






前提 - 故障演练介绍
什么是故障演练?
混沌工程
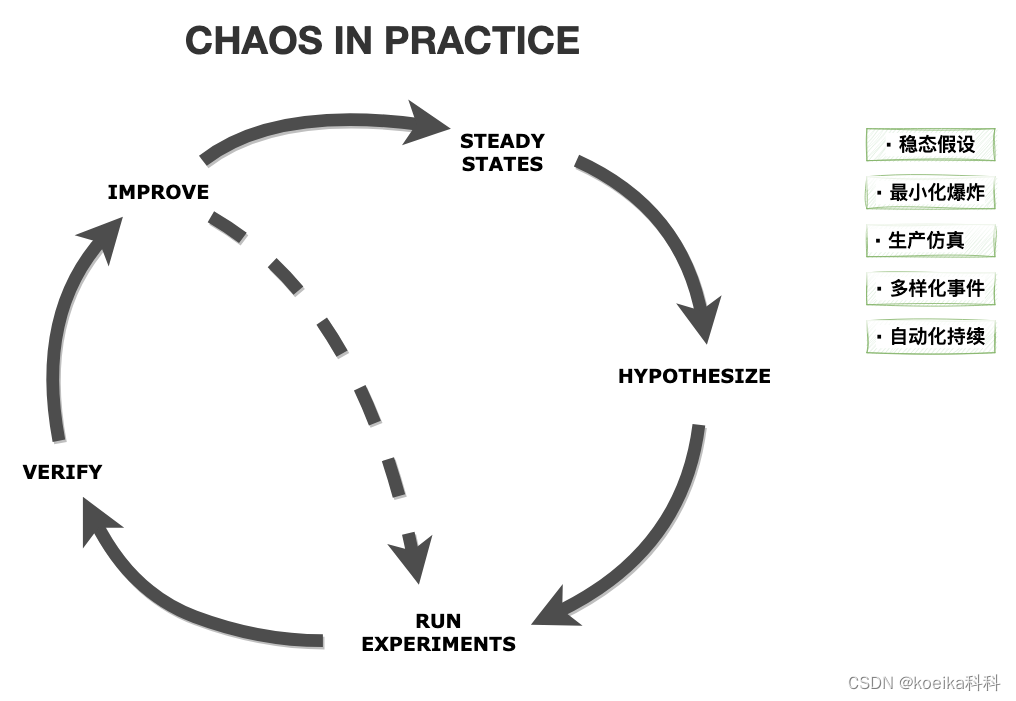
什么是混沌工程? Netflix在2012年发布了Chaos Monkey, 向业界介绍了这个思想 PRINCIPLES OF CHAOS
ENGINEERING。混沌工程简单来说,就是扰动注入已经呈现稳态的系统中,观测系统因此而产生的变化并做出对策,使今后系统面对同类异常扰动的变化delta在空间和时间维度上尽可能的小。混沌工程不是一次性的试验,通过验证,改进和再试验,形成一种往复性的提升机制。 故障演练就是混沌工程的实现方式之一。
(接下来的具体设计,我们会围绕CHAOS IN PRACTICE这几个要素展开探索。)
为什么需要故障演练?
