







Abstract
1.解决的问题
对未见的对象实例进行6D姿态估计,不依赖于精准的CAD模型。
2.贡献
- 提出了归一化对象坐标空间 (NOCS)。
- 基于Mask-RCNN设计网络,它联合预测 RGB 图像中多个看不见的对象的类标签、实例掩码和 NOCS 映射。
- 一种空间上下文感知混合现实技术(CAMERA),合成数据集。
3.结果
大量实验表明,所提出的方法能够稳健地估计真实环境中未见对象实例的姿态和大小,同时在标准 6D 姿态估计基准上实现最先进的性能。
代码:https://github.com/hughw19/NOCS_CVPR2019
Introduction
(1).第一个挑战是找到一种表示法,允许为特定类别中的不同对象定义6D姿势和大小,直观的解释,如果没有CAD model你就无法定义物体的正面反面等,你不知道它的正面反面是什么,所以需要一种对于没见过物体的表示方法。
(2). 第二个挑战是无法获得用于训练和测试的大规模数据集。
Background and Overview
1.Category-Level 6D Object Pose and Size Estimation
我们重点研究对象实例的3个旋转、3个平移和3个缩放参数(维度)的估计问题。这个问题的解决方案可以可视化为对象周围的一个紧密定向的边界框(见图1)。
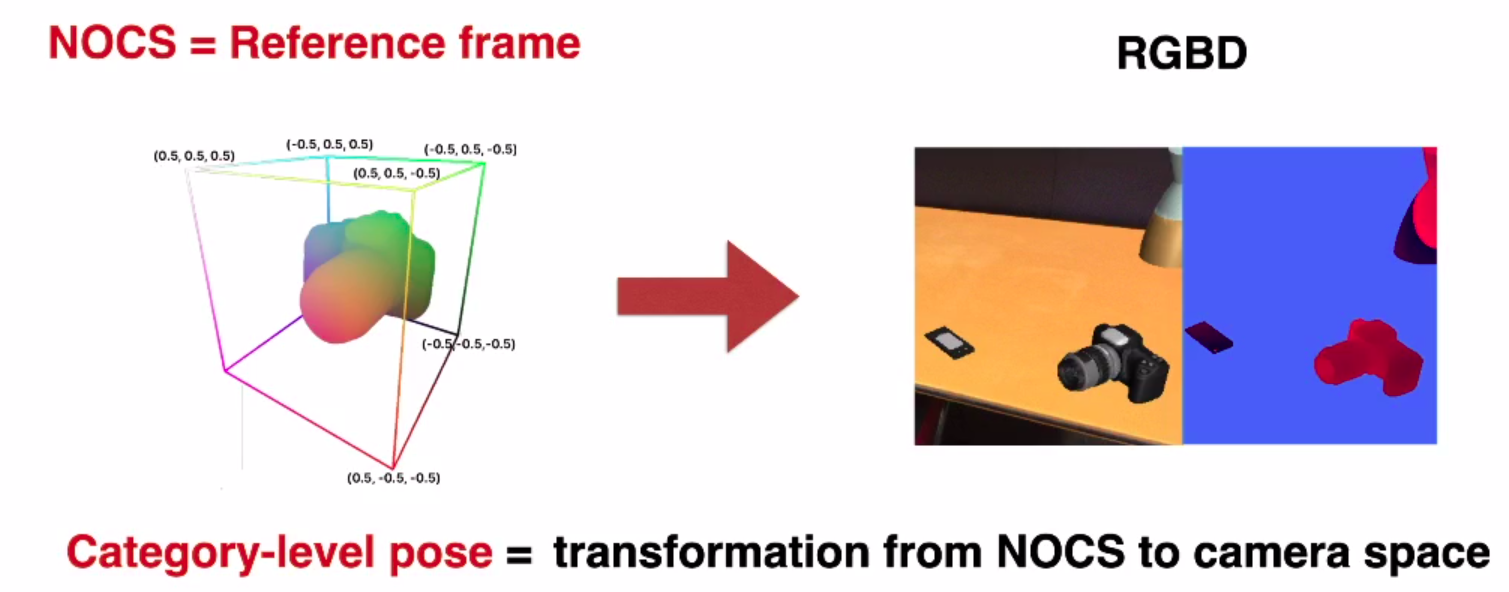
虽然以前没有观察到,但这些对象来自已知的对象类别(例如,相机),在训练期间已经观察到了这些对象的训练样本。此任务特别具有挑战性,因为我们不能在测试时使用CAD模型,并且6D姿势对于看不见的对象没有很好的定义。为了克服这个问题,我们提出了一种新的表示,它定义了一个共享对象空间,可以为看不见的对象定义 6D 姿势和大小。

图1
解释一下图1,(a)表示输入的RGB图片和深度图,(b)颜色编码的归一化对象坐标空间(NOCS)表示,NOCS允许我们在类级别一致的定义6D姿态,( c )表示获得了完整的6D姿态(三色坐标轴表示)和尺寸(红框表示)
2.Normalized Object Coordinate Space (NOCS)
NOCS被定义为包含在单元立方体中的3D空间, { x , y , z } ∈ [ 0 , 1 ] \left\{ x,y,z \right\}\in \left [ 0,1 \right ] {x,y,z}∈[0,1],给定每个类别的已知对象CAD模型的形状集合,我们通过均匀缩放对象来归一化它们的大小,以便其紧边界框的对角线长度为1,并在NOCS空间内居中 (见图2)。此外,我们在同一类别中一致地对齐对象中心和方向。
总结一下这个步骤:
