






数据查看
http://www.glass.umd.edu/Download.html
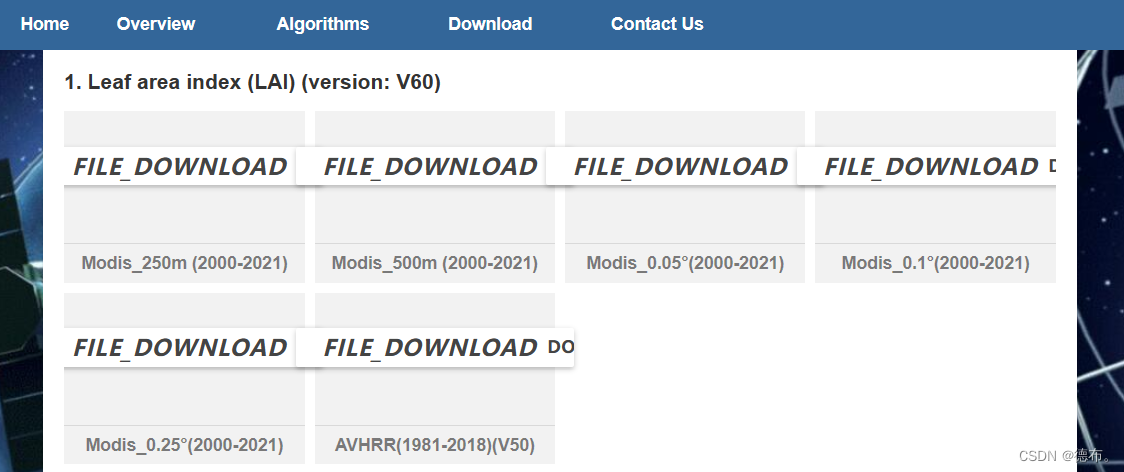
一、选择Modis_250m