随着我们的系统规模越来越大,我们在不断适应着新的变化,如前期的应用拆分到近期的以mono repo形式集成react到项目中…
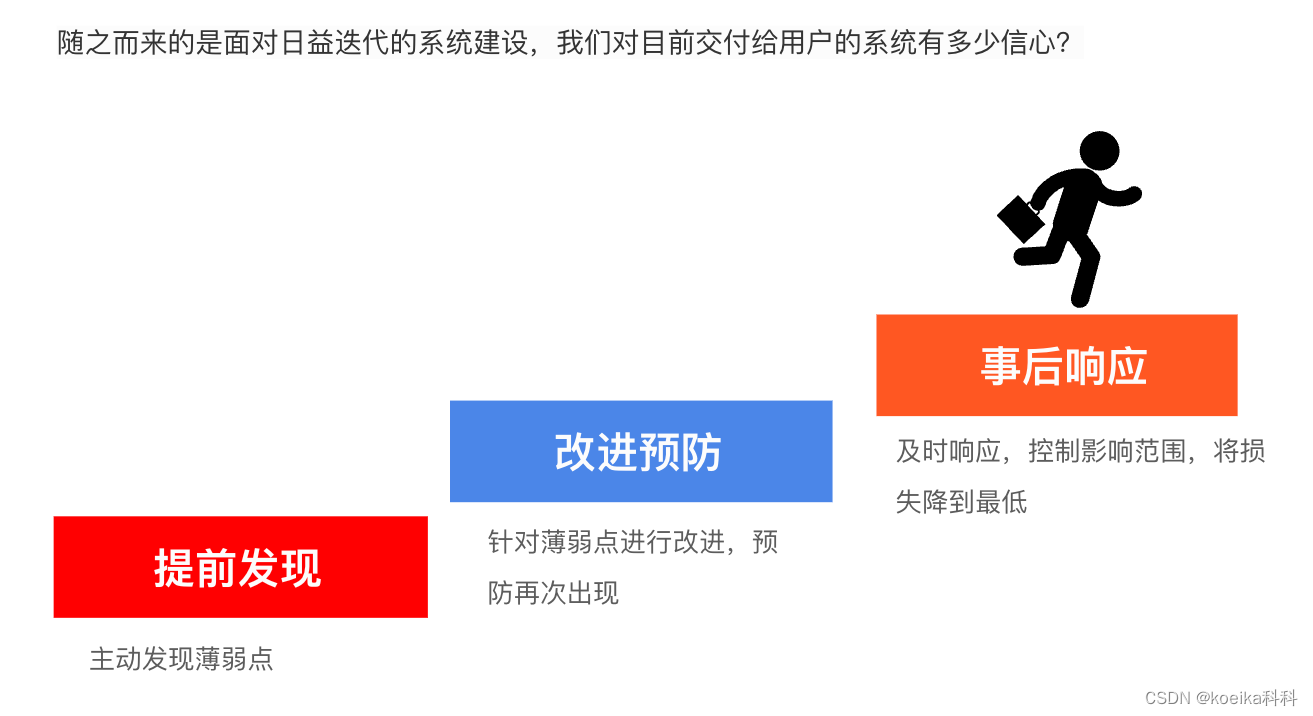
随之而来的是面对日益迭代的系统建设,我们对目前交付给用户的系统有多少信心?
诚然,我们的系统功能在交付出去时肯定都是”符合用户期待的“,”功能运行正常的“。但是难免会有一些没有考虑到的交互会导致一些没有预料到的结果。我们需要主动发现我们的弱点,在意外出现之前将其解决。同样,当无法提前发现的故障发生时,我们需要如何响应。
这些就是故障演练的出发点。
一、背景
1.1 背景:
当线上有故障时我们应该怎么处理,处理流程是什么样的,涉及到哪些操作,我们怎么分析故障?
发现大部分同学对此部分还没有特别清晰的概念。
1.2 痛点:
