









系列文章目录
- 本系列将详细记录各种前沿论文中的可视化分析,以及这些可视化分析的相关代码及原理。
- 本文为开始篇,重点介绍 Flux 模型的 Attention Map 可视化
参考论文
- custom diffusion(CVPR23)
- color peel(ECCV24)
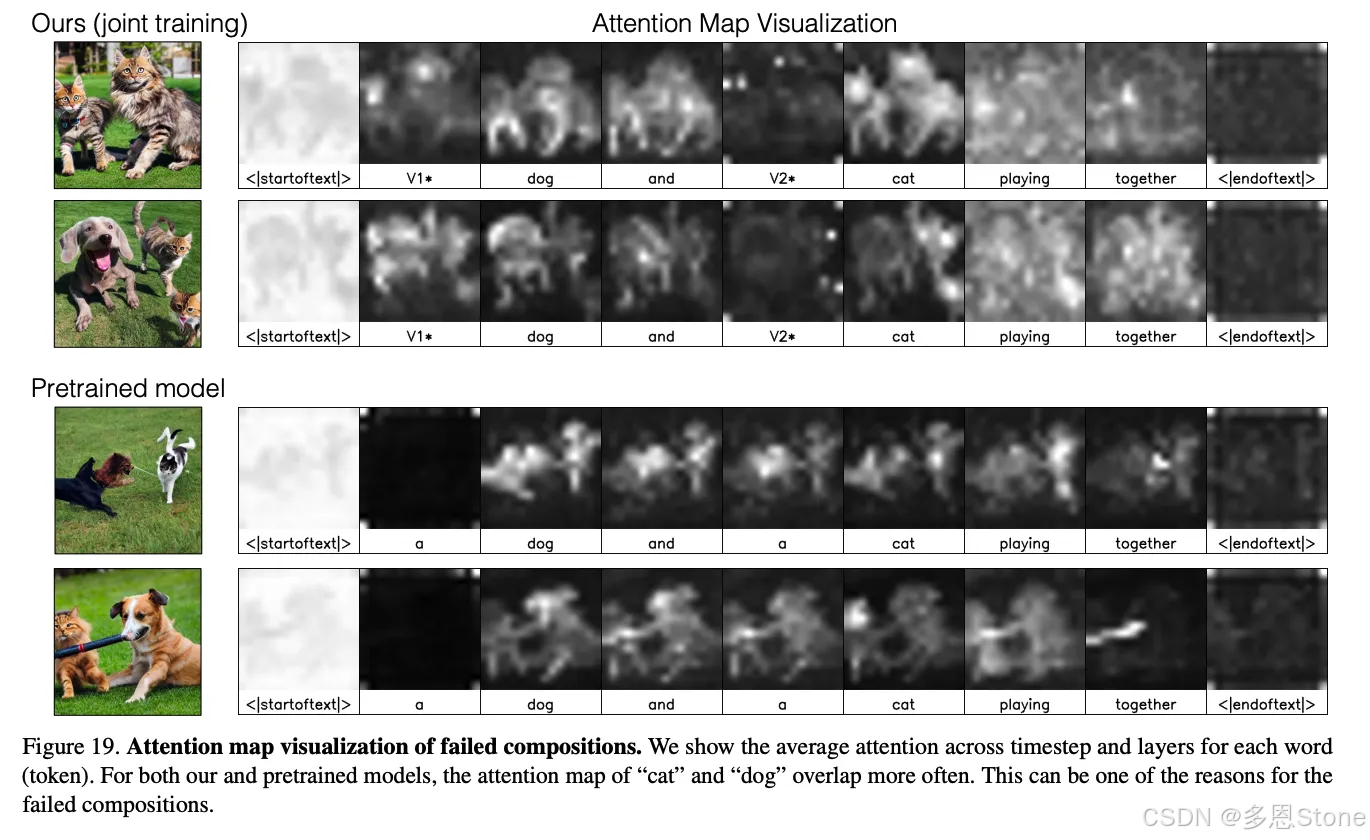
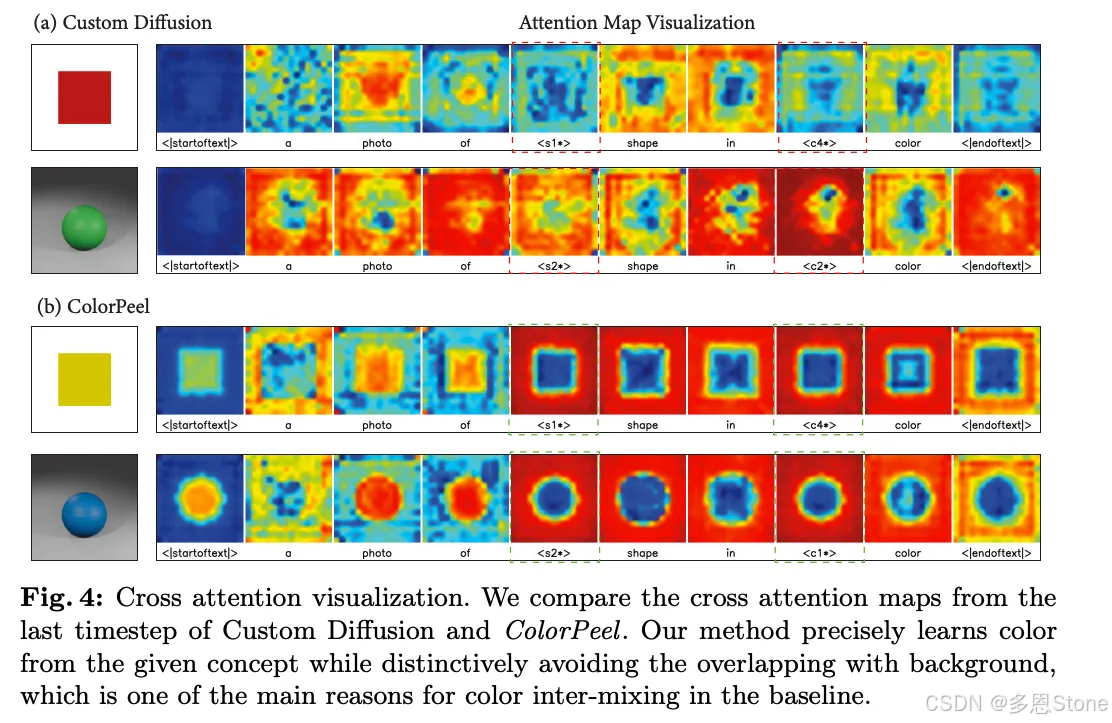
一、开源项目
本文以下方开源项目为例,进行代码拆解和分析。
- https://github.com/wooyeolbaek/attention-map-diffusers
二、使用步骤
代码结构:
- attention-map-diffusers/demo/demo-flux-dev.py
- 定位到有两个关键函数:init_pipeline 和 save_attention_maps
- 两个函数都在 attention-map-diffusers/attention_map_diffusers/utils.py
1.取得 Attention Map
- init_pipeline 中包含两个关键部分
- 注册 attention: register_cross_attention_hook
- 替换 call 方法: replace_call_method_for_flux
elif pipeline.transformer.__class__.__name__ == 'FluxTransformer2DModel':
from diffusers import FluxPipeline
FluxAttnProcessor2_0.__call__ = flux_attn_call2_0
FluxPipeline.__call__ = FluxPipeline_call
pipeline.transformer = register_cross_attention_hook(pipeline.transformer, hook_function, 'attn')
pipeline.transformer = replace_call_method_for_flux(pipeline.transformer)
