目标物体位置的鲁棒性,我们对上述数据集采用了数据增强技术。通过随机缩放处理不同尺寸的输入图像,以提升尺度不变性。缩放比例从原始尺寸的80%、100%和120%中随机选取,在保证图像完整性的同时,确保增强后的图像仍保留足够的可识别语义信息。水平与垂直方向的随机翻转技术引入了镜像变换不变性,有效降低了模型对此类变化的敏感性。此外,通过施加随机旋转使模型能够适应图像旋转变化,从而增强旋转不变性。这些技术的综合应用显著提升了遥感图像分类模型的整体鲁棒性和性能表现。图9展示了部分遥感图像数据增强的示意图。
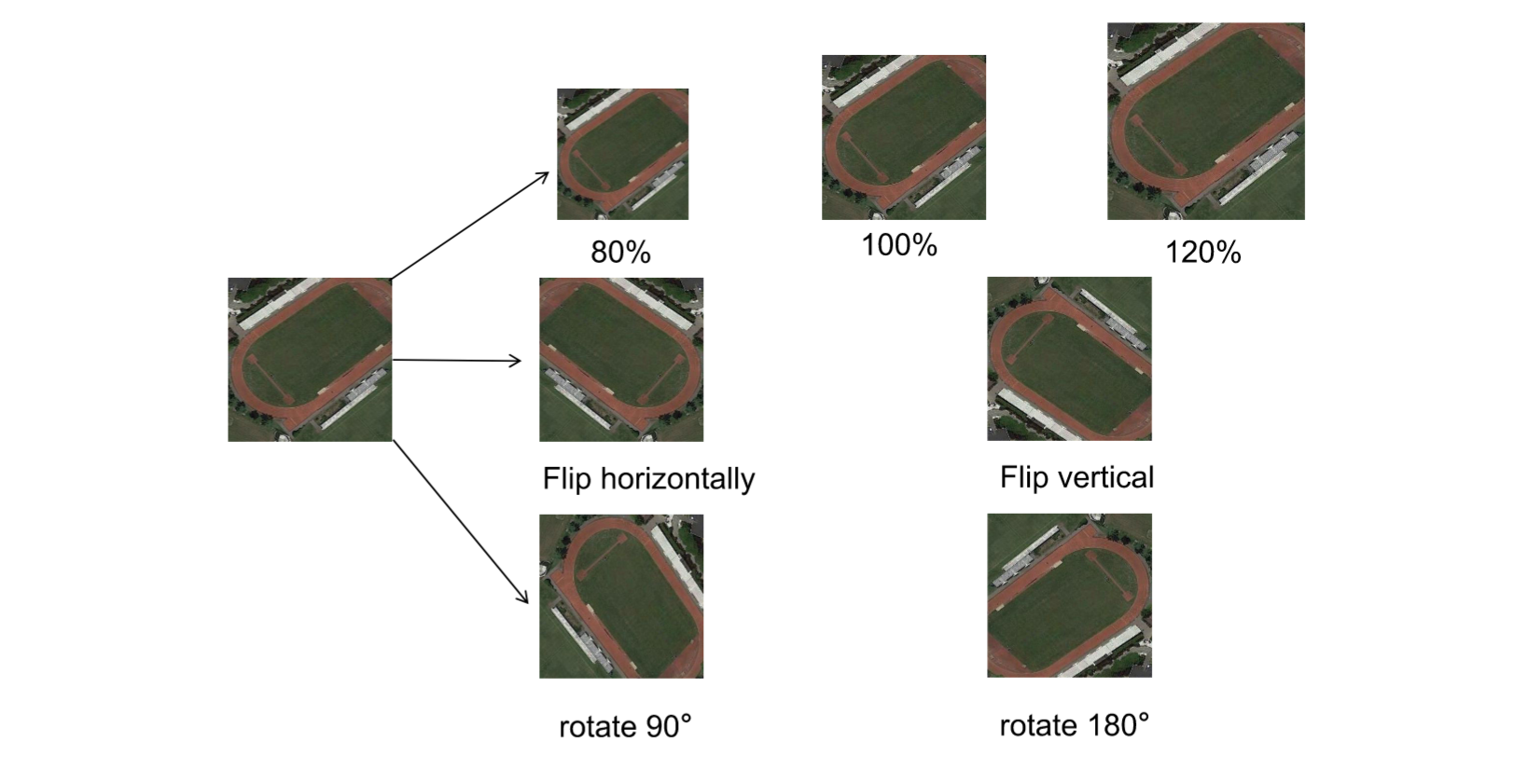
图9. 游乐场样本数据增强示意图。
此外,我们将数据集按7:3的比例划分为训练集和测试集。这种分配方式提供了充足的训练样本量,这对有效训练模型和降低过拟合风险至关重要。同时,更大的测试集能提升模型在真实场景中的性能评估效果,减少随机误差带来的影响。通过在独立测试集上评估模型,可以验证其在不同数据分布、噪声水平和异常值情况下的表现。这一过程增强了模型的鲁棒性,确保其在多样化场景中的有效性。
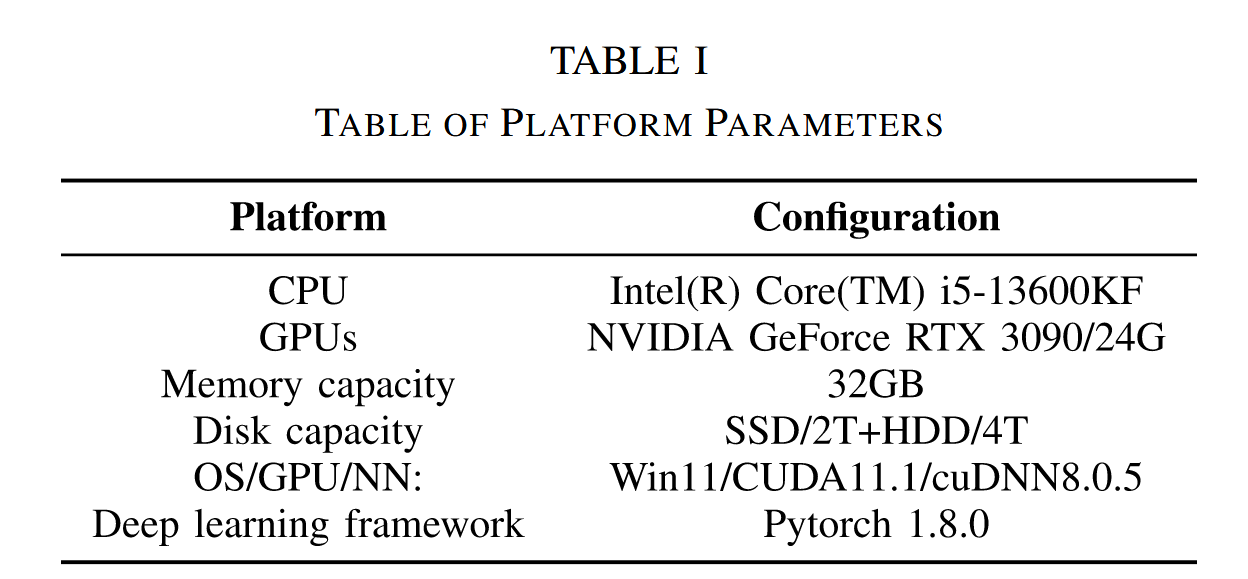
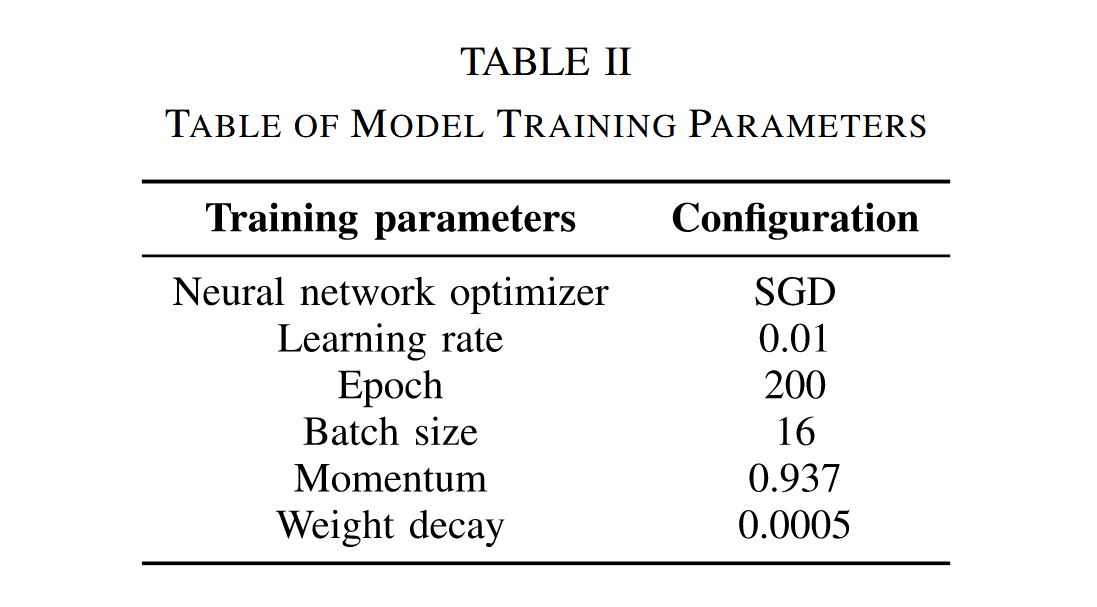
- 实验环境:实验所用硬件与软件环境的具体配置详见表I,模型训练参数列于表II。
B.消融实验
为严格验证YOLOv5模型改进方案的有效性,本研究采用NWPU VHR-10数据集开展了一系列系统的消融实验。实验设计保持了数据集使用的一致性,并控制了模型参数、输入图像尺寸等变量。表III详细展示了这些实验的量化结果,客观评估了所提方法改进带来的性能提升。

第一行是YOLOv5的原始模型,第二行是结合CoT改进后的YOLOv5模型,第三行是结合SPD组件改进后的YOLOv5模型,第四行是同时使用SPD与一个CoTC3组合改进的YOLOv5模型。
通过消融实验可以看出,当在YOLOv5的颈部网络中加入CoT注意力机制时,CoT模块能够通过学习目标上下文之间的关系,使模型有效捕获更多目标信息,模型精度从91.2%提升至91.5%。当在骨干网络中加入空洞卷积和深度可分离卷积后,相较于普通卷积能有效扩展模型对目标的表征能力,但mAP指标有所下降,这表明SPD组件可能与当前模型结构或数据特征的匹配度不足。然而当我们同时加入SPD组件和CoT模块时,模型精度从91.2%显著提升至93.5%,说明SPD组件与CoT模块可能在模型的不同层级和任务的不同阶段产生了协同效应。SPD组件通过保留细粒度空间特征增强了模型对小目标和低分辨率目标的捕捉能力,而CoT模块则通过整合广泛上下文信息提升了模型在复杂场景中的全局识别能力。二者的结合使模型能够充分利用不同层级的图像信息以获得更佳检测效果。此外从表格数据可见,我们提出的框架在各识别率指标上均较YOLOv5原始框架有所提升,其中车辆类别的识别率提升幅度达11.3%。