- 基本开发日常不涉及故障处理,大部分开发不了解如何处理故障的细节,对前端安全生产重视度不足
- 以往前端未举行过故障演习,没有参考指引
- 没有常态化的度量能力,让大家看清当前的水位,并形成一种推动力,促使大家去完善内部建设
- 相关的生态伙伴没有能广泛的参与进来,大部分质量保障基础设施的建设热点都与前端关联度不高
- 告警配置指引,告警规则创建没有一个前置校验过程

二、目的
- 举行故障演练,让所有参与人员对质量生产重视起来。同时熟悉故障处理流程,对如何处理故障有清晰的了解,提高故障处理效率。
- 提供故障演练指南,为之后的故障演习提供依据及支持。
- 通过故障演练的复盘与分析,揭露目前内部存在的弱点,提高故障发现能力与组织响应能力
- 响应告警通知,检测告警规则准确性(待后续加入故障演习,本次不讨论)
三、故障设计
基于混沌工程理念探索如何设计故障 :

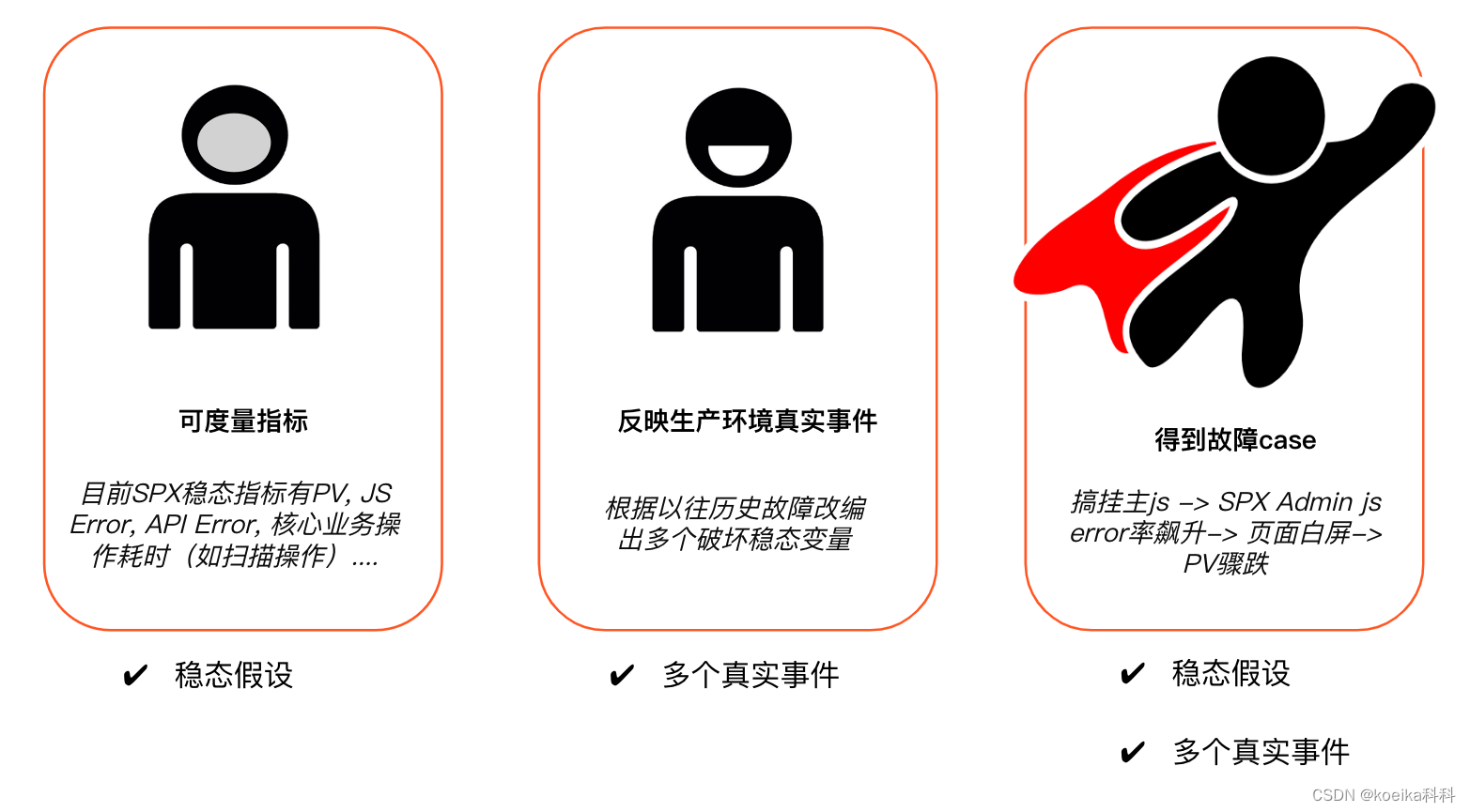
3.1 【稳态假设】- 我们需要什么故障
这里的稳态也就是各类能代表当前业务能力的关键指标的集合,并且他们在一个固定的业务周期里处于相对稳定的状态。
目前前端业务指标主要有几种:PV, JS Error, API Error, 核心业务操作耗时(如扫描操作)…
找到了稳态就可以制定一个假设,以SPX Admin 为例,如果把主js搞挂,那么同比来看,SPX Admin js error率会飙升,并且PV会骤跌。
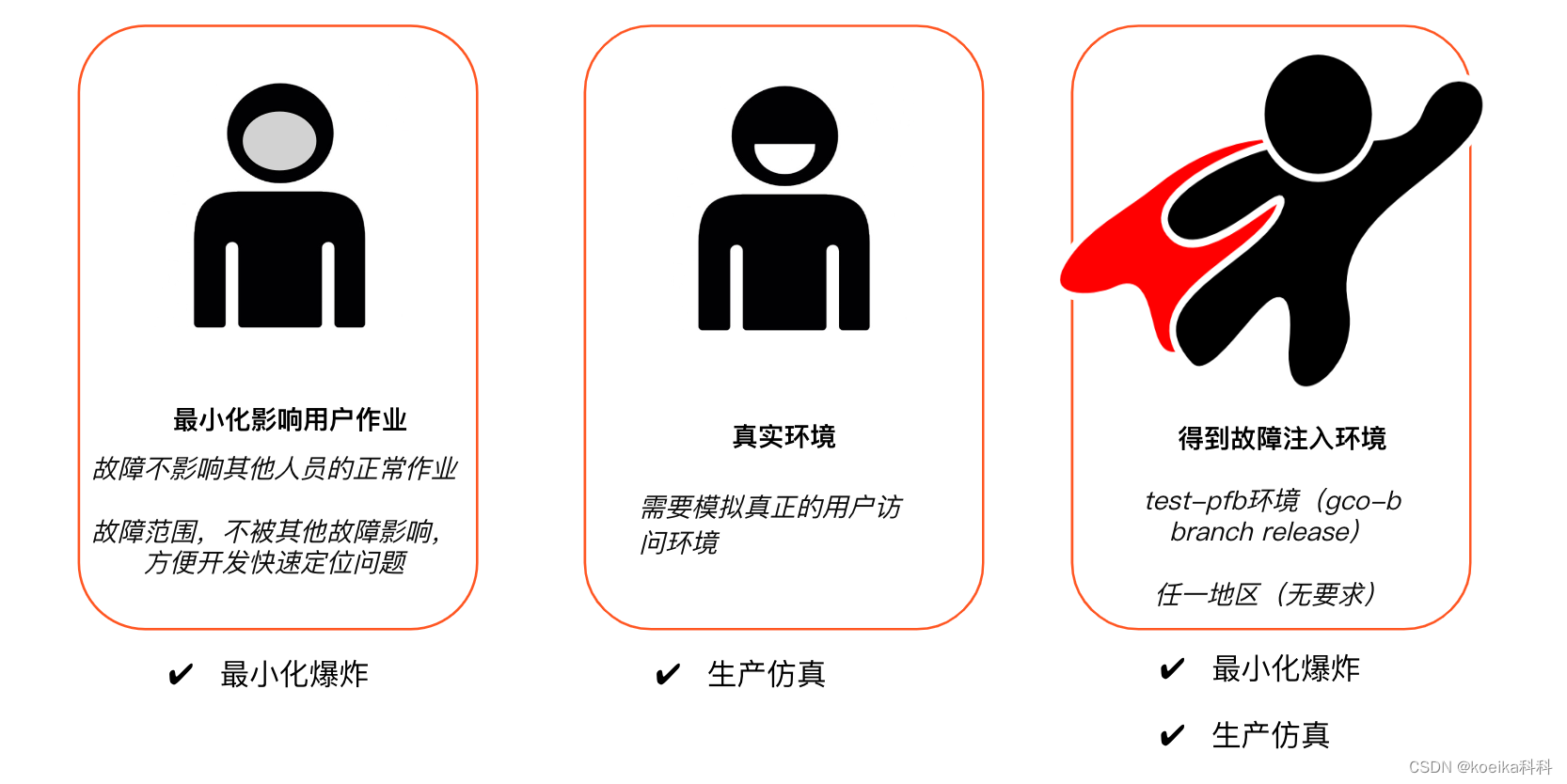
3.2【最小化爆炸,生产仿真】- 故障环境
上面的思考已经得出我们应该做什么故障,怎么做出故障。那么故障应该注入在哪里?