(1).Step 1: 旋转归一化,也就是物体方向的对齐。

(2).Step 2: 平移归一化,就是将物体的紧包围盒的中心放到(0.5,0.5,0.5)的位置。
(3).Step 3: 尺度归一化,将紧密包围盒对角线缩放为1
此外,我们在同一类别中一致地对齐对象中心和方向。我们使用ShapeNetCore 中的模型,这些模型已经针对比例,位置和方向进行了规范化。图2显示了相机类别中的规范化形状的示例。我们的表示允许将形状的每个顶点表示为NOCS(图2中的颜色编码)内的元组(x,y,z)。
我们的CNN预测了用颜色编码的NOCS坐标的2D透视投影,即NOCS Map(图2左下角)。有多种方式来解释NOCS图:(1)作为NOCS中观察到的物体部分的形状重建,或 (2)作为密集的像素-NOCS对应。(还是逐像素预测)我们的CNN学习对不可见对象的形状预测进行泛化,或者在对大型形状集合进行训练时学习预测对象像素-NOCS的对应关系。 这种表示方法比其他方法(例如,边界框)更稳健,因为即使在对象仅部分可见的情况下,我们也可以进行操作。
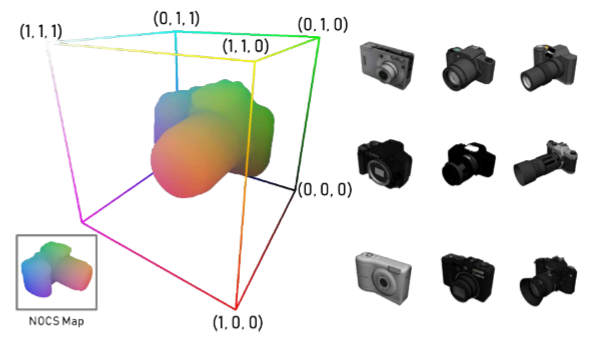
图2
3.Method Overview
在Instance_level中如果直接回归R,t我们是预测物体坐标系相对于相机坐标系的变换,在Category-level下也是一样的,只不过这里的物体坐标系是归一化的物体坐标系(NOCS),如下图。
具体的过程如下图,使用建立在Mask-RCNN框架下CNN预测类标签和实例掩码,以及逐像素预测NOCS map上的三维坐标,之后将NOCS转换成点云,注意在CNN中我们不使用深度图,因为我们想利用现有的RGB数据集,如COCO,其中不包含深度,以提高性能,这里相当于一个弱监督的过程。
然后我们使用深度图结合相机内参进行Backproject,得到相机坐标系下的点云,这变成了一个3D-3D的问题,并使用Umeyama algorithm、鲁棒的离群值去除和对齐技术来预测完整的度量6D对象的姿势和大小。具体的实现方法我在代码文章中说明。
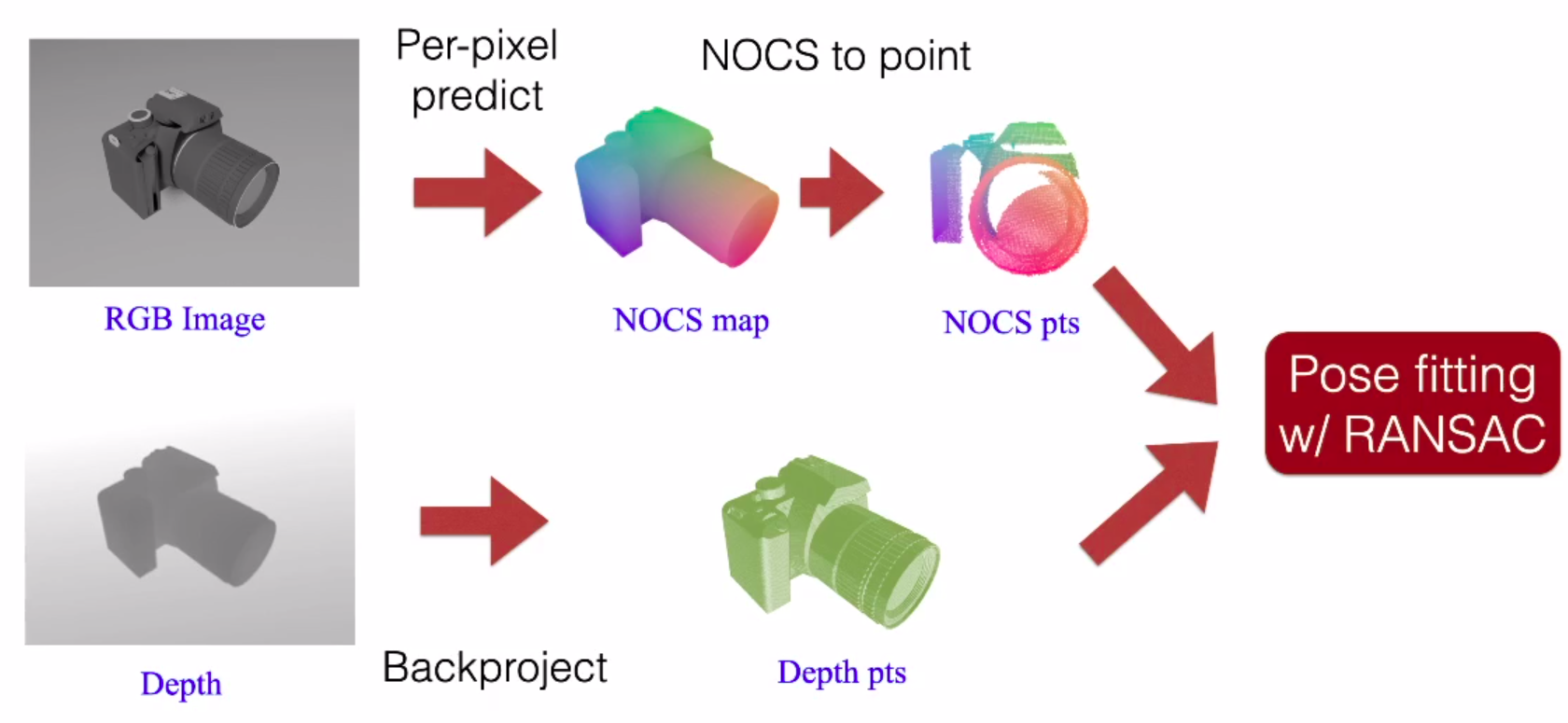
我们的 CNN 建立在 Mask R-CNN 框架 之上,除了类标签和实例掩码之外,还改进了联合预测 NOCS Map。Method部分包含有关我们的改进和可以处理对称对象的新损失函数的更多细节。在训练期间,我们使用通过新的 Context-Aware MixEd ReAlity (CAMERA) 方法渲染的地面实况图像(参见Datasets节)。这个大型数据集使我们能够在测试时从新类别中泛化到新实例。为了进一步弥合领域差距,我们还使用了一个较小的真实世界数据集。

