








介绍
Beautiful Soup是一个Python包,功能包括解析HTML、XML文档、修复含有未闭合标签等错误的文档(此种文档常被称为tag soup)。这个扩展包为待解析的页面创建一棵树,以便提取其中的数据,这在网络数据采集时非常有用。
用法实例
解析源码
text = '''
<html><head><title>This is a python demo page</title></head>
<body>
<p class="title"><b>The demo python introduces several python courses.</b></p>
<p class="course">Python is a wonderful general-purpose programming language.
<a href="http://www.icourse163.org/course/BIT-268001" class="py1" id="link1">Basic Python</a>
and <a href="http://www.icourse163.org/course/BIT-1001870001" class="py2" id="link2">Advanced Python
</a>.</p>
</body>
</html>
'''
导入库
from bs4 import BeautifulSoup
初始化Beautiful Soup
# 第一个参数为传给BeautifulSoup的对象,
# 第二个为解析器的类型(有html.parser、lxml、xml等)
soup = BeautifulSoup(text, 'html.parser')
解析HTML代码
输出原代码
# 按照标准的缩进格式的结构输出
print(soup.prettify())
1、节点选择器
选择元素
根据需要选择的节点,如title、head、p等
print(soup.title)
print(soup.p)
结果:

提取信息
| 属性 | 作用 |
|---|---|
| name | 获取节点的名称 |
| attrs或[‘class’] | 获取所有属性 |
| string | 获取文本内容 |
print(soup.title.name)
print(soup.p.attrs)
# 直接选择属性
print(soup.p['class'])
print(soup.p.string)
结果:

嵌套选择
获取节点内部的节点元素
print(soup.head.title)

关联选择
1、子节点和孙子节点
# 子节点
print(soup.head.contents)
for child in soup.head.children:
print(child)
# 得到所有子孙节点
for child in soup.head.descendants:
print(child)
结果:
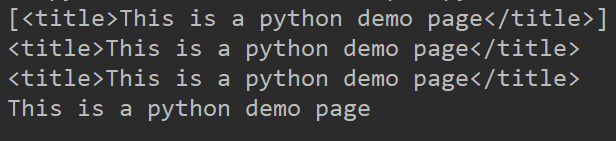
2、父节点和祖先节点
# 获取所有父节点
print(soup.a.parent)
print('..............................')
# 获取所有祖先节点
for parent in soup.a.parents:
if parent is None:
print(parent)
else:
print(parent.name)
结果:

3、兄弟节点
| 属性 | 作用 |
|---|---|
| next_sibling | 下一个兄弟元素 |
| previous_sibling | 上一个兄弟元素 |
| next_siblings | 后面所有元素 |
| previous_siblings | 前面所有元素 |
.next_sibling 和 .previous_sibling 属性真实结果是标签之间的顿号和换行符
print(soup.p.next_sibling)
print(soup.p.next_sibling.next_sibling)
print(soup.p.previous_sibling)
for sibling in soup.p.next_siblings:
print(repr(sibling))
结果:

4、提取信息
print(soup.a.next_sibling.next_sibling)
# 文本
print(soup.a.next_sibling.next_sibling.string)
# 属性
print(soup.a.next_sibling.next_sibling.attrs)
结果:

2、方法选择器
find_all()
通过name、attrs、text属性等,查询所有符号条件的元素
find_all( name , attrs , recursive , text , **kwargs )
print('##########根据name选择############')
print(soup.find_all(name='a'))
print('##########根据attrs选择############')
print(soup.find_all(attrs={'class': 'course'}))
print('##########根据kwargs选择############')
print(soup.find_all(class_='course'))
print('##########根据text选择############')
print(soup.find_all(text=re.compile('python')))
print(soup.find_all(text=re.compile("Python"), id="link1"))
结果:

| 方法 | 说明 |
|---|---|
| find() | 通过name、attrs、text属性等,返回单个元素 |
| find_parents()或find_parent | 返回(所有)祖先节点 |
| find_next_siblings()或find_next_sibling() | 返回后面所有(第一个)兄弟节点 |
| find_previous_siblings()或find_previous_sibling() | 返回前面所有(第一个)兄弟节点 |
| find_all_next()或find_next() | 返回节点后所有(第一个)符合条件的节点 |
| find_previous_siblings()或find_previous_sibling() | 返回节点前所有(第一个)符合条件的节点 |
3、CSS选择器
调用select()方法,传入相应CSS,获取想要数据
嵌套选择
在一个节点中,再遍历其中的节点
print(soup.select('p'))
print('')
for p in soup.select('p'):
print(p.select('a'))
结果:

获取属性
直接传入[’属性名‘]或attrs属性获取属性值
for a in soup.select('a'):
print(a['id'])
print(a.attrs)
结果:

获取文本
通过string属性或get_text()方法获取文本
for a in soup.select('a'):
print(a['id'], ':')
print(a.get_text())
















 803
803











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