按照混沌工程五要素之最小化爆炸,生产仿真来看,
故障应最小化影响用户,且需要模拟真正的用户访问环境。
具体场景如:
故障不影响其他人员的正常作业
故障独立发生,不被其他故障影响,方便开发快速定位问题
故障环境需要同步live
针对第一点:不影响其他人的正常作业。
首先可以排除test,uat, live。test用于开发日常工作,测试; uat用于业务测试; live更不用说。
考虑pfb,我们可以在pfb中注入故障,在pfb中触发监控上报等。
考虑staging,我们可以在非回归的时间占用某一环境进行演练。
针对第二点: 故障独立发生,不被其他故障影响。
有两种场景,
使用test-pfb或uat-pfb,每个故障对应一个pfb,满足独立故障注入;
使用staging环境,只在一段时间内注入一个故障。
针对第三点: 故障环境同步live, 在pfb环境中,我们部署的分支是由live分支切出来的,可以同步线上环境内容。
因此在pfb环境注入故障为最佳的选择。 由于较常使用的是test-pfb,所以本次演习选择test-pfb环境,任一地区(无要求)。
3.3【多样化事件】- 制造故障
故障类型
后端已有较成熟的故障演练体系,主要关注的是线程池满,数据库连接,网络延时等问题.那么当涉及到前端的故障演练时我们需要关注哪些方面?
查看以往故障场景 质量问题与复盘,举例:
| 前端 sre:业务代码,sre侧配置 | |
| 网络: 网络攻击 | |
| 发版:打包错误,版本异常 | |
| 配置 |
可以总结具体的问题:
- 有依赖的问题类型:
sre:配置,资源,网络,访问…
后端: 接口,逻辑,发版顺序…
- 纯前端问题类型:
(业务问题,样式,资源访问(菜单栏配置,权限),翻译,页面展示(白屏,部分白屏),功能性问题,部署问题,发版顺序…)
以上可概括为js error, api error, 发版,配置问题
有依赖的问题类型: 在前端面无法触发,需要sre,qa协助注入故障。
纯前端问题类型:可以修改代码,配置等制造。
区别于后端的演练,我们发现实际前端故障演练关注代码,资源等数据。
故障注入
纯前端问题的故障的注入目前有几个方面:
-
配置更改
修改apollo配置,将接口或功能指向已下线的接口或页面,引发接口404或pv下降问题
修改devhelp菜单栏配置,权限树配置,将页面隐藏或展示非本地区页面,引发pv下降或业务上报多出非使用的页面问题 -