图3
4.Datasets
类别级 3D 检测和 6D 姿势和尺寸估计的一个主要挑战是真实数据的不可用。虽然已经进行了几次尝试,如 NYU v2 和 SUNRGB-D ,但它们有很大的局限性。首先,它们不提供对象的 6D 姿势,只关注 3D 边界框。其次,增强现实和机器人等应用程序受益于桌面设置中的手动缩放对象,而当前数据集中缺少这些对象,这些数据集中专注于较大的对象,例如椅子和桌子。最后,这些数据集不包含我们需要的真实标签类型的标注(即 NOCS Map),并且包含有限数量的示例。
4.1.Context-Aware Mixed Reality Approach(上下文感知混合现实方法)
为了便于手尺度物体生成大量具有地面真实信息的训练数据,我们提出了一种新的上下文感知混合现实(CAMERA) 方法,该方法克服了以往方法的局限性,使数据生成的耗时更少,成本更高。它以上下文感知的方式将真实背景图像与合成渲染的前景对象相结合,即,合成对象被渲染并合成到具有合理的物理位置、照明和比例的真实场景中(参见图4)。这种混合现实的方法使我们能够生成比以前可用的更大数量的训练数据。
-
Real Scenes: 我们使用 31 个变化很大的室内场景的真实 RGB-D 图像作为背景(图4中间)。我们的重点是桌面场景,因为大多数以人为中心的室内空间都由带有手尺度物体的桌面组成。我们总共为 31 个场景收集了 553 张图像,其中 4 个留作验证。
-
Synthetic Objects: 为了在上面的真实场景中渲染看起来逼真的对象,我们从ShapeNetCore中选取了手动比例的对象,手动删除了任何看起来不真实或有拓扑问题的对象。我们总共挑选了6类物品–瓶子、碗、相机、罐子、笔记本电脑和马克杯。我们还创建了一个干扰项类别,由上面未列出的类别(如显示器、电话和吉他)中的对象实例组成。这提高了对我们的主要类别进行预测时的稳健性,即使场景中存在其他对象。我们精选的ShapeNetCore版本由1085个单独的对象实例组成,我们留出184个实例进行验证。
-
Context-Aware Compositing:为了提高真实感,我们以上下文感知的方式合成虚拟对象,即,我们将虚拟对象放置在它们自然出现的地方(例如,在支持表面上),并使用合理的照明。我们使用平面检测算法在真实图像中获得像素级的平面分割。随后,我们在分段平面上随机采样可以放置合成对象的位置和方向。然后我们放置几个虚拟光源来模拟真实的室内照明条件。最后,我们将渲染的图像和真实的图像结合在一起,生成一个具有完美地面真实NOCS地图、遮罩和类别标签的逼真合成。