表IV的结果对比了我们提出的模型与其他配置方案的精确率和召回率指标,包括采用SPD和CoT增强的YOLOv8,以及经过类似增强处理的DS-YOLOv8[43]。DS-YOLOv8是一种专为复杂遥感图像设计的算法,在遥感图像的小目标和遮挡场景中表现优异,因此我们选择其作为实验对照组。所有实验均在NWPU VHR-10数据集上进行,结果表明我们的模型在精确率和召回率上均优于对比方案,分别达到0.935和0.950。
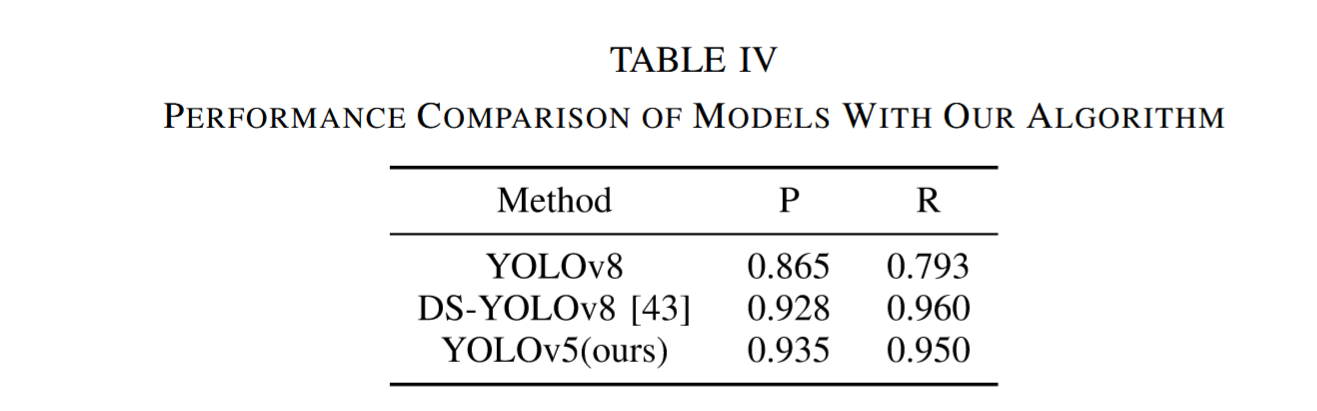
图10和图11展示了该模型训练过程中部分参数的变化曲线及准确率数值。从图10可以看出,我们的模型在NWPU VHR-10数据集中的各类遥感图像上均能取得优异效果,精确率超过0.85。特别是对飞机目标的识别准确率可达0.995,我们认为这是由于飞机具有明显的形状和轮廓特征,使得模型能有效捕捉其特性从而获得更高精度。桥梁的识别效果相对其他遥感图像较弱,我们认为这主要是因为桥梁本身的样本数量在各类图像数据中最少,导致模型对其训练效果不如其他目标理想。
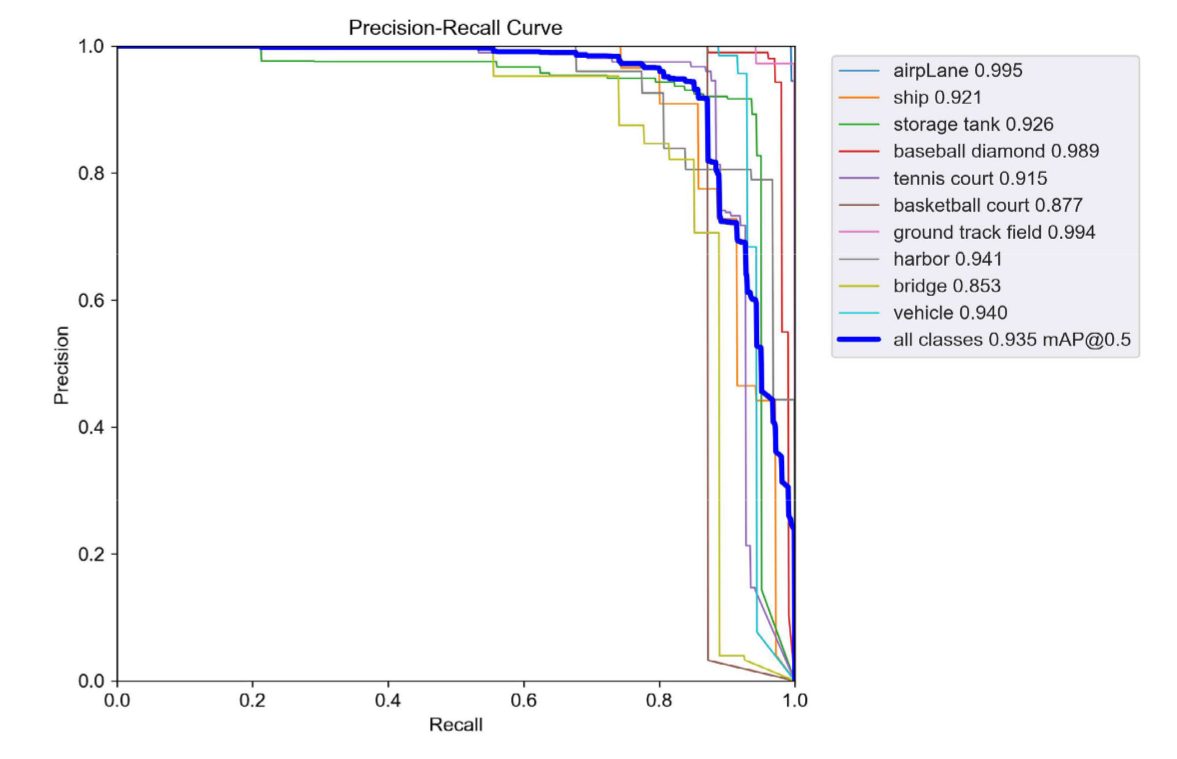
图10. 我们的模型实验结果。
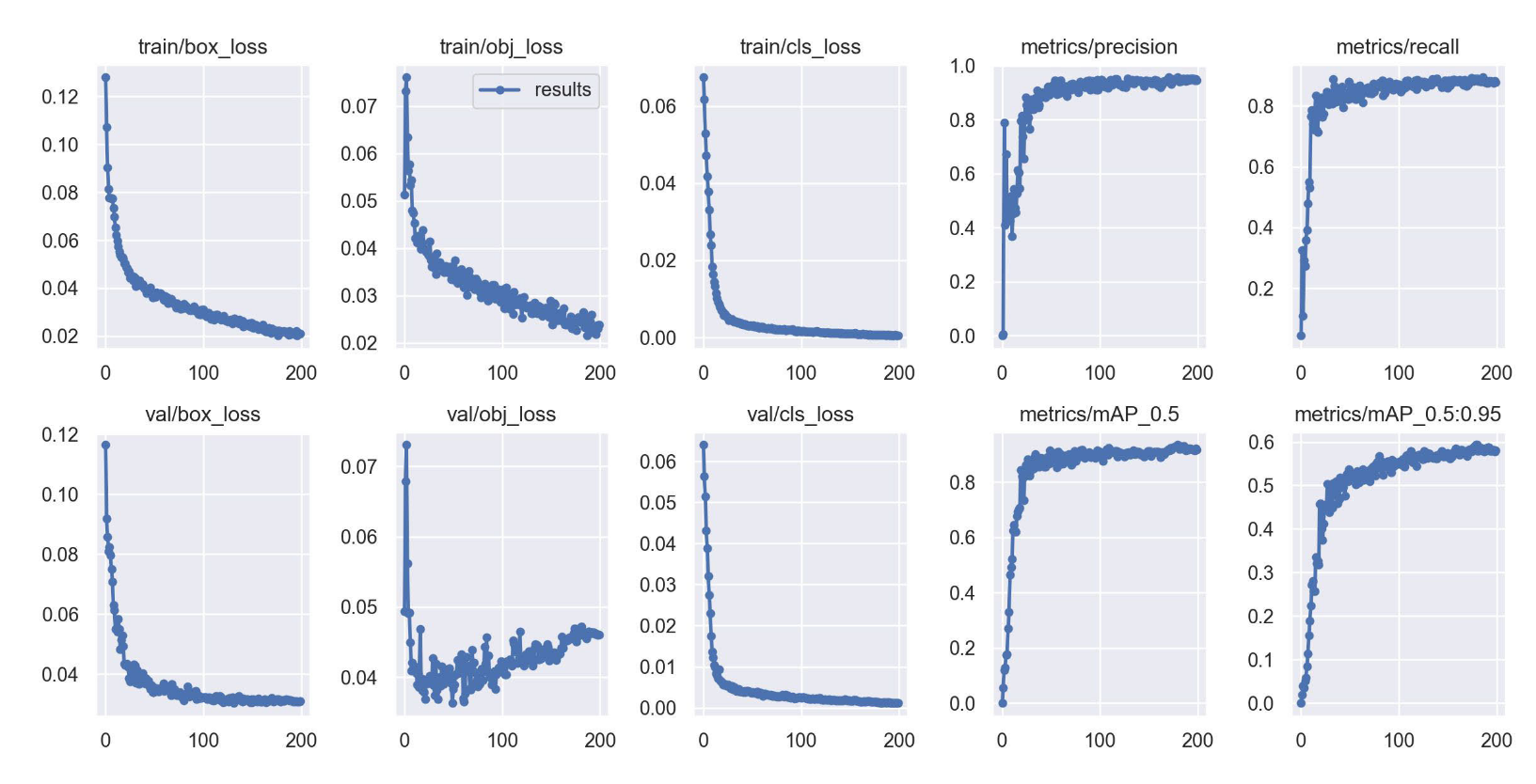
图11. 模型训练过程中各项指标的变化曲线。
训练效果主要通过观察mAP_0.5:0.95和召回率的波动情况来评估,二者波动越小表明训练效果越好。从图11可以看出,精确率、召回率等指标在50个训练周期后均呈现平稳收敛态势,这说明我们的模型训练结果可靠且效果显著。通过边界框(box)图表可见,模型最终结果趋近于0.02,表明我们的模型在边界框识别过程中具有较高精度。从验证集分类(val_cls)和训练集分类(train_cls)曲线来看,模型的损失均值最终无限趋近于0,这说明目标检测效果非常理想。metrics/mAP_0.5图表中曲线最终趋于平缓,表明模型已完成收敛并达到稳定性能水平。
C. 不同损失函数的结果对比
作为深度学习模型训练体系中的关键要素,损失函数用于量化模型预测结果与真实值之间的差异,其本质是指导模型参数优化的导航工具。在目标检测算法领域,交并比(IoU)[44]是评估分割模型性能的常用指标,通过计算预测分割结果与真实分割掩模的交集与并集之比来实现。图12展示了IoU定义的示意图,其数学表达式如下:
图12. 交并比(IoU)定义示意图。