代码修改:
增删改功能代码,如引入一个不存在的依赖,删除某个被引用的函数,修改函数名等产生js error的问题
增删改接口,直接在代码中修改api path,导致大量404上报 -
【特殊】发版问题:
修改发版顺序,产生依赖关联问题
因为纯前端问题类型可以内部独立注入,不需依赖前端外的同学,修改代码的方式也比较简单,所以本次故障演习只造纯前端类型的故障。
同时为了避免参与人员花费过多时间在排查问题上,我们注入的故障需要比较明显,容易修复。 按照质量问题与复盘中的真实故障进行改造,
我们需要关注代码的质量,也要关注故障发生时,开发、系统的发现能力和组织的响应能力。 结合稳态假设 + 故障类型 + 故障注入方式
我们得到以下case => 举例
| 指标 | 核心场景 |
|---|---|
| PV / js error | 页面白屏 |
| API error | 接口写错 |
3.4 【自动化持续】 不讨论
每次故障演习都拉通所有参与人员进行,很难持续化进行。
如果这种故障注入的方式能够以自动化的方式加到系统中,定期编排和分析团队质量和组织能力,能帮助团队持续化的关注内部质量安全。
但是本次故障演练主旨在让团队成员熟悉故障处理流程,所以此处不展开讨论。
四、演练编排
以上介绍了故障case的内容,下面介绍故障演练的一系列安排:
4.1 如何发现故障
目前发现故障的方式分主动发现,被动发现。
主动发现:
- 通过访问页面,查看控制台,发现页面中出现的明显的问题。
- 通过监控平台巡检。
被动发现:
- 业务,qa等其他人员在通知发生故障
- 监控告警通知
我们可以对主动发现与被动发现的情况都做故障演习:
主动发现:
通过提示演练人员查看页面发现 通过提示演练人员巡检,查看监控平台。在业务、qa等上报问题前发现 被动发现:
创建jira单通知演练人员,或直接模仿业务通知故障。 通过配置test环境告警规则 告警配置指引,告警规则创建
,触发故障满足告警规则,触发告警。(目前spx 还未接入test环境告警预计2023.12月之后添加,考虑后续加入此场景)
4.2 演练内容
我们需要演练什么? 回顾我们的目的,熟悉故障处理流程,提供故障演习指南。
所以我们需要准备一个预案,针对故障类型,为演练人员提供故障处理指引,并在处理故障发生过程中熟悉整个流程。
