






目录
定义
向量 c()
矩阵 matrix(data, nrow, ncol, byrow, dimnames=list())
数组 array(data, 维度, dimnames=list()维度名称)
向量、矩阵、数组存储的数据类型必须相同
1.向量(1)字段定义
向量创建时值需要时相同类型的
Eg:age <- c(1,23,4,5) 创建了一个名为age的向量,向量里面的值可以是数字、字符串,sex <- c(“nan”,”nv”) 也可以是逻辑值 bool <- c(TRUE, FALSE, FALSE)
Weight<-c(2,3)
Age <- 1:10 创建了一个包含1至10的Age向量

(2)访问向量中的元素时,可用字段名[下标] eg:age[3] è4 age[2]è23
可用age[c(1,3)] 访问age中的第一个和第三个元素 1 4
可用age[1:3] 访问age中的第一个至第三个元素

2. 定义矩阵
(1)方式一:matrix(5:24, nrow=4, ncol=5) 矩阵的数值是5至24,4行5列,默认是按列填充 matrix(5:24, nrow=4, ncol=5,byrow=TRUE) 按行来填充

方式二:
x<- c(1, 2, 3, 4)
rnames <- c(“R1”, “R2”)
cnames<- c(“C1”, “C2”)
newMatrix<- matrix(x, nrow=2, ncol=2, byrow=TRUE, dimnames=list(rnames, cnames))

方式三 省略一些
Eg: matrix(1:20, nrow=4) 意思是创建一个已x为数据,4行 按列展示的矩阵
(2)获取矩阵数据
Eg:x[3,] 访问矩阵第三行数据
访问矩阵第一列的数据 x[, 1]
访问矩阵第1行3列的数据 x[1, 3]

3.定义数组
?array
(1)方式一:
Eg:dim1 <- c(“A1”, “A2”, “A3”) dim2 <- c(“B1”, “B2”, “B3”) dim3 <- c(“C1”, “C2”, “C3”) d<- array(1:24, c(3, 2, 4), dimnames=list(dim1, dim2, dim3)

4. 数据框定义
(1)各个列之间的数据模式可以不一致,但是每个列的数据类型是要保持一致的
Eg:patientId <- c (1, 10, 12, 13)
age<- c(24, 25, 30, 31)
diabetes<- c(“type1”, “type2”, “type3”, “type2”)
status<- c(“poor”, “improved”, “excellent”, “poor”)
patientsData <- data.frame(patientId, age, diabetes, status)

(2)获取数据框中的数据
方式一:patientsData[1:2] 获取数据框中的1列和2列
方式二:patientsData[c(“age”, “status”)] 获取列名为age和status的数据
方式三:patientsData$age, 获取列名为age的数据
方式四:attach(patientsData) 先将数据框patiensData加入到R的搜索中
然后直接通过列名称获取即可,eg diabetes
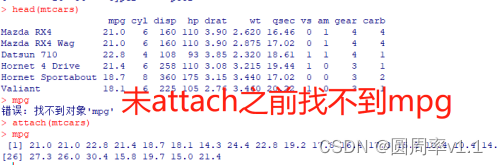
从R搜索路径中移除 detach(patientsData)
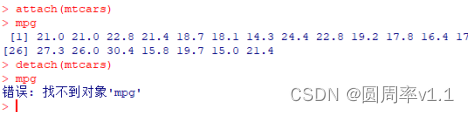
方法五 with(数据框名称, {取出数据框中的列,输出列})
Eg: with(mtcars, { l<-mpg, l})
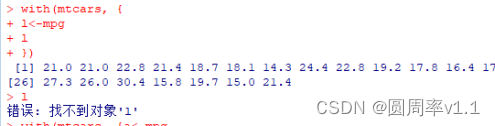
L只在with的大括号内有效在括号外就无效了
5. 因子定义
可以采用 factor(名称) 进行转换
Eg: factor(diabetes)
获取方式同向量获取方式

6.列表定义
Eg: g<- “my first” h<- c(12, 23, 34)
J <- matrix(1:10,nrow=2)
Mylist <- list (g, h, J)