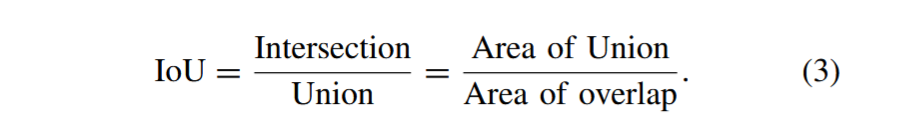
“交集”指预测分割结果与真实分割掩码重合区域的面积,“并集”则是二者合并区域的总面积。IoU是大多数损失函数的先驱,常见的SIoU[45]、EIoU[46]、DIoU、CIoU[47]、α-EIoU等均由其演化而来。
损失函数的选择直接影响模型的训练效果和性能。作为一种惩罚机制,损失函数需要在训练过程中被最小化,理想情况下能勾勒出与真实标注框相匹配的预测目标轮廓框。定义损失函数有几种方法,这些方法会综合考虑以下框体"失配"指标的某种组合:框中心距离、重叠面积以及宽高比。
在图像分割任务中,SIoU作为一种量化指标,用于衡量模型预测分割结果与实际分割掩码之间的重叠程度。现有方法主要通过交并比(IoU)、中心点距离和宽高比等指标来对齐真实框与预测框,但未能考虑两者间偏差的方向性问题。这一局限会阻碍收敛效率,导致预测框在训练过程中发生偏移,从而产生次优模型。SIoU通过重新定义角度惩罚度量,将回归目标之间的向量夹角纳入计算,使预测框能快速与最近坐标轴对齐,进而实现单坐标轴(X或Y)上的回归,有效降低自由度总数。该方法可加速模型收敛并提升训练效率,最终获得更优的模型性能。
SIoU的计算方法如下,其中 Δ \Delta Δ代表距离成本, Ω \Omega Ω代表形状成本:
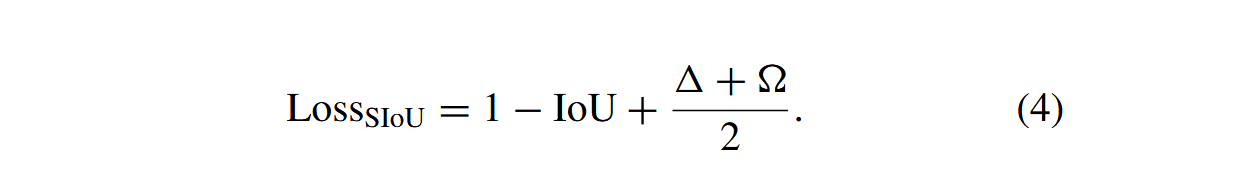
CIoU是一种用于衡量目标检测框匹配度的指标。相较于传统的IoU,CIoU考虑了更多因素,能够更准确地度量目标框之间的距离和重叠程度。
具体而言,CIoU综合考虑了目标框的中心点坐标、宽高比以及两框之间的重叠面积,能更全面地衡量匹配程度。其计算公式如下:
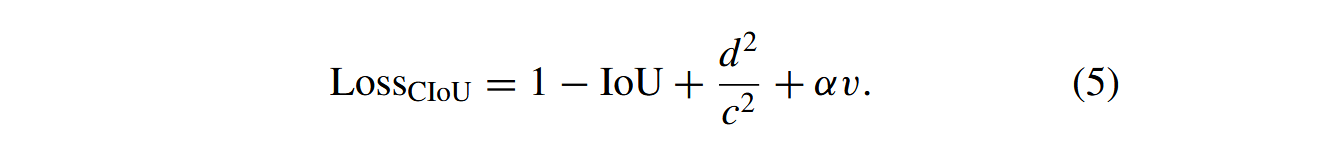
IoU是传统的交并比,表示预测框与真实框重叠区域面积与其并集区域面积的比值。 d d d是预测框中心点与真实框中心点之间的欧氏距离。 c c c是用于标准化 d d d的参数,其值为对角线的长度。 α α α是平衡系数,用于平衡中心点距离与框大小的影响。 V V V是校正因子,用于惩罚长宽比差异较大的情况。
EIoU损失是对CIoU损失的进一步改进。CIoU采用宽高比损失作为惩罚项,而EIoU则提出直接预测边界框的宽度和高度,并将实际框作为惩罚项。其计算公式如下:
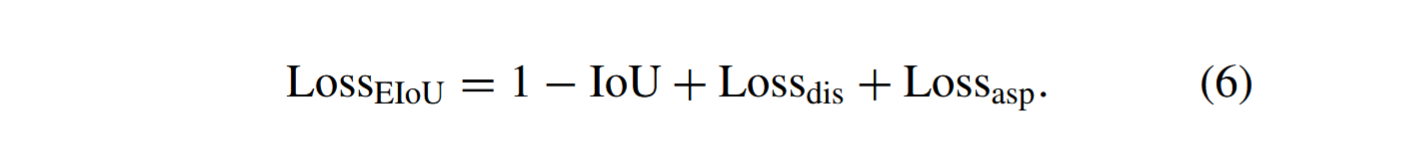
L o s s d i s Loss_{dis} Lossdis是与预测框和实际框中心距离相关的损失。 L o s s a s p Loss_{asp} Lossasp表示预测框和实际框在宽度和高度差异上的损失。