对可能会用到的预案进行调研,从故障类型,场景,预案操作方面考虑。
场景:
目前前端遇到问题的场景会有三种,
-
日常问题:
一般会由开发,业务人员发现。日常值班遇到的故障类型较多,几乎所有类型都可能会出现 -
发版问题:
一般由发版qa,发版参与人员发现。一般是发版顺序问题,依赖,或突然发现的功能性问题。 -
值班
一般通过观察监控提前发现问题,或由开发及业务人员上报。一般涉及接口访问,流量异常,服务扩容等问题。涉及前端方面较少。
预案针对以上三种类型进行编写。
预案操作:
通过查看历来故障场景,总结前端现有的操作,一般是回滚,降级,修复,开关,扩容,通知依赖方等。
围绕以上三种方面考虑,输出预案编排:具体不举例,根据业务情况编写。
4.3 演练前期准备
1. 职能分组
| 职能 | 定义 |
|---|---|
| 决策组 | 根据关键信息决策是否执行某一个预案 。 关键信息的聚合点,对外沟通 。实时关注『日常/发版/大促值班群』 。 需要对预案熟悉 |
| 预案执行组 | 根据决策组决定,执行预案,降低损失,减少事态持续恶化。在『大促日报』记录预。执行记录。在『日常/发版/大促值班群』反馈问题进度 。需要能执行多条预案而不混乱 |
| 定位组 | 根据监控,日志,其他线索定位排查问题。实时关注决策组消息。记录问题处理进度。在『大促值班群』反馈问题进度。汇总关键信息,提供预案选项。每个模块有一个责任人 |
| 巡视组 | 虚拟的组,由『定位组』的成员组成,轮流巡视。 定位组的A成员开始每30分钟巡视一次,如果A成员需要定位问题,或者有其他事不做巡视,需要交接给B成员进行巡视。确保每30分钟都有一名值班人员在巡视。需要敏锐地发现问题 |
2. 相关系统权限申请,提前熟悉监控指引,熟悉演练流程
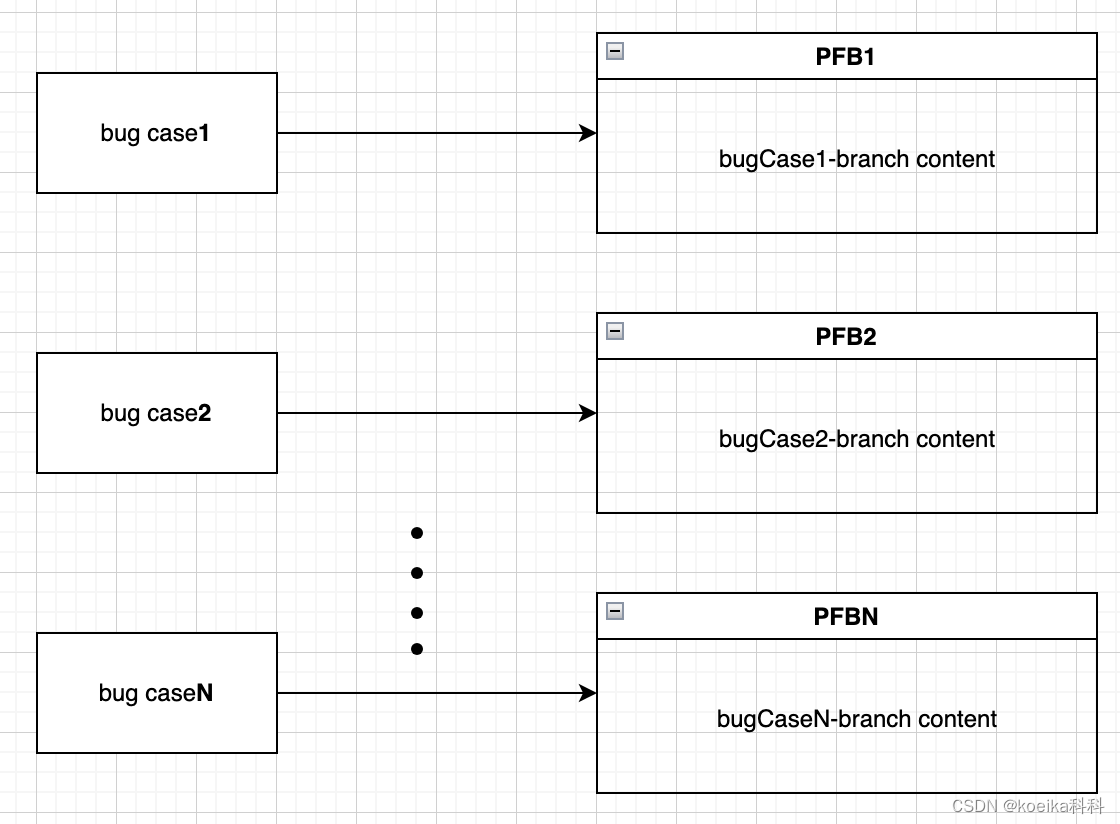
3. 故障注入组提前在pfb中注入故障
需要对每个故障准备第一个pfb,注入故障并部署。
4. 演练宣讲,提前动员成员预热,做好演练前准备
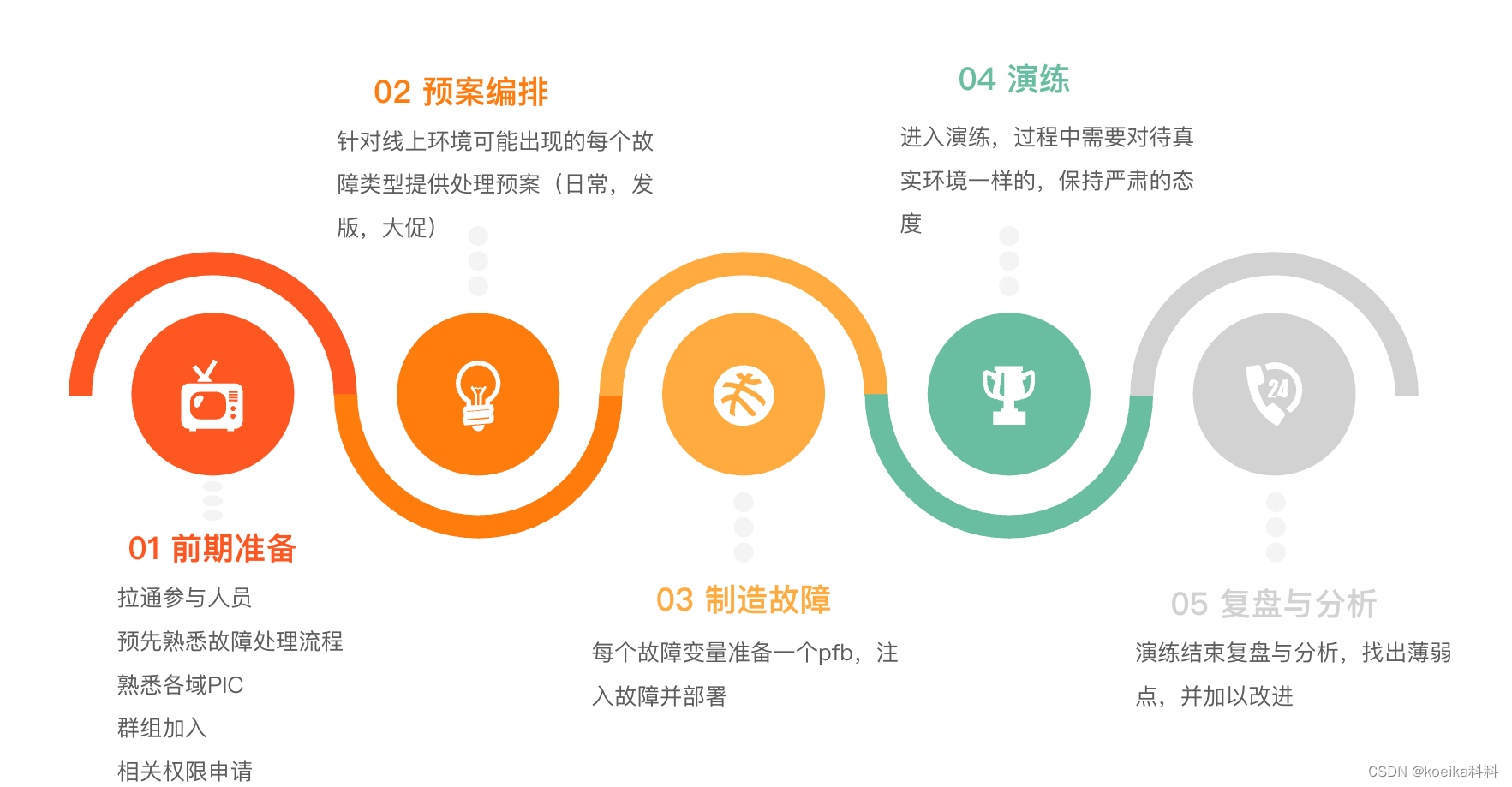
4.4 演练方式
我们要怎么演练?
考虑如下:
线下:会议室,演练人员到达会议室,在会议室中听从主持人指示,在现场进行故障演习
线上:zoom 会议,演练人员加入zoom会议,主持人主持故障控场,演练人员在会议中交流进行故障演习