我们总共渲染了300K合成图像,其中25K留出用于验证。据我们所知,这是用于类别级6D姿势和大小估计的最大数据集。我们的混合现实合成技术是使用Unity游戏引擎实现的,它带有用于平面检测和点采样的定制插件(所有这些插件都将公开发布)。与使用非上下文感知数据相比,使用我们的方法生成的图像看起来可信且逼真,从而提高了泛化能力。

图4
图四说明:我们使用上下文感知混合现实 (CAMERA) 方法通过组合桌面场景的真实图像、检测平面并将合成对象渲染到平面上来生成数据(左)。由于对象是合成的,我们获得了类标签、实例掩码、NOCS map以及 6D 姿势和大小的准确真实标签。 我们的方法快速、经济高效,并且可以生成逼真且合理的图像(中)。我们还收集了用于训练、测试和验证的真实数据集(右图)。
4.2.Real-World Data
为了进一步提高和验证我们的算法在具有挑战性的杂波和光照条件下的真实世界性能,我们捕获了两个真实世界数据集:(1)真实世界训练数据集,它补充了我们之前生成的混合现实数据;(2)真实世界测试数据集,用于评估6D姿势和大小估计的性能。我们开发了一种半自动的方法来标注地面真实物体的姿势和大小。图4显示了我们的真实数据示例。
我们使用结构传感器捕获了18个不同真实场景(7个用于训练,5个用于验证,6个用于测试)的8K RGB-D帧(4300帧用于训练,950帧用于验证,2750帧用于测试)。对于每个训练和测试子集,我们使用了6个类别和每个类别3个唯一的实例。对于验证集,我们使用6个类别,每个类别有一个唯一的实例。我们在每个场景中放置5个以上的对象实例来模拟现实世界中的杂乱。对于每个实例,我们使用为此目的开发的RGB-D重建算法获得了干净而准确的3D网格。总体而言,我们的组合数据集包含18个不同的真实场景,42个独特的对象实例,跨越6个类别,使其成为类别级别6D姿势和大小估计的最全面的数据集。
5.Method
图 3 显示了我们从 RGB-D 图像中对多个以前看不见的对象进行 6D 姿势和大小估计的方法。 CNN 预测对象的类标签、掩码和 NOCS 映射。然后我们使用 NOCS 图和深度图来估计度量 6D 姿势和对象的大小。
5.1.NOCS Map Prediction CNN
我们的 CNN 的目标是纯粹基于 RGB 图像估计对象的类标签、实例掩码和 NOCS 映射。 我们建立在基于区域的 Mask R-CNN 框架 的基础上,因为它在 2D 对象检测和实例分割任务上展示了最先进的性能,是模块化和灵活的、快速的,并且可以很容易地扩展以预测 NOCS map如下所述。
5.1.1NOCS Map Head
Mask R-CNN 建立在 Faster R-CNN 架构的基础上,由两个模块组成——一个用于提出可能包含对象的区域的模块,以及一个用于检测和分类区域内对象的检测器。此外,它还预测区域内对象的实例掩码。
