






 这篇博客介绍了在VS Code环境下遇到的问题:如何加载和查看GTM-Transformer论文中的数据集。作者详细展示了如何使用torch库加载category_labels.pt文件,并提供了相关链接以供参考。
这篇博客介绍了在VS Code环境下遇到的问题:如何加载和查看GTM-Transformer论文中的数据集。作者详细展示了如何使用torch库加载category_labels.pt文件,并提供了相关链接以供参考。
复现论文 GTM-Transformer 过程中的数据集
直接用 vscode 打开的效果没法看
import torch
# Load category and color encodings
cat_dict = torch.load('C:/自己替换/category_labels.pt')
for k, v in cat_dict.items(): # k 参数名 v 对应参数值
print(k, v)
运行结果图:
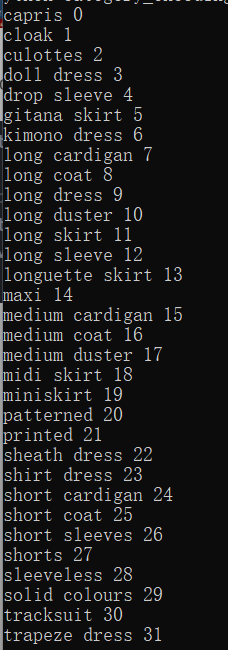
参考博客:https://blog.csdn.net/weixin_45562000/article/details/114580412?utm_medium=distribute.pc_relevant.none-task-blog-2defaultbaidujs_utm_term~default-0.pc_relevant_default&spm=1001.2101.3001.4242.1&utm_relevant_index=3


















 307
307



 到【灌水乐园】发言
到【灌水乐园】发言