α-EIoU是基于α-IoU概念[48]提出的指数化综合损失函数,其表达式如下:
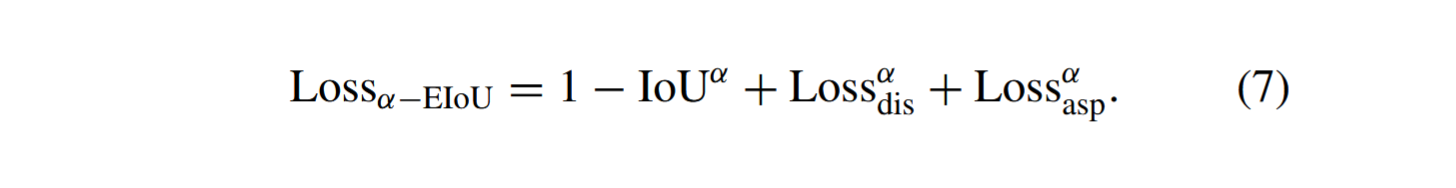
我们提出一种与上述损失函数结合的加权损失函数,表示如下:
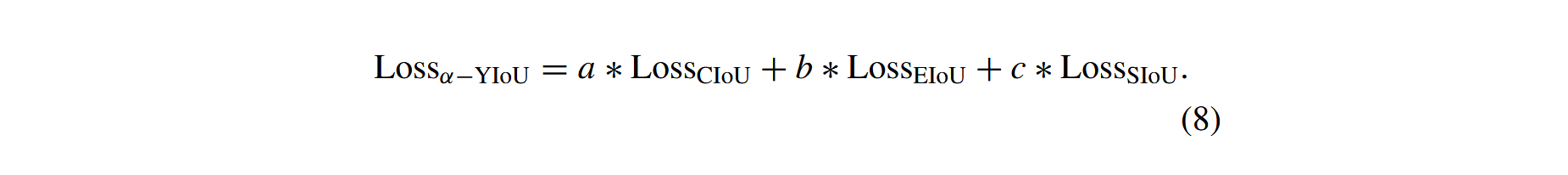
我们通过实验发现,将权重比例设置为0.3、0.3和0.4时效果最佳。
在此研究框架下,我们基于NWPU VHR-10数据集开展了大量实验。这些实验深入探究了多种边界框损失函数,系统分析了其对网络检测精度的影响。通过详细评估EIoU、α-EIoU、SIoU和α-YIoU等损失函数,并与YOLOv5采用的CIoU损失函数进行对比,我们取得了显著成果。具体实验结果详见表V。
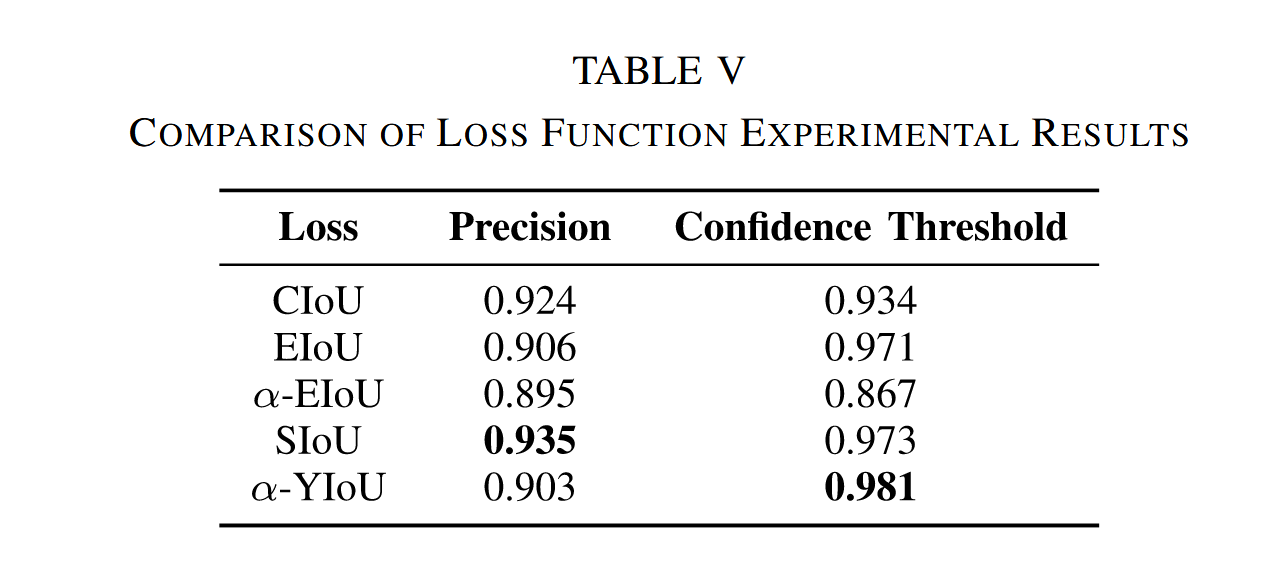
实验表明,每种损失函数均实现了较高精度,验证了其有效性。数据显示,EIoU的置信度阈值较原损失函数有显著提升,但识别准确率有所下降。 α − E I o U α-EIoU α−EIoU在特定场景下能提供更高的检测精度,但整体性能相较 E I o U EIoU EIoU未取得明显改善,这可能源于α参数调优的复杂性及其对不同场景的较高敏感性。 α − Y I o U α-YIoU α−YIoU具有优异的置信度阈值,但精度低于 S I o U SIoU SIoU。值得注意的是, S I o U SIoU SIoU的实施显著提升了模型在遥感影像上的识别能力,其精度较YOLOv5原损失函数提高了1.1%,这印证了改进后损失函数在YOLOv5框架下对遥感数据集检测精度提升的适应性。SIoU达到0.973置信度时实现了完全准确,较基准CIoU取得了实质性突破。
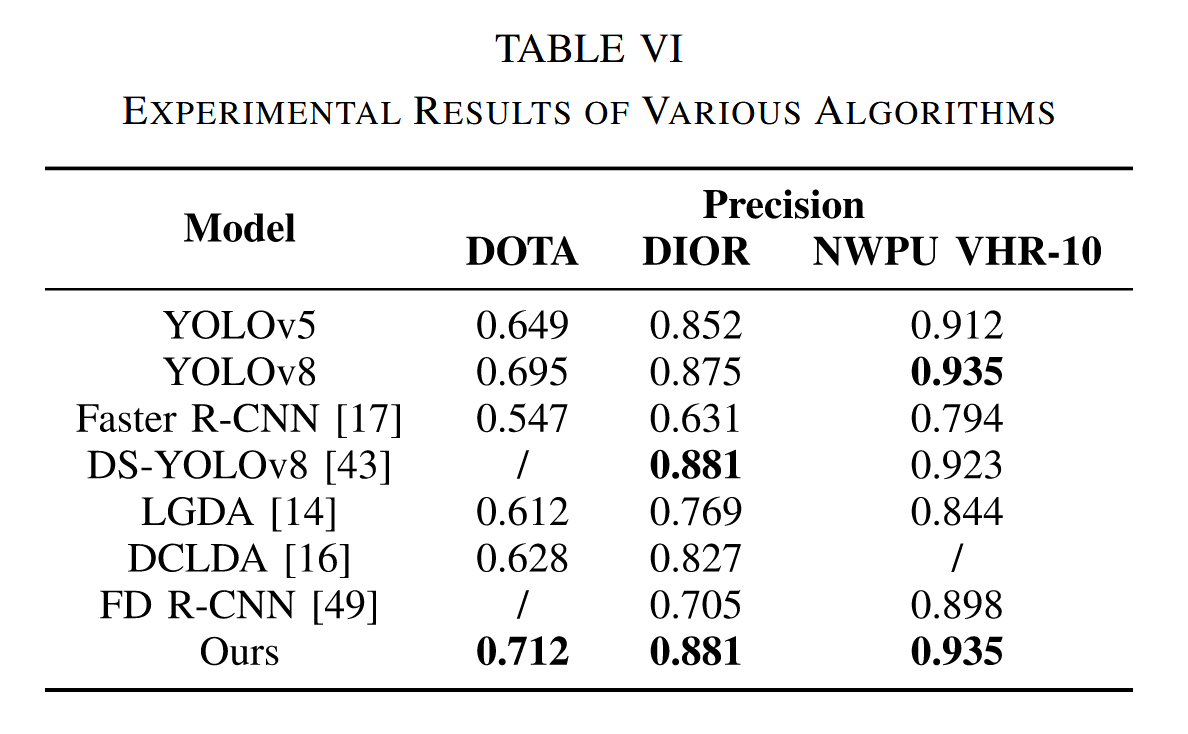
D. 与其他方法的比较
本文进一步分析了五种不同模型(YOLOv5、YOLOv8、Faster R-CNN、DS-YOLOv8[43]和LGDA)在遥感图像识别领域的分类精度,并将其与表VI中我们提出的模型进行对比。实验结果表明,作为最新提出的YOLO模型,YOLOv8在DOTA、DIOR和NWPU VHR-10数据集上表现良好。相比之下,经典的两阶段模型Faster R-CNN分类精度较低,这可能是由于遥感影像数据集存在目标尺度变化大、目标分布不均匀、细节丢失、图像纹理弱等挑战所致。而我们的方法通过引入Transformer机制,能够有效处理遥感图像中的长程依赖关系。与DS-YOLOv8相比,我们的模型在NWPU VHR-10数据集上表现更优,在DIOR数据集上也能达到同等效果。相较于LGDA和DCLDA模型,我们的模型在相应数据集上的识别精度更高,这表明我们的模型具有更强的数据处理和特征提取能力,能够更精准地识别分类目标物体,并具备更好的泛化能力。