1.1 注册钩子 hook
# ... existing code ...
def hook_function(name, detach=True):
def forward_hook(module, input, output):
if hasattr(module.processor, "attn_map"):
timestep = module.processor.timestep
attn_maps[timestep] = attn_maps.get(timestep, dict())
attn_maps[timestep][name] = module.processor.attn_map.cpu() if detach \
else module.processor.attn_map
del module.processor.attn_map
return forward_hook
# 在register_cross_attention_hook函数中:
hook = module.register_forward_hook(hook_function(name))
这行代码的作用是:
-
register_forward_hook是PyTorch的一个内置方法,用于注册一个前向传播钩子。这个钩子会在模块的前向传播完成后被调用。 -
hook_function(name)返回一个forward_hook函数,这个函数会:- 检查模块的处理器是否有注意力图(attn_map)
- 如果有,将注意力图保存到全局的
attn_maps字典中 - 保存时会按时间步(timestep)和层名(name)组织
-
钩子的工作流程:
- 每当模块完成一次前向传播
- 钩子函数会自动触发
- 捕获并存储该层的注意力图
- 然后删除原始注意力图以释放内存
这种机制让我们能够:
- 在不修改原始模型代码的情况下收集注意力图
- 按时间步和层级组织存储注意力信息
- 实时监控模型的注意力机制
这是实现注意力图可视化的关键部分。
1.2 替换 call 方法
这个替换的主要目的是为了在模型的前向传播过程中捕获注意力图。
def replace_call_method_for_flux(model):
# 替换主transformer模型的forward方法
if model.__class__.__name__ == 'FluxTransformer2DModel':
from diffusers.models.transformers import FluxTransformer2DModel
# 使用自定义的FluxTransformer2DModelForward替换原始forward方法
model.forward = FluxTransformer2DModelForward.__get__(model, FluxTransformer2DModel)
# 递归处理所有子层
for name, layer in model.named_children():
# 替换transformer block的forward方法
if layer.__class__.__name__ == 'FluxTransformerBlock':
from diffusers.models.transformers.transformer_flux import FluxTransformerBlock
# 使用自定义的FluxTransformerBlockForward替换原始forward方法
layer.forward = FluxTransformerBlockForward.__get__(layer, FluxTransformerBlock)
replace_call_method_for_flux(layer)
替换的原因:
-
注意力图捕获:
- 原始的forward方法没有保存注意力图的功能
- 自定义的forward方法会在计算注意力的同时保存注意力图
-
时间步记录:
- 自定义forward方法可以记录当前的时间步信息
- 这对于分析不同时间步的注意力变化很重要
-
非侵入式修改:
- 这种方式不需要修改原始模型代码
- 只是临时替换了forward方法,不影响模型的其他功能
-
层级追踪:
- 通过递归替换,确保模型中所有相关层都能捕获注意力信息
- 可以分析不同层级的注意力模式
这种替换机制配合之前的hook机制,共同实现了完整的注意力图捕获和存储功能。
所以完成 hook + 替换后,推理时自动就开始取得 attention map。即在推理(去噪过程)就自动跳到 hook_function 的 forward_hook 中。
2.存储 Attention Map
让我详细解释这个保存注意力图的层级结构:
- 目录结构:
base_dir/
├── timestep_0/ # 单个时间步
│ ├── layer_1/ # 该时间步的层
│ │ └── attention_maps.png # 该层的注意力图
│ └── layer_2/
├── timestep_1/
└── batch-0/average_attention_maps.png # 存储的所有时间步和层的平均注意力图(total_attn_map)对应到每个token的可视化结果
- 代码主要逻辑:
def save_attention_maps(attn_maps, tokenizer, prompts, base_dir='attn_maps', unconditional=True):
# 1. 准备工作
# 将提示词转换为token
token_ids = tokenizer(prompts)['input_ids']
total_tokens = [tokenizer.convert_ids_to_tokens(token_id) for token_id in token_ids]
# 2. 初始化总注意力图(用于计算平均)
total_attn_map = list(list(attn_maps.values())[0].values())[0].sum(1)
if unconditional:
total_attn_map = total_attn_map.chunk(2)[1] # 只取条件部分
total_attn_map = torch.zeros_like(total_attn_map.permute(0, 3, 1, 2))
# 3. 遍历每个时间步
for timestep, layers in attn_maps.items():
# 4. 遍历每个层
for layer, attn_map in layers.items():
# 处理注意力图
attn_map = attn_map.sum(1).squeeze(1).permute(0, 3, 1, 2)
if unconditional:
attn_map = attn_map.chunk(2)[1]
# 累加到总注意力图
resized_attn_map = F.interpolate(attn_map, size=total_attn_map_shape, mode='bilinear')
total_attn_map += resized_attn_map
# 5. 为每个batch保存该层的注意力图
for batch, (tokens, attn) in enumerate(zip(total_tokens, attn_map)):
save_attention_image(attn, tokens, batch_dir, to_pil)
# 6. 保存平均注意力图
total_attn_map /= total_attn_map_number
特别说明:
-
文件命名:
- 每个注意力图文件名格式为:
{index}-{token}.png - token会被特殊处理(添加<>-等标记)以表示词的开始和结束
- 每个注意力图文件名格式为:
-
注意力图处理:
- 对每个注意力图进行维度变换和压缩
- 如果是unconditional模式,只保留条件部分的注意力图
- 所有注意力图会被调整到相同大小并累加求平均
-
特殊处理:
- 支持批处理(多个输入)
- 支持unconditional模式(只保留条件部分)
- 计算并保存所有时间步和层的平均注意力图
这种存储结构让我们可以:
- 分析每个时间步的注意力变化
- 比较不同层的注意力模式
- 查看每个token对应的注意力分布
- 观察整体平均的注意力分布



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