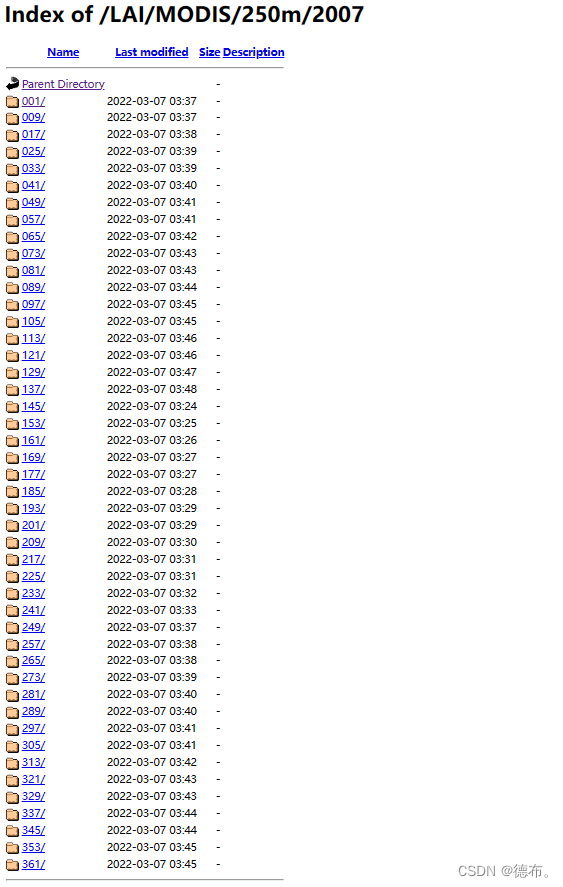

1)数据批量下载
- 编写代码进行进行下载
#-*- coding:utf-8 -*-
# http://www.glass.umd.edu/LAI/MODIS/250m/2007/001/GLASS01D01.V60.A2007001.h00v08.2022012.hdf
url_name=[]
site = r'http://www.glass.umd.edu/LAI/MODIS/250m/'
years = ['2008', '2009', '2010', '2011', '2012', '2013', '2014']#数据年份
days = ['001', '009', '017', '025', '033', '041', '049', '057', '065', '073',
'081', '089', '097', '105', '113', '121', '129', '137', '145', '153',
'161', '169', '177', '185', '193', '201', '209', '217', '225', '233',
'241', '249', '257', '265', '273', '281', '289', '297', '305', '313',
'321', '329', '337', '345', '353', '361']
#生成下载链接并导入到txt中,范围是全球。
for year in years:
for day in days:
for i in range(0, 36):#区域列号
for j in range(0, 15):#区域行号
if i<10:
if j < 10:
url_name= site + year + '/' + day + '/' + 'GLASS01D01.V60.A' + year + day + '.h0'+str(i)+'v0'+str(j)+".2022012.hdf"
else:
url_name = site + year + '/' + day + '/' + 'GLASS01D01.V60.A' + year + day + '.h0' + str(i) + 'v' + str(j) + ".2022012.hdf"
else:
if j < 10:
url_name = site + year + '/' + day + '/' + 'GLASS01D01.V60.A' + year + day + '.h' + str(i) + 'v0' + str(j) + ".2022012.hdf"
else:
url_name = site + year + '/' + day + '/' + 'GLASS01D01.V60.A' + year + day + '.h' + str(i) + 'v' + str(j) + ".2022012.hdf"
with open('F:\BEPS_SCOPE\Dataset\\urls.txt', 'a') as f:
f.write(url_name + '\n')
参考https://blog.csdn.net/weixin_42776126/article/details/118555405?spm=1001.2014.3001.5501
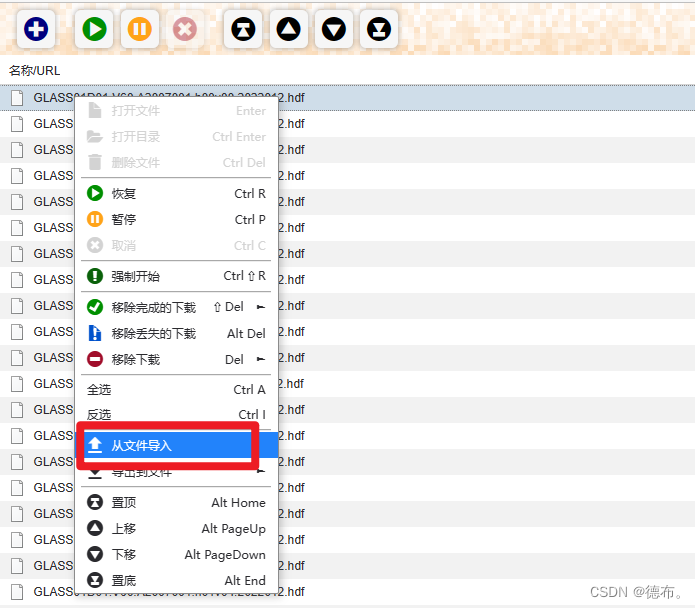
- 使用“Down ThemAll!”插件进行下载
点击“从文件中导入”,选择Python保存的"TXT"文件
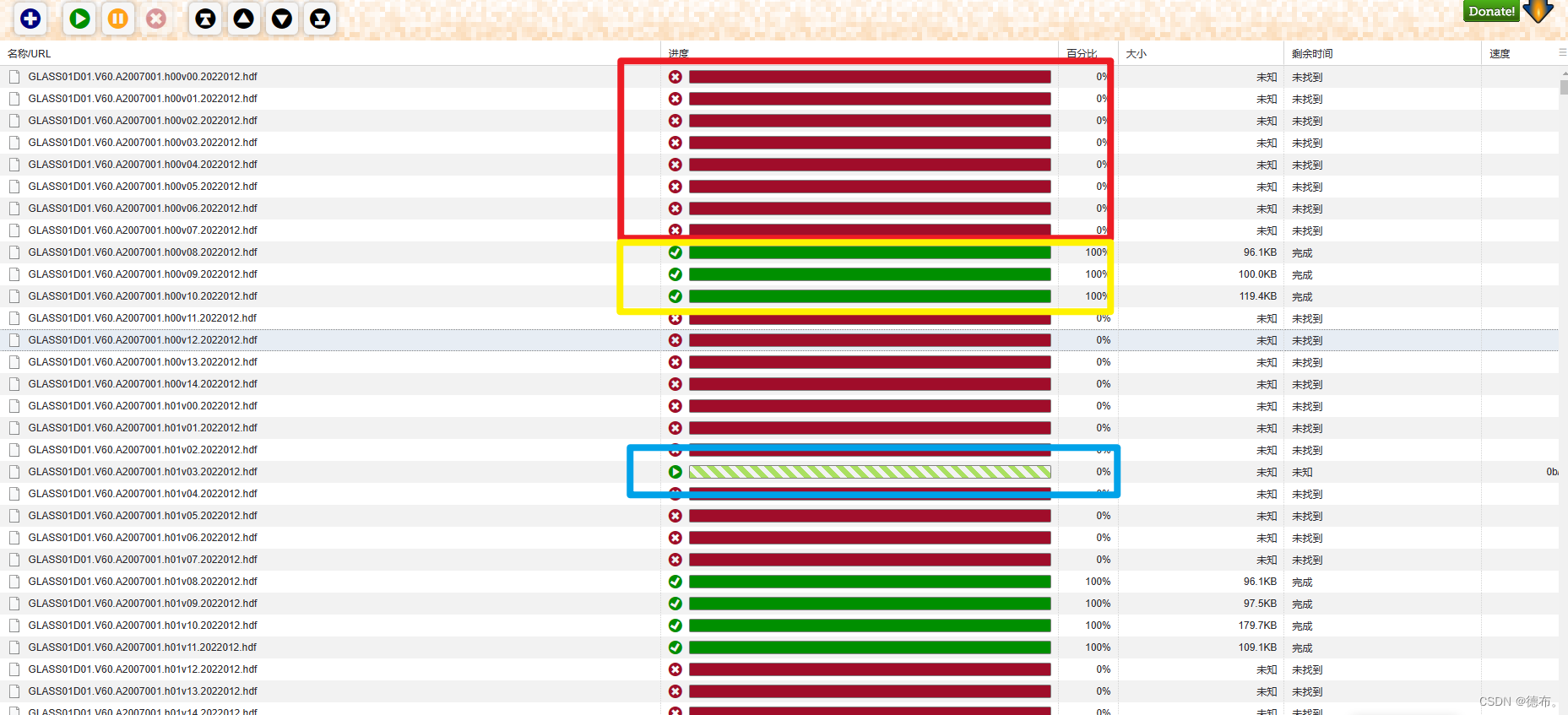
开始下载,因为需要下载全球数据,所以python代码中没有进行行列号的选择,行号为0-36,列号为0-15,但实际上并不是每个行列号对应的区域都有数据,会出现下载不成功的情况。另外如果有“未知”情况发生,需要认真核对是否有当前区域的数据。
2) 数据预处理
参考https://blog.csdn.net/weixin_42776126/article/details/120960494
二、选择Modis_0.25°数据,下载得到HDF格式的数据利用python进行处理