我们的主要贡献是增加了3个头部结构,用于预测NOCS map的x,y,z分量 (见图5)。与mask head类似,我们在测试时使用object category先于查找相应的预测通道。在训练过程中,损失函数中只使用来自真实对象类别的NOCS map分量。我们使用ResNet50主干和特征金字塔网络(FPN)。

图5
图5是NOCS Map的头部结构。我们在Mask R-CNN结构的基础上添加了额外的头结构用以预测NOCS Map下的x,y,z坐标分量。这些头要么直接用于像素回归,要么直接用于分类。我们使用ReLU激活函数和3x3卷积层。
-
Regression vs. Classification
为了预测 NOCS map,我们可以回归每个像素值,也可以通过离散化像素值将其视为分类问题(在图 5 中由 (B) 表示)。 直接回归可能是一项更难的任务,可能会在训练期间引入不稳定性。 类似地,具有大量类(例如,B = 128、256)的像素分类可能会引入更多参数,从而使训练比直接回归更具挑战性。 我们的实验表明,B = 32 的像素分类比直接回归表现更好。 -
Loss Function
我们网络的类、框和掩码头使用与Mask R-CNN中所述相同的损失函数。对于NOCS Map Head,我们使用两个损失函数: 用于分类的标准softmax损失函数,以及用于回归的以下L1损失函数,这使学习更加鲁棒。
L ( y , y ∗ ) = 1 n { 5 ( y − y ∗ ) 2 , ∣ y − y ∗ ∣ ≤ 1 ∣ y − y ∗ − 0.05 ∣ , ∣ y − y ∗ ∣ > 1 , ∀ y ∈ N , y ∗ ∈ N p L(y,y^{*})=\frac{1}{n}\left\{\begin{matrix} 5(y-y^{*})^{2}, \ \ \begin{vmatrix} y-y^{*}\end{vmatrix}\leq 1 \\ \left|y-y^{*}-0.05 \right| \ ,\left| y-y^{*}\right|> 1\\ \end{matrix}\right.,\forall y \in N,y^{*} \in N_{p} L(y,y∗)=n1{5(y−y∗)2, ∣∣y−y∗∣∣≤1∣y−y∗−0.05∣ ,∣y−y∗∣>1,∀y∈N,y∗∈Np
其中, y ∈ R 3 y \in R^{3} y∈R3是真实标签NOCS Map的像素值, y ∗ y^{*} y∗是预测的NOCS Map像素值,n是ROI内掩码像素的数量, I I I和 I p I_{p} Ip是真实和预测的NOCS maps。
-
对称物体