获取数据 mylist[[2]] 双方括号

常用方法
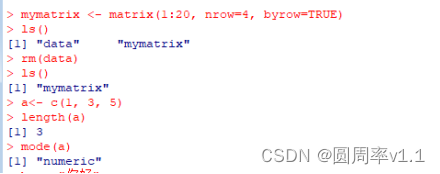
- ls() 列举当前已有的对象
- rm(对象名A) 删除对象A
- length(向量名称) 获取向量的长度 eg a<- c(1, 3, 5) length(a) =3
- mode(名称) 获取元素的数据类型 mode(a) “numeric”
5.根据条件获取向量值
Eg: a <- -10: 5
a[a>2] è 3,4,5
a[a>2 | a<-8] 获取大于2或者小于-8 的值 è 3,4,5,-9,-10
a[a>-5 & a<0] 获取大于-5 并且小于0 的数 -4,-3,-2,-1
6.向量内容自动转换及修改

7.获取平方根 sqrt(名称)
8.四则运算 z<- x+y 当两个向量长度不一致的时候,会循环短的向量
9.定义向量 seq(向量开始值,结束值,步长)
Eg : a<- seq( 1, 10, 2) è a:1 3 5 7 9
10.循环生成向量 rep(值,循环次数)
Eg: a<- rep(5, 4) è a: 5 5 5 5 值为5循环4次
B <- rep(1:2, 3) è B: 1 2 1 2 1 2 1:2的序列循环3次
11.随机生成 rnorm(10) 随机生成均值为0,标准差为1 正态分布的随机向量
Rnorm(个数x,mean=a, sd=b) 随机生成均值为a,标准差为b,正态分布的x个随机值
12.根据条件获取向量值
Eg: a <- -10: 5
a[a>2] è 3,4,5
a[a>2 | a<-8] 获取大于2或者小于-8 的值 è 3,4,5,-9,-10
a[a>-5 & a<0] 获取大于-5 并且小于0 的数 -4,-3,-2,-1

list列表详解
1.定义及获取
(1)Mylist <- list(stud.id=1234, stud.age= c(2, 5, 6))
获取列表里某一列的值Mylist[[1]] è1234
获取列表中某一列 Mylist[1] è stud.id 1234
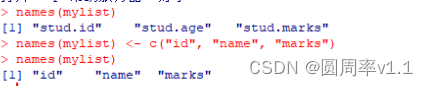
(2)获取列表中各列的名称 names(列表名)
给列表各列修改名称 names(列表名) <- c(“A”, “S”, “C”)
2.列表扩充及删减
Mylist$parents <- c(“Mna”, “bb”)
Mylist <- mylist[-4] 删除mylist中第四列
合并多个列表 list <- c(列表1名,列表2名,….)


3.列表转换成向量
Eg: unllist(列表名) 会将每一列中的数值强行转换为字符
数据源导入
1.键盘输入
先创建数据mydata <- data.frame(age=numeric(0), gender=character(0), weight=numeric(0))
使用edit进行编辑 mydata <- edit(mydata)
也可以用 fix(mydata),效果跟edit一样,不同的地方是,使用edit的时候需要将edit(mydata)赋值给mydata,而fix不需要,直接修改mydata

2.从文本文件导入
使用read.table(文件路径,hearder=TRUE, sep=”,”)
文件路径不能有中文;
Header可以是TRUE或者FALSE ,取决于文本数据中是否含有表头内容,有就TRUE
Sep指的是数据之间使用什么进行分割
如果导入失败,可能原因是R不支持该文件的编码方式,选择ANSI,操作方式可以另存为新的文件,并且选择ANSI编码
3.Excel导入

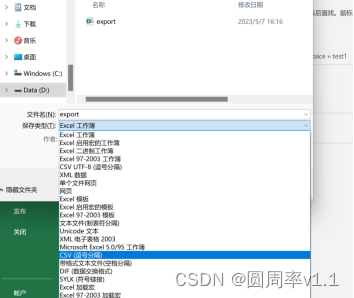

使用read.csv导入excel的时候可能出现上面的问题,可以将Excel另存为csv后缀文件
用户自定义函数
1.定义
myfunction <- function(参数){
流程。。。
这里返回内容
}
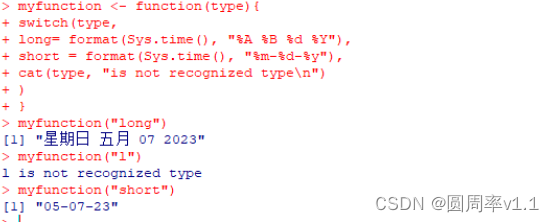
里面的type是传参,如果type是long的时候输入一种格式的时间,如果是short的时候,输入简单格式时间,如果两者都不是,输出,is not recognized type
2.for循环使用

