









用 pytorch 几秒就能跑完的,用 onnxruntime 反而慢了10 倍不止,下图中 ‘CUDAExecutionProvider’ 也说明 onnxruntime 确实是用上了 GPU。
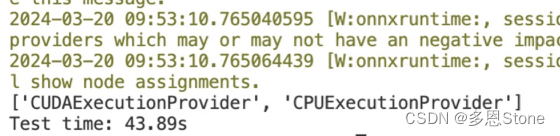
onnxruntime 部分代码如下
opts = onnxruntime.SessionOptions()
ort_session = onnxruntime.InferenceSession('/path/to/yourmodel.onnx', opts, providers=['CUDAExecutionProvider'])
# double check is using GPU?
print(ort_session.get_providers())
# onnx 的输入是 numpy array 而非 tensor!
ort_inputs = {'input': numpy_input}
ort_output = ort_session.run(['output'], ort_inputs)[0]
# tensor 转 numpy
ort_output = torch.from_numpy(ort_output)
排查方法
在 onnxruntime.InferenceSession 前可以加入以下代码,
opts.enable_profiling = True
# 可以在当前目录下保存一个 onnxruntime_profile_xxx.json
onnxruntime.set_default_logger_severity(1)
# 可以在 bash 中获得详细信息
打开 onnxruntime_profile_xxx.json ,关键看 dur 部分代表了持续时间。
从上图可见 session_initialization 部分耗时占了非常多,有 45335065 微秒,也就是 40 多秒,说明就是 session 初始化占据了大部分时间。
解决方案
将 onnxruntime session 的初始化和实际推理进行分离,即统一进行 session 初始化,而每次用模型时只采用 .run 即可。示例代码如下:
# 全局初始化ONNX Runtime会话
def initialize_session():
session_options = onnxruntime.SessionOptions()
session_options.graph_optimization_level = onnxruntime.GraphOptimizationLevel.ORT_ENABLE_EXTENDED
ort_session = onnxruntime.InferenceSession('/swinir-trt/swinir_real_sr_large_model_dynamic.onnx',
session_options=session_options,
providers=['CUDAExecutionProvider'])
return ort_session
##### 分割线 #####
# 具体需要用 onnx 模型推理的位置只用 .run
ort_inputs = {'input': numpy_input}
ort_output = ort_session.run(['output'], ort_inputs)[0]
# tensor 转 numpy
ort_output = torch.from_numpy(ort_output)
分离两部分后,每次模型的推理时间便正常了,仅需短短几秒就能完成!
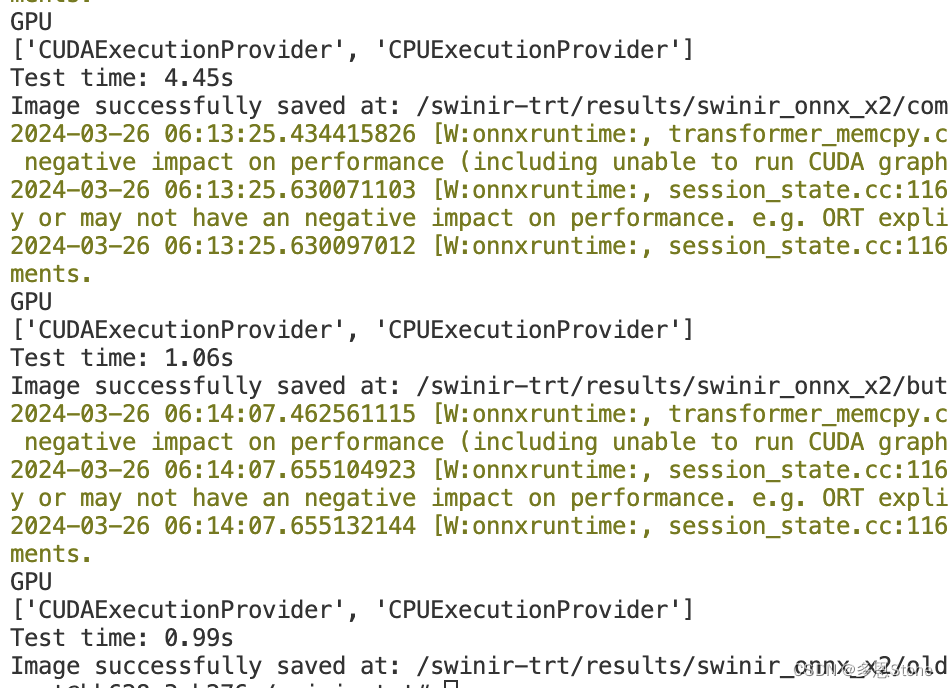
那么问题来了,为什么 session 初始化要搞怎么久?有了解的朋友欢迎留言讨论呀~
补充:减缓 session 初始化太久的问题
pip install onnx-simplifier
pip3 install -U pip && pip3 install onnxsim
onnxsim input_onnx_model.onnx output_onnx_model.onnx
将原始的 input_onnx_model.onnx 简化为 output_onnx_model.onnx
模型比较复杂的话,会等一段时间,如果成功运行会出现类似如下的提示:
Simplifying...
Finish! Here is the difference:
┏━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┓
┃ ┃ Original Model ┃ Simplified Model ┃
┡━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━┩
│ Add │ 1955 │ 547 │
│ Cast │ 2760 │ 0 │
│ Concat │ 1913 │ 404 │
│ Constant │ 25917 │ 834 │
│ ConstantOfShape │ 2485 │ 18 │
│ Conv │ 36 │ 36 │
│ Div │ 381 │ 231 │
│ Equal │ 2052 │ 19 │
│ Erf │ 54 │ 54 │
│ Expand │ 2430 │ 85 │
│ Gather │ 2877 │ 601 │
│ LayerNormalization │ 110 │ 110 │
│ LeakyRelu │ 24 │ 24 │
│ MatMul │ 324 │ 324 │
│ Mod │ 4 │ 4 │
│ Mul │ 2110 │ 165 │
│ Not │ 54 │ 2 │
│ Pad │ 1 │ 1 │
│ Range │ 1944 │ 64 │
│ Reshape │ 2776 │ 605 │
│ Resize │ 2 │ 2 │
│ ScatterND │ 486 │ 17 │
│ Shape │ 6613 │ 236 │
│ Slice │ 2335 │ 271 │
│ Softmax │ 54 │ 54 │
│ Sub │ 58 │ 5 │
│ Transpose │ 345 │ 293 │
│ Unsqueeze │ 4194 │ 472 │
│ Where │ 2052 │ 21 │
│ Model Size │ 125.4MiB │ 114.7MiB │
└────────────────────┴────────────────┴──────────────────┘
官方文档:https://pypi.org/project/onnx-simplifier/
参考博客:
https://zhuanlan.zhihu.com/p/686755347














 2342
2342











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