许多常见的家用物品 (例如瓶子) 绕轴对称。我们的NOCS表示形式没有考虑对称性,这会导致某些对象类出现较大错误。为了缓解此问题,我们引入了将对称性考虑在内损失函数的一种变体。对于我们训练数据中的每个类别,我们定义一个对称轴。围绕此轴的预定义旋转会导致产生相同损失函数值的NOCS映射。例如,具有正方形顶部的长方体有一个垂直对称轴,在此轴上旋转角度 θ = { 0 ∘ , 9 0 ∘ , 18 0 ∘ , 27 0 ∘ } \theta =\left\{ 0^{\circ},90^{\circ},180^{\circ},270^{\circ} \right\} θ={0∘,90∘,180∘,270∘}导致相同的NOCS映射,因此具有相同的损失。对于非对称的物体, θ = 0 ∘ \theta = 0^{\circ} θ=0∘是唯一的。我们发现 ∣ θ ∣ ≤ 6 |\theta| \leq 6 ∣θ∣≤6足以处理大多数对称类别。我们生成沿对称轴旋转 ∣ θ ∣ |\theta| ∣θ∣次的真实NOCS Map映射标签 { y 1 ~ , . . . , y ∣ θ ∣ ~ } \left\{\tilde{y_{1}},...,\tilde{y_{|\theta|}} \right\} {y1~,...,y∣θ∣~}。然后我们定义对称的损失函数 L s L_{s} Ls, L s = m i n i = 1 , . . . , ∣ θ ∣ L ( y i ~ , y ∗ ) L_{s}=min_{i=1,...,|\theta|}L(\tilde{y_{i}},y^{*}) Ls=mini=1,...,∣θ∣L(yi~,y∗), y ∗ y^{*} y∗表示预测的NOCS映射像素(x,y,z)。 -
训练策略
我们使用在COCO数据集上的2D实例分割任务上训练的权重初始化ResNet50骨干网、RPN和FPN。对于所有头,我们使用 Delving deep into
rectifiers: Surpassing human-level performance on imagenet
classification中提出的初始化技术。我们使用batch_size= 2 ,0.001 的初始学习率,以及动量为 0.9 和 1×10−4 权重衰减的 SGD 优化器。在训练的第一阶段,我们冻结了 ResNet50 权重,只训练头部中的层,RPN 和 FPN 进行 10K 次迭代。在第二阶段,我们将 ResNet50 层冻结在第 4 级以下并训练 3K 次迭代。在最后阶段,我们将 ResNet50 层冻结在第 3 级以下,再进行 70K 次迭代。当切换到每个阶段时,我们将学习率降低 10 倍。
5.2 6D姿态与尺寸估计
