







摘要
这篇文章建立在基于分割驱动的6D姿态估计论文,论文中参考文献[13]就是这篇论文,实际上这两篇论文是一个实验室的工作,本篇论文也是在解决[13]结论中作者提出的问题。
最新的 6D 姿态估计框架首先依赖深度网络来建立 3D 对象关键点和 2D 图像位置之间的对应关系,然后使用基于 RANSAC 的 Perspective-n-Point (PnP) 算法的变体。 然而,这个两阶段的过程不是最理想的:首先,它不是端到端的可训练的。 其次,训练深度网络依赖于不直接反映最终 6D 姿态估计任务的代理损失。
在这项工作中,我们引入了一种深度架构,可以直接从对应关系中回归 6D 姿势。 它将每个3D关键点的一组候选对应关系作为输入,并说明每个组内对应关系的顺序无关紧要,而组的顺序,即3D关键点的顺序是固定的。 我们的架构是通用的,因此可以与现有的对应提取网络结合使用,从而产生单阶段 6D 姿势估计框架。 我们的实验表明,这些单阶段框架在准确性和速度方面始终优于两阶段框架。
1.Introduction
两阶段的6D问题存在三个缺点。
- 用于训练深度网络的损失函数并不反映姿态估计的真实目标,而是编码了一个替代任务,例如最小化检测到的图像投影的 2D 误差。 然而,这些误差与姿势精度之间的关系并不是一对一的。 如图 1 (a) 所示,对于最新框架,具有相同平均 2D 误差的两组对应关系可能会导致不同的姿态估计。
我总结一下:现阶段大多数基于2D投影点预测的网络的优化目标是减小预测点位置和真实点位置的平均误差,因此,即使是同一个优化目标值,也可能得到两个不同的预测结果。 - 两阶段过程不是端到端可训练的。
- 当需要处理许多对应关系时,迭代的 RANSAC 非常耗时。

图1
2.Related Work
这些方法的共同点是,对应关系是相互独立建立的,并且一致性只是在事实之后由不属于深度网络的 RANSAC PnP 算法强加。 如[53]所示,尽管在不同的上下文中,这未能利用所有对应关系都受相机姿势约束并且因此彼此不独立的事实。
我们在本文中的目标是通过将过程中基于 RANSAC 的 PnP 部分实现为可以与建立对应关系的深度网络相结合的深度网络,从而将上述两阶段过程转变为单阶段过程。 这不是一个小问题,因为 PnP 的标准方法涉及执行奇异值分解 (SVD),它可以嵌入到深度网络中,但通常会导致数值不稳定。 在 [5] 中,通过避免显式使用 SVD 而是通过直接线性变换 (DLT) 方法 [9] 将 PnP 视为最小二乘拟合问题来解决这个问题。 然而,这并不能保证结果描述了真正的旋转,仍然需要进一步的后处理。
相比之下,[49] 的反向传播友好的特征分解方法执行显式 SVD,并且原则上可以用于执行 PnP。 但是,这样做将无法考虑算法的 RANSAC 部分来选择正确的对应关系。 虽然 RANSAC 可以通过深度网络 [1, 2] 实现,但其较差的可重复性(如图 1(b)所示)使其不适合训练端到端 6D 姿态估计网络。 简而言之,目前还没有人提出令人满意的解决方案来设计单级 6D 姿态估计网络,这也是我们在此解决的问题。
