







目录
1.K-近邻算法(KNN)概念
如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
2.k近邻算法api --Scikit-learn工具
安装:
pip3 install scikit-learn==0.19.1K-近邻算法API
- sklearn.neighbors.KNeighborsClassifier(n_neighbors=5)
- n_neighbors:int,可选(默认= 5),k_neighbors查询默认使用的邻居数
最简单的代码:
#导入模块
from sklearn.neighbors import KNeighborsClassifier
#构造数据集
x = [[0], [1], [2], [3]]
y = [0, 0, 1, 1]
#模型训练
# 实例化API
estimator = KNeighborsClassifier(n_neighbors=1)
# 使用fit方法进行训练
estimator.fit(x, y)
estimator.predict([[1]])注:代码由notebook实现,py文件的话需要相应的print进行输出。
3.距离公式:
理解 :多远的距离算近?
欧式距离
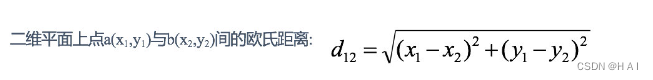
曼哈顿距离

切比雪夫距离
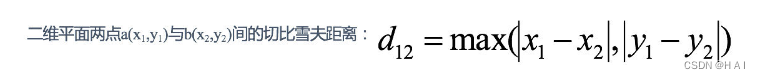
闵可夫斯基距离
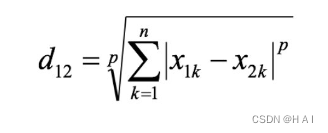
其中p是一个变参数:
-
当p=1时,就是曼哈顿距离;
-
当p=2时,就是欧氏距离;
-
当p→∞时,就是切比雪夫距离。
4.K近邻算法的K值选取
- K值过小:
- 容易受到异常点的影响
- k值过大:
- 受到样本均衡的问题
K值选择问题,李航博士的一书「统计学习方法」上所说:
- 1) 选择较小的K值,就相当于用较小的领域中的训练实例进行预测,
- “学习”近似误差会减小,只有与输入实例较近或相似的训练实例才会对预测结果起作用,与此同时带来的问题是“学习”的估计误差会增大,
- 换句话说,K值的减小就意味着整体模型变得复杂,容易发生过拟合;
- 2) 选择较大的K值,就相当于用较大领域中的训练实例进行预测,
- 其优点是可以减少学习的估计误差,但缺点是学习的近似误差会增大。这时候,与输入实例较远(不相似的)训练实例也会对预测器作用,使预测发生错误。
- 且K值的增大就意味着整体的模型变得简单。
- 3) K=N(N为训练样本个数),则完全不足取,
- 因为此时无论输入实例是什么,都只是简单的预测它属于在训练实例中最多的类,模型过于简单,忽略了训练实例中大量有用信息。
- 在实际应用中,K值一般取一个比较小的数值,例如采用交叉验证法(简单来说,就是把训练数据在分成两组:训练集和验证集)来选择最优的K值。
5. kd树
实现k近邻算法时,主要考虑的问题是如何对训练数据进行快速k近邻搜索。
这在特征空间的维数大及训练数据容量大时尤其必要。
k近邻法最简单的实现是线性扫描(穷举搜索),即要计算输入实例与每一个训练实例的距离。计算并存储好以后,再查找K近邻。当训练集很大时,计算非常耗时。
为了提高kNN搜索的效率,可以考虑使用特殊的结构存储训练数据,以减小计算距离的次数。
(可以baidu to learn)















 9621
9621











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