我们的目标是通过使用NOCS map和输入深度图来估计检测到的对象的完整度量6D姿势和尺寸。为此,我们使用rgb-d相机内参和外参将深度图像与彩色图像对齐。然后,我们应用预测的对象掩码来获得检测到的对象的3D点云 P m P_{m} Pm。我们还使用NOCS地图来获得 P n P_{n} Pn的3D表示。然后,我们估计将Pn转换为Pm的比例,旋转和平移。对于这个7维刚性变换估计问题,我们使用Umeyama算法 [45],使用RANSAC [15] 进行离群值去除。定性结果请见补充材料。
6.Experiments and Results
- 评价指标:我们报告了 3D 对象检测和 6D 姿势估计指标的结果。为了评估3D检测和对象尺寸估计,我们使用阈值为50%的并集交集 (IOU) 度量。对于6D位姿估计,我们报告了平移误差小于m cm,旋转误差小于n°的对象实例的平均精度。我们将目标检测与6D姿势评估分离,因为它提供了更清晰的性能图像。我们设置了预测和真实之间10% 的包围框重叠的检测阈值,以确保大多数对象都被包括在评估中。对于对称的对象类别(瓶子、碗和罐子),我们允许预测的3D边界框绕对象的垂直轴自由旋转,而不会受到惩罚。我们对马克杯类别执行特殊处理,当手柄不可见时使其对称,因为在这种情况下很难判断其姿势,即使是对人类来说也是如此。我们使用来检测相机数据的句柄可见性,并手动为真实数据进行注释。
- 基线:没有NOCS Map 的Mask R-CNN,使用预测的实例掩码从深度图中获得物体的三维点云。我们将掩码点云与从相应类别中随机选择的一个模型对齐(使用 ICP)。
- 评估数据集:(1)CAMERA25 (2)REAL275
6.1Category-Level 6D Pose and Size Estimation
- Test on CAMERA25:
mAP 3D IOU 50%: 83.9%
mAP 5 ∘ 5^{\circ} 5∘,5cm: 40.9%
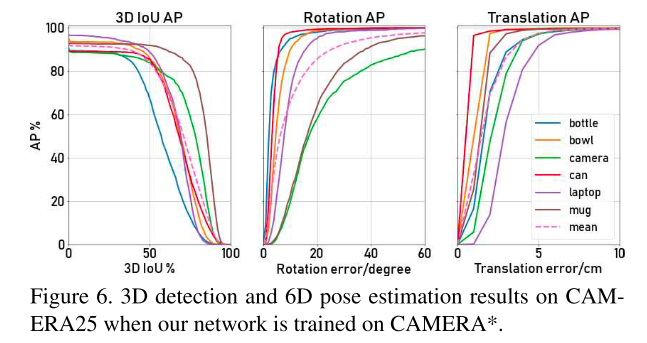
图6
- Test on REAL275:然后,我们在COCO的弱监督下,在真实世界数据集(REAL*)的组合上训练我们的网络,并在真实世界测试集上对其进行评估。由于COCO没有真实NOCS地图,我们在训练期间不使用NOCS lost。我们使用20K的可可图像,其中包含我们类别中的实例。为了在这些数据集之间进行平衡,对于每个小批量,我们从三个数据源中选择图像,其中Camera的概率为60%,CoCo的概率为20%,REAL的概率为20%。该网络是我们用来产生所有可视化结果的最佳性能模型(图8)。