线上: 群聊,创建故障群,在群中进行故障演习,群聊机器人控场,演练人员根据机器人安排进行故障演习
考虑到,处理故障的过程中不需要线下交流,且zoom中不方便留记录,语音交流非必须等情况,最后选择使用群聊方式进行演练。
具体演练方式如下:
1、由于每个故障独立,不需要太多数据就能让演练人员发现,所以没有考虑编写脚本产生故障数据(若数据量大,推荐考虑)。提前通知演练人员注入故障,在这段时间内,故障注入组成员手动持续触发故障,保持可观的故障率。
2、为了最小化影响演练人员的日常工作,所以决定黑盒+白盒演练,对演练人员提示故障类型,但不说明故障内容,定位组成员通过提示定位故障
3、定位组定位出问题后,根据上面提到的预案,筛选当前预案,提供可靠预案到决策组决策选择最佳方案。
4、执行组执行决策组预案,修复故障
5、处理时效收集,整体复盘
黑盒演练 团队的监控能力、应急能力和处理问题速度 无脑触发
白盒演练 针对性问题的处理能力和排查思路 定制化出发
五、演练流程
- 提前拉参与人员进故障演习群
- 每一个组都会进行2-3例故障处理,通过bot提前提示参与模块即将开始进行演练后开始注入故障
- 故障注入组成员按照故障case注入故障,每个故障对应一个pfb,注入后以模拟当前故障场景的形式,通知参与成员发生了什么故障,并告知当前故障在哪个pfb,以及对应的分支。
- 故障注入组成员查看case已产生并且监控可查后,通过bot提醒巡检组成员巡检或查看问题,并提示故障场景等
- 巡检组成员查看故障页面或监控通知相关模块的定位组成员进行定位
- 定位组成员根据监控,日志,及其他线索定位排查问题
- 定位组定位出问题后,汇总关键信息,提供预案选项,由决策组决策是否执行某个预案 预案执行组根据决策组决策,执行对应的预案。
若需要修改代码,则在第3点中故障注入成员提前说明的故障分支,pfb,进行修复,并部署。 并在『演练群』反馈问题进度。 - 待问题修复后,巡检组成员(由定位组成员组成)持续观察环境是否有问题,待环境恢复正常后。等待故障注入组成员通知重复2.
ps: 演练过程中也可以模拟真实故障修复场景,给到演练人员一定的压力,以严肃 紧迫的态度进行演练 ~


















 839
839

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