R集成开发环境(IDE--Rstudio)
下载地址 http://www.rstudio.com
R画图
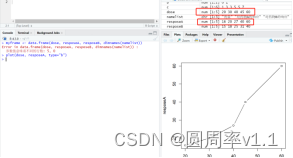
1.plot()
绘制图形plot(数据A, 数据B,type=“b”) type=“b”表示同时绘制点和线条,数据A相当于x轴,数据B相当于y轴
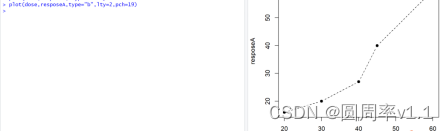
2.par()

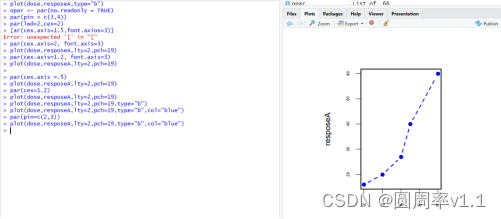
Opor <- par(no.readonly=TRUE)
还可以 par(lty=2, pch=17) lty=2用虚线展示 pch=17 默认点符号转换为实心的三角符号

如果想要回复到原先的图像,可以直接使用 par(Opor) Opor 是将par(no,readonly=TRUE)的值赋给Opor,这个字符可以是其他任何字符,相当于一个名字,可以叫其他的