在遥感影像中,目标物体往往覆盖广阔区域,传统卷积技术难以有效捕捉长距离空间关联。通过引入基于自注意力机制的CoT模块,模型能够识别这些大范围空间依赖关系,从而显著提升目标定位的召回率与精确度。同时采用的SPD组件增强了模型对遥感影像中目标位置、形态及上下文动态特征的理解能力,使检测精度和鲁棒性均获得实质性提升。在DOTA数据集上的实验表明,本方法较基线模型提升6.3%,较YOLOv8模型提高1.7%,充分验证了其在目标识别方面的优越性。如图13所示,该模型实现了差异化的识别效果可视化呈现。
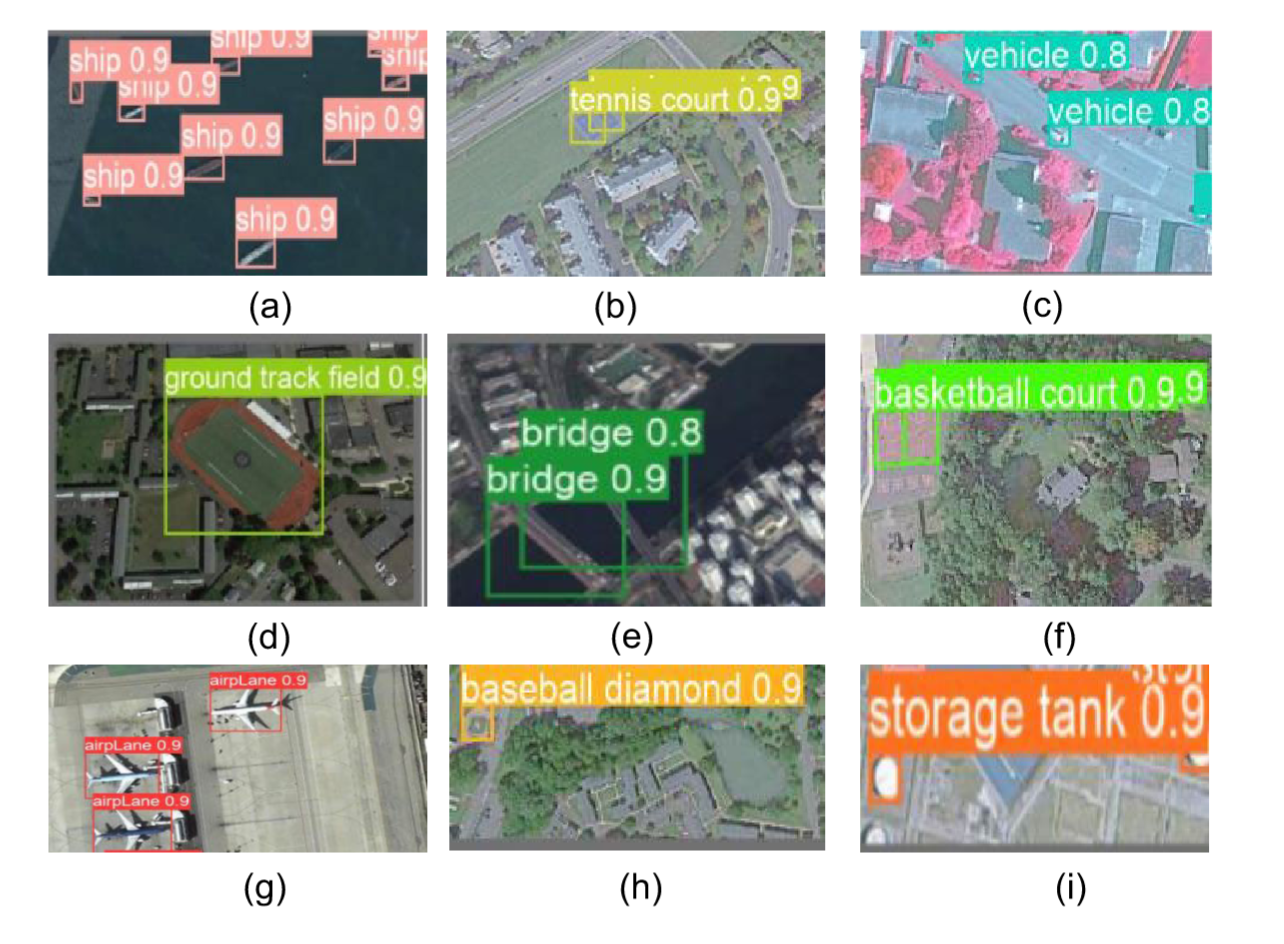
图13. 识别效果图。(a)船舶。(b)输电线路。©车辆。(d)地面实况场。(e)桥梁。(f)建筑物群。(g)飞机。(h)边界。(i)存储塔。
我们展示了上述部分方法在NWPU VHR-10、DOTA和DIOR数据集上的热力图。通过对比分析图14可以看出,本文方法的热力图中目标位置具有更强的显著性,这表明模型能更准确地聚焦并定位小目标。相比之下,其他方法的热力图中目标显著性较弱,红色区域分散或不明显,说明模型在小目标定位方面存在不足。最后一幅图中背景区域(蓝色和绿色部分)响应值较低且目标物体轮廓更为清晰,这表明模型能更准确地识别和描述目标的边缘与形状,在区分目标与背景方面表现更好,受背景干扰较小。而其他方法的热力图中目标轮廓可能出现模糊,说明模型在细节提取方面存在缺陷。

图14. 不同检测模型热力图对比。从上至下各行分别代表NWPU VHR-10、DOTA和DIOR数据集。(a)原图 (b)YOLOv5热力图 ©YOLOv8热力图 (d)DS-YOLOv8热力图 (e)本文方法热力图。
表VII全面评估了我们的模型在NWPU VHR-10、DOTA和DIOR数据集中各类别目标的检测性能。每行对应特定数据集,各列则代表不同目标类型,包括高速公路服务区(EA)、风力发电机(WL)、环岛(RA)、体育场(SM)和游泳池(SW)等类别。模型在这些数据集上表现出的稳定性,尤其在小目标检测方面的优异性能,凸显了其对遥感任务关键需求的适应能力。

在NWPU VHR-10数据集中,我们的模型在清晰定义和具有挑战性的类别中均表现出色,尤其在车辆(VE, 0.940)和小型目标(ST, 0.926)检测上取得了显著成果。这些分数证明了模型在杂乱场景中识别小目标的优势,即使存在常见背景干扰。以复杂城市场景和自然场景著称的DOTA数据集同样展现了模型的优势:能精准检测输电设备(TC, 0.936)等小目标,同时有效处理环岛、桥梁等复杂背景。包含多种光照与天气条件下多样化目标的DIOR数据集中,模型保持了高检测率,特别是风力涡轮(WL, 0.957)和电力设备(EA, 0.951)。这些结果表明,即使目标被多样化的上下文特征包围,模型仍能实现小目标的精准识别。