我们的架构受到 PointNet [37, 38] 的启发。 然而,PointNet 旨在为刚性转换提供不变性,这与我们所需要的相反。 此外,我们引入了一种分组特征聚合方案来有效地处理 6D 对象姿态估计中的对应聚类。
3.Approach
给定一个RGB图像由一个标定的摄像机捕获,我们的目标是同时检测物体并估计其6D姿态。 我们假设它们是刚性的,它们的三维模型是可用的。 在这一节中,我们首先形式化了6D姿态估计问题,假设目标物体上的每个3D关键点都有一组先验的2D对应,并提出了一个从这些输入产生6D姿态的网络结构。 该网络由图3所示。 然后,我们讨论了当这些对应是另一个网络的输出时,如何获得一个单级6D位姿估计框架。
3.1 6D Pose from Correspondence Clusters
共有n个3D关键点,每个3D关键点有m个可能的correspondences。
λ
i
k
[
u
i
k
1
]
=
K
(
R
p
i
+
t
)
(
1
)
\lambda_{ik}\begin{bmatrix} u_{ik}\\ 1 \\ \end{bmatrix}=K(Rp_{i}+t) \ (1)
λik[uik1]=K(Rpi+t) (1)
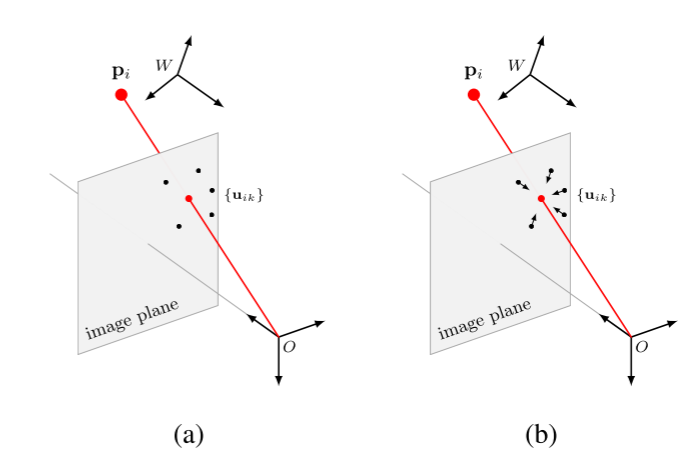
图2
经典的PNP方法[21,7,46]试图在给定几个对应关系的情况下恢复R和T,这通常涉及到使用RANSAC来寻找有效的对应关系。 在这个过程中,必须对许多随机选择的对应子集进行奇异值分解,在找到一个只包含有效对应集之前,必须尝试这些子集。
在这项工作中,我们提出用一个适当设计的具有参数θ的深度网络G来实现非线性回归来代替这个繁琐的过程。
(
R
,
t
)
=
g
(
{
(
p
i
↔
u
i
k
)
}
1
≤
i
≤
n
,
1
≤
k
≤
m
;
θ
)
(
2
)
(R,t)=g(\left\{ (p_{i}\leftrightarrow u_{ik})\right\}_{1\leq i\leq n,1\leq k\leq m};\theta ) \ (2)
(R,t)=g({(pi↔uik)}1≤i≤n,1≤k≤m;θ) (2)
我们现在来看 g θ g_{\theta} gθ的实际实现,在本节的其余部分我们首先讨论网络作为输入的3D到2D对应集合 C 2 3 = { ( p i ↔ u i k ) } i ≤ i ≤ n , 1 ≤ k ≤ m C^{3}_{2}=\left\{ (p_{i}\leftrightarrow u_{ik})\right\}_{i\leq i\leq n,1\leq k\leq m} C23={(pi↔uik)}i≤i≤n,1≤k≤m然后讨论 我们设计的架构来解释它们。
3.1.1 Properties of the Correspondence Set
我们将与特定3D点相关联的所有2D点称为一个聚类,因为假设用于寻找它们的算法是一个好的算法,它们倾向于围绕3D点投影的真实位置聚类,如图1所示。 我们的实施选择是由以下考虑因素驱动的:
- 聚类排序。簇内的对应顺序无关紧要,不应影响结果。 但是,簇的顺序对应于 3D 点的顺序,这是给定的和固定的。
- 簇内与跨簇群交互。虽然同一簇中的点对应于同一3D点,但每个点的2D位置估计应该是有噪声的。 因此,该模型需要捕捉每个簇内的噪声分布。 更重要的是,单个聚类不能告诉我们关于姿态的信息,最终的姿态只能通过捕获多个聚类的全局结构来推断。
- 刚性转换很重要。当用深度网络处理三维点云时,通常希望结果对刚性变换不变。 相反,在这里,我们希望我们的2D点表示三维点的投影,我们从它们中提取的特征应该依赖于它们的绝对位置,这是姿态估计的关键。
3.1.2 网络结构
我们构建了一个简单的网络体系结构,如图3所示。 利用上面讨论的性质从对应簇中预测姿态。 它包括三个主要模块:具有共享网络参数的局部特征提取模块、单个簇内的特征聚集模块和由简单的全连通层构成的全局推理模块。
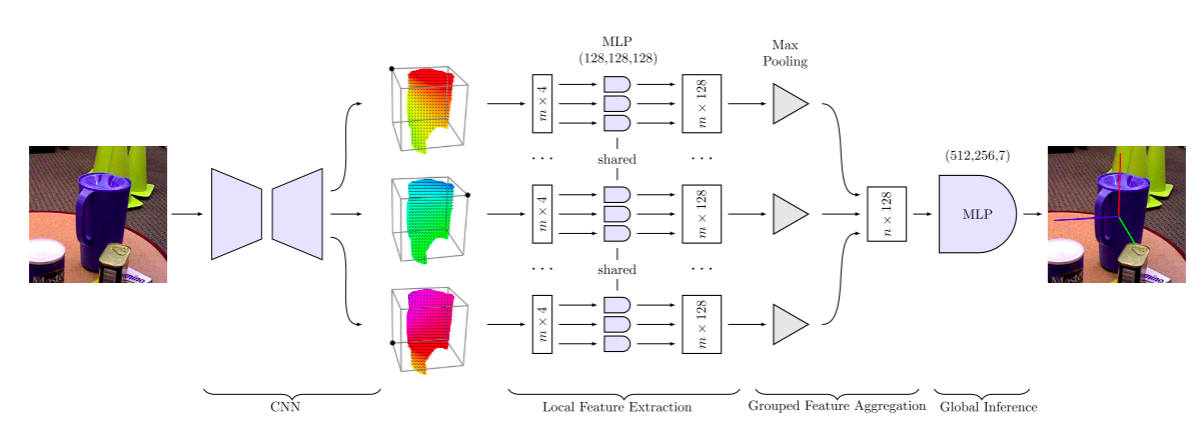
图3
- 局部特征提取。 主要解决性质2,通过单个对应的三层MLP实现簇间的交互,不同对应之间的权重是共享的,这实现了跨簇间的交互。
- 分组特征聚合。由于聚类的顺序是给定的,但每个聚类内的点是无顺序的,为了提取每个聚类的表示,我们设计了一种对对应顺序不敏感的分组特征聚合方法。 理论上,我们可以使用类似于PointNet的体系结构 。然而,PointNet的设计是为刚性转换提供不变性,这与我们需要的相反。 相反,给定 n n n个簇,每个包含m个2D关键点 { u i k } , 1 ≤ i ≤ n , 1 ≤ k ≤ m \left\{u_{ik} \right\},1\leq i\leq n,1 \leq k \leq m {uik},1≤i≤n,1≤k≤m,我们定义了一个集合函数
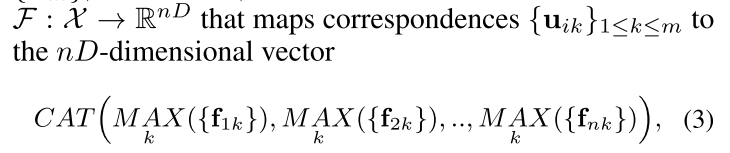
f
i
k
f_{ik}
fik是通过上述全连接层获得的
u
i
k
u_{ik}
uik的D维度特征表示。MAX()最大池化操作,CAT()合并操作。
在我们的实验中,我们发现实例规一化和批规一化都没有提高这里的性能。 因此,我们在我们的网络
g
θ
g_{\theta}
gθ中不使用这些操作。
原则上,可以使用单个最大池操作,而不考虑群的顺序,就像PointNet[37]所做的那样,实现所有点的置换不变性。 然而,在我们的例子中,这将意味着忽略组的顺序是固定的这一属性。 相比之下,等式3对簇内的任何排列都是不变的,但仍然说明预定义的簇顺序。 我们将在结果部分演示这种方法的好处。
总结一下这里Max处理顺序不变,所以针对于k找最大,因为对应内部的2D点顺序无所谓,所以将Max作用于k,而有许多个簇,这些簇间的顺序是无所谓的,所以直接合并。
- 全局推理。然后,我们将聚集群体特征的ND维向量传递给另一个MLP,该MLP输出6D姿态。 为此,我们使用三个完全连通层,并将最终姿态编码为四元数和平移。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