3.文本属性

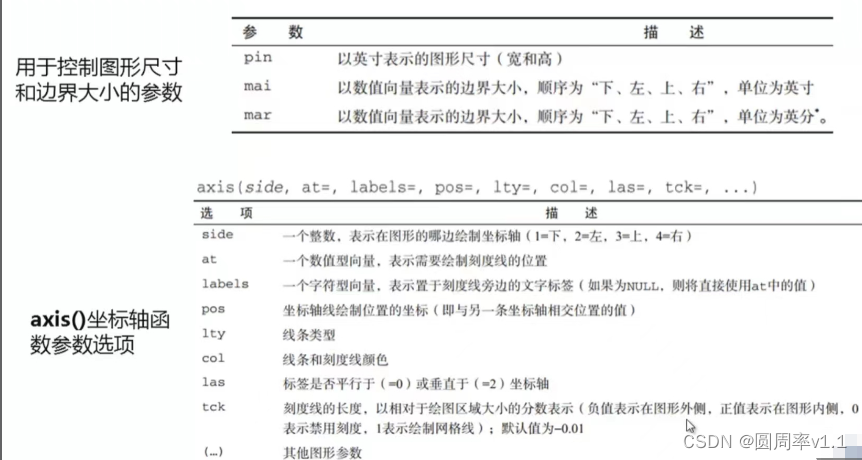
4.图形、边界尺寸
5.添加标题
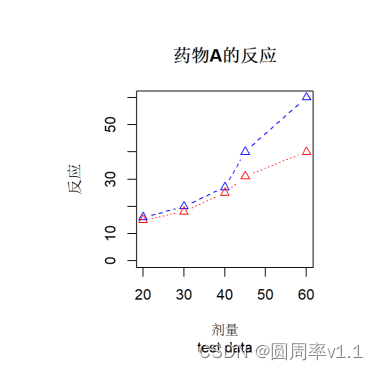
plot(dose,resposeA,lty=2,pch=2,type = "b",col="blue",main="药物A的反应",sub="test data", xlab="剂量", ylab="反应", xlim=c(20,60), ylim=c(0,60))
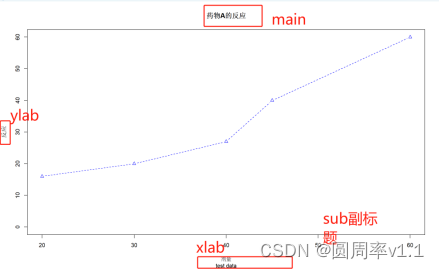
此外 xlim=c(20,60) x轴的刻度从20到60,ylim表示y轴的刻度
也可以用title函数来添加
Eg:title(main=”title”, col.main=”red”, sub=”futest”, col.sub=”green”)
再添加一条线lines(dose,resposeB,type="b",lty=3, pch=2,col="red")
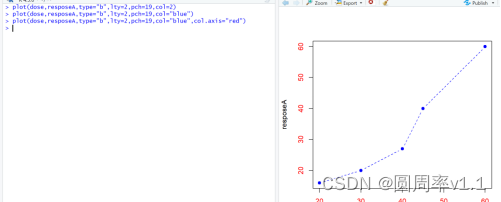
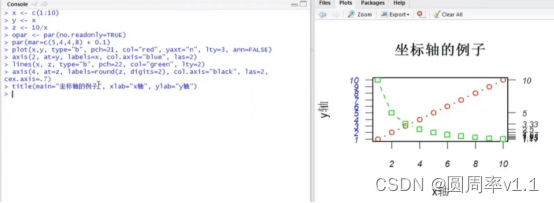
6自定义坐标轴
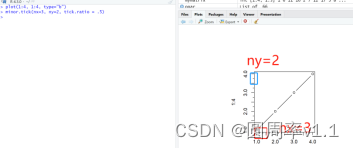
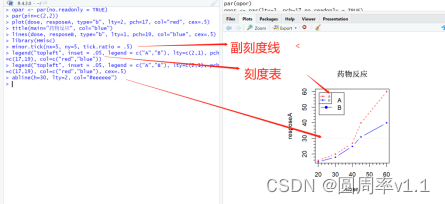
7.次要刻度线
需要先下载包Hmisc, install.packages(“Hmisc”)
导入Hmisc包 library(Hmisc)
之后使用 minor.tick(nx=2, ny=3, tick.ration=n)
其中nx=2,是把x轴上主要的刻度线分成2份,ny=3:是把y轴上的主要刻度线分3份; tick.ration:代表着次要刻度与主要刻度的比值
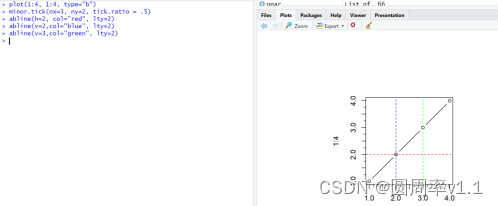
8.参考线
参考线,abline(h=value, v=value)
其中h=value :代表着y轴上有一个点,平行于x轴的水平线,v则是平行于y轴的竖线,abline是在已有的图形上添加辅助线
Eg abline(h=2, col=”red”, lty=2) 水平线,与y轴相交于(0,2)
9.图例
添加图例是用legend函数来实现的


10.文本标注
11.图形组合
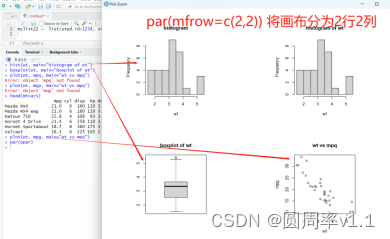
- par函数的mfrow
柱状图 hist()
线形图plot()
箱线图 boxplot()
layout函数
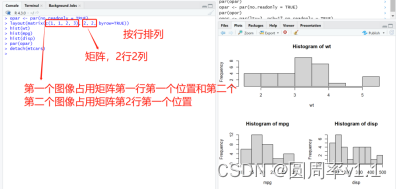
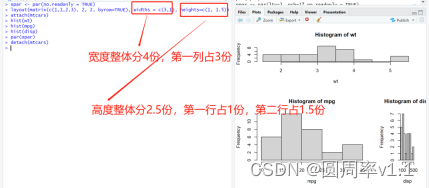
图形布局的精细控制
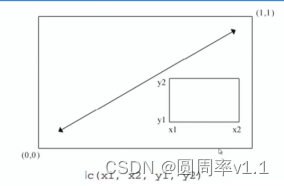
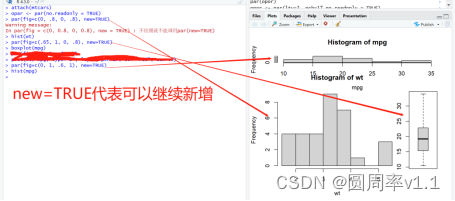
R的基本数据管理
1.新增属性