总体而言,表VII中的各项结果表明,我们模型的独特架构有效解决了多样化遥感场景中小目标检测的常见挑战,使其非常适用于需要在复杂背景下精确识别小目标的应用场景。
5.结论
本研究提出了一种改进的遥感图像识别框架,能够有效解决此类影像中目标对象精准识别的固有难题。具体结论如下。
-
我们对YOLOv5的框架进行了改进,提出了一种新型框架。首先,在原框架中加入了SPD组件,使模型能更好地捕捉遥感图像的球面特征。随后,我们提出新模块CoTC3,将CoT注意力机制融入C3模块,能有效保留细粒度特征并提升图像表征学习能力。最终将CoTC3模块嵌入主干网络,并替换颈部网络中的主要C3模块。这一改进显著增强了模型在不同遥感场景下的鲁棒性和泛化能力,从而全面提升其在各类场景中的综合性能。
-
我们修改了原模型的损失函数,从EIoU、CIoU、α-EIoU和SIoU损失函数中筛选实验。实证测试表明,采用SIoU损失函数时检测精度最高。
-
通过将本文方法与Faster R-CNN、YOLOv5及YOLOv8进行对比,在NWPU VHR-10数据集上本文方法与YOLOv8精度持平,均达到93.5%;但在DOTA和DIOR数据集上,本文方法比YOLOv8分别高出1.7%和0.6%,验证了所提方法的可行性。
-
开展的四轮消融实验表明:单独添加CoT模块时模型精度提升有限,而同时集成CoT模块与SPD组件可带来性能的显著提升。其中车辆和桥梁的检测精度增幅尤为突出,均超过10%。
未来,我们将尝试将本文提出的模型应用于无人机,并对模型及其实际应用进行改进。此外,考虑到实际应用中可能遇到雨雾等极端天气条件,我们计划进一步优化算法以应对这些挑战,从而提升模型的实用性能。
6.引用文献
- [1] H. Bany Salameh, M. Alhafnawi, A. Masadeh, and Y. Jararweh, “Federated reinforcement learning approach for detecting uncertain deceptive target using autonomous dual UAV system,” Inf. Process. Manage., vol. 60, no. 2, Mar. 2023, Art. no. 103149, doi: 10.1016/j.ipm.2022.103149.