from pyhdf.SD import SD
from osgeo import gdal, osr
import os
root = r'F:\SCOPE_MLR\Dataset\GLASS_LAI\PYTHON\HDF'
# 遍历主文件夹下的子文件夹
for subdir in os.listdir(root):
subdir_path = os.path.join(root, subdir)
# 检查是否为文件夹
if os.path.isdir(subdir_path):
# 遍历子文件夹中的HDF文件
for file_name in os.listdir(subdir_path):
if file_name.endswith('.hdf'):
HDF_FILE_URL = os.path.join(subdir_path, file_name)
# 进行HDF文件的处理操作
# %% 读取HDF信息并提取数据
filename = file_name.split('.')[1]
filename = "GLASS_" + filename
file = SD(HDF_FILE_URL)
print(file.info()) # 打印HDF文件的信息,包括文件中包含的数据集数量、维度等
datasets_dic = file.datasets() # 获取HDF文件中所有数据集的字典。
for idx, sds in enumerate(datasets_dic.keys()):
print(idx, sds) # 遍历数据集字典中的键(数据集名称)和值(数据集对象),使用enumerate函数获取索引, 打印数据集的索引和名称。
sds_obj = file.select('LAI') # 选择名为'LAI'的数据集
LAI = sds_obj.get() # 获取选定数据集的数据
'''Spatial Reference'''
sr = osr.SpatialReference() # 创建一个空间参考对象
sr.ImportFromEPSG(4326) # 将空间参考对象设置为EPSG 4326坐标系,即WGS 1984坐标系
s = sr.ExportToWkt() # 将空间参考对象转换为WKT(Well-Known Text)格式的字符串
driver = gdal.GetDriverByName("GTiff") # 获取GTiff驱动程序
dataset = driver.Create(filename + '.tif', 1440, 720, 1, gdal.GDT_Int16,
["TILED=YES", "COMPRESS=LZW"]) # 创建一个输出GeoTIFF文件,指定文件名、图像宽度、图像高度、波段数、数据类型和创建选项;1440,720是HDF中数字矩阵的大小;
#利用HDF数据表示的左上角(-180.00,90.00)和右下角(180.00,-90.00)的坐标,计算像元的宽度和高度,坐标数据来源于.hdf.xml文件
pixelwidth = (180.00 - (-180.00)) / 1440
pixelheight = (90.00 - (-90.00)) / 720
im_geotrans = (-180.00, pixelwidth, 0.0, 90.00, 0.0, pixelheight) # 设置输出图像的地理变换信息,包括左上角X坐标、像元宽度、旋转角度、左上角Y坐标、旋转角度和像元高度
dataset.SetGeoTransform(im_geotrans) # 设置输出图像的地理变换
dataset.SetProjection(s) # 设置输出图像的空间参考信息
dataset.GetRasterBand(1).WriteArray(LAI)
参考https://blog.csdn.net/amyniez/article/details/125825307
https://www.bilibili.com/read/cv16607460/

















 556
556

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