2.判断数据中是否有NA :is.na(数据)

3.操作数据运算时抛出NA的影响
Eg,sum(data, na.rm=TRUE) ,数据data求和操作,并刨除NA的影响
如果不用na.rm =TRUE,如图会打印出NA

删除有NA数据的所在行
Eg na.omit(data) 删除数据data中有NA的行
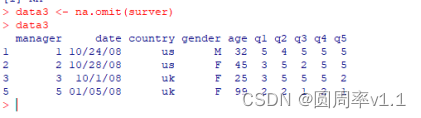
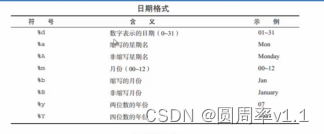
4.日期
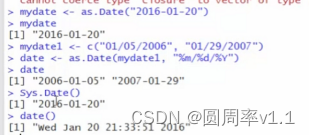
5.类型转换

6.数据集的合并
(1)矩阵按列方式合并 cbind(matrix1, matrix2)

(2)merge(frame1,frame2, by=xxxx), merge合并两个数据框,两个数据源同时含有xxx列,通过xxx列实现两个数据源的合并
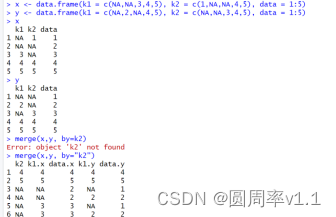
添加方式:取到x的第一行,k2=1,发现y中没有k2=1的行,所有k2=1不添加到合并中
取x的第二行,k2=NA,在y中发现两个k2=NA的行,所以就x的第二行分别与y的两行合并,以此类推
(3)按行合并矩阵 rbind(x,y),
7.数据集取子集

(1)使用subset函数, 用于数据框和矩阵
Eg subset(data, 条件, select =c(留下的列) )
newdata <- subset(surver, age>=35 | age<26, select=c("age", "q1", "q2", "q3", "q4"))
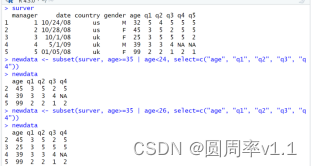
(2)随机抽样函数
使用sample函数 sample(n,size, replace) n为数据,size为随机取样本个数,replace=FALSE的时候为不重复抽取(此时n的长度要大于等于size),TRUE的时候抽取的数据可以重复,

图形中报错的原因就是数据里面只有0和1,想要随机取出100个数,还设置了replace=FALSE,抽取的数据不能重复导致的

五行数据中随机抽取3行不重复的数据
R高级数据管理
1.数学函数
(1)abs(-3) è3 取绝对值
(2)sqrt(9) è 3 平方根
(3)ceiling(3.5) è4 向上取整
(4)floor(3.5) è 3 向下取整
(5)round(3.4) è3 四舍五入
(6)三角函数 sin(), cos()
(7)对数函数 log()
2.统计函数
(1)sum 求和
(2)mean() 平均
(3)sd 标准差
(4)var()方差
(5)max()最大值
(6)min()最小值
(7)scale(data, data是数据源,将数据data标准化成均值为0, 标准差为1,
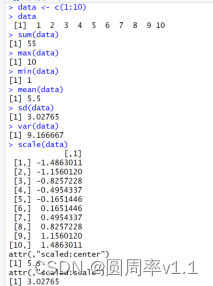
3.字符处理函数
(1)nchar(x), 统计变量中字符数量 nchar("adadjad1232") è11
(2)substr(x, start,end) 将字符串x中从start到end的字符提取出来 substr(x,1,3)
(3)grep(字符,x) 在x中搜索字符所在的位置
(4)sub(a, b ,x) 将字符串中的a 替换成b,x是字符串时只替换第一次出现的a,如果是向量则替换全部的a
(5)strsplit(x, a) ,遇到a的时候将字符串分割
(6)paste( x,y) 将x和y连接起来

未完待续......















 8083
8083











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