在实际测试集中,我们获得了50%的3D IOU的MAP为76.4%,(5◦,5 cm)指标的MAP为10.2%,(10◦,5 cm)指标的MAP为23.1%。相比之下,基线算法(MASK RCNN+ICP align)对于50%的3D IOU的MAP为43.8%,对于(5◦,5 cm)和(10◦,5 cm)度量的MAP为0.8%,显著低于我们的算法性能。图7显示了更详细的分析和比较。这个实验表明,通过学习预测密集的NOCS地图,我们的算法能够提供关于对象的形状、部分和可见性的额外详细信息,这些信息对于正确估计对象的6D姿势和大小都是至关重要的。
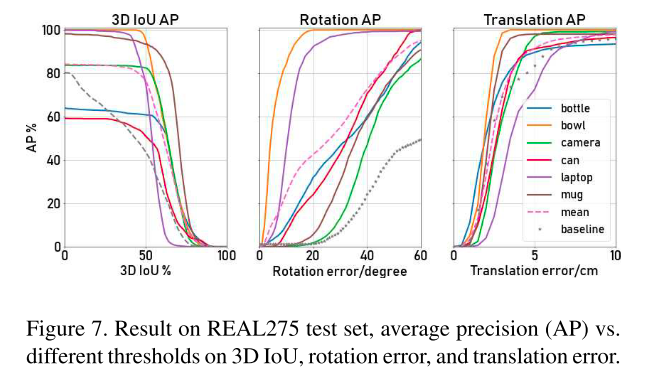
图7

图8
6.2 消融实验
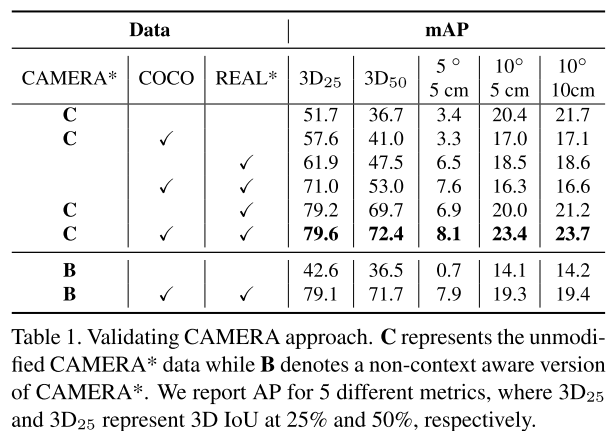
- CAMERA Approach:
表1
- Classification vs. Regression and Symmetry Loss:
表2

6.3 Instance-level 6D Pose Estimation
数据集:OccludedLINEMOD 。15%作为训练集,使用Section 4方法生成15000合成图片。
Baseline:PoseCNN
该实验表明,虽然我们的方法设计用于类别级姿态估计,但它也可以在标准 6D 姿态估计基准上实现最先进的性能。
- Limitations and FutureWork:
据我们所知,我们的方法是解决类别级 6D 姿势和尺寸估计问题的第一种方法。 还有许多悬而未决的问题需要解决。 首先,在我们的方法中,姿势估计取决于区域建议和类别预测,这可能是不正确的并对结果产生负面影响。 其次,我们的方法依靠深度图像将 NOCS 预测提升到真实世界坐标。 未来的工作应该研究直接从 RGB 图像估计 6D 姿势和大小。
7.Conclusion
我们提出了一种用于先前看不见的对象实例的类别级6D位置和大小估计的方法。我们提出了一个新的规范化对象坐标空间(NOCS),它允许我们定义具有一致对象缩放和方向的共享空间。我们提出了一种CNN,它预测可与深度图一起使用的NOCS图,以使用姿势拟合方法估计全度量6D姿势和看不见对象的大小。我们的方法在增强现实,机器人和3D场景理解等领域具有重要的应用。
遗留问题
不理解的地方标红了
1.紧边界框对角线长度为1?不是根3?还是指的归一化的物体对角线? 2.颜色编码如何实现的? 3. 分类问题的B(N)指的是什么?B=32,64,128是什么意思,是颜色的编码莫?怎么能这么大的维度,还是类别数?













 4886
4886











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