- [2] R. Marasinghe, T. Yigitcanlar, S. Mayere, T. Washington, and M. Limb, “Computer vision applications for urban planning: A systematic review of opportunities and constraints,” Sustain. Cities Soc., vol. 100, Jan. 2024, Art. no. 105047.
- [3] E. Corcoran, M. Winsen, A. Sudholz, and G. Hamilton, “Automated detection of wildlife using drones: Synthesis, opportunities and constraints,” Methods Ecol. Evol., vol. 12, no. 6, pp. 1103–1114, Jun. 2021.
- [4] C. P. Papageorgiou, M. Oren, and T. Poggio, “A general framework for object detection,” in Proc. 6th Int. Conf. Comput. Vis., Bombay, India. Los Alamitos, CA, USA: IEEE Computer Society, Jan. 1998, pp. 555–562, doi: 10.1109/ICCV.1998.710772.
- [5] E. Corvee and F. Bremond, “Body parts detection for people tracking using trees of histogram of oriented gradient descriptors,” in Proc. 7th IEEE Int. Conf. Adv. Video Signal Based Surveill., Boston, MA, USA. Los Alamitos, CA, USA: IEEE Computer Society, Aug. 2010, pp. 469–475, doi: 10.1109/AVSS.2010.51.
- [6] Y. Freund and R. E. Schapire, “A decision-theoretic generalization of on-line learning and an application to boosting,” J. Comput. Syst. Sci., vol. 55, no. 1, pp. 119–139, Aug. 1997, doi: 10.1006/jcss. 1997.1504.
- [7] C. Cortes and V. Vapnik, “Support-vector networks,” Mach. Learn., vol. 20, no. 3, pp. 273–297, Sep. 1995, doi: 10.1007/ BF00994018.
- [8] R. Girshick, J. Donahue, T. Darrell, and J. Malik, “Rich feature hierarchies for accurate object detection and semantic segmentation,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Columbus, OH, USA. Los Alamitos, CA, USA: IEEE Computer Society, Jun. 2014, pp. 580–587, doi: 10.1109/CVPR.2014.81.
- [9] R. Girshick, “Fast R-CNN,” in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), Santiago, Chile. Los Alamitos, CA, USA: IEEE Computer Society, Dec. 2015, pp. 1440–1448, doi: 10.1109/ICCV.2015.169.
- [10] J. Zhang, Q. Gao, H. Luo, and T. Long, “Mineral identification based on deep learning using image luminance equalization,” Appl. Sci., vol. 12, no. 14, p. 7055, Jul. 2022.
- [11] W. Liu et al., “SSD: single shot multibox detector,” in Proc. Eur. Conf. Comput. Vis. (ECCV), 2016, pp. 21–37, doi: 10.1007/978-3-319-464480_2.
- [12] L. Zhu, X. Geng, Z. Li, and C. Liu, “Improving YOLOv5 with attention mechanism for detecting boulders from planetary images,” Remote Sens., vol. 13, no. 18, p. 3776, Sep. 2021.
- [13] J. Zhang, Z. Chen, G. Yan, Y. Wang, and B. Hu, “Faster and lightweight: An improved YOLOv5 object detector for remote sensing images,” Remote Sens., vol. 15, no. 20, p. 4974, Oct. 2023.
- [14] D. Biswas and J. Tešic ́, “Domain adaptation with contrastive learning for object detection in satellite imagery,” IEEE Trans. Geosci. Remote Sens., vol. 62, 2024, Art. no. 5620615, doi: 10.1109/TGRS. 2024.3391621.
- [15] D. Konstantinidis, V. Argyriou, T. Stathaki, and N. Grammalidis, “A modular CNN-based building detector for remote sensing images,” Comput. Netw., vol. 168, Feb. 2020, Art. no. 107034, doi: 10.1016/j.comnet.2019.107034.
- [16] D. Biswas and J. Tešic ́, “Unsupervised domain adaptation with debiased contrastive learning and support-set guided pseudolabeling for remote sensing images,” IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens., vol. 17, pp. 3197–3210, 2024, doi: 10.1109/JSTARS. 2024.3349541.
- [17] T. Bai et al., “An optimized faster R-CNN method based on DRNet and RoI align for building detection in remote sensing images,” Remote Sens., vol. 12, no. 5, p. 762, Feb. 2020, doi: 10.3390/rs12050762.
- [18] L. Lang, K. Xu, Q. Zhang, and D. Wang, “Fast and accurate object detection in remote sensing images based on lightweight deep neural network,” Sensors, vol. 21, no. 16, p. 5460, Aug. 2021, doi: 10.3390/s21165460.
- [19] R. Sunkara and T. Luo, “No more strided convolutions or pooling: A new CNN building block for low-resolution images and small objects,” in Machine Learning and Knowledge Discovery in Databases (Lecture Notes in Computer Science), vol. 13715, Grenoble, France, M. Amini, S. Canu, A. Fischer, T. Guns, P. K. Novak, and G. Tsoumakas, Eds. Cham, Switzerland: Springer, Sep. 2022, pp. 443–459, doi: 10.1007/978-3-031-26409-2_27.
- [20] D. Bahdanau, K. Cho, and Y. Bengio, “Neural machine translation by jointly learning to align and translate,” in Proc. 3rd Int. Conf. Learn. Represent. (ICLR), 2015, pp. 1–15.
- [21] P. Li, Y. Zhang, L. Yuan, and X. Xu, “Fully transformer-equipped architecture for end-to-end referring video object segmentation,” Inf. Process. Manage., vol. 61, no. 1, Jan. 2024, Art. no. 103566, doi: 10.1016/j.ipm.2023.103566.
- [22] Q. Gao, T. Long, and Z. Zhou, “Mineral identification based on natural feature-oriented image processing and multi-label image classification,” Expert Syst. Appl., vol. 238, Mar. 2024, Art. no. 122111.
- [23] Y. Zhao, T. Xia, Y. Jiang, and Y. Tian, “Enhancing inter-sentence attention for semantic textual similarity,” Inf. Process. Manage., vol. 61, no. 1, Jan. 2024, Art. no. 103535, doi: 10.1016/j.ipm.2023.103535.
- [24] G. Ren, L. Diao, F. Guo, and T. Hong, “A co-attention based multi-modal fusion network for review helpfulness prediction,” Inf. Process. Manage., vol. 61, no. 1, Jan. 2024, Art. no. 103573, doi: 10.1016/j.ipm.2023.103573.
