







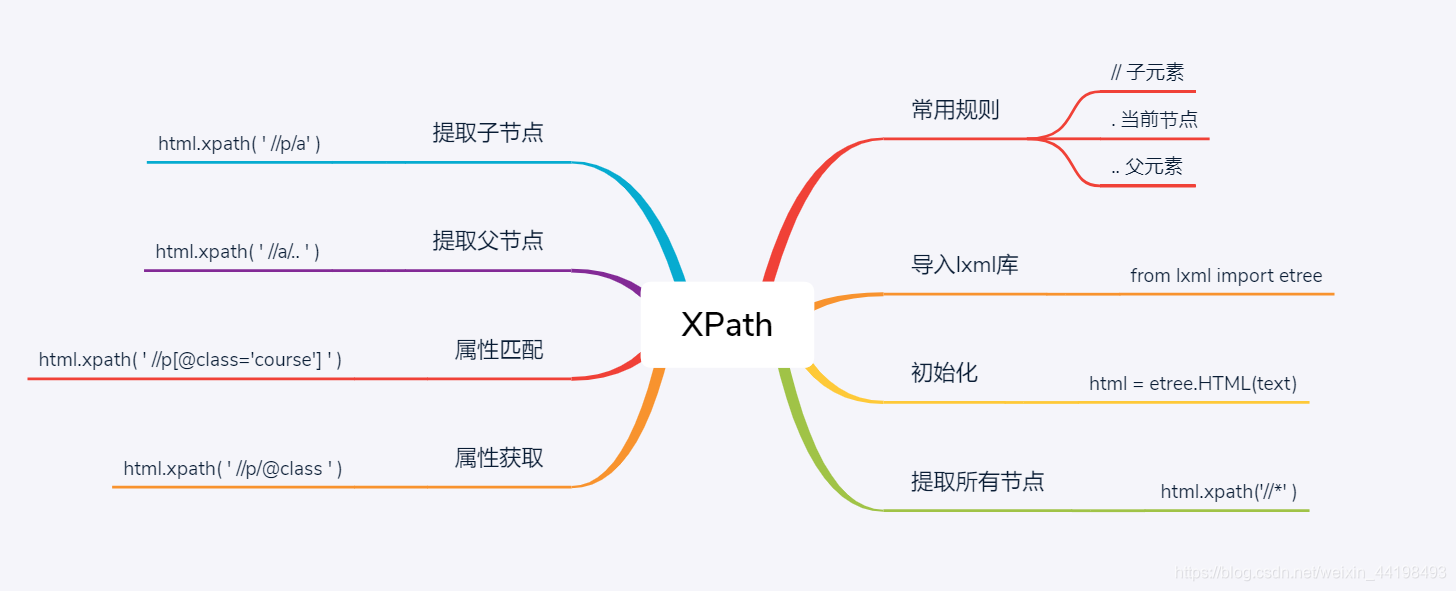
常用规则
| 句法 | 描述 |
|---|---|
| tag | 选择具有给定标记的所有子元素。例如,spam选择指定的所有子元素spam,并spam/egg选择指定的所有孙子egg的所有命名的孩子 spam。 |
| * | 选择所有子元素。例如,*/egg 选择所有名为egg的元素。 |
| . | 选择当前节点。这在路径的开头非常有用,表明它是相对路径。 |
| … | 选择父元素 |
| // | 选择当前元素下所有级别的所有子元素。例如,.//egg选择egg整个树中的所有元素 |
| [@attrib] | 选择具有给定属性的所有元素。 |
| [@attrib=‘value’] | 选择给定属性具有给定值的所有元素。该值不能包含引号。 |
| [tag] | 选择具有子命名的所有元素 tag。只支持直系孩子。 |
| [tag=‘text’] | 选择所有具有子名称tag的元素,其子文件 的完整文本内容(包括后代)等于给定的内容text。 |
| [position] | 选择位于给定位置的所有元素。该位置可以是整数(1是第一个位置),表达式last() (对于最后一个位置),或相对于最后位置的位置(例如last()-1) |
用法实例
演示html代码:
<html><head><title>This is a python demo page</title></head>
<body>
<p class="title"><b>The demo python introduces several python courses.</b></p>
<p class="course">Python is a wonderful general-purpose programming language.
<a href="http://www.icourse163.org/course/BIT-268001" class="py1" id="link1">Basic Python</a>
and <a href="http://www.icourse163.org/course/BIT-1001870001" class="py2" id="link2">Advanced Python
</a>.</p>
</body>
</html>
导入lxml库
from lxml import html
etree = html.etree
提取所有节点
一般用 // 开头的XPath规则选取,其后跟节点名称*、html、body、div等
# 获取HTML文本
html = etree.HTML(text)
# 获取全部节点的文本
result = html.xpath('//*/text()')
print(result)
例子:

提取子节点
通过 / 或者 // 查找元素的子节点或子孙节点
# 查找p节点下a元素的文本
result = html.xpath('//p/a/text()')
结果:

提取父节点
用两个.来实现
# 选取a的父类节点p的文本
result = html.xpath('//a/../text()')
结果:

属性匹配
用@符号进行属性过滤
# 选取class为course的p节点的文本
result=html.xpath('//p[@class="course"]/text()')
结果:

属性获取
用@获取节点的属性
# 获取p节点的所有class属性
result = html.xpath('//p/@class')
结果:

属性多值匹配和多属性匹配
当某个节点有多个属性时,使用contains()函数
# contains()函数—第一个参数传入属性名称,第二个为属性值
result = html.xpath('//p/a[contains(@class,"py1")]/text()')
结果:

当要根据多个属性指定一个节点时,就要同时匹配多个属性,用and、or、| 等来连接。
result = html.xpath
('//p/a[contains(@class,"py1") and @id="link1" ]/text()')
参考文档:
python lxml使用官方网站
xpath规则














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