- [25] Y. Li, T. Yao, Y. Pan, and T. Mei, “Contextual transformer networks for visual recognition,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 45, no. 2, pp. 1489–1500, Feb. 2023, doi: 10.1109/TPAMI. 2022.3164083.
- [26] Enhanced Target Detection: Fusion of SPD and CoTC3 Within YOLOv5 Framework. Accessed: Aug. 19, 2024. [Online]. Available: https://github.com/yucls/CoTC3
- [27] T. Ojala, M. Pietikäinen, and D. Harwood, “Performance evaluation of texture measures with classification based on Kullback discrimination of distributions,” in Proc. 12th Int. Conf. Pattern Recognit., vol. 1, Jerusalem, Israel, Oct. 1994, pp. 582–585, doi: 10.1109/ICPR.1994.576366.
- [28] D. G. Lowe, “Object recognition from local scale-invariant features,” in Proc. 7th IEEE Int. Conf. Comput. Vis., Corfu, Greece. Los Alamitos, CA, USA: IEEE Computer Society, Sep. 1999, pp. 1150–1157, doi: 10.1109/ICCV.1999.790410.
- [29] Y. LeCun et al., “Backpropagation applied to handwritten zip code recognition,” Neural Comput., vol. 1, no. 4, pp. 541–551, Dec. 1989, doi: 10.1162/neco.1989.1.4.541.
- [30] J. L. Elman, “Finding structure in time,” Cogn. Sci., vol. 14, no. 2, pp. 179–211, Mar. 1990, doi: 10.1207/s15516709cog1402_1.
- [31] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, “You only look once: Unified, real-time object detection,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Las Vegas, NV, USA, Jun. 2016, pp. 779–788, doi: 10.1109/CVPR.2016.91.
- [32] H. Park, Y. Yoo, G. Seo, D. Han, S. Yun, and N. Kwak, “C3: Concentrated-comprehensive convolution and its application to semantic segmentation,” 2018, arXiv:1812.04920.
- [33] Y. Huang, X. Wen, Y. Gao, Y. Zhang, and G. Lin, “Tree species classification in UAV remote sensing images based on super-resolution reconstruction and deep learning,” Remote Sens., vol. 15, no. 11, p. 2942, Jun. 2023, doi: 10.3390/rs15112942.
- [34] Y. Cheng et al., “A multi-feature fusion and attention network for multiscale object detection in remote sensing images,” Remote Sens., vol. 15, no. 8, p. 2096, Apr. 2023, doi: 10.3390/rs15082096.
- [35] Z. Tong, Y. Li, J. Zhang, L. He, and Y. Gong, “MSFANet: Multiscale fusion attention network for road segmentation of multispectral remote sensing data,” Remote Sens., vol. 15, no. 8, p. 1978, Apr. 2023, doi: 10.3390/rs15081978.
- [36] F. Hongjian and B. Hongyang, “Object detection method for optical remote sensing images integrating multiple attention mechanisms,” Acta Photon. Sinica, vol. 51, no. 12, 2022, Art. no. 1210003.
- [37] D. Biswas, M. M. M. Rahman, Z. Zong, and J. Tesic, “Improving the energy efficiency of real-time DNN object detection via compression, transfer learning, and scale prediction,” in Proc. IEEE Int. Conf. Netw., Archit. Storage (NAS), Philadelphia, PA, USA, Oct. 2022, pp. 1–8, doi: 10.1109/NAS55553.2022.9925528.
- [38] K. He, X. Zhang, S. Ren, and J. Sun, “Spatial pyramid pooling in deep convolutional networks for visual recognition,” in Proc. 13th Eur. Conf. Comput. Vis. (ECCV), in Lecture Notes in Computer Science, vol. 8691, Zürich, Switzerland, D. J. Fleet, T. Pajdla, B. Schiele, and T. Tuytelaars, Eds. Springer, 2014, pp. 346–361, doi: 10.1007/ 978-3-319-10578-9_23.
- [39] E. H. Adelson, C. H. Anderson, J. R. Bergen, P. J. Burt, and J. M. Ogden, “Pyramid methods in image processing,” RCA Eng., vol. 29, no. 6, pp. 33–41, 1984.
- [40] G.-S. Xia et al., “DOTA: A large-scale dataset for object detection in aerial images,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Salt Lake City, UT, USA. Los Alamitos, CA, USA: IEEE Computer Society, Jun. 2018, pp. 3974–3983.
- [41] K. Li, G. Wan, G. Cheng, L. Meng, and J. Han, “Object detection in optical remote sensing images: A survey and A new benchmark,” ISPRS J. Photogramm. Remote Sens., vol. 159, pp. 296–307, Jan. 2020.
- [42] G. Cheng, P. Zhou, and J. Han, “Learning rotation-invariant convolutional neural networks for object detection in VHR optical remote sensing images,” IEEE Trans. Geosci. Remote Sens., vol. 54, no. 12, pp. 7405–7415, Dec. 2016, doi: 10.1109/TGRS.2016.2601622.
- [43] L. Shen, B. Lang, and Z. Song, “DS-YOLOv8-based object detection method for remote sensing images,” IEEE Access, vol. 11, pp. 125122–125137, 2023, doi: 10.1109/ACCESS.2023.3330844.
- [44] J. Yu, Y. Jiang, Z. Wang, Z. Cao, and T. Huang, “UnitBox: An advanced object detection network,” in Proc. 24th ACM Int. Conf. Multimedia, Amsterdam, The Netherlands, A. Hanjalic et al., Eds., Oct. 2016, pp. 516–520, doi: 10.1145/2964284.2967274.
- [45] Z. Gevorgyan, “SIoU loss: More powerful learning for bounding box regression,” ArXiv, vol. abs/2205.12740, 2022.
- [46] Y.-F. Zhang, W. Ren, Z. Zhang, Z. Jia, L. Wang, and T. Tan, “Focal and efficient IOU loss for accurate bounding box regression,” Neurocomputing, vol. 506, pp. 146–157, Sep. 2022, doi: 10.1016/j.neucom.2022.07.042.
- [47] Z. Zheng, P. Wang, W. Liu, J. Li, R. Ye, and D. Ren, “Distance-IoU loss: Faster and better learning for bounding box regression,” in Proc. 44th AAAI Conf. Artif. Intell. (AAAI), 32nd Innov. Appl. Artif. Intell. Conf. (IAAI), 10th AAAI Symp. Educ. Adv. Artif. Intell. (EAAI), New York, NY, USA. Palo Alto, CA, USA: AAAI Press, Apr. 2020, pp. 12993–13000, doi: 10.1609/aaai.v34i07.6999.
- [48] J. He, S. M. Erfani, X. Ma, J. Bailey, Y. Chi, and X. Hua, “α-IoU: A family of power intersection over union losses for bounding box regression,” in Proc. Adv. Neural Inf. Process. Syst., Annu. Conf. Neural Inf. Process. Syst., vol. 34, M. Ranzato, A. Beygelzimer, Y. N. Dauphin, P. Liang, and J. W. Vaughan, Eds., Dec. 2021, pp. 20230–20242. [Online]. Available: https://proceedings.neurips.cc/paper/2021/hash/a8f1 5eda80c50adb0e71943adc8015cf-Abstract.html
- [49] Z. Hu and C. Wang, “Improved faster R-CNN algorithm for small target detection in remote sensing images,” Comput. Eng. Sci., vol. 46, pp. 1063–1071, Jun. 2024.



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











